 電子發燒友App
電子發燒友App


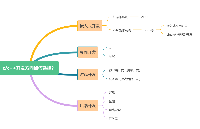
Linux內核同步機制,挺復雜的一個東西,常用的有自旋鎖,信號量,互斥體,原子操作,順序鎖,RCU,內存屏障等。這里就說說它們的特點和基本用法。
自旋鎖 :通用的 和讀寫的
特點:
1. 處理的時間很短。
2. 嘗試獲取鎖時,不能睡眠,但是有trylock接口可以直接退出。
3. 多用在中斷中。
4. 任何時候只有一個保持者能夠訪問臨界區。
5. 可以被中斷打斷的(硬件和軟件的)
6. 獲取自旋鎖后首先就是關閉了搶占
spin_lock使用接口:
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 void spin_lock_init(spinlock_t *lock); //init
void spin_lock(spinlock_t *lock); // 獲取鎖
void spin_unlock(spinlock_t *lock); //釋放鎖
其他變體
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
Rwlock: 讀寫自旋鎖基本特點和通用自旋鎖一樣,但是有時候多線程頻繁讀取臨界區如果同時只能一個那么效率會很低,它的特點就是在讀的時候獲取讀鎖,可以同時有N個線程同時讀,在寫時需要獲得寫鎖(不能有讀和寫鎖)。
在讀操作時,寫操作必須等待;寫操作時,讀操作也需要的等待。這樣雖然避免了數據的不一致,但是某些操作要等待,后面還會出現順序鎖,是對讀寫鎖的優化,把寫的優先級調高了
使用接口:
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26rwlock_init(lock); //init
read_lock(lock); //獲取讀鎖
read_unlock(lock) ;
write_lock (lock); //獲取寫鎖
write_unlock(lock);
/*
* include/linux/rwlock_types.h - generic rwlock type definitions
* and initializers
*
* portions Copyright 2005, Red Hat, Inc., Ingo Molnar
* Released under the General Public License (GPL)。
*/
typedef struct {
arch_rwlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
而關于自旋鎖的缺點?這里找到ibm一個文章
信號量(semaphore):通用的 和讀寫的
相對于自旋鎖,它最大的特點就是允許調用它的線程進入睡眠
C
1
2
3
4
5
6/* Please don‘t access any members of this structure directly */
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
void sema_init(struct semaphore *sem, int val); // val值代表了同時多少個線程可以進入臨界區,一般為1 即作為互斥體使用;當然》1 時,并發操作同一資源會引發什么呢?
down_interruptible(struct semaphore *sem); // 獲取信號量 ,它是可以中斷的。
up(struct semaphore *sem); // 釋放信號量,一般配對使用,當然也可以在別的線程里釋放它。
讀寫信號量:rwsem 它和讀寫自旋鎖類似 除了線程可以睡眠
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/* the rw-semaphore definition
* - if activity is 0 then there are no active readers or writers
* - if activity is +ve then that is the number of active readers
* - if activity is -1 then there is one active writer
* - if wait_list is not empty, then there are processes waiting for the semaphore
*/
struct rw_semaphore {
__s32 activity;
raw_spinlock_t wait_lock;
struct list_head wait_list;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
init_rwsem(sem) ; // 初始化
down_read(struct rw_semaphore *sem); // 獲取讀信號量
up_read(struct rw_semaphore *sem); //釋放讀信號量
down_write(struct rw_semaphore *sem); //獲取寫信號量
up_write(struct rw_semaphore *sem); // 釋放寫信號量
互斥體(mutex):和count=1的信號量幾乎沒有區別,當然擁有互斥鎖的進程總是盡可能的在短時間內釋放
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_SMP)
struct task_struct *owner;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
const char *name;
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
mutex_init(mutex); // init 互斥鎖
mutex_lock(); //獲取互斥鎖,幾乎都能獲取
mutex_unlock(); //釋放互斥鎖
原子操作(atomic)(和架構相關,就是多條指令相當于一條指令執行,多用于計數)
組要是在smp上有意義,防止多條指令被多cpu執行。也是為了實現互斥。
順序鎖(sequence)
特點:
和讀寫自旋鎖鎖類似,但是它的寫不會等待。寫的時候持有自旋鎖。首先讀者的代碼應該盡可能短且寫者不能頻繁獲得鎖,其次被保護的數據結構不包括被寫修改的指針或被讀間接引用的指針。當要保護的資源很小很簡單,會很頻繁被訪問并且寫入操作很少發生且必須快速時,就可以用seqlock。
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Seqlock:
typedef struct {
unsigned sequence;
spinlock_t lock;
} seqlock_t;
seqlock_init(x) / DEFINE_SEQLOCK(x) // init
write_seqlock(seqlock_t *sl) ; // 獲取寫鎖
write_sequnlock(seqlock_t *sl);
read_seqbegin 和 read_seqretry 結合使用 //讀時如果有寫鎖,則循環等待直到鎖釋放。
應用實例drivers/md/md.c
retry:
seq = read_seqbegin(&bb-》lock);
memset(bbp, 0xff, PAGE_SIZE);
for (i = 0 ; i 《 bb-》count ; i++) {
u64 internal_bb = p[i];
u64 store_bb = ((BB_OFFSET(internal_bb) 《《 10)
| BB_LEN(internal_bb));
bbp[i] = cpu_to_le64(store_bb);
}
bb-》changed = 0;
if (read_seqretry(&bb-》lock, seq))
goto retry;
RCU:read-copy-update
在linux提供的所有內核互斥設施當中屬于一種免鎖機制。Rcu無需考慮讀和寫的互斥問題。
它實際上是rwlock的一種優化。讀取者不必關心寫入者。所以RCU可以讓多個讀取者與寫入者同時工作。寫入者的操作比例在10%以上,需要考慮其他互斥方法。并且必須要以指針的方式來訪問被保護資源。
Rcu_read_lock //僅僅是關閉搶占
Rcu_read_unlock //打開搶占
Rcu_assign_pointer(ptr,new_ptr)
//等待隊列:它并不是一種互斥機制。它輔助comletion。
//它主要用來實現進程的睡眠等待。
//操作接口:wait/ wake_up
C
1
2
3
4
5struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
完成接口(completion) :該機制被用來在多個執行路徑間作同步使用,即協調多個執行路徑的執行順序。如果沒有完成體,則睡眠在wait_list上。這里usb 在提交urb時會用到。
如果驅動程序要在執行后面操作之前等待某個過程的完成,它可以調用wait_for_completion,以要完成的事件為參數:
Completion機制是線程間通信的一種輕量級機制:允許一個線程告訴另一個線程工作已經完成
C
1
2
3
4
5
6
7
8
9
10
11
12struct completion {
unsigned int done;
wait_queue_head_t wait;
};
接口:
DECLARE_COMPLETION(x) // 靜態定義completion
init_completion(struct completion *x); // 動態init
INIT_COMPLETION(x); // 初始化一個已經使用過的completion
Wait_for_completion(struct completion *x);
complete(struct completion *); //done +1,喚醒等待的一個。
Complete_all // 喚醒所有的,一般不會用。
內存屏障
內存屏障主要有:讀屏障、寫屏障、通用屏障、優化屏障
內存屏障主要解決了兩個問題:單處理器下的亂序問題和多處理器下的內存同步問題
編譯器優化以保證程序上下文因果關系為前提。
以 讀屏障為例,它用于保證讀操作有序。屏障之前的讀操作一定會先于屏障之后的讀操作完成,寫操作不受影響,同屬于屏障的某一側的讀操作也不受影響。類似的, 寫屏障用于限制寫操作。而通用屏障則對讀寫操作都有作用。而優化屏障則用于限制編譯器的指令重排,不區分讀寫。前三種屏障都隱含了優化屏障的功能。比如:
tmp = ttt; *addr = 5; mb(); val = *data;
有了內存屏障就了確保先設置地址端口,再讀數據端口。而至于設置地址端口與tmp的賦值孰先孰后,屏障則不做干預。有了內存屏障,就可以在隱式因果關系的場景中,保證因果關系邏輯正確。
在Linux中,優化屏障就是barrier()宏,它展開為asm volatile(“”:::”memory”)
smp_rmb(); // 讀屏障
smp_wmb(); //寫屏障
smp_mb(); // 通用屏障
Blk:大內核鎖
BKL(大內核鎖)是一個全局自旋鎖,使用它主要是為了方便實現從Linux最初的SMP過度到細粒度加鎖機制。它終將退出歷史舞臺。
BKL的特性:
持有BKL的任務仍然可以睡眠 。因為當任務無法調度時,所加的鎖會自動被拋棄;當任務被調度時,鎖又會被重新獲得。當然,并不是說,當任務持有BKL時,睡眠是安全的,緊急是可以這樣做,因為睡眠不會造成任務死鎖。
BKL是一種遞歸鎖。一個進程可以多次請求一個鎖,并不會像自旋鎖那么產生死鎖。BKL可以在進程上下文中。
BKL是有害的:
在內核中不鼓勵使用BKL。一個執行線程可以遞歸的請求鎖lock_kernel(),但是釋放鎖時也必須調用同樣次數的unlock_kernel()操作,在最后一個解鎖操作完成之后,鎖才會被釋放。BKL在被持有時同樣會禁止內核搶占。多數情況下,BKL更像是保護代碼而不是保護數據。
備注:單核不可搶占內核 唯一的異步事件就是硬件中斷 ,所以想要同步即關閉中斷即可。對于單核可搶占和多核可搶占的 ,除了中斷 還有進程調度(即優先級高的進程搶占cpu資源),而上述所有這些機制都是為了防止并發。
















 工商網監
工商網監
評論