 電子發燒友App
電子發燒友App


分支預測的英文名字是“Branch Prediction”,如果大家在Google上搜索這個關鍵字,可以看到關于分支預測的很多內容。不過,要搞清楚分支預測是如何工作的,才是問題的關鍵。
?
分支預測對程序的影響
??
下面,我們先來看兩段代碼。
?
代碼1:
?
#include?
?
執行結果:?
@ubuntu:/data/study$ g++ fenzhi.cpp && ./a.out
21.6046
sum = 314931600000
?
代碼2:?
#include?
?
執行結果:?
@ubuntu:/data/study$ g++ fenzhi.cpp && ./a.out
8.52157
sum = 314931600000
?
第一段代碼生成隨機數組后,沒有進行排序;第二段代碼對隨機的數組進行排序,執行的時間上發生了非常大的差異。?
究竟發生了什么事情?
??
導致他們結果不同的原因,就是分支預測。 ?簡單來說,分支預測是CPU處理器對程序的一種預測,和CPU架構有關系,現在的很多處理器都有分支預測的功能。 ?CPU在執行這段代碼的時候:?
if?(data[c] >= 128) sum += data[c];
?
CPU會有一個提前預測機制,比如前面的執行結果都是true,那么下一次在判斷if的時候,就會默認由true來處理,讓下面的幾條指令提前進入預裝。
?
當然,這個判斷不會影響實際的結果輸出,這個判斷只是為了讓CPU并行執行代碼。
?
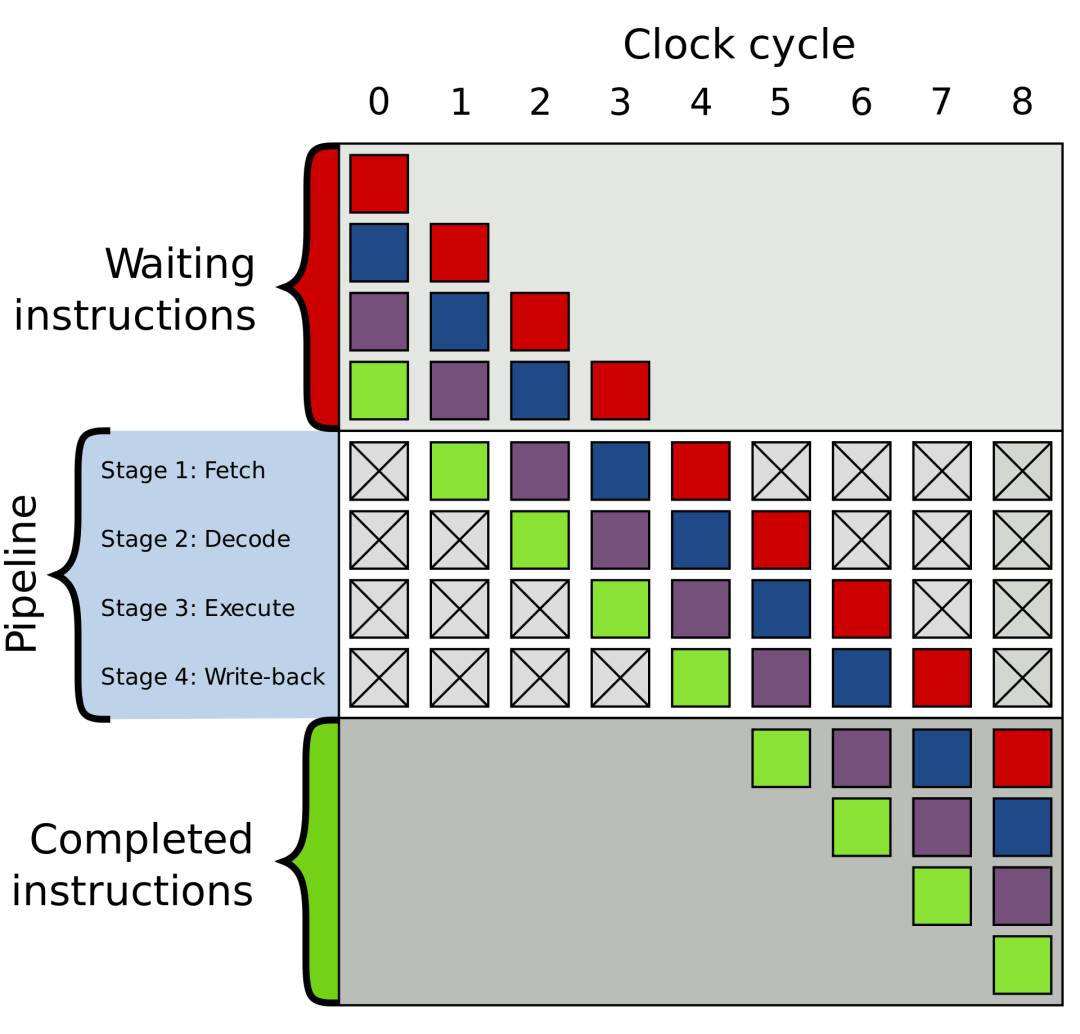
CPU執行一條指令分為幾個階段:
?

?
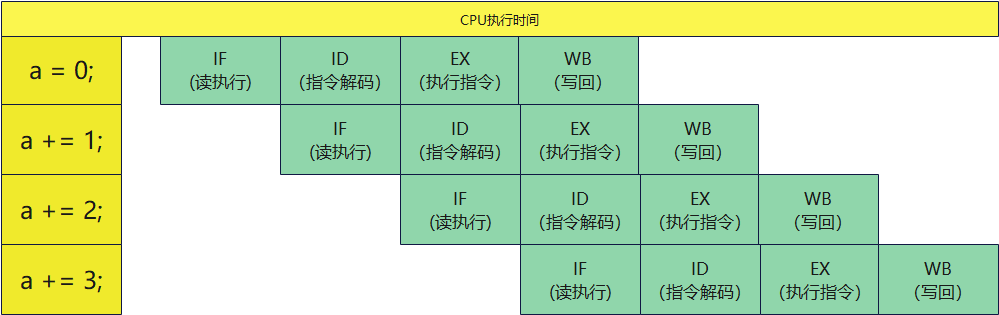
既然是分階段執行,也就是我們正常說的pipeline(流水線執行)。 ?流水線的工人只要完成自己負責的內容就好了,沒有必要去關心其他的人處理。 ?如果我有一段代碼,如下:?
int?a = 0;
a?+= 1;
a?+= 2;
a?+= 3;
?
?
?
從這個圖上我們可以看到,我們認為是在執行 a = 0結束后,才會執行a+=1。 ?但是實際CPU是在執行a=0的第一條執行后,馬上就去執行a+=1的第一條指令了。 ?也就因為這樣,執行速度上得到了大幅度的提升。?但對于if() 語言,在沒有分支預測的時候,我們需要等待if()執行出現結果后才能繼續執行下一個代碼。
?

?
如果存在分支預測的情況:?

?
通過比較我們可以發現,如果存在分支預測的時候,就讓執行速度變快了。?
?
?
如果預測失敗,會不會就影響了執行的時間?答案是肯定的。
?
在前面的例子中,沒有對數組排序的情況下,分支預測大部分都會是失敗的,這個時候就會在執行結束后重新取指令執行,會嚴重影響執行效率。
?
而在排序后的例子中,分支預測一直處于成功的狀態,CPU的執行速率得到大幅度的提升。
?
如何解決性能下降問題?
??
分支預測會存在一定的能性下降,想讓性能提升的方法,就是不要使用這個該死的if語句。
?
比如上面的代碼,我們可以修改成這樣:
?
#include?
?
比如,我們看到的絕對值代碼,里面也用了這樣的思想。
?
/**
?* abs - return absolute value of an argument
?* @x: the value. If it is unsigned type, it is converted to signed type first.
?* char is treated as if it was signed (regardless of whether it really is)
?* but the macro's return type is preserved as char.
?*
?* Return: an absolute value of x.
?*/
#define abs(x) __abs_choose_expr(x, long long,
????__abs_choose_expr(x, long,
????__abs_choose_expr(x, int,
????__abs_choose_expr(x, short,
????__abs_choose_expr(x, char,
????__builtin_choose_expr(
??????__builtin_types_compatible_p(typeof(x), char),
??????(char)({ signed?char?__x = (x); __x<0?-__x:__x; }),
??????((void)0)))))))
#define __abs_choose_expr(x, type, other) __builtin_choose_expr(
??__builtin_types_compatible_p(typeof(x), signed?type) ||
??__builtin_types_compatible_p(typeof(x), unsigned?type),
??({ signed?type __x = (x); __x < 0?? -__x : __x; }), other)
?
當然,你也可以這樣寫:
?
int?abs(int?i){
???if(i<0)
????return?~(--i);
??return?i;
}
?
所以說,計算機的盡頭是數學~
審核編輯:湯梓紅











 工商網監
工商網監
評論