 電子發(fā)燒友App
電子發(fā)燒友App


以x86體系為代表的CPU已經(jīng)占有了桌面和服務(wù)器處理器的絕大部分份額,而且這個(gè)趨勢(shì)還在不斷增強(qiáng)。CPU具有兼容性強(qiáng)、易編程、應(yīng)用資源豐富、價(jià)格低廉的優(yōu)勢(shì),但是在某些領(lǐng)域,CPU存在天然的缺陷,以FPGA、GPU為代表的硬件可以克服CPU的缺陷,因此也擁有自己的市場(chǎng)。
1.1 圖解各類型芯片
從設(shè)計(jì)軟件進(jìn)行計(jì)算任務(wù)的軟件工程人員的角度,可以將芯片分為CPU、GPU、FPGA和ASIC等類型。
對(duì)處理器芯片的特性和應(yīng)用,理論上是軟件人員具有最大發(fā)言權(quán)。但每一類芯片的使用和理解都不是一件簡(jiǎn)單的事情,以CPU為例:即使從事CPU環(huán)境的編程設(shè)計(jì)多年,也很難談得上深入理解了CPU的設(shè)計(jì)思想。能深入各種芯片編程的軟件人員更是鳳毛麟角,更別談進(jìn)行分析和比較。另外一個(gè)問(wèn)題是軟件和硬件設(shè)計(jì)已分離多年,軟件設(shè)計(jì)人員,很難深入理解芯片的設(shè)計(jì)思路,即使操作系統(tǒng)的設(shè)計(jì)人員也一樣。而芯片的設(shè)計(jì)廠商由于利益相關(guān),往往只宣揚(yáng)各自的優(yōu)點(diǎn),回避缺陷,在測(cè)試對(duì)比中選擇有利的測(cè)試條件,產(chǎn)生對(duì)己有利的測(cè)試數(shù)據(jù)。測(cè)試數(shù)據(jù)的真真假假,更加混淆了技術(shù)人員的視聽。
在對(duì)各種芯片比較和研究的過(guò)程中,我們認(rèn)為不應(yīng)該沉湎于具體芯片的架構(gòu)和設(shè)計(jì)思路,而應(yīng)該關(guān)注芯片的實(shí)際應(yīng)用。有兩個(gè)原因支持我們的思路。一個(gè)原因是芯片的架構(gòu)非常繁復(fù),熟悉各種芯片幾乎是不可能的任務(wù)。另一個(gè)更重要的原因是技術(shù)的價(jià)值在于應(yīng)用。不管何種芯片設(shè)計(jì)或者架構(gòu),最終決定芯片價(jià)值的是實(shí)際的應(yīng)用。從應(yīng)用的角度出發(fā),應(yīng)按照易用性和經(jīng)濟(jì)性兩個(gè)維度考察芯片。
易用性指用芯片進(jìn)行編程的難度以及相關(guān)編程資源的獲取難度。這個(gè)指標(biāo)技術(shù)人員雖然不怎么關(guān)心,但其實(shí)對(duì)芯片發(fā)展有重大,甚至是絕對(duì)的重要性。例如在FPGA的編程實(shí)踐中,相關(guān)的編程資源非常難以獲得,即使獲得也往往是代價(jià)巨大。比如常見的JPEG圖片,相關(guān)的FPGA編解碼庫(kù)往往需要付出數(shù)萬(wàn)美元的成本,這和CPU領(lǐng)域大量的開源庫(kù)完全不能相提并論。價(jià)格的昂貴還帶來(lái)了測(cè)試和驗(yàn)證的繁雜。提供庫(kù)資源的廠商往往需要曠日持久的溝通和談判以及簽署協(xié)議才能進(jìn)行驗(yàn)證工作,這在很多研發(fā)項(xiàng)目運(yùn)作中幾乎是不可承受的。
經(jīng)濟(jì)性指提供相同性能情況下的芯片成本。芯片往往型號(hào)眾多,比如FPGA芯片,既有上千美元甚至幾千美元售價(jià)的高端型號(hào),也有幾美元計(jì)價(jià)的低端型號(hào)。脫離芯片成本談?wù)撔阅軟](méi)有意義。需要指出的是,成本是綜合的運(yùn)營(yíng)成本,而非單獨(dú)的芯片購(gòu)買成本。比如某款芯片如果性能等于CPU十倍,那么它不僅僅是頂替了十顆CPU,而是頂替了十臺(tái)服務(wù)器的采購(gòu)成本以及十臺(tái)服務(wù)器的運(yùn)營(yíng)成本,考慮到實(shí)際的運(yùn)營(yíng)成本往往大于采購(gòu)成本,后者可能更具有重要性。
1.2 芯片的分類
對(duì)常用的處理器芯片進(jìn)行分類,有一個(gè)明顯的特點(diǎn):CPU&GPU需要軟件支持,而FPGA&ASIC則是軟硬件一體的架構(gòu),軟件就是硬件。這個(gè)特點(diǎn)是處理器芯片中最重要的一個(gè)特征。
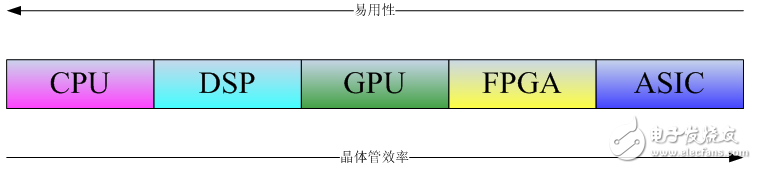
上圖可以從兩個(gè)角度來(lái)說(shuō)明:從ASIC->CPU的方向,沿著這個(gè)方向芯片的易用性越來(lái)越強(qiáng),CPU&GPU的編程需要編譯系統(tǒng)的支持,編譯系統(tǒng)的作用是把高級(jí)軟件語(yǔ)言翻譯成機(jī)器可以識(shí)別的指令(也叫機(jī)器語(yǔ)言)。高級(jí)語(yǔ)言帶來(lái)了極大的便利性和易用性,因此用CPU&GPU實(shí)現(xiàn)同等功能的軟件開發(fā)周期要遠(yuǎn)低于FPGA&ASIC芯片。沿著CPU->ASIC的方向,芯片中晶體管的效率越來(lái)越高。因?yàn)镕PGA&ASIC等芯片實(shí)現(xiàn)的算法直接用晶體管門電路實(shí)現(xiàn),比起指令系統(tǒng),算法直接建筑在物理結(jié)構(gòu)之上,沒(méi)有中間層次,因此晶體管的效率最高。
本質(zhì)上軟件的操作對(duì)象是指令,而CPU&GPU則扮演高速執(zhí)行指令的角色。指令的存在將程序執(zhí)行變成了軟件和硬件兩部分,指令的存在也決定了各種處理器芯片的一些完全不同的特點(diǎn)以及各自的優(yōu)劣勢(shì)。
FPGA&ASIC等芯片的功能是固定的,它們實(shí)現(xiàn)的算法直接用門電路實(shí)現(xiàn),因此FPGA&ASIC編程就是用門電路實(shí)現(xiàn)算法的過(guò)程,軟件完成意味著門電路的組織形式已經(jīng)確定了,從這個(gè)意義上,F(xiàn)PGA&ASIC的軟件就是硬件,軟件就決定了硬件的組織形式。軟硬件一體化的特點(diǎn)決定了FPGA&ASIC設(shè)計(jì)中極端重要的資源利用率特征。利用率指用門電路實(shí)現(xiàn)算法的過(guò)程中,算法對(duì)處理器芯片所擁有的門電路資源的占用情況。如果算法比較龐大,可能出現(xiàn)門電路資源不夠用或者雖然電路資源夠用,但實(shí)際布線困難無(wú)法進(jìn)行的情況。
存在指令系統(tǒng)的處理器芯片CPU&GPU不存在利用率的情況。它們執(zhí)行指令的過(guò)程是不斷從存儲(chǔ)器讀入指令,然后由執(zhí)行器執(zhí)行。由于存儲(chǔ)器相對(duì)于每條指令所占用的空間幾乎是無(wú)限的,即使算法再龐大也不存在存儲(chǔ)器空間不夠,無(wú)法把算法讀入的情況。而且計(jì)算機(jī)系統(tǒng)還可以外掛硬盤等擴(kuò)展存儲(chǔ),通過(guò)把暫時(shí)不執(zhí)行的算法切換到硬盤保存更增加了指令存儲(chǔ)的空間。
處理器芯片各自長(zhǎng)期發(fā)展的過(guò)程中,形成了一些使用和市場(chǎng)上鮮明的特點(diǎn)。CPU&GPU領(lǐng)域存在大量的開源軟件和應(yīng)用軟件,任何新的技術(shù)首先會(huì)用CPU實(shí)現(xiàn)算法,因此CPU編程的資源豐富而且容易獲得,開發(fā)成本低而開發(fā)周期,而FPGA&ASIC編程需要的資源通常很難獲得,這些資源往往以IP(intellectual property)的方式授予和收費(fèi),授予的周期往往很長(zhǎng)而且需要簽署法律協(xié)議,而費(fèi)用也很昂貴。導(dǎo)致FPGA&ASIC的開發(fā)成本高而且周期很長(zhǎng)。
1.3 CPU架構(gòu)和編程設(shè)計(jì)
無(wú)論是x86體系為代表的繁雜指令系統(tǒng)(CISC)CPU還是精簡(jiǎn)指令系統(tǒng)(RISC)CPU,其核心都是執(zhí)行一套指令系統(tǒng)。x86體系的CPU不斷更新?lián)Q代,不斷提升主頻,采用更先進(jìn)的工藝和新架構(gòu),目的就是為了更高性能地執(zhí)行x86指令。因?yàn)閄86系列的CPU應(yīng)用廣泛,已經(jīng)成為事實(shí)上的標(biāo)準(zhǔn),本文所指的CPU特指X86系列的CPU。
從CPU內(nèi)部結(jié)構(gòu)觀察,大致可分為控制器和執(zhí)行器,再加上存儲(chǔ)管理部件MMU以及總線接口部件。控制器不斷從存儲(chǔ)器取出指令,進(jìn)行指令譯碼,執(zhí)行器從譯碼完成的指令隊(duì)列中取出譯碼指令執(zhí)行。各個(gè)功能部件既能獨(dú)立工作,又能與其他部件配合工作,下圖給出了CPU各個(gè)部件之間的指令操作流水圖。
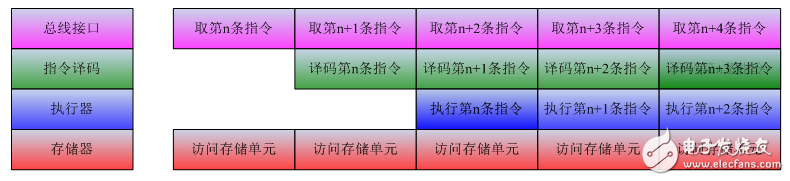
指令系統(tǒng)是計(jì)算機(jī)系統(tǒng)發(fā)展中的巨大進(jìn)步。借助指令系統(tǒng),高級(jí)語(yǔ)言的出現(xiàn)成為可能,大大方便了計(jì)算機(jī)的應(yīng)用。但是事情的另一面是使用指令系統(tǒng)后,所有的計(jì)算任務(wù)都要翻譯為指令,執(zhí)行一個(gè)簡(jiǎn)單的計(jì)算任務(wù)可能就需要多條指令完成。從晶體管的角度來(lái)看,簡(jiǎn)單的計(jì)算任務(wù)可能就需要眾多的晶體管共同參與。為提升性能,采用指令系統(tǒng)的CPU,其性能設(shè)計(jì)出發(fā)點(diǎn)是增強(qiáng)指令執(zhí)行的效率。
以前CPU的架構(gòu)設(shè)計(jì)一直圍繞如何增強(qiáng)指令執(zhí)行的效率,為此采取的措施是不斷提升主頻、加多流水線(奔騰首次應(yīng)用了雙路流水,而現(xiàn)在的CPU往往擁有20以上的流水?dāng)?shù)目
)以及增加CPU的cache提升取指令的效率(早期奔騰芯片擁有幾十K的緩存,而至強(qiáng)E5的三級(jí)緩存超過(guò)10MB,甚至可達(dá)到30MB)。近幾年,CPU的架構(gòu)更加重視多核的應(yīng)用,期望通過(guò)多核實(shí)現(xiàn)更高的性能。
CPU設(shè)計(jì)出發(fā)點(diǎn)是增強(qiáng)指令的運(yùn)行性能,因此CPU的核心功能強(qiáng)大,占用的晶體管資源龐大,具有很高的運(yùn)行效率,因此CPU的多核不可能做到非常多。目前頂級(jí)的X86 CPU具有十多個(gè)核心,而GPU已經(jīng)達(dá)到幾千個(gè)核心。
對(duì)編程設(shè)計(jì)來(lái)說(shuō),如果線程完全獨(dú)立的執(zhí)行計(jì)算任務(wù),線程間數(shù)據(jù)不存在共享和競(jìng)爭(zhēng)關(guān)系,那么并行效率可以達(dá)到線性效果。不過(guò)現(xiàn)實(shí)中的編程,有很大一類是單任務(wù)的并行化,即將一個(gè)繁雜的任務(wù)通過(guò)多核并行執(zhí)行來(lái)加速,那么就面臨兩個(gè)困難:一個(gè)是將任務(wù)并行化之后面臨多線程之間的切換代價(jià)。因?yàn)镃PU核心功能強(qiáng)大,因此操作系統(tǒng)切換線程時(shí)需要CPU內(nèi)部大量的狀態(tài)寄存器置位,所以線程之間切換是代價(jià)很大的操作(實(shí)測(cè)中,線程切換大概需要幾十微秒),如果計(jì)算任務(wù)的執(zhí)行時(shí)間小于這個(gè)數(shù)字,那么多線程執(zhí)行對(duì)性能提升可能并無(wú)收益,甚至可能效率反而下降。
另一個(gè)問(wèn)題是任務(wù)執(zhí)行中數(shù)據(jù)的依賴關(guān)系。如果計(jì)算任務(wù)中某部分必須利用前面部分的計(jì)算結(jié)果,即存在數(shù)據(jù)依賴性,那么就必須等前面部分計(jì)算完成才能執(zhí)行后面的計(jì)算,而不可能并行計(jì)算。數(shù)據(jù)依賴是計(jì)算中經(jīng)常遇到的場(chǎng)景,編程設(shè)計(jì)需要調(diào)整代碼結(jié)構(gòu)盡量減少相關(guān)性提升并行性。












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論