 電子發燒友App
電子發燒友App


前言
從圖像中提取文字屬于信息智能化處理的前沿課題,是當前人工智能與模式識別領域中的研究熱點。由于文字具有高級語義特征,對圖片內容的理解、索引、檢索具有重要作用,因此,研究圖片文字提取具有重要的實際意義。又由于靜態圖像文字提取是動態圖像文字提取的基礎,故著重介紹了靜態圖像文字提取技術。
隨著計算機科學的飛速發展,以圖像為主的多媒體信息迅速成為重要的信息傳遞媒介,在圖像中,文字信息(如新聞標題等字幕) 包含了豐富的高層語義信息,提取出這些文字,對于圖像高層語義的理解、索引和檢索非常有幫助。
圖像文字提取又分為動態圖像文字提取和靜態圖像文字提取兩種,其中,靜態圖像文字提取是動態圖像文字提取的基礎,其應用范圍更為廣泛,對它的研究具有基礎性,所以本文主要討論靜態圖像的文字提取技術。靜態圖像中的文字可分成兩大類: 一種是圖像中場景本身包含的文字, 稱為場景文字; 另一種是圖像后期制作中加入的文字, 稱為人工文字,如右圖所示。場景文字由于其出現的位置、小、顏色和形態的隨機性, 一般難于檢測和提取;而人工文字則字體較規范、大小有一定的限度且易辨認,顏色為單色, 相對與前者更易被檢測和提取, 又因其對圖像內容起到說明總結的作用,故適合用來做圖像的索引和檢索關鍵字。對圖像中場景文字的研究難度大,目前這方面的研究成果與文獻也不是很豐富,本文主要討論圖像中人工文字提取技術。
靜態圖像中文字的特點
靜態圖像中文字(本文特指人工文字,下同)具有以下主要特征:
(1)文字位于前端,且不會被遮擋;
(2)文字一般是單色的;
(3)文字大小在一幅圖片中固定,并且寬度和高度大體相同,從滿足人眼視覺感受的角度來說,圖像中文字的尺寸既不會過大也不會過小;
(4)文字的分布比較集中;
(5)文字的排列一般為水平方向或垂直方向;
(6)多行文字之間,以及單行內各個字之間存在不同于文字區域的空隙。在靜態圖片文字的檢測與提取過程中, 一般情況下都是依據上述特征進行處理的。
數字圖象處理
靜態圖像文字提取一般分為以下步驟:文字區域檢測與定位、文字分割與文字提取、文字后處理。其流程如圖所示。
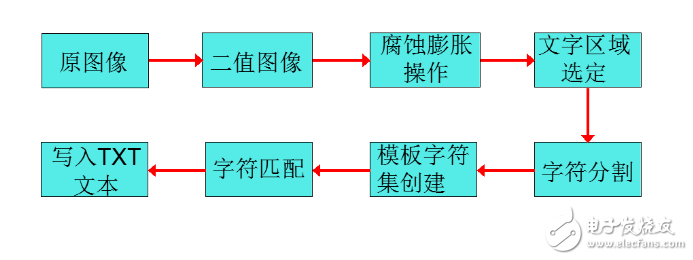
文字提取、識別的詳細步驟
1. 在Matlab中調用i1=imread(‘字符.jpg’),可得到原始圖像,如圖所示:
?
2. 調用i2=rgb2gray(i1),則得到了灰度圖像,如圖所示:
?
調用a=size(i1);b=size(i2);可得到:a=3,b=2 即三維圖像變成了二維灰度圖像
3. 調用i3=(i2》=thresh);其中thresh為門限,
圖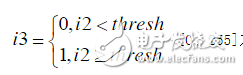 之間這里,?
之間這里,?
得到二值圖像,如圖所示:?

4. 把二值圖像放大觀察,可看到離散的黑點 對其采用腐蝕膨脹處理,得到處理后的圖像,如圖所示
?
可見,腐蝕膨脹處理后的圖像質量有了很大的改觀。 橫向、縱向分別的腐蝕膨脹運算比橫向、縱向同時的腐蝕膨脹運算好上很多,圖6可看出差別:
?
5、對腐蝕膨脹后的圖像進行Y方向上的區域選定,限定區域后的圖像如圖所示: 掃描方法:中間往兩邊掃
?
縱向掃描后的圖像與原圖像的對照,如圖8所示:
?
6、對腐蝕膨脹后的圖像進行X方向上的區域選定,限定區域后的圖像如圖9所示: 掃描方法:兩邊往中間掃
?
縱向掃描后的圖像與原圖像的對照,如圖所示:
?
7. 調用i8=(iiXY~=1),使背景為黑色(0),字符為白色(1),便于后期處理。 背景交換后的圖像如圖11所示:
8. 調用自定義函數(字符獲取函數)i9=getchar(i8),得到圖像如圖所示:
9、調用自定義的字符獲取函數對圖像進行字符切割,并把切割的字符裝入一維陣列,切割 過程如圖12所示:
10.調用以下代碼,可將陣列word中的字符顯示出來,如圖13所示:
?
? ? ? ? for j=1:cnum %cnum為統計的字符個數
? ? ? ? subplot(5,8,j),imshow(word{j}),title(int2str(j)); %顯示字符?
? ? ? end
?可以看到,字符寬度不一致
?
11. 調用以下代碼,將字符規格化,便于識別: for j=1:cnum word{j}=imresize(word{j},[40 40]); %字符規格化成40×40的 end 得到規格化之后的字符如圖14所示:
12. 調用以下代碼創建字符集:
code=char(‘由于作者水平有限書中難免存在缺點和疏漏之處懇請讀批評指正,。’);
將創建的字符集保存在一個文件夾里面,以供匹配時候調用,如圖15所示:
?
13. 字符匹配采用模板匹配算法:將現有字符逐個與模板字符相減,認為相減誤差最小的現 有字符與該模板字符匹配。
?
也就是說,字符A與模板字符T1更相似,我們可以認為字符集中的字符T2就是字符A。 經模板匹配,可得字符信息如下: 由于讀者書評有限書中難免存在缺點和紕漏之處,懇請讀者批評指正。 效果如圖16所示:
?
14、調用以下代碼,將字符放入newtxt.txt文本:
new=[‘newtxt’,‘.txt’]; c=fopen(new,‘a+’); fprintf(c,‘%s ’,Code(1:cnum)); fclose(c); newtxt.txt文本內容如圖17所示:
?
總結
1、算法具有局限性。對于左右結構的字符(如:川)容易造成誤識別,“川”字將會被識別成三部分。當圖片中文字有一定傾斜角度時,這將造成識別困難。
2、模板匹配效率低。對于處理大小為m×m的字符,假設有n個模板字符,則識別一個字符至
少需要m×m×n×2次運算,由于漢字有近萬個,這將使得運算量十分巨大!此次字符識 別一共花了2.838秒。
3、伸縮范圍比較小。對于受污染的圖片,轉換成二值圖像將使字符與污染源混合在一起。
對于具體的圖片,需反復選擇合適的thresh進行二值化處理,甚至在處理之前必須進行各種濾波。











 工商網監
工商網監
評論