 電子發燒友App
電子發燒友App


本文將介紹一些優化技術,幫助設計人員節約多達 10% 的代碼空間,從而讓容量有限的程序存儲器支持更多新特性和補丁。
良好的操作方法
許多程序員在 32 位處理器上學習編寫軟件,如 Intel 的 Pentium 處理器或某種 ARM 平臺。不過,嵌入式領域的軟件編寫需要不同的思路。在 32 位 CPU 上,存儲比特位的最佳方法通常是使用 32 位變量。對 8 位處理器而言,最好的辦法就是采用單字節。像增強型 8051s 等某些處理器可能提供特殊的 1 位變量。
嵌入式處理器通常會超出標準的哈佛架構將存儲器分散到不同的存儲器空間中,有的相互重疊,有的又是相互分離。例如,8051 中常見的存儲器空間包括 CODE、XDATA、DATA、IDATA、BIT 以及寄存器等。當要決定在何處存放變量時,了解每個存儲器空間的優缺點顯得非常重要,特別是在各個存儲空間的容量都有限時更是如此。例如,IDATA 空間可能只能運行 256 個字節,不過它為間接存取進行了優化。雖然 DATA 空間也只能運行 256 個字節,但它包括了 位可尋址空間和寄存器。盡管 CODE 和 XDATA 只能通過慢速間接存取機制進行訪問,但它們的尋址空間卻高達 64K。
許多 8 位 CPU 的編譯器包含了很多優化程序,不過,這些優化程序都有其局限性。如果可以,應該盡可能簡化表達。例如下面這段代碼:
X = a * CONSTANT1;
X *= CONSTANT2;
通常要比下述代碼多占空間:
X = a * CONSTANT1* CONSTANT2;
因為編譯器能將兩個常量合并為一個。
優化——三思而后行
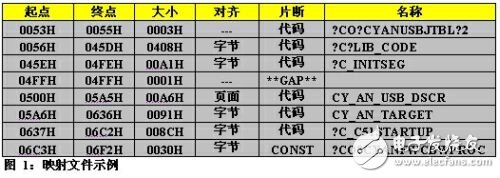
經驗豐富的木匠都知道做事應該事先作好計劃,三思而后行。嵌入式固件工程師也應該遵循這一原則。所有嵌入式編譯器都提供了一個可給出有用信息映射文件。如圖 1 所示,該映射文件提供了本文所用代碼示例的有用信息。圖中所示的庫 (LIB_CODE) 使用的空間超過了 1K,而且啟動代碼 (c51startup) 使用的代碼超過了 140 字節。
進行優化的另一原因是可以節約時間。在優化之前,衡量程序的性能尤為重要。顯而易見,如果源文件過大,肯定會占用大量的存儲器空間,但我們很難測定代碼的哪些關鍵部分在消耗寶貴的 MIPS。在此過程中,我們可將程序概要分析 (Profiling) 作為一個重要的工具來加以利用。
我們可利用未使用的單一輸出引腳來進行程序概要分析,不過輸出引腳越多,分析也就越容易。我們可創建一個宏來設置程序概要分析輸出,如下所示,再將宏放在每個例程的起點和終點處。
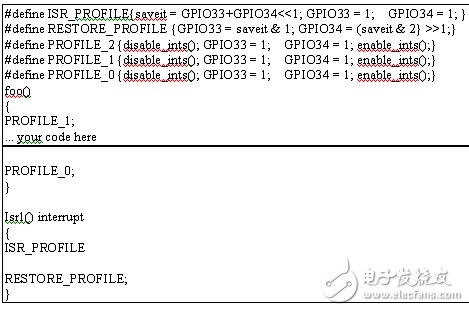
了解支付情況
在上述的映射文件中,我們了解到庫占用了 1K 的寶貴存儲器空間。深入查看映射文件,通過 Excel 進行分析后得到了如圖 2 所示的結果。我們從圖中移出較小的庫函數部分。盡管這些函數名稱比較晦澀,不過我們可以對照庫參考資料逐一了解其含義。首先,ULDIV 是指無符號數的長除法 (long division),而圖中第二個則是指長乘法 (long multiplication)。
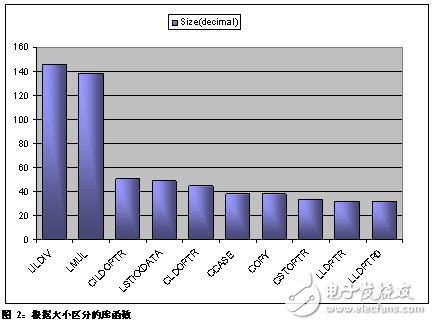
.map 文件的交叉參考表明我們很幸運:上述函數只用于一個文件中。.lst 文件顯示了長除法函數的兩種使用情況以及長乘法函數的一種使用情況
glNandDevCapacity = CYAN_NAND_DEV_NUMPAGES_BLOCK * CYAN_NAND_UBLKS_PER_ZONE * (uint32_t)glNandNumZones;
在該特定案例中,我們知道 zone 的數量是一個二進制數,而另兩個值為常量。因此,我們可用重復 8 次的左移位 (left shift) 操作替代長乘法:

盡管這個例程相當大,但它仍能減少庫的使用并減小代碼的整體大小。
掌握比編輯器更多的信息
成熟的 8 位編譯器包括代碼編寫良好、經過優化的庫函數。不過,這些函數須考慮到通過對數據的了解可自行處理的一些不常見情況。映射文件中顯示的最大庫函數就是這樣一個很好的例子。調用兩次 ULDIV 例程,以獲得輸入值除以常量后得到的除數和余數:
zn = (adj_lba / CYAN_NAND_UBLKS_PER_ZONE);
glNandRelativeBlkAddr = (adj_lba % CYAN_NAND_UBLKS_PER_ZONE);
由于我們在預期值方面比編譯器了解的更多,因此我們可以讓編譯器不使用龐大的長除法函數,而采用較小的 16 位版本來替代。

激進的的程序優化者甚至可能實現他們自己的二進制長除法例程。
全局變量更好用
將參數傳遞給函數是一個很好的代碼經驗。在 C 程序中,編譯器可絕對確保調用的子程序不會修改參數。編譯器可處理存儲器管理的問題。不過,這將占用難以承受的大量時間和空間。試考慮下面這段代碼:

由于變量在 main() 中已經聲明,因此該變量與真正的全局變量之間的真正差別是命名空間 (namespace)。但是,每次調用 foo() 時,編譯器都必須在新的位置存儲 effectiveGlobal。聲明真正的全局變量有助于降低因調用而造成的代碼和數據開銷。
向編譯器提供盡可能多的信息
8051 可提供 64K 的地址空間 XDATA、256 字節的堆棧與間接尋址空間 IDATA 以及 256 字節的直接尋址空間 DATA 等多個存儲器空間。在大多數情況下,代碼編寫人員都知道指針指向了哪個存儲器空間。如果用戶指定了存儲器空間,編譯器就無需包含對例程中的所有三類存儲器進行尋址的代碼,只需使用一個即可。由于指針無需包含數據空間信息,因此有助于節約數據空間。
在我的 8051 編譯器中,上述變量可通過包含 OPTR 字符串的庫例程進行存取。在列表和庫文件中搜索對OPTR的引用可以發現長變量被多次使用,而且由于在代碼中假定了指針的大小,其中某些長變量還會導致一些問題。
在變量聲明中使用 const 關鍵詞可以實現兩方面的優化:第一,編譯器不必再存儲變量的初始值;第二,編譯器能在編譯時間而非執行時間執行一些數學運算。查看示例程序的編譯輸出,以確定對 const與 #define 的處理是否真的一樣。以下是我對代碼的測試:
經過測試,得到以下輸出,表明它并不清楚 const 變量的值。

匯編語言
不少嵌入式固件工程師信誓旦旦的表示他們始終能比編譯器做得更好,不僅如此,他們還認為應該使用匯編語言重新編寫所有代碼。然而事實上,現代編譯器提供的許多特性已經能趕上人腦的水平了。
變量共享:一些 8 位處理器尚無有效的機制來存取堆棧上的變量。一般的解決方案是創建調用樹,并在相互不進行調用的函數間共享變量。在匯編程序中要想保持這種結構相當困難,且容易出錯。
可靠性:任何從事專業軟件或固件開發工作的人員都能讀懂 C 語言程序。如果您需要將代碼交給其它開發人員處理,他們無需掌握那些為發揮匯編語言的最大效率而需要的所有技巧便可立即開始修改代碼。
可移植性:C 語言最初的開發目的之一就是要提供一種非常抽象,以便可以在多種處理器上應用的語言。這一目標至今仍然非常重要。
代碼共享:許多 8 位編譯器都能在鏈接時間之后進行優化,這使得編譯器不僅能執行許多人工能完成的優化,而且還能完成一些人工所不能完成的優化。例如,現在許多編譯器都能搜索不同函數 中 共 有的代碼字符串,并將其合并為一個新的函數。而人類是不可能記住每個編譯周期中執行此函數所需要的全部細節的。
匯編語言現在仍占有一席之地。不過,在使用匯編語言之前應首先考慮上述所有因素。
結論
在撰寫本文的過程中,我將成熟程序的大小從 0x6000 多字節縮減到了 0x5f2b 字節,節約了 200 多字節。該程序過去曾是多次試圖優化程序大小的目標。











 工商網監
工商網監
評論