 電子發(fā)燒友App
電子發(fā)燒友App


原文出處: ctthuangcheng???
cgroup 與組調(diào)度
linux內(nèi)核實現(xiàn)了control group功能(cgroup,since linux 2.6.24),可以支持將進(jìn)程分組,然后按組來劃分各種資源。比如:group-1擁有30%的CPU和50%的磁盤IO、group-2擁有10%的CPU和20%的磁盤IO、等等。具體參閱cgroup相關(guān)文章。
cgroup支持很多種資源的劃分,CPU資源就是其中之一,這就引出了組調(diào)度。
linux內(nèi)核中,傳統(tǒng)的調(diào)度程序是基于進(jìn)程來調(diào)度的。假設(shè)用戶A和B共用一臺機(jī)器,這臺機(jī)器主要用來編譯程序。我們可能希望A和B能公平的分享CPU資源,但是如果用戶A使用make -j8(8個線程并行make)、而用戶B直接使用make的話(假設(shè)他們的make程序都使用了默認(rèn)的優(yōu)先級),A用戶的make程序?qū)a(chǎn)生8倍于B用戶的進(jìn)程數(shù),從而占用(大致)8倍于B用戶的CPU。因為調(diào)度程序是基于進(jìn)程的,A用戶的進(jìn)程越多,被調(diào)度的機(jī)率就越大,就越具有對CPU的競爭力。
如何保證A、B用戶公平分享CPU呢?組調(diào)度就能做到這一點。把屬于用戶A和B的進(jìn)程各分為一組,調(diào)度程序?qū)⑾葟膬蓚€組中選擇一個組,再從選中的組中選擇一個進(jìn)程來執(zhí)行。如果兩個組被選中的機(jī)率相當(dāng),那么用戶A和B將各占有約50%的CPU。
相關(guān)數(shù)據(jù)結(jié)構(gòu)
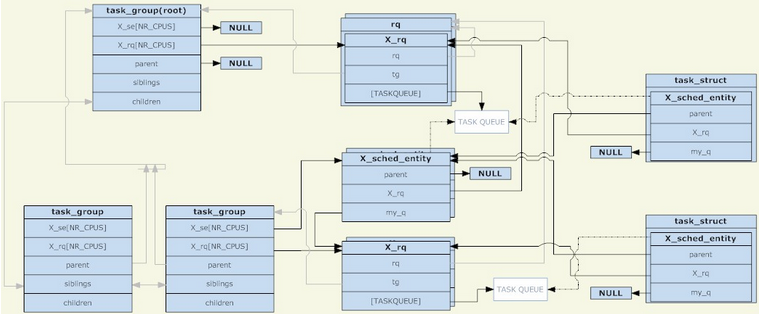
在linux內(nèi)核中,使用task_group結(jié)構(gòu)來管理組調(diào)度的組。所有存在的task_group組成一個樹型結(jié)構(gòu)(與cgroup的目錄結(jié)構(gòu)相對應(yīng))。
一個task_group可以包含具有任意調(diào)度類別的進(jìn)程(具體來說是實時進(jìn)程和普通進(jìn)程兩種類別),于是task_group需要為每一種調(diào)度策略提供一組調(diào)度結(jié)構(gòu)。這里所說的一組調(diào)度結(jié)構(gòu)主要包括兩個部分,調(diào)度實體和運(yùn)行隊列(兩者都是每CPU一份的)。調(diào)度實體會被添加到運(yùn)行隊列中,對于一個task_group,它的調(diào)度實體會被添加到其父task_group的運(yùn)行隊列。
為什么要有調(diào)度實體這樣的東西呢?因為被調(diào)度的對象有task_group和task兩種,所以需要一個抽象的結(jié)構(gòu)來代表它們。如果調(diào)度實體代表task_group,則它的my_q字段指向這個調(diào)度組對應(yīng)的運(yùn)行隊列;否則my_q字段為NULL,調(diào)度實體代表task。在調(diào)度實體中與my_q相對的是X_rq(具體是針對普通進(jìn)程的cfs_rq和針對實時進(jìn)程的rt_rq),前者指向這個組自己的運(yùn)行隊列,里面會放入它的子節(jié)點;后者指向這個組的父節(jié)點的運(yùn)行隊列,也就是這個調(diào)度實體應(yīng)該被放入的運(yùn)行隊列。
于是,調(diào)度實體和運(yùn)行隊列又組成了另一個樹型結(jié)構(gòu),它的每一個非葉子節(jié)點都跟task_group的樹型結(jié)構(gòu)是相對應(yīng)的,而葉子節(jié)點都對應(yīng)到具體的task。就像非TASK_RUNNING狀態(tài)的進(jìn)程不會被放入運(yùn)行隊列一樣,如果一個組中不存在TASK_RUNNING狀態(tài)的進(jìn)程,則這個組(對應(yīng)的調(diào)度實體)也不會被放入它的上一級運(yùn)行隊列。明確一點,只要調(diào)度組創(chuàng)建了,其對應(yīng)的task_group就肯定存在于由task_group組成的樹型結(jié)構(gòu)中;而其對應(yīng)的調(diào)度實體是否存在于由運(yùn)行隊列和調(diào)度實體組成的樹型結(jié)構(gòu)中,要取決于這個組中是否存在TASK_RUNNING狀態(tài)的進(jìn)程。
作為根節(jié)點的task_group是沒有調(diào)度實體的,調(diào)度程序總是從它的運(yùn)行隊列出發(fā),來選擇下一個調(diào)度實體(根節(jié)點必定是第一個被選中的,沒有其他候選者,所以根節(jié)點不需要調(diào)度實體)。根節(jié)點task_group所對應(yīng)的運(yùn)行隊列被包裝在一個rq結(jié)構(gòu)中,里面除了包含具體的運(yùn)行隊列以外,還有一些全局統(tǒng)計信息等字段。
調(diào)度發(fā)生的時候,調(diào)度程序從根task_group的運(yùn)行隊列中選擇一個調(diào)度實體。如果這個調(diào)度實體代表一個task_group,則調(diào)度程序需要從這個組對應(yīng)的運(yùn)行隊列繼續(xù)選擇一個調(diào)度實體。如此遞歸下去,直到選中一個進(jìn)程。除非根task_group的運(yùn)行隊列為空,否則遞歸下去一定能找到一個進(jìn)程。因為如果一個task_group對應(yīng)的運(yùn)行隊列為空,它對應(yīng)的調(diào)度實體就不會被添加到其父節(jié)點對應(yīng)的運(yùn)行隊列中。
最后,對于一個task_group來說,它的調(diào)度實體和運(yùn)行隊列都是每CPU一份的,一個(task_group對應(yīng)的)調(diào)度實體只會被加入到相同CPU所對應(yīng)的運(yùn)行隊列。而對于task來說,它的調(diào)度實體則只有一份(沒有按CPU劃分),調(diào)度程序的負(fù)載均衡功能可能會將(task對應(yīng)的)調(diào)度實體從不同CPU所對應(yīng)的運(yùn)行隊列移來移去。(參見《linux內(nèi)核SMP負(fù)載均衡淺析》)
組的調(diào)度策略
組調(diào)度的主要數(shù)據(jù)結(jié)構(gòu)已經(jīng)理清了,這里還有一個很重要的問題。我們知道task擁有其對應(yīng)的優(yōu)先級(靜態(tài)優(yōu)先級 or 動態(tài)優(yōu)先級),調(diào)度程序根據(jù)優(yōu)先級來選擇運(yùn)行隊列中的進(jìn)程。那么,既然task_group和task一樣,都被抽象成調(diào)度實體,接受同樣的調(diào)度,task_group的優(yōu)先級又該如何定義呢?這個問題需要具體到調(diào)度類別來解答(不同的調(diào)度類別,其優(yōu)先級定義方式不一樣),具體來說就是rt(實時調(diào)度)和cfs(完全公平調(diào)度)兩種類別。
實時進(jìn)程的組調(diào)度
實時進(jìn)程是對CPU有著實時性要求的進(jìn)程,它的優(yōu)先級是跟具體任務(wù)相關(guān)的,完全由用戶來定義的。調(diào)度器總是會選擇優(yōu)先級最高的實時進(jìn)程來運(yùn)行。
發(fā)展到組調(diào)度,組的優(yōu)先級就被定義為“組內(nèi)最高優(yōu)先級的進(jìn)程所擁有的優(yōu)先級”。比如組內(nèi)有三個優(yōu)先級分別為10、20、30的進(jìn)程,則組的優(yōu)先級就是10(數(shù)值越小優(yōu)先級越大)。
組的優(yōu)先級如此定義,引出了一個有趣的現(xiàn)象。當(dāng)task入隊或者出隊時,要把它的所有祖先節(jié)點都先出隊,然后再重新由底向上依次入隊。因為組節(jié)點的優(yōu)先級是依賴于它的子節(jié)點的,task的入隊和出隊將影響它的每一個祖先節(jié)點。
于是,當(dāng)調(diào)度程序從根節(jié)點的task_group出發(fā)選擇調(diào)度實體時,總是能沿著正確的路徑,找到所有TASK_RUNNING狀態(tài)的實時進(jìn)程中優(yōu)先級最高的那一個。這個實現(xiàn)似乎理所當(dāng)然,但是仔細(xì)想想,這樣一來,將實時進(jìn)程分組還有什么意義呢?無論分組與否,調(diào)度程序要做的事情都是“在所有TASK_RUNNING狀態(tài)的實時進(jìn)程中選擇優(yōu)先級最高的那一個”。這里似乎還缺了些什么……
現(xiàn)在需要先介紹一下linux系統(tǒng)中的兩個proc文件:/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us。這兩個文件規(guī)定了,在以sched_rt_period_us為一個周期的時間內(nèi),所有實時進(jìn)程的運(yùn)行時間之和不超過sched_rt_runtime_us。這兩個文件的默認(rèn)值是1s和0.95s,表示每秒種為一個周期,在這個周期中,所有實時進(jìn)程運(yùn)行的總時間不超過0.95秒,剩下的至少0.05秒會留給普通進(jìn)程。也就是說,實時進(jìn)程占有不超過95%的CPU。而在這兩個文件出現(xiàn)之前,實時進(jìn)程的運(yùn)行時間是沒有限制的,如果一直有處于TASK_RUNNING狀態(tài)的實時進(jìn)程,則普通進(jìn)程會一直不能得到運(yùn)行。相當(dāng)于sched_rt_runtime_us等于sched_rt_period_us。
為什么要有sched_rt_runtime_us和sched_rt_period_us兩個變量呢?直接使用一個表示CPU占有百分比的變量不可以么?我想這應(yīng)該是由于很多實時進(jìn)程實際上都是周期性地在干某件事情,比如某語音程序每20ms發(fā)送一個語音包、某視頻程序每40ms刷新一幀、等等。周期是很重要的,僅僅使用一個宏觀的CPU占有比無法準(zhǔn)確描述實時進(jìn)程需求。
而實時進(jìn)程的分組就把sched_rt_runtime_us和sched_rt_period_us的概念擴(kuò)展了,每個task_group都有自己的sched_rt_runtime_us和sched_rt_period_us,保證自己組內(nèi)的進(jìn)程在以sched_rt_period_us為周期的時間內(nèi),最多只能運(yùn)行sched_rt_runtime_us這么多時間。CPU占有比為sched_rt_runtime_us/sched_rt_period_us。
對于根節(jié)點的task_group,它的sched_rt_runtime_us和sched_rt_period_us就等于上面兩個proc文件中的值。而對于一個task_group節(jié)點來說,假設(shè)它下面有n個調(diào)度子組和m個TASK_RUNNING狀態(tài)的進(jìn)程,它的CPU占有比為A、這n個子組的CPU占有比為B,則B必須小于等于A,而A-B剩下的CPU時間將分給那m個TASK_RUNNING狀態(tài)的進(jìn)程。(這里討論的是CPU占有比,因為每個調(diào)度組可能有著不同的周期值。)
為了實現(xiàn)sched_rt_runtime_us和sched_rt_period_us的邏輯,內(nèi)核在更新進(jìn)程的運(yùn)行時間的時候(比如由周期性的時鐘中斷觸發(fā)的時間更新)會給當(dāng)前進(jìn)程的調(diào)度實體及其所有祖先節(jié)點都增加相應(yīng)的runtime。如果一個調(diào)度實體達(dá)到了sched_rt_runtime_us所限定的時間,則將其從對應(yīng)的運(yùn)行隊列中剔除,并將對應(yīng)的rt_rq置throttled狀態(tài)。在這個狀態(tài)下,這個rt_rq對應(yīng)的調(diào)度實體不會再次進(jìn)入運(yùn)行隊列。而每個rt_rq都會維護(hù)一個周期性的定時器,定時周期為sched_rt_period_us。每次定時器觸發(fā),其對應(yīng)的回調(diào)函數(shù)就會將rt_rq的runtime減去一個sched_rt_period_us單位的值(但要保持runtime不小于0),然后將rt_rq從throttled狀態(tài)中恢復(fù)回來。
還有一個問題,前面說到,默認(rèn)情況下,系統(tǒng)中每秒鐘內(nèi)實時進(jìn)程的運(yùn)行時間不超過0.95秒。如果實時進(jìn)程實際對CPU的需求不足0.95秒(大于等于0秒、小于0.95秒),則剩下的時間都會分配給普通進(jìn)程。而如果實時進(jìn)程的對CPU的需求大于0.95秒,它也只能夠運(yùn)行0.95秒,剩下的0.05秒會分給其他普通進(jìn)程。但是,如果這0.05秒內(nèi)沒有任何普通進(jìn)程需要使用CPU(一直沒有TASK_RUNNING狀態(tài)的普通進(jìn)程)呢?這種情況下既然普通進(jìn)程對CPU沒有需求,實時進(jìn)程是否可以運(yùn)行超過0.95秒呢?不能。在剩下的0.05秒中內(nèi)核寧可讓CPU一直閑著,也不讓實時進(jìn)程使用。可見sched_rt_runtime_us和sched_rt_period_us是很有強(qiáng)制性的。
最后還有多CPU的問題,前面也提到,對于每一個task_group,它的調(diào)度實體和運(yùn)行隊列是每CPU維護(hù)一份的。而sched_rt_runtime_us和sched_rt_period_us是作用在調(diào)度實體上的.所以如果系統(tǒng)中有N個CPU,實時進(jìn)程實際占有CPU的上限N*sched_rt_runtime_us/sched_rt_period_us。也就是說,盡管默認(rèn)情況下限制了每秒鐘之內(nèi),實時進(jìn)程只能運(yùn)行0.95秒。但是對于某個實時進(jìn)程來說,如果CPU有兩個核,也還是能滿足它100%占有CPU的需求的(比如執(zhí)行死循環(huán))。然后,按道理說,這個實時進(jìn)程占有的100%的CPU應(yīng)該是由兩部分組成的(每個CPU占有一部分,但都不超過95%)。但是實際上,為了避免進(jìn)程在CPU間的遷移導(dǎo)致上下文切換、緩存失效等一系列問題,一個CPU上的調(diào)度實體可以向另一個CPU上對應(yīng)的調(diào)度實體借用時間。其結(jié)果就是,宏觀上既滿足了sched_rt_runtime_us的限制,又避免了進(jìn)程的遷移。
普通進(jìn)程的組調(diào)度
文章一開頭提到了希望A、B兩個用戶在進(jìn)程數(shù)不相同的情況下也能平分CPU的需求,但是上面關(guān)于實時進(jìn)程的組調(diào)度策略好像與此不太相干,其實這就是普通進(jìn)程的組調(diào)度所要干的事。
相比實時進(jìn)程,普通進(jìn)程的組調(diào)度就沒有這么多講究。組被看作是跟進(jìn)程幾乎完全相同的實體,它擁有自己的靜態(tài)優(yōu)先級、調(diào)度程序也動態(tài)地調(diào)整它的優(yōu)先級。對于一個組來說,組內(nèi)進(jìn)程的優(yōu)先級并不影響組的優(yōu)先級,只有這個組被調(diào)度程序選中時,這些進(jìn)程的優(yōu)先級才被考慮。
為了設(shè)置組的優(yōu)先級,每個task_group都有一個shares參數(shù)(跟前面提到的sched_rt_runtime_us和sched_rt_period_us兩個參數(shù)并列)。shares并不是優(yōu)先級,而是調(diào)度實體的權(quán)重(這是CFS調(diào)度器的玩法),這個權(quán)重和優(yōu)先級是有一一對應(yīng)的關(guān)系的。普通進(jìn)程的優(yōu)先級也會被轉(zhuǎn)換成其對應(yīng)調(diào)度實體的權(quán)重,所以可以說shares就代表了優(yōu)先級。
shares的默認(rèn)值跟普通進(jìn)程默認(rèn)優(yōu)先級對應(yīng)的權(quán)重是一樣的。所以在默認(rèn)情況下,組和進(jìn)程是平分CPU的。
示例
(環(huán)境:ubuntu 10.04,kernel 2.6.32,Intel Core2 雙核)
掛載一個只劃分CPU資源的cgroup,并創(chuàng)建grp_a和grp_b兩個子組:
分別開三個shell,第一個加入grp_a,后兩個加入grp_b:
(為什么要用ttt.sh來寫cgroup下的tasks文件呢?因為寫這個文件需要root權(quán)限,當(dāng)前shell沒有root權(quán)限,而sudo只能賦予被它執(zhí)行的程序的root權(quán)限。其實sudo sh,然后再在新開的shell里面執(zhí)行echo操作也是可以的。)
回到cgroup目錄下,確認(rèn)這幾個shell都被加進(jìn)去了:
現(xiàn)在準(zhǔn)備在這三個shell下同時執(zhí)行一個死循環(huán)的程序(a.out),為了避免多CPU帶來的影響,將進(jìn)程綁定到第二個核上:
?
編譯生成a.out,然后在前面的三個shell中分別運(yùn)行。三個shell分別會fork出一個子進(jìn)程來執(zhí)行a.out,這些子進(jìn)程都會繼承其父進(jìn)程的cgroup分組信息。然后top一下,可以觀察到屬于grp_a的a.out占了50%的CPU,而屬于grp_b的兩個a.out各占25%的CPU(加起來也是50%):
?
接下來再試試實時進(jìn)程,把a(bǔ).out程序改造如下:
然后設(shè)置grp_a的rt_runtime值:
現(xiàn)在的配置是每秒為一個周期,屬于grp_a的實時進(jìn)程每秒種只能執(zhí)行300毫秒。運(yùn)行a.out(設(shè)置實時進(jìn)程需要root權(quán)限),然后top看看:
?
可以看到,CPU雖然閑著,但是卻不分給a.out程序使用。由于雙核的原因,a.out實際的CPU占用是60%而不是30%。
其他
前段時間,有一篇“200+行Kernel補(bǔ)丁顯著改善Linux桌面性能”的新聞比較火。這個內(nèi)核補(bǔ)丁能讓高負(fù)載條件下的桌面程序響應(yīng)延遲得到大幅度降低。其實現(xiàn)原理是,自動創(chuàng)建基于TTY的task_group,所有進(jìn)程都會被放置在它所關(guān)聯(lián)的TTY組中。通過這樣的自動分組,就將桌面程序(Xwindow會占用一個TTY)和其他終端或偽終端(各自占用一個TTY)劃分開了。終端上運(yùn)行的高負(fù)載程序(比如make -j64)對桌面程序的影響將大大減少。(根據(jù)前面描述的普通進(jìn)程的組調(diào)度的實現(xiàn)可以知道,如果一個任務(wù)給系統(tǒng)帶來了很高的負(fù)載,只會影響到與它同組的進(jìn)程。這個任務(wù)包含一個或是一萬個TASK_RUNNING狀態(tài)的進(jìn)程,對于其他組的進(jìn)程來說是沒有影響的。)

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論