 電子發燒友App
電子發燒友App


嵌入式軟件開發如果具有更好的閱讀性、擴展性以及維護性,就需要考慮很多因素。今天給大家分享幾個嵌入式軟件設計的原則。
1 設計原則
SRP 單一職責原則 Single Responsibility Principle 每個函數或者功能塊只有一個職責,只有一個原因會使其改變。
OCP 開放一封閉原則 The Open-Closed Principle 對于擴展是開放的,對于修改是封閉的。
DIP 依賴倒置原則 Dependency Inversion Principle 高層模塊和低層模塊應該依賴中間抽象層(即接口),細節應該依賴于抽象。
ISP 接口隔離原則 Interface Segregation Principle 接口盡量細化,同時方法盡量少,不要試圖去建立功能強大接口供所有依賴它的接口去調用。
LKP 最少知道原則 ?Least Knowledge Principle 一個子模塊應該與其它模塊保持最少的了解。
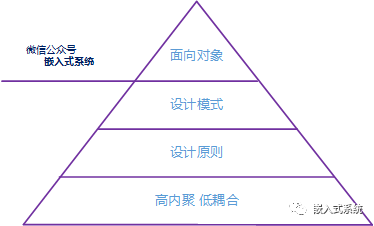
2 單一職責原則 (SRP)
函數或功能應該僅有一個引起它變化的原因。單一職責原則是最簡單但又最難運用的原則,需要按職責分割大模塊,如果一個子模塊承擔的職責過多,就等于把這些職責耦合在一起,一個職責的變化可能會削弱或抑制這個模塊完成其他職責的能力。劃分依據是影響它改變的只有一個原因,并不是單純理解的一個模塊只實現一個功能,對函數層面也是如此。
2.1 什么是職責
在 SRP 中把職責定義為“變化的原因”(a reason for change),如果有可能存在多于一個的動機去改變一個子模塊,表明這個模塊就具有多個職責。有時很難注意到這點,習慣以組的形式去考慮職責。例如Modem 程序接口,大多數人會認為這個接口看起來非常合理。
//interface?Modem?違反?SRP void?connect(); void?disconnect(); void?send(); void?recv();
然而,該接口中卻顯示出兩個職責。第一個職責是連接管理,第二個職責是數據通信,connect和 disconnect函數進行調制解調器的連接處理,send 和 recv函數進行數據通信。
這兩個職貴應該被分開嗎?這依賴于應用程序變化的方式。如果應用程序的變化會影響連接函數,如外設與主機熱插拔,連接后是數據收發,則需要分開。如果是socket,其本身連接狀態與數據交互是綁定的關系,應用程序的變化總是導致這兩個職責同時變化,那沒必分離它們,強行分割反而會引入復雜性。
2.2 分離耦合
多個職責耦合不是所希望的,但有時無法避免,有些和硬件或操作系統有關的原因,迫使把不愿耦合在起的東西耦合在一起。然而,對于應用部分來說應當盡量分離解耦。軟件前期模塊設計真正要做的許多內容,就是發現職責并把那些職責相互分離。
3 開放-封閉原則 (OCP)
如果期望開發的軟件不會在第一版后就被拋棄,就必須牢牢地記住這點。那怎樣的設計才能面對需求改變卻可以保持相對穩定,從而使得系統可以在第一個版本以后不斷推出新的版本呢?開放-封閉原則為我們提供了指引。
軟件實體(模塊、函數等)應該是可以擴展的,但是不可修改的。如果程序中的一處改動會產生連鎖反應,導致相關模塊的改動,那么設計就具有僵化性的臭味。OCP 建議應該對系統進行重構,這樣以后對系統再進行那樣的改動時,就只需要添加新的代碼,而不必改動已經正常運行的代碼。
3.1 特性
開放-封閉原則設計出的模塊具有兩個主要的特征。
對于護展是開放的 (Open ?for ?extension)
模塊的行為是可以擴展的,當應用需求改變時,可以對模塊進行擴展,使其滿足新需求。
對于更改是封閉的(Closed ? for ? modificaiton)
模塊的源代碼是不能被侵犯的,不允許修改已有源代碼。
兩個特征看似互相矛盾,擴展模塊行為的通常方式就是修改該模塊的源代碼,不允許修改的模塊常常都被認為是具有固定的行為。怎樣可能在不改動模塊源代碼的情況下去更改它的行為呢?關鍵是抽象。
3.2 抽象隔離
在 C++等面向對象設計技術時,可以創建出固定卻能夠描述一組任意個可能行為的抽象體,這個抽象體就是抽象基類,而這一組任意個可能的行為則表現為可能的派生類。模塊可以操作抽象體,由于模塊依賴于一個固定的抽象體,所以它對于更改可以是關閉的。同時通過從這個抽象體派生,也可以擴展此模塊的行為。
面向對象的語言多態特性很容易實現,而嵌入式的C該如何呢?一個函數接口或功能,不要直接固化相關邏輯,而是把具體實現細節對外開放可擴展的,便于后期添加功能,且不影響其它的功能。
3.3 違反 OCP
一個應用程序需要在窗口上繪制圓形(Circle)和方形(Square),圓形和方形會被創建在同一個列表中,并保持適當的順序,程序按順序遍歷列表并繪制所有的圓形和方形。
如果使用C語言,并采用不遵循OCP的過程化方法,一組數據結構,它的第一個成員都相同,但是其余的成員都不同。每個結構中的第一個成員都是一個用來標識該結構是代表圓或方形的類型碼。DrawAllShapes 函數遍歷數組,該數組的元素是指向這些數據結構的指針,根據類型碼調用對應的函數 (DrawCircle 或 DrawSquare)。
typedef?enum
{
????CIRCLE,
????SQUARE,
}?ShapeType;
typedef?struct
{
????ShapeType?itsType;
}?Shape;
typedef?struct
{
????double?x;
????double?y;
}?Point;
typedef?struct
{
????ShapeType?itsType;
????double?itsSide;
????Point?itsTopLeft;
}?Square;
typedef?struct
{
????ShapeType?itsType;
????double?itsRadius;
????Point?itsCenter;
}?Circle;
void?DrawSquare(struct?Square*);
void?DrawCircle(struct?Circle*);
void?DrawAllShapes(Shape?**list,?int?n)
{
????int?i;
????Shape*?s;
????for(i?=?0;?i?itsType)
????????{
????????????case?SQUARE:
????????????????DrawSquare((struct?Square*)s);
????????????????break;
????????????case?CIRCLE:
????????????????DrawCircle((struct?Circle*)s);
????????????????break;
????????}
????}
}
DrawAllShapes 函數不符合 OCP,如果希望函數能夠繪制包含有三角形的列表,就必須得更改這個函數,擴展switch增加三角形。事實上,每增加一種新的形狀類型,都必須要更改這個函數。在這樣的應用程序中增加一種新的形狀類型,就意味著要找出所有包含上述 switch(或 if else 語句)的函數,在每一處都添加對新增的形狀類型的判斷。
在嵌入式數據流中,數據解析是常見情景,如果新手開發,可能是一個萬能長函數完成全部解析功能。比如不同類型的數據解析錯誤樣例:
typedef?int?int32_t;
typedef?short?int16_t;
typedef?char?int8_t;
typedef?unsigned?int?uint32_t;
typedef?unsigned?short?uint16_t;
typedef?unsigned?char?uint8_t;
#define?NULL?((void?*)(0))
//違反OCP的樣例
不同類型的數據集中在一起,使用switch-case處理,與前面DrawAllShapes一樣,后續擴展會影響既有函數。
int16_t?cmd_handle_body_v1(uint8_t?type,?uint8_t?*data,?uint16_t?len)
{
????switch(type)
????{
????????case?0:
????????????//handle0
????????????break;
????????case??1:
????????????//handle1
????????????break;
????????default:
????????????break;
????}
????return?-1;
}
3.4 遵循 OCP
上面的數據解析樣例調整后:
//遵守OCP原則
typedef?int16_t?(*cmd_handle_body)(uint8_t?*data,?uint16_t?len);
typedef?struct
{
????uint8_t?type;
????cmd_handle_body?hdlr;
}?cmd_handle_table;
static?int16_t?cmd_handle_body_0(uint8_t?*data,?uint16_t?len)
{
????//handle0
????return?0;
}
static?int16_t?cmd_handle_body_1(uint8_t?*data,?uint16_t?len)
{
????//handle1
????return?0;
}
//擴展新指令只需要在這里加上就行,不會影響先前的
static?cmd_handle_table?cmd_handle_table_map[]?=
{
????{0,?cmd_handle_body_0},
????{1,?cmd_handle_body_1}
};
int16_t?handle_cmd_body_v2(uint8_t?type,?uint8_t?*data,?uint16_t?len)
{
????int16_t?ret=-1;
????uint16_t?i?=?0;
????uint16_t?size?=?sizeof(cmd_handle_table_map)?/?sizeof(cmd_handle_table_map[0]);
????for(i?=?0;?i?
雖然不如C++抽象與多態,但整體實現了OCP的效果,在不修改handle_cmd_body_v2的情況下,擴展cmd_handle_table_map。這個模式其實是通用的表驅動法。
3.5 策略性的閉合
上面的例子其實并非是100%封閉。一般而言,無論模塊是多么的“開放-封閉”,都會存在一些無法對之封閉的變化,沒有對所有的情況都貼切的模型。既然不可能完全封閉,那么就必須有策略地對待這個問題。也就是說,設計人員必須對模塊應該對哪種變化封閉做出選擇。必須先預估最有可能發生的變化,然后構造隔離這些變化,這需要設計人員具備一些行業經驗及預測能力。
遵循OCP 的代價也是昂貴的,肆無忌憚的從軟件角度進行抽象隔離,創建抽象隔離要花費開發時間和代碼空間,同時也增加了軟件設計的復雜性。比如前面handle_cmd_body_v1比handle_cmd_body_v2,如果明確需求或者硬件資源緊缺,后者從設計原則角度更合理,但前者更直接且符合資源緊缺且需求固定的場景。對于嵌入式軟件應該對程序中頻繁變化的部分提取抽象。
4 依賴倒置原則 (DIP)
依賴倒置原則即高層模塊(調用者)不依賴于低層模塊(被調用者),二者都應該依賴于抽象。
結構化程序分析和設計,總是傾向于創建高層模塊依賴低層模塊,策略依賴于細節的結構,這是大部分嵌入式軟件的結構,從業務層到組件層,再到驅動層,自頂向下的設計思維。良好的面向對象的程序,其依賴結構相對于傳統的過程式方法設計的結構而言就是被“倒置”了。
高層模塊依賴于低層模塊,意味著低層模塊的改動會直接影響到高層模塊,從而迫使它們依次做出改動,在不同的上下文中重用高層模塊就會變得困難。
4.1 倒置的接口所有權
“Don't ?call ?us,we'll ?call ?you.”(不要調用我們,我們會調用你),低層模塊實現在高層模塊中聲明并被高層模塊調用的接口,也就是低層模塊按高層模塊的需求來實現功能。通過這種倒置的接口所有權,滿足高層在任何上下文的重用。事實上,即使是嵌入式軟件,開發的重點是隨時變化的高層模塊,一般都是相似的上層應用軟件在不同的硬件環境運行,所以高層的復用更能提高軟件質量。
4.2 樣例對比
假設控制熔爐調節器的軟件,從外界通道中讀取當前的溫度,并通過向另一個通道發送命令來控制熔爐加熱的開或關。按數據流的結構大概如下:
//溫度調節器的調度算法
//檢測到當前溫度在設定范圍外,開啟或關閉熔爐的加熱器
void?temperature_regulate(int?min_temp,?int?max_temp)
{
????int?tmp;
????while(1)
????{
????????tmp?=?read_temperature();//讀取溫度
????????if(tmp??max_temp)
????????{
????????????furnace_disable();//停止加熱
????????}
????????wait();
????}
}
算法的高層意圖是清楚的,但是實現代碼中卻夾雜著低層細節。導致這段代碼(控制算法)根本不能重用于不同的硬件,只是代碼很少,算法實現容易,看起來不會造成太大的損害。如果一個復雜的溫度控制算法,需要移植到不同平臺,或者需求改變,要求在溫度異常時發出額外警示呢?
void?temperature_regulate_v2(Thermometers?*t,Heaterk?*h,int?min_temp,?int?max_temp)
{
????int?tmp;
????while(1)
????{
????????tmp?=?t->read();
????????if(tmp?enable();
????????}
????????else?if(tmp?>?max_temp)
????????{
????????????h->disable();
????????}
????????wait();
????}
}
這就倒置了依賴關系,使得高層的調節策略不再依賴于任何溫度計或者熔爐的特定細節。該算法具有較好的可重用性,算法不依賴細節。
依賴倒置尤其可以解決嵌入式軟件中硬件頻繁變更對軟件復用帶來的問題。比如運動手環的計步器,在面向過程的開發按從高到低的調用關系,如果后續因為物料等原因更換加速度傳感器,則會導致上層必須修改,尤其是沒有內部封裝,應用層直接調用驅動接口的方式,需要逐個替換。如果后續不確定傳感器可能用哪顆,軟件需要根據傳感器特性自動調整,則需要大量switch-case來替換。
app??->?drv_pedometer_a
//調用關系全部替換為
app??->?drv_pedometer_b
如果采用依賴倒置,兩者依賴于抽象:
app??->?get_pedometer_interface
//底層依賴抽象
drv_pedometer_a??->?get_pedometer_interface
drv_pedometer_b??->?get_pedometer_interface
依賴倒置,即不同的硬件驅動均依賴抽象的接口,上層業務也依賴抽象層,所有的開發都圍繞get_pedometer_interface來設計,這樣硬件變化不會影響上層軟件的復用。這個實現其實是通用的代理模式。
4.3 結論
使用傳統的過程化程序設計所創建出來的依賴關系結構,策略是依賴于細節的,這樣會使策略受到細節改變的影響。事實上,使用何種語言來編寫程序是無關緊要的。即使是嵌入式C,如果程序的依賴關系是倒置的,它就是面向對象的設計思維。
依賴倒置原則是實現面向對象技術宣稱的好處的基本機制,正確應用對于創建可重用的框架來說是必須的,同時它對于構建在變化面前富有彈性的代碼也是非常重要的;由于抽象和細節被彼此隔離,所以代碼也容易維護。
5 接口隔離原則 (ISP)
使用多個專門的接口,而不使用單一的總接口,即客戶端不應該依賴那些它不需要的接口。面向對象開發時,繼承的基類中包含本不需要的接口,原本特定需求擴展的接口成了通用,導致所有派生類都要去實現沒有意義的接口,即為接口污染。
5.1 接口污染
接口隔離原則”的重點是“接口”二字,在嵌入式C層面有兩種理解:
1、如果把“接口”理解為一組API接口集合,可以是某個子功能的一系列接口。如果部分接口只被部分調用者使用,就需要將這部分接口隔離出來,單獨給這部分調用者使用,而不強迫其它調用者也依賴這部分本不會被用到的接口。類似購物,不需要捆綁銷售,只買自己需要的。
2、如果把“接口”理解為單個API接口或函數,部分調用者只需要函數中的部分功能,可把函數拆分成粒度更細的多個函數,讓調用者只依賴它需要的那個細粒度函數。即一個函數不要傳入過多的參數配置,寧可拆分為多個同類接口簡化調用,也不要提供一個萬能的需要一些不相關參數的接口。模塊對外接口不要過度封裝,參數太多也不便于閱讀和使用。
5.2 風險與解決
如果一個程序依賴于部分它不使用的方法,這程序就面臨著由于這些未使用方法的改變所帶來的變更,這無意中導致了所有相關程序之間的耦合。換種說法,如果一個客戶程序依賴于它不使用的方法,但是其他客戶程序卻要使用這些方法,那當其他客戶要求這個方法改變時,就會影響到這個客戶程序。應該盡可能地避免這種耦合,分離接口。
在嵌入式C中,隨著迭代升級,也會擴展新功能,或者直接為函數增加傳入參數,或者函數內部增加額外的處理,導致接口產生冗余,對不同版本的調用者并不友好(如果本身是功能迭代升級沒問題,避免不同版本的差異是平級關系)。更改的代價和影響就變得不可預測,并且更改所附帶的風險也會增加。更改一個和自己不相關的功能也可能產生影響,表面是修改A功能卻導致B功能異常,“城門失火,殃及池魚”,這種對單元測試覆蓋也難以把握。
模塊層面,不相關的接口可以使用預編譯宏屏蔽,這樣也節省代碼空間;函數層面擴展新功能時可以新建接口,重新實現和原來接口功能平級的擴展版或者v2,盡量不要通過傳參合并,除非明確兩者是遞進關系而不是并列關系。
微信公眾號【嵌入式系統】建議,子模塊分多個c文件,內部函數務必加static,僅模塊內部的使用全局函數可以在c內使用extern,不要加到h頭文件。功能類似但應用場景不同的函數可以放在一起,且注釋里互相提到對方,說明差異。更多編碼規范和編碼技巧可以參考《嵌入式C編碼規范》、《代碼的保養》。
6 最少知道原則(LKP)
迪米特法則(Law of Demeter,縮寫是 LOD),也叫最小知道(知識)原則,一個功能對其依賴的子功能知道的越少越好,對于被依賴的子功能無論邏輯多么復雜,都盡量將邏輯封裝在內部。通俗的解釋就是,使用某個子模塊,不需要關注其內部實現,調用盡可能少的API接口。
比如執行A操作需要按順序調用1-2-3-4四個接口,執行B操作需要按順序調用1-2-4-3四個接口,對于調用者需要清楚知道模塊內細節才能正確使用,這種完全可以合并接口,封裝A和B兩個動作,在其內部執行具體的細節,對外隱藏封閉,外界使用時無需關注。
最少知道原則(迪米特原則)的初衷在于降低模塊間的耦合,模塊更好的信息隱藏和更少的信息重載,將部分信息固化封閉。但過度的封閉也有缺點,一旦客制化需求變更,如果新增C操作是4-3-2-1就需要擴展新接口。
7 ?重構
重構是持續進行的,好比用餐后對廚房的清理工作。第一次沒有清理用餐會快一點,但是由于沒有對盤碟和用餐環境進行清潔,第二天做準備工作的時間就要更長一點。這會再一次促使放棄清潔工作。的確,跳過清潔工作能夠很快用餐,但是臟亂在逐漸積累。最終,得花費大量的時間去尋找合適的烹飪器具,鑿去盤碟上已經干硬的食物殘余,并把它們洗擦干凈。飯是天天要吃的,忽略掉清潔工作并不能真正加快做飯速度,片面追求速度早晚要翻車,欲速則不達。重構的目的就是為了每天清潔代碼,保持代碼的清潔。
?
軟件開發大部分是基于這種理不清的混沌狀態的迭代開發,所有的原則和模式對于臟亂的代碼來說將沒有任何價值。在應用各種設計原則、設計模式前(《嵌入式軟件的設計模式(上)》、《嵌入式軟件的設計模式(下)》),首先學習編寫清潔的代碼。
8 隨想
面向對象的設計原則還有很多,基于類的繼承、封裝、多態有各種通用指導規則,而這些設計原則對于嵌入式C并不完全適用。嵌入式C是結構化程序設計,自頂向下的方式,在需求多變時或多或少存在弊端,其特點是快但亂。所以重構是必不可少的,在不改變外在行為的前提下,改進代碼的內部結構;但修改成什么樣式才是合適的,就可以參考前面的五種規則。
現在的嵌入式軟件開發極少像以前把一個字節掰成八瓣使用,資源足夠的情況下,嵌入式應用開發可適當參考面向對象的方式實現高質量的軟件;具體方案思路兩種,函數指針,抽象隔離。“沒有什么問題是不能通過增加一個抽象層解決的,如果有,再增加一層”。
審核編輯:黃飛
?











 工商網監
工商網監
評論