 電子發燒友App
電子發燒友App


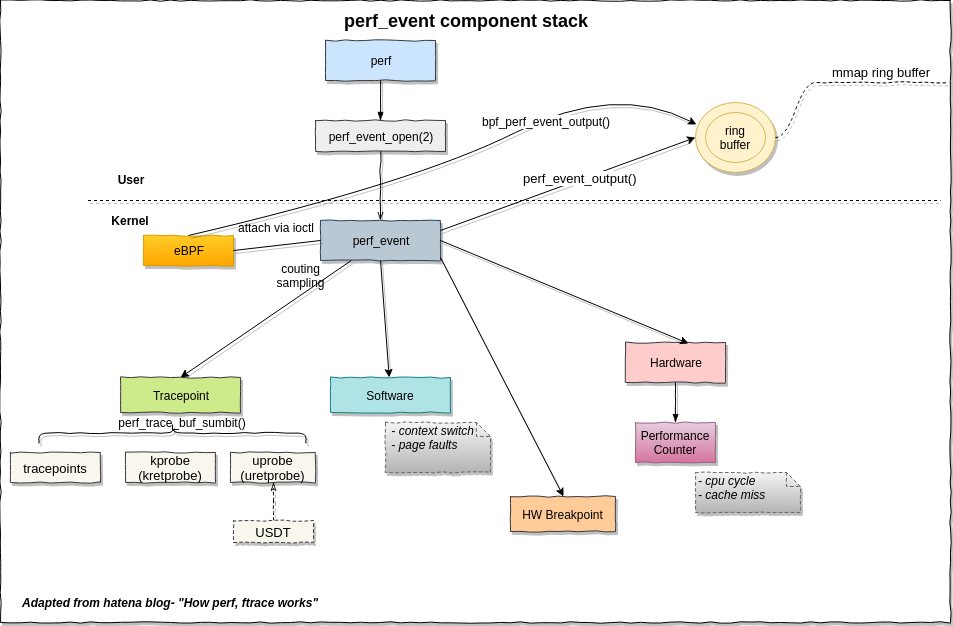
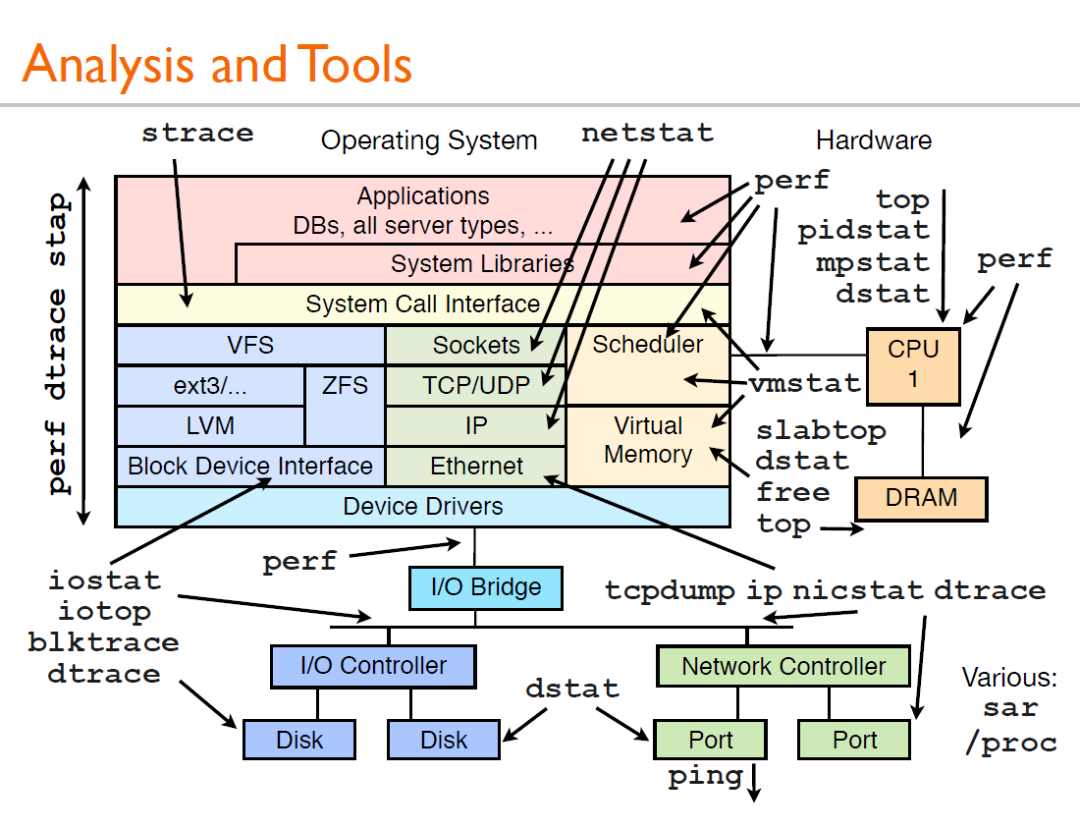
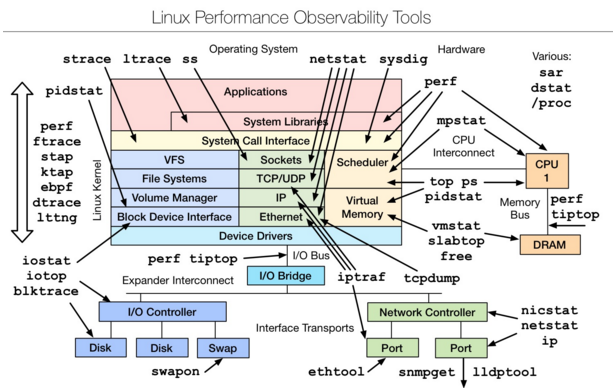
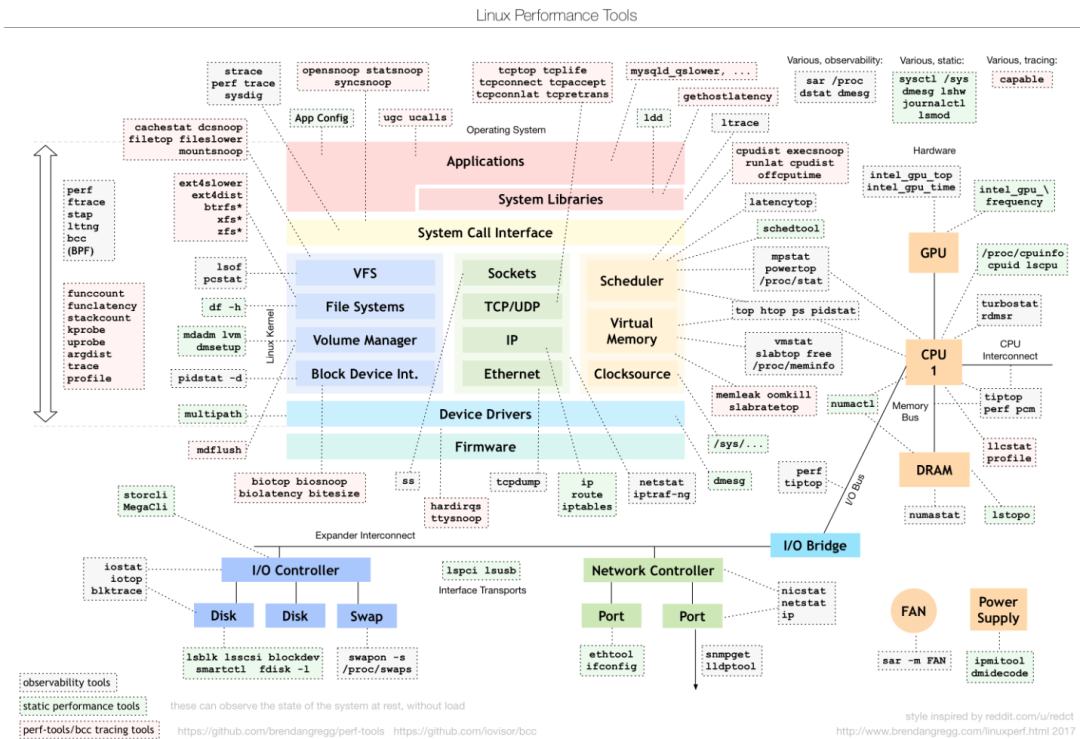
什么是perf?
Linux性能調優工具,32內核以上自帶的工具,軟件性能分析。在2.6.31及后續版本的linux內核里,安裝perf非常的容易。
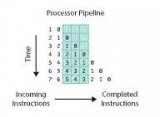
幾乎能夠處理所有與性能相關的事件。
什么是性能事件?
指在處理器或者操作系統中發生,可能影響到程序性能的硬件事件或者軟件事情。
主要關注點在哪里?
算法優化(空間復雜度、時間復雜度)、代碼優化(提到執行速度、減少內存占用)
評估程序對硬件資源的使用情況,例如各級cache的訪問次數,各級cache的丟失次數、流水線停頓周期、前端總線訪問次數等。
評估程序對操作系統資源的使用情況,系統調用次數、上下文切換次數、任務遷移次數。
基本原理?
硬件的話采用PMC(performance monitoring unit)CPU的部件,在特定的條件下探測的性能事件是否發生以及發生的次數。
軟件性能測試,內置于kernel,分布在各個功能模塊中,統計和操作系統相關性能事件。
如何使用高精度的采樣?
如果需要采用高精度的采樣,需要在制定性能事情時,在事件后添加后綴“:p”或者“:pp”
[cpp]?view plain?copy
0:無精度保證??
1:采樣指令好觸發性能時間的指令偏差為常數(:p)??
2:盡量保證偏差為0(:pp)??
3:保證偏差必須為0(:ppp)??
有哪些常用的命令?
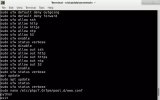
1、perf list 列出所有能夠觸發perf采樣點的事件(當前硬件環境支持的性能事件)
總體分為三類hardware(硬件產生)、software(內核軟件產生)、tradepoint(內核中靜態tracepoint觸發事件)。
[html]?view plain?copy
List?of?pre-defined?events?(to?be?used?in?-e):??
cpu-cycles?OR?cycles???????????????????????????????[Hardware?event]處理器周期事件??
stalled-cycles-frontend?OR?idle-cycles-frontend????[Hardware?event]??
stalled-cycles-backend?OR?idle-cycles-backend??????[Hardware?event]??
instructions???????????????????????????????????????[Hardware?event]??
cache-references???????????????????????????????????[Hardware?event]??
cache-misses???????????????????????????????????????[Hardware?event]??
branch-instructions?OR?branches????????????????????[Hardware?event]??
branch-misses??????????????????????????????????????[Hardware?event]??
bus-cycles?????????????????????????????????????????[Hardware?event]??
cpu-clock??????????????????????????????????????????[Software?event]??
task-clock?????????????????????????????????????????[Software?event]??
page-faults?OR?faults??????????????????????????????[Software?event]??
minor-faults???????????????????????????????????????[Software?event]??
major-faults???????????????????????????????????????[Software?event]??
context-switches?OR?cs?????????????????????????????[Software?event]??
cpu-migrations?OR?migrations???????????????????????[Software?event]??
alignment-faults???????????????????????????????????[Software?event]??
emulation-faults???????????????????????????????????[Software?event]??
L1-dcache-loads????????????????????????????????????[Hardware?cache?event]??
L1-dcache-load-misses??????????????????????????????[Hardware?cache?event]??
L1-dcache-stores???????????????????????????????????[Hardware?cache?event]??
L1-dcache-store-misses?????????????????????????????[Hardware?cache?event]??
L1-dcache-prefetches???????????????????????????????[Hardware?cache?event]??
L1-dcache-prefetch-misses??????????????????????????[Hardware?cache?event]??
L1-icache-loads????????????????????????????????????[Hardware?cache?event]??
L1-icache-load-misses??????????????????????????????[Hardware?cache?event]??
L1-icache-prefetches???????????????????????????????[Hardware?cache?event]??
L1-icache-prefetch-misses??????????????????????????[Hardware?cache?event]??
LLC-loads??????????????????????????????????????????[Hardware?cache?event]??
LLC-load-misses????????????????????????????????????[Hardware?cache?event]??
LLC-stores?????????????????????????????????????????[Hardware?cache?event]??
LLC-store-misses???????????????????????????????????[Hardware?cache?event]??
LLC-prefetches?????????????????????????????????????[Hardware?cache?event]??
LLC-prefetch-misses????????????????????????????????[Hardware?cache?event]??
dTLB-loads?????????????????????????????????????????[Hardware?cache?event]??
dTLB-load-misses???????????????????????????????????[Hardware?cache?event]??
dTLB-stores????????????????????????????????????????[Hardware?cache?event]??
dTLB-store-misses??????????????????????????????????[Hardware?cache?event]??
dTLB-prefetches????????????????????????????????????[Hardware?cache?event]??
dTLB-prefetch-misses???????????????????????????????[Hardware?cache?event]??
iTLB-loads?????????????????????????????????????????[Hardware?cache?event]??
iTLB-load-misses???????????????????????????????????[Hardware?cache?event]??
branch-loads???????????????????????????????????????[Hardware?cache?event]??
branch-load-misses?????????????????????????????????[Hardware?cache?event]??
2、perf stat分析程序的整體性能
利用10個典型事件剖析了應用程序。
task-clock:目標任務真真占用處理器的時間,單位是毫秒,我們稱之為任務執行時間,
后面是任務的處理器占用率(執行時間和持續時間的比值)
持續時間值從任務提交到任務結束的總時間(總時間在stat結束之后會打印出來)。
context-switches:上下文切換次數,前半部分是切換次數,后面是平均每秒發生次數(M是10的6次方)。
cpu-migrations:處理器遷移,linux為了位置各個處理器的負載均衡,
會在特定的條件下將某個任務從一個處理器遷往另外一個處理器,此時便是發生了一次處理器遷移。
page-fault:缺頁異常,linux內存管理子系統采用了分頁機制,
當應用程序請求的頁面尚未建立、請求的頁面不在內存中或者請求的頁面雖在在內存中,
但是尚未建立物理地址和虛擬地址的映射關系是,會觸發一次缺頁異常。
cycles:任務消耗的處理器周期數
instructions:任務執行期間產生的處理器指令數,IPC(instructions perf cycle)
IPC是評價處理器與應用程序性能的重要指標。(很多指令需要多個處理周期才能執行完畢),
IPC越大越好,說明程序充分利用了處理器的特征。
branches:程序在執行期間遇到的分支指令數。
branch-misses:預測錯誤的分支指令數
cache-misses:cache時效的次數
cache-references:cache的命中次數
常用的參數如下
[cpp]?view plain?copy
-e,指定性能事件??
-p,指定分析進程的PID??
-t,指定待分析線程的TID??
-r?N,連續分析N次??
-d,全面性能分析,采用更多的性能事件??
一次分析后的結果如下:
[html]?view plain?copy
Performance?counter?stats?for?process?id?'21787':??
42677.253367?task-clock????????????????#????0.142?CPUs?utilized???????????
587,906?context-switches??????????#????0.014?M/sec???????????????????
29,209?CPU-migrations????????????#????0.001?M/sec???????????????????
117?page-faults???????????????#????0.000?M/sec???????????????????
82,341,400,508?cycles????????????????????#????1.929?GHz?????????????????????[83.48%]??
61,262,984,952?stalled-cycles-frontend???#???74.40%?frontend?cycles?idle????[83.28%]??
43,113,701,768?stalled-cycles-backend????#???52.36%?backend??cycles?idle????[66.72%]??
44,023,301,495?instructions??????????????#????0.53??insns?per?cycle?????????
#????1.39??stalled?cycles?per?insn?[83.50%]??
8,137,448,528?branches??????????????????#??190.674?M/sec???????????????????[83.22%]??
430,957,756?branch-misses?????????????#????5.30%?of?all?branches?????????[83.34%]??
300.393753095?seconds?time?elapsed??
3、perf top實時顯示系統/進程的性能統計信息
默認性能事件“cycles CPU周期數”進行全系統的性能剖析
常見的參數如下:
[cpp]?view plain?copy
-p:指定進程PID??
-t:指定線程的TID??
-a:分析整個系統的性能(默認)??
-d:界面刷新周期,默認是2秒??
結果輸出中,比例是該符號引發的性能時間在整個監測域中占的比例,通常稱為熱度。
[html]?view plain?copy
samples??pcnt?function???????????????????????????????????????????????????????????????????????????????DSO??
_______?_____?______________________________________________________________________________________?_________??
61.00?19.4%?native_write_msr_safe??????????????????????????????????????????????????????????????????[kernel]??
18.00??5.7%?JVM_InternString???????????????????????????????????????????????????????????????????????libjvm.so??
17.00??5.4%?find_busiest_group?????????????????????????????????????????????????????????????????????[kernel]??
17.00??5.4%?_spin_lock?????????????????????????????????????????????????????????????????????????????[kernel]??
12.00??3.8%?dev_hard_start_xmit????????????????????????????????????????????????????????????????????[kernel]??
11.00??3.5%?tg_load_down???????????????????????????????????????????????????????????????????????????[kernel]??
9.00??2.9%?futex_wake?????????????????????????????????????????????????????????????????????????????[kernel]??
8.00??2.5%?do_futex???????????????????????????????????????????????????????????????????????????????[kernel]??
7.00??2.2%?load_balance_fair??????????????????????????????????????????????????????????????????????[kernel]??
7.00??2.2%?weighted_cpuload???????????????????????????????????????????????????????????????????????[kernel]??
7.00??2.2%?update_cfs_shares??????????????????????????????????????????????????????????????????????[kernel]??
7.00??2.2%?JVM_LatestUserDefinedLoader????????????????????????????????????????????????????????????libjvm.so??
6.00??1.9%?update_cfs_load????????????????????????????????????????????????????????????????????????[kernel]??
5.00??1.6%?_ZN16SystemDictionary30resolve_instance_class_or_nullE12symbolHandle6HandleS1_P6Thread?libjvm.so??
5.00??1.6%?br_sysfs_delbr?????????????????????????????????????????????????????????????????????????[bridge]??
5.00??1.6%?futex_wait????????????
4、perf ?record/report記錄一段時間內系統/進程的性能事件
默認在當前目錄下生成數據文件:perf.data
report讀取生成的perf.data文件,-i參數指定路徑
了解perf,是性能分析的開始。
http://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
?













 工商網監
工商網監
評論