 電子發(fā)燒友App
電子發(fā)燒友App


01 程序結(jié)構(gòu)優(yōu)化
1、程序的書寫結(jié)構(gòu) 雖然書寫格式并不會(huì)影響生成的代碼質(zhì)量,但是在實(shí)際編寫程序時(shí)還是應(yīng)該遵循一定的書寫規(guī)則,一個(gè)書寫清晰、明了的程序,有利于以后的維護(hù)。在書寫程序時(shí),特別是對于While、for、do…while、if…else、switch…case 等語句或這些語句嵌套組合時(shí),應(yīng)采用“縮格”的書寫形式。
2、標(biāo)識符 程序中使用的用戶標(biāo)識符除要遵循標(biāo)識符的命名規(guī)則以外,一般不要用代數(shù)符號(如a、b、x1、y1)作為變量名,應(yīng)選取具有相關(guān)含義的英文單詞(或縮寫)或漢語拼音作為標(biāo)識符,以增加程序的可讀性,如:count、number1、red、work 等。
3、程序結(jié)構(gòu) C 語言是一種高級程序設(shè)計(jì)語言,提供了十分完備的規(guī)范化流程控制結(jié)構(gòu)。因此在采用C 語言設(shè)計(jì)單片機(jī)應(yīng)用系統(tǒng)程序時(shí),首先要注意盡可能采用結(jié)構(gòu)化的程序設(shè)計(jì)方法,這樣可使整個(gè)應(yīng)用系統(tǒng)程序結(jié)構(gòu)清晰,便于調(diào)試和維護(hù)。
對于一個(gè)較大的應(yīng)用程序,通常將整個(gè)程序按功能分成若干個(gè)模塊,不同模塊完成不同的功能。各個(gè)模塊可以分別編寫,甚至還可以由不同的程序員編寫,一般單個(gè)模塊完成的功能較為簡單,設(shè)計(jì)和調(diào)試也相對容易一些。在C 語言中,一個(gè)函數(shù)就可以認(rèn)為是一個(gè)模塊。
所謂程序模塊化,不僅是要將整個(gè)程序劃分成若干個(gè)功能模塊,更重要的是,還應(yīng)該注意保持各個(gè)模塊之間變量的相對獨(dú)立性,即保持模塊的獨(dú)立性,盡量少使用全局變量等。對于一些常用的功能模塊,還可以封裝為一個(gè)應(yīng)用程序庫,以便需要時(shí)可以直接調(diào)用。但是在使用模塊化時(shí),如果將模塊分成太細(xì)太小,又會(huì)導(dǎo)致程序的執(zhí)行效率變低(進(jìn)入和退出一個(gè)函數(shù)時(shí)保護(hù)和恢復(fù)寄存器占用了一些時(shí)間)。
4、定義常數(shù) 在程序化設(shè)計(jì)過程中,對于經(jīng)常使用的一些常數(shù),如果將它直接寫到程序中去,一旦常數(shù)的數(shù)值發(fā)生變化,就必須逐個(gè)找出程序中所有的常數(shù),并逐一進(jìn)行修改,這樣必然會(huì)降低程序的可維護(hù)性。因此,應(yīng)盡量當(dāng)采用預(yù)處理命令方式來定義常數(shù),而且還可以避免輸入錯(cuò)誤。
5、減少判斷語句 能夠使用條件編譯(ifdef)的地方就使用條件編譯而不使用if 語句,有利于減少編譯生成的代碼的長度。
6、表達(dá)式 對于一個(gè)表達(dá)式中各種運(yùn)算執(zhí)行的優(yōu)先順序不太明確或容易混淆的地方,應(yīng)當(dāng)采用圓括號明確指定它們的優(yōu)先順序。一個(gè)表達(dá)式通常不能寫得太復(fù)雜,如果表達(dá)式太復(fù)雜,時(shí)間久了以后,自己也不容易看得懂,不利于以后的維護(hù)。
7、函數(shù) 對于程序中的函數(shù),在使用之前,應(yīng)對函數(shù)的類型進(jìn)行說明,對函數(shù)類型的說明必須保證它與原來定義的函數(shù)類型一致,對于沒有參數(shù)和沒有返回值類型的函數(shù)應(yīng)加上“void”說明。如果果需要縮短代碼的長度,可以將程序中一些公共的程序段定義為函數(shù)。如果需要縮短程序的執(zhí)行時(shí)間,在程序調(diào)試結(jié)束后,將部分函數(shù)用宏定義來代替。注意,應(yīng)該在程序調(diào)試結(jié)束后再定義宏,因?yàn)榇蠖鄶?shù)編譯系統(tǒng)在宏展開之后才會(huì)報(bào)錯(cuò),這樣會(huì)增加排錯(cuò)的難度。
8、盡量少用全局變量,多用局部變量 因?yàn)槿肿兞渴欠旁跀?shù)據(jù)存儲器中,定義一個(gè)全局變量,MCU 就少一個(gè)可以利用的數(shù)據(jù)存儲器空間,如果定義了太多的全局變量,會(huì)導(dǎo)致編譯器無足夠的內(nèi)存可以分配;而局部變量大多定位于MCU 內(nèi)部的寄存器中,在絕大多數(shù)MCU 中,使用寄存器操作速度比數(shù)據(jù)存儲器快,指令也更多更靈活,有利于生成質(zhì)量更高的代碼,而且局部變量所能占用的寄存器和數(shù)據(jù)存儲器在不同的模塊中可以重復(fù)利用。
9、設(shè)定合適的編譯程序選項(xiàng) 許多編譯程序有幾種不同的優(yōu)化選項(xiàng),在使用前應(yīng)理解各優(yōu)化選項(xiàng)的含義,然后選用最合適的一種優(yōu)化方式。通常情況下一旦選用最高級優(yōu)化,編譯程序會(huì)近乎病態(tài)地追求代碼優(yōu)化,可能會(huì)影響程序的正確性,導(dǎo)致程序運(yùn)行出錯(cuò)。因此應(yīng)熟悉所使用的編譯器,應(yīng)知道哪些參數(shù)在優(yōu)化時(shí)會(huì)受到影響,哪些參數(shù)不會(huì)受到影響。
02 代碼的優(yōu)化
1、選擇合適的算法和數(shù)據(jù)結(jié)構(gòu) 應(yīng)熟悉算法語言。將比較慢的順序查找法用較快的二分查找法或亂序查找法代替,插入排序或冒泡排序法用快速排序、合并排序或根排序代替,這樣可以大大提高程序執(zhí)行的效率。
選擇一種合適的數(shù)據(jù)結(jié)構(gòu)也很重要,比如在一堆隨機(jī)存放的數(shù)據(jù)中使用了大量的插入和刪除指令,比使用鏈表要快得多。數(shù)組與指針具有十分密切的關(guān)系,一般來說指針比較靈活簡潔,而數(shù)組則比較直觀,容易理解。對于大部分分的編譯器,使用指針比使用數(shù)組生成的代碼更短,執(zhí)行效率更高。
但是在Keil 中則相反,使用數(shù)組比使用的指針生成的代碼更短。
2、使用盡量小的數(shù)據(jù)類型 能夠使用字符型(char)定義的變量,就不要使用整型(int)變量來定義;能夠使用整型變量定義的變量就不要用長整型(long int),能不使用浮點(diǎn)型(float)變量就不要使用浮點(diǎn)型變量。當(dāng)然,在定義變量后不要超過變量的作用范圍,如果超過變量的范圍賦值,C 編譯器并不報(bào)錯(cuò),但程序運(yùn)行結(jié)果卻錯(cuò)了,而且這樣的錯(cuò)誤很難發(fā)現(xiàn)。
3、使用自加、自減指令 通常使用自加、自減指令和復(fù)合賦值表達(dá)式(如a-=1 及a+=1 等)都能夠生成高質(zhì)量的程序代碼,編譯器通常都能夠生成inc 和dec 之類的指令,而使用a=a+1 或a=a-1之類的指令,有很多C 編譯器都會(huì)生成2~3個(gè)字節(jié)的指令。
4、減少運(yùn)算的強(qiáng)度 可以使用運(yùn)算量小但功能相同的表達(dá)式替換原來復(fù)雜的的表達(dá)式。如下:
(1)求余運(yùn)算
a=a%8;
可以改為:
a=a&7;
說明:位操作只需一個(gè)指令周期即可完成,而大部分的C 編譯器的“%”運(yùn)算均是調(diào)用子程序來完成,代碼長、執(zhí)行速度慢。通常,只要求是求2n 方的余數(shù),均可使用位操作的方法來代替。
(2)平方運(yùn)算
a=pow(a,2.0);
可以改為:
a=a*a; 說明:在有內(nèi)置硬件乘法器的單片機(jī)中(如51 系列),乘法運(yùn)算比求平方運(yùn)算快得多,因?yàn)楦↑c(diǎn)數(shù)的求平方是通過調(diào)用子程序來實(shí)現(xiàn)的,在自帶硬件乘法器的AVR 單片機(jī)中,如ATMega163 中,乘法運(yùn)算只需2 個(gè)時(shí)鐘周期就可以完成。即使是在沒有內(nèi)置硬件乘法器的AVR單片機(jī)中,乘法運(yùn)算的子程序比平方運(yùn)算的子程序代碼短,執(zhí)行速度快。如果是求3 次方,如: a=pow(a,3.0);
更改為:
a=a*a*a; 則效率的改善更明顯。
(3)用移位實(shí)現(xiàn)乘除法運(yùn)算
a=a*4;
b=b/4;
可以改為:
a=a《《2;
b=b》》2; 說明:通常如果需要乘以或除以2n,都可以用移位的方法代替。在ICCAVR 中,如果乘以2n,都可以生成左移的代碼,而乘以其它的整數(shù)或除以任何數(shù),均調(diào)用乘除法子程序。用移位的方法得到代碼比調(diào)用乘除法子程序生成的代碼效率高。實(shí)際上,只要是乘以或除以一個(gè)整數(shù),均可以用移位的方法得到結(jié)果,如:
a=a*9
可以改為:
a=(a《《3)+a
5、循環(huán)
(1)循環(huán)語對于一些不需要循環(huán)變量參加運(yùn)算的任務(wù)可以把它們放到循環(huán)外面,這里的任務(wù)包括表達(dá)式、函數(shù)的調(diào)用、指針運(yùn)算、數(shù)組訪問等,應(yīng)該將沒有必要執(zhí)行多次的操作全部集合在一起,放到一個(gè)init 的初始化程序中進(jìn)行。
(2)延時(shí)函數(shù) 通常使用的延時(shí)函數(shù)均采用自加的形式:
void delay (void){unsigned int i;for (i=0;i《1000;i++); }將其改為自減延時(shí)函數(shù):void delay (void){unsigned int i;for (i=1000;i》0;i--); }
兩個(gè)函數(shù)的延時(shí)效果相似,但幾乎所有的C 編譯對后一種函數(shù)生成的代碼均比前一種代碼少1~3 個(gè)字節(jié),因?yàn)閹缀跛械腗CU 均有為0轉(zhuǎn)移的指令,采用后一種方式能夠生成這類指令。在使用while 循環(huán)時(shí)也一樣,使用自減指令控制循環(huán)會(huì)比使用自加指令控制循環(huán)生成的代碼更少1~3 個(gè)字母。
但是在循環(huán)中有通過循環(huán)變量“i”讀寫數(shù)組的指令時(shí),使用預(yù)減循環(huán)時(shí)有可能使數(shù)組超界,要引起注意。
(3)while 循環(huán)和do…while 循環(huán) 用while 循環(huán)時(shí)有以下兩種循環(huán)形式:
unsigned int i;i=0;while (i《1000){i++; //用戶程序}或:unsigned int i;i=1000;do{i--; //用戶程序}while (i》0);
在這兩種循環(huán)中,使用do…while循環(huán)編譯后生成的代碼的長度短于while循環(huán)。
6、查表 在程序中一般不進(jìn)行非常復(fù)雜的運(yùn)算,如浮點(diǎn)數(shù)的乘除及開方等,以及一些復(fù)雜的數(shù)學(xué)模型的插補(bǔ)運(yùn)算,對這些即消耗時(shí)間又消費(fèi)資源的運(yùn)算,應(yīng)盡量使用查表的方式,并且將數(shù)據(jù)表置于程序存儲區(qū)。如果直接生成所需的表比較困難,也盡量在啟動(dòng)時(shí)先計(jì)算,然后在數(shù)據(jù)存儲器中生成所需的表,后面在程序運(yùn)行直接查表就可以了,減少了程序執(zhí)行過程中重復(fù)計(jì)算的工作量。
7、其它 比如使用在線匯編及將字符串和一些常量保存在程序存儲器中,均有利于優(yōu)化。
03 乘除法優(yōu)化
目前單片機(jī)的市場競爭很激烈,許多應(yīng)用出于性價(jià)比的考慮,選擇使用程序存儲空間較小(如1K,2K)的小資源8位MCU芯片進(jìn)行開發(fā)。一般情況下,這類MCU沒有硬件乘法、除法指令,在程序必須使用乘除法運(yùn)算時(shí),如果單純依靠編譯器調(diào)用內(nèi)部函數(shù)庫來實(shí)現(xiàn),常常會(huì)有代碼量偏大、執(zhí)行效率偏低的缺點(diǎn)。
上海晟矽微電子推出的MC30、MC32系列MCU,采用了RISC架構(gòu),在小資源8位MCU領(lǐng)域有廣大的用戶群和廣泛的應(yīng)用,本文就以晟矽微電的這兩個(gè)系列產(chǎn)品的指令集為例,結(jié)合匯編與C編譯平臺,給大家介紹一種即省時(shí)又節(jié)約資源的乘除法算法。
1、乘法篇 單片機(jī)中的乘法是二進(jìn)制的乘法,也就是把乘數(shù)的各個(gè)位與被乘數(shù)相乘,然后再相加得出,因?yàn)槌藬?shù)和被乘數(shù)都是二進(jìn)制,所以實(shí)際編程時(shí)每一步的乘法可以用移位實(shí)現(xiàn)。
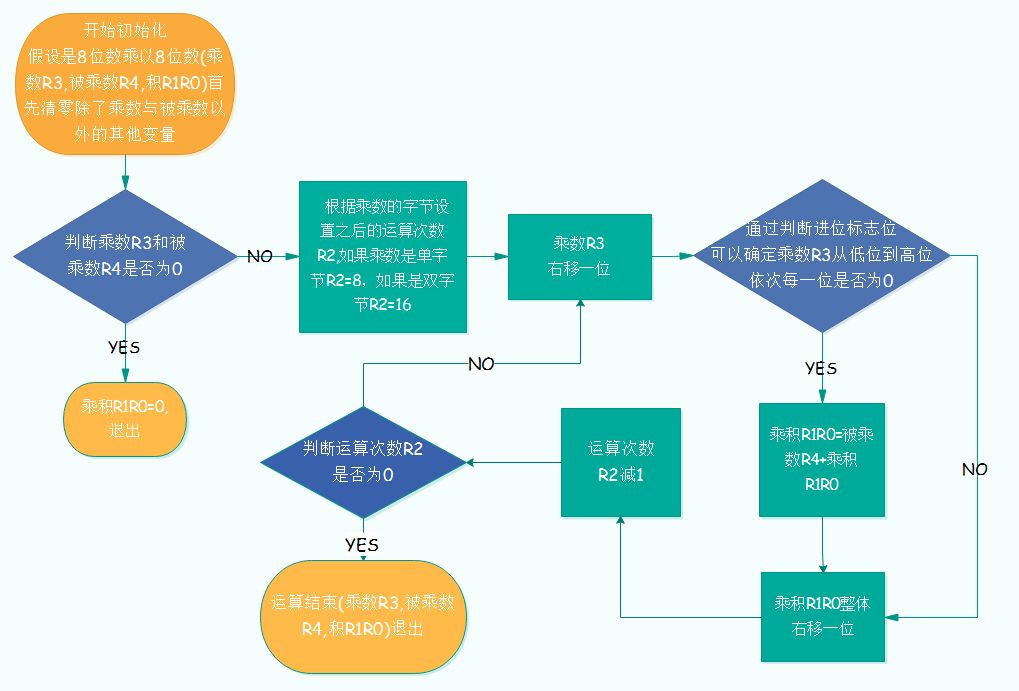
例如:乘數(shù)R3=01101101,被乘數(shù)R4=11000101,乘積R1R0。步驟如下:
1、清空乘積R1R0;
2、乘數(shù)的第0位是1,那被乘數(shù)R4需要乘上二進(jìn)制數(shù)1,也就是左移0位,加到R1R0里;
3、乘數(shù)的第1位是0,忽略;
4、乘數(shù)的第2位是1,那被乘數(shù)R4需要乘上二進(jìn)制數(shù)100,也就是左移2位,加到R1R0里;
5、乘數(shù)的第3位是1,那被乘數(shù)R4需要乘上二進(jìn)制數(shù)1000,也就是左移3位,加到R1R0里;
6、乘數(shù)的第4位是0,忽略;
7、乘數(shù)的第5位是1,那被乘數(shù)R4需要乘上二進(jìn)制數(shù)100000,也就是左移5位,加到R1R0里;
8、乘數(shù)的第6位是1,那被乘數(shù)R4需要乘上二進(jìn)制數(shù)1000000,也就是左移6位,加到R1R0里;
9、乘數(shù)的第7位是0,忽略;
10、這時(shí)候R1R0里的值就是最后的乘積,至此算法完成。
以上例子運(yùn)算結(jié)果:
R1R0 = R3 * R4= (R4《《6)+(R4《《5)+(R4《《3)+(R4《《2)+R4 = 101001111100001
實(shí)際運(yùn)算流程圖見下圖:
在實(shí)際的程序設(shè)計(jì)過程中,程序優(yōu)化有兩個(gè)目標(biāo),提高程序運(yùn)行效率,和減少代碼量。我們來看下本文提供的匯編算法和普通C語言編程的效率和代碼量對比。
表1.1是程序運(yùn)行效率的對比數(shù)據(jù)(可能會(huì)有小的偏差),很明顯匯編編譯出來的運(yùn)行時(shí)間要比C語言減少很多。
匯編(時(shí)鐘周期)
C語言(時(shí)鐘周期)
8*8位乘法
79-87
184-190
16*8位乘法
201-210
362-388
16*16位乘法
234-379
396-468
表1.1 乘法運(yùn)算時(shí)鐘周期對比表 表1.2是程序代碼量的對比數(shù)據(jù)(可能會(huì)有小的偏差),匯編占用的程序空間也要比C語言小很多。
匯編(Byte)
C語言(Byte)
8*8位乘法
15
34
16*8位乘法
19
96
16*16位乘法
31
96
表1.2 乘法運(yùn)算ROM空間使用情況對比表 綜上兩點(diǎn),本文介紹的乘法算法各方面使用情況都要比C編譯好很多。如果大家在使用過程中,原有的程序不能滿足應(yīng)用需求,例如遇到程序空間不夠或者運(yùn)行時(shí)間太久等問題,都可以按照以上方式進(jìn)行優(yōu)化。 匯編語言最接近機(jī)器語言的。在匯編語言中可以直接操作寄存器,調(diào)整指令執(zhí)行順序。由于匯編語言直接面對硬件平臺,而不同的硬件平臺的指令集及指令周期均有較大差異,這樣會(huì)對程序的移植和維護(hù)造成一定的不便,所以我們針對精簡指令集做了乘法運(yùn)算的例程,便于大家的移植和理解。




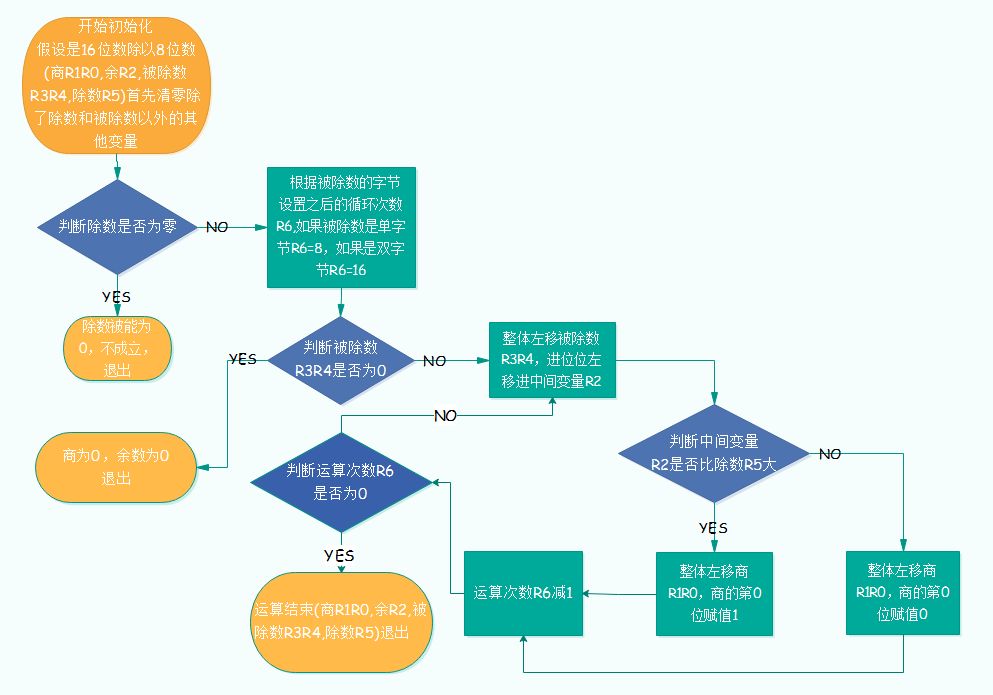
2、除法篇 單片機(jī)中的除法也是二進(jìn)制的除法,和現(xiàn)實(shí)中數(shù)學(xué)的除法類似,是從被除數(shù)的高位開始,按位對除數(shù)進(jìn)行相除取余的運(yùn)算,得出的余數(shù)再和之后的被除數(shù)一起再進(jìn)行新的相除取余的運(yùn)算,直到除不盡為止,因?yàn)閱纹瑱C(jī)中的除法是二進(jìn)制的,每個(gè)步驟除出來的商最大只有1,所以我們實(shí)際編程時(shí)可以把每一步的除法看作減法運(yùn)算。 例如:被除數(shù)R3R4=1100110001101101,除數(shù)R5=11000101,商R1R0,余數(shù)R2。步驟如下:
1、清空商R1R0,余數(shù)R2; 2、被除數(shù)放開最高位,第15位,為1,1比除數(shù)小,商為0,余數(shù)R2為1; 3、上一步余數(shù)并上被除數(shù)次高位,第14位,得11,11仍然比除數(shù)小,商為0,余數(shù)R2為11 4、直到放開第8位后,得11001100,比除數(shù)大,商得1,余數(shù)R2為111; 5、上一步余數(shù)并上被除數(shù)第7位,得1110,沒有除數(shù)大,商為0,余數(shù)R2為1110; 6、上一步余數(shù)并上被除數(shù)第6位,得11101,沒有除數(shù)大,商為0,余數(shù)R2為11101; 7、按照以上步驟,直到放開了被除數(shù)得第3位,得11101101,比除數(shù)大,商為1,余數(shù)R2為101000; 8、上一步余數(shù)并上被除數(shù)第2位,得1010001,沒有除數(shù)大,商為0,余數(shù)R2為1010001; 9、上一步余數(shù)并上被除數(shù)第1位,得10100010,沒有除數(shù)大,商為0,余數(shù)R2為10100010; 10、上一步余數(shù)并上被除數(shù)第0位,得101000101,比除數(shù)大,商為1,余數(shù)R2為10000000; 11、然后把以上所有步驟中得商從左至右依次排列就是最后的商100001001,余數(shù)為最后算得的余數(shù)10000000。 以上例子運(yùn)算結(jié)果:R1R0 = R3R4 / R5 = 100001001 ;R2 = R3R4 % R5 = 10000000 實(shí)際運(yùn)算流程圖見下圖:
除法運(yùn)算的效率,代碼量見以下表格 表2.1是程序運(yùn)行效率和代碼量的對比數(shù)據(jù)(可能會(huì)有小的偏差),很明顯本文提供的匯編算法要優(yōu)化的很多。
16/8位除法
匯編
C語言
時(shí)鐘周期
287-321
740-804
使用空間(Byte)
35
142
表2.1 除法運(yùn)算時(shí)鐘周期對比表 所以對于除法運(yùn)算,本文提供的方法也是相對較優(yōu)的。 以下是針對精簡指令集做的除法運(yùn)算,16/8位的例程,便于大家的移植和理解。


編輯:黃飛









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論