 電子發燒友App
電子發燒友App


Cache coherency
Cacheability
Normal memory可以設置為cacheable或non-cacheable,可以按inner和outer分別設置。
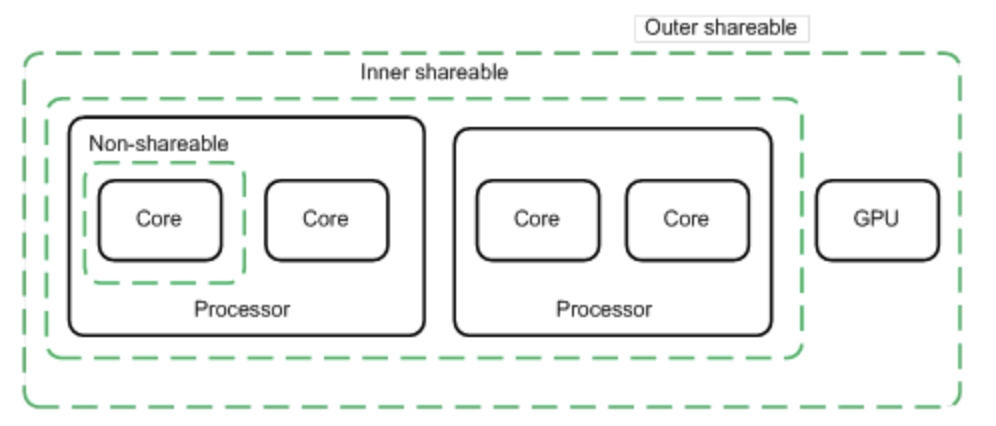
Shareability
設置為non-shareable則該段內存只給一個特定的核使用,設置為inner shareable或outer shareable則可以被其它觀測者訪問(其它核、GPU、DMA 設備),inner和outer的區別是要求cache coherence的范圍,inner觀測者和outer觀測者的劃分是implementation defined。
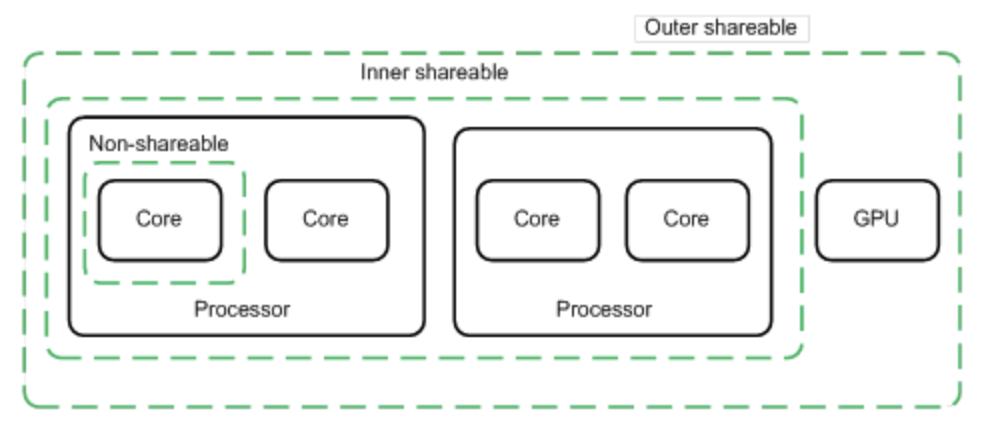
圖1
PoC&PoU
當clean或invalidate cache的時候,可以操作到特定的cache級別,具體地,可以到下面兩個“點”:
Point of coherency(PoC):保證所有能訪問內存的觀測者(CPU 核、DSP、DMA 設備)能看到一個內存地址的同一份拷貝的“點”,一般是主存。
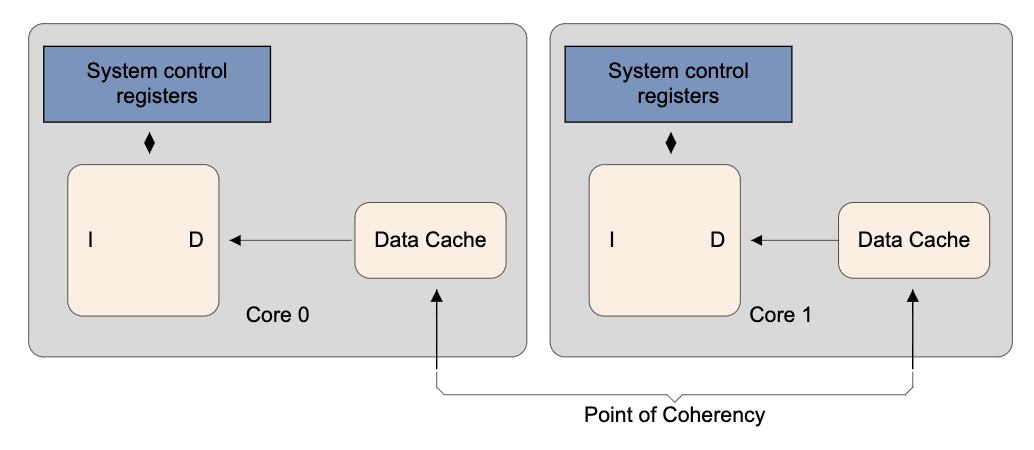
圖2
Point of unification(PoU):保證一個核的icache、dcache、MMU(TLB)看到一個內存地址的同一份拷貝的“點”,例如unified L2 cache是下圖中的核的PoU,如果沒有L2 cache,則是主存。
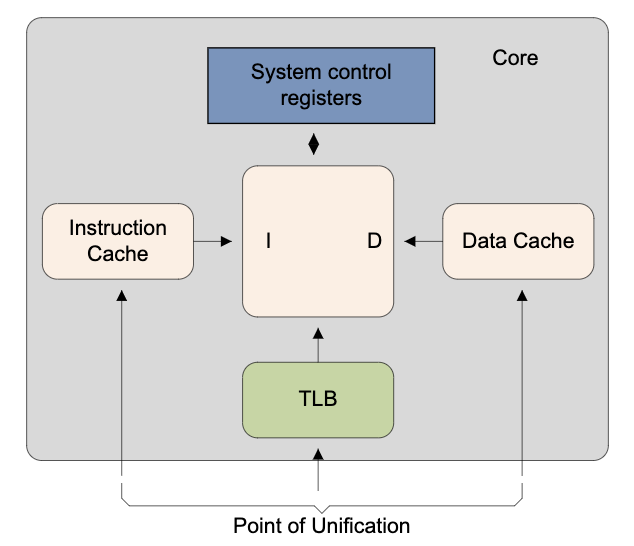
圖3
當說“invalidate icache to PoU”的時候,是指invalidate icache,使下次訪問時從L2 cache(PoU)讀取。
PoU的一個應用場景是:運行的時候修改自身代碼之后,使用兩步來刷新cache,首先,clean dcache到PoU,然后invalidate icache到PoU。
Memory consistency
Armv8-A采用弱內存模型,對normal memory的讀寫可能亂序執行,頁表里可以配置為non-reordering(可用于 device memory)。
Normal memory:RAM、Flash、ROM in physical memory,這些內存允許以弱內存序的方式訪問,以提高性能。
單核單線程上連續的有依賴的str和ldr不會受到弱內存序的影響,比如:
str x0, [x2]?
ldr x1, [x2]
Barriers
ISB
刷新當前PE的pipeline,使該指令之后的指令需要重新從cache或內存讀取,并且該指令之后的指令保證可以看到該指令之前的context changing operation,具體地,包括修改ASID、TLB維護指令、修改任何系統寄存器。
DMB
保證所指定的shareability domain內的其它觀測者在觀測到dmb之后的數據訪問之前觀測到dmb之前的數據訪問:
str x0, [x1]
dmb
str x2, [x3] //如果觀測者看到了這行str,則一定也可以看到第 1行str
同時,dmb還保證其后的所有數據訪問指令能看到它之前的dcache或unified cache維護操作:
dc csw, x5?
ldr x0, [x1] // 可能看不到dcache clean?
dmb ish?
ldr x2, [x3] // 一定能看到dcache clean
DSB
保證和dmb一樣的內存序,但除了訪存操作,還保證其它任何后續指令都能看到前面的數據訪問的結果。
等待當前PE發起的所有cache、TLB、分支預測維護操作對指定的shareability domain可見。
可用于在sev指令之前保證數據同步。
一個例子:
str x0, [x1] // update a translation table entry?
dsb ishst // ensure write has completed?
tlbi vae1is, x2 // invalidate the TLB entry for the entry that changes?
dsb ish // ensure that TLB invalidation is complete?
isb // synchronize context on this processor
DMB&DSB options
dmb和dsb可以通過option指定barrier約束的訪存操作類型和shareability domain:
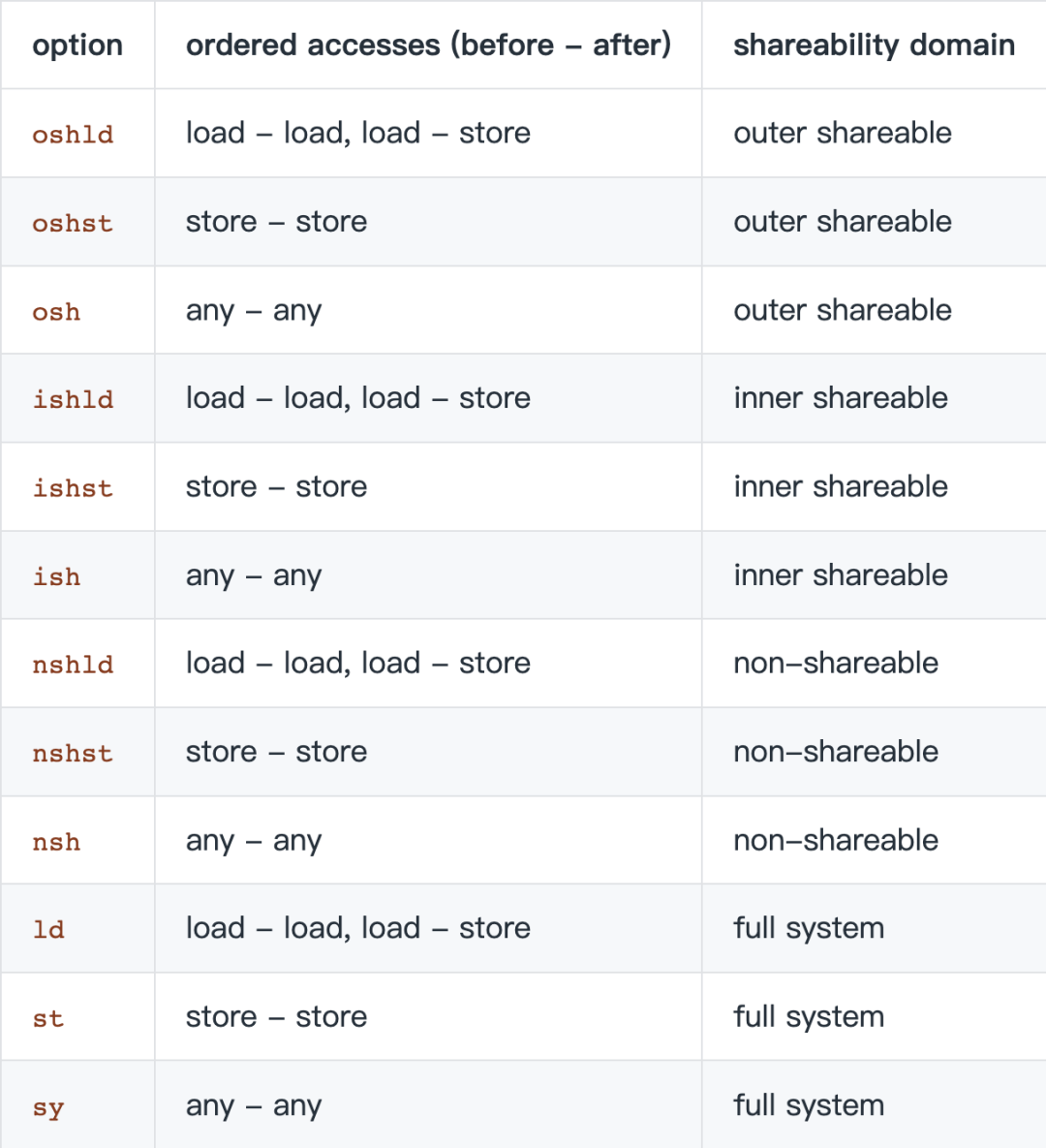
圖4
One-way barriers
Load-Acquire (LDAR): All loads and stores that are after an LDAR in program order, and that match the shareability domain of the target address, must be observed after the LDAR.
Store-Release (STLR): All loads and stores preceding an STLR that match the shareability domain of the target address must be observed before the STLR.
LDAXR
STLXR
Unlike the data barrier instructions, which take a qualifier to control which shareability domains see the effect of the barrier, the LDAR and STLR instructions use the attribute of the address accessed.
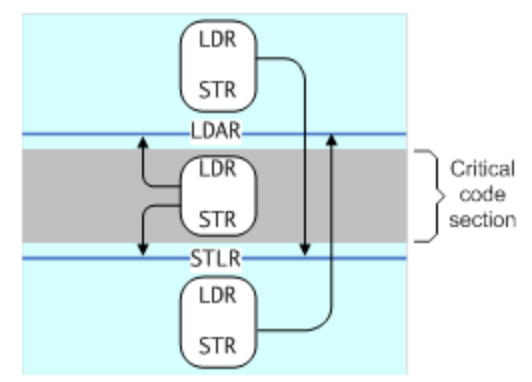
圖5
C++&Rust memory order
Relaxed
Relaxed原子操作只保證原子性,不保證同步語義。
//Thread 1:?
r1=y.load(std::memory_order_relaxed); //A?
x.store(r1, std::memory_order_relaxed); //B?
//Thread 2:?
r2=x.load(std::memory_order_relaxed); //C?
y.store(42, std::memory_order_relaxed); //D
上面代碼在Arm上編譯后使用str和ldr指令,可能被亂序執行,有可能最終產生r1==r2==42的結果,即A看到了D,C看到了B。
典型的relaxed ordering的使用場景是簡單地增加一個計數器,例如std::shared_ptr中的引用計數,只需要保證原子性,沒有memory order的要求。
Release-acquire
Rel-acq原子操作除了保證原子性,還保證使用release 的store和使用acquire的load之間的同步,acquire時必可以看到release之前的指令,release時必看不到 acquire之后的指令。
#include
#include
#include
#include
std::atomic
int data;
void producer() {
std::string *p=new std::string("Hello");
data=42;
ptr.store(p, std::memory_order_release);
}
void consumer() {
std::string *p2;
while (!(p2=ptr.load(std::memory_order_acquire)))
;
assert(*p2=="Hello"); //never fires
assert(data==42); //never fires
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
上面代碼中,一旦consumer成功load到了ptr中的非空string指針,則它必可以看到data=42這個寫操作。
這段代碼在Arm上會編譯成使用stlr和ldar,但其實C++所定義的語義比stlr和ldar實際提供的要弱,C++只保證使用了release和acquire的兩個線程間的同步。
典型的rel-acq ordering的使用場景是mutex或spinlock,當釋放鎖的時候,釋放之前的臨界區的內存訪問必須都保證對同時獲取鎖的觀測者可見。
Release-consume
和rel-acq相似,但不保證consume之后的訪存不會在release之前完成,只保證consume之后對consume load操作有依賴的指令不會被提前,也就是說consume 之后不是臨界區,而只是使用release之前訪存的結果。
Note that currently (2/2015) no known production compilers track dependency chains: consume operations are lifted to acquire operations.
#include
#include
#include
#include
std::atomic
int data;
void producer() {
std::string *p=new std::string("Hello");?
data=42;
ptr.store(p, std::memory_order_release);
}
void consumer() {
std::string *p2;
while (!(p2=ptr.load(std::memory_order_consume)))
;
assert(*p2=="Hello"); //never fires: *p2 carries dependency from ptr ? ?
assert(data==42); //may or may not fire: data does not carry dependency from ptr?
}
int main() { ? ?
std::thread t1(producer);
std::thread t2(consumer); ? ?
t1.join(); t2.join();
}
上面代碼中,由于assert(data==42)不依賴consume load指令,因此有可能在 load到非空指針之前執行,這時候不保證能看到release store,也就不保證能看到data=42。
Sequentially-consistent
Seq-cst ordering和rel-acq保證相似的內存序,一個線程的seq-cst load如果看到了另一個線程的seq-cst store,則必可以看到store之前的指令,并且load之后的指令不會被store之前的指令看到,同時,seq-cst還保證每個線程看到的所有seq-cst指令有一個一致的total order。
典型的使用場景是多個producer多個consumer的情況,保證多個consumer能看到producer操作的一致total order。
#include
#include
#include
std::atomic
std::atomic
std::atomic
void write_x() { ? ?
x.store(true, std::memory_order_seq_cst);?
}?
void write_y() { ??
y.store(true,std::memory_order_seq_cst);?
}?
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst))?
; ? ?
if (y.load(std::memory_order_seq_cst)) { ?
++z;
}?
}?
void read_y_then_x() {?
while (!y.load(std::memory_order_seq_cst)) ? ? ?
; ?
if (x.load(std::memory_order_seq_cst)) {?
++z; ??
}
}
int main() {
std::thread a(write_x); ? ?
std::thread b(write_y); ? ?
std::thread c(read_x_then_y); ? ?
std::thread d(read_y_then_x); ? ?
a.join(); b.join(); c.join(); d.join(); ? ?
assert(z.load() !=0); //will never happen
}
上面的代碼中,read_x_then_y和read_y_then_x不可能看到相反的x和y的賦值順序,所以必至少有一個執行到++z。
Seq-cst和其它ordering混用時可能出現不符合預期的結果,如下面例子中,對thread 1來說,A sequenced before B,但對別的線程來說,它們可能先看到B,很遲才看到A,于是C可能看到B,得到r1=1,D看到E,得到r2=3,F看不到A,得到r3=0。
//Thread 1:?
x.store(1, std::memory_order_seq_cst); //A
y.store(1, std::memory_order_release); //B?
//Thread 2:?
r1=y.fetch_add(1, std::memory_order_seq_cst); //C?
r2=y.load(std::memory_order_relaxed); //D?
//Thread 3:?
y.store(3, std::memory_order_seq_cst); //E?
r3=x.load(std::memory_order_seq_cst); //F
編輯:黃飛











 工商網監
工商網監
評論