 電子發(fā)燒友App
電子發(fā)燒友App


Spark 作為一個基于內存的分布式計算引擎,其內存管理模塊在整個系統(tǒng)中扮演著非常重要的角色。理解 Spark 內存管理的基本原理,有助于更好地開發(fā) Spark 應用程序和進行性能調優(yōu)。本文旨在梳理出 Spark 內存管理的脈絡,拋磚引玉,文中闡述的原理基于 Spark 2.1 版本,閱讀本文需要讀者有一定的 Spark 和 Java 基礎,了解 RDD、Shuffle、JVM 等相關概念。
在執(zhí)行 Spark 的應用程序時,Spark 集群會啟動 Driver 和 Executor 兩種 JVM 進程,前者為主控進程,負責創(chuàng)建 Spark 上下文,提交 Spark 作業(yè)(Job),并將作業(yè)轉化為計算任務(Task),在各個 Executor 進程間協(xié)調任務的調度,后者負責在工作節(jié)點上執(zhí)行具體的計算任務,并將結果返回給 Driver,同時為需要持久化的 RDD 提供存儲功能[1]。由于 Driver 的內存管理相對來說較為簡單,本文主要對 Executor 的內存管理進行分析,下文中的 Spark 內存均特指 Executor 的內存。
一、堆內和堆外內存規(guī)劃
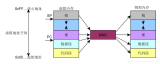
作為一個 JVM 進程,Executor 的內存管理建立在 JVM 的內存管理之上,Spark 對 JVM 的堆內(On-heap)空間進行了更為詳細的分配,以充分利用內存。同時,Spark 引入了堆外(Off-heap)內存,使之可以直接在工作節(jié)點的系統(tǒng)內存中開辟空間,進一步優(yōu)化了內存的使用。
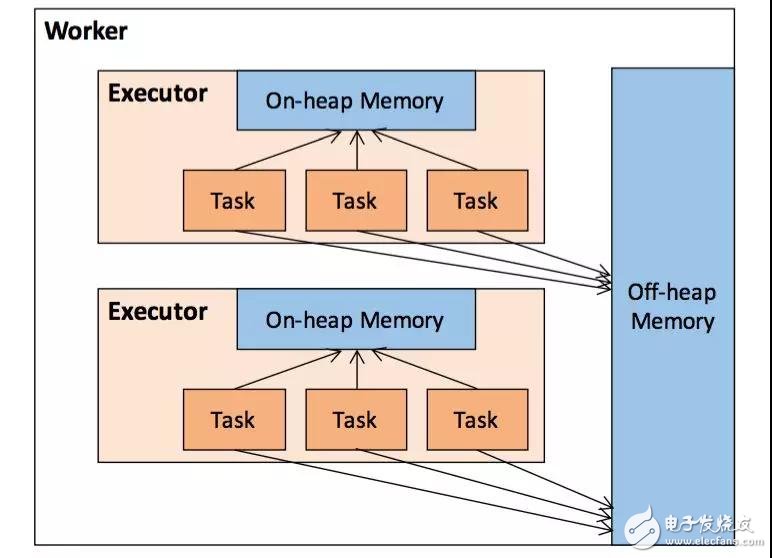
圖 1 . 堆內和堆外內存示意圖
1堆內內存
堆內內存的大小,由 Spark 應用程序啟動時的 –executor-memory 或 spark.executor.memory 參數(shù)配置。Executor 內運行的并發(fā)任務共享 JVM 堆內內存,這些任務在緩存 RDD 數(shù)據和廣播(Broadcast)數(shù)據時占用的內存被規(guī)劃為存儲(Storage)內存,而這些任務在執(zhí)行 Shuffle 時占用的內存被規(guī)劃為執(zhí)行(Execution)內存,剩余的部分不做特殊規(guī)劃,那些 Spark 內部的對象實例,或者用戶定義的 Spark 應用程序中的對象實例,均占用剩余的空間。不同的管理模式下,這三部分占用的空間大小各不相同(下面第二節(jié)會進行介紹)。
Spark 對堆內內存的管理是一種邏輯上的“規(guī)劃式”的管理,因為對象實例占用內存的申請和釋放都由 JVM 完成,Spark 只能在申請后和釋放前記錄這些內存,我們來看其具體流程:
申請內存:
Spark 在代碼中 new 一個對象實例
JVM 從堆內內存分配空間,創(chuàng)建對象并返回對象引用
Spark 保存該對象的引用,記錄該對象占用的內存
釋放內存:
Spark 記錄該對象釋放的內存,刪除該對象的引用
等待 JVM 的垃圾回收機制釋放該對象占用的堆內內存
我們知道,JVM 的對象可以以序列化的方式存儲,序列化的過程是將對象轉換為二進制字節(jié)流,本質上可以理解為將非連續(xù)空間的鏈式存儲轉化為連續(xù)空間或塊存儲,在訪問時則需要進行序列化的逆過程——反序列化,將字節(jié)流轉化為對象,序列化的方式可以節(jié)省存儲空間,但增加了存儲和讀取時候的計算開銷。
對于 Spark 中序列化的對象,由于是字節(jié)流的形式,其占用的內存大小可直接計算,而對于非序列化的對象,其占用的內存是通過周期性地采樣近似估算而得,即并不是每次新增的數(shù)據項都會計算一次占用的內存大小,這種方法降低了時間開銷但是有可能誤差較大,導致某一時刻的實際內存有可能遠遠超出預期[2]。此外,在被 Spark 標記為釋放的對象實例,很有可能在實際上并沒有被 JVM 回收,導致實際可用的內存小于 Spark 記錄的可用內存。所以 Spark 并不能準確記錄實際可用的堆內內存,從而也就無法完全避免內存溢出(OOM, Out of Memory)的異常。
雖然不能精準控制堆內內存的申請和釋放,但 Spark 通過對存儲內存和執(zhí)行內存各自獨立的規(guī)劃管理,可以決定是否要在存儲內存里緩存新的 RDD,以及是否為新的任務分配執(zhí)行內存,在一定程度上可以提升內存的利用率,減少異常的出現(xiàn)。
2堆外內存
為了進一步優(yōu)化內存的使用以及提高 Shuffle 時排序的效率,Spark 引入了堆外(Off-heap)內存,使之可以直接在工作節(jié)點的系統(tǒng)內存中開辟空間,存儲經過序列化的二進制數(shù)據。利用 JDK Unsafe API(從 Spark 2.0 開始,在管理堆外的存儲內存時不再基于 Tachyon,而是與堆外的執(zhí)行內存一樣,基于 JDK Unsafe API 實現(xiàn)[3]),Spark 可以直接操作系統(tǒng)堆外內存,減少了不必要的內存開銷,以及頻繁的 GC 掃描和回收,提升了處理性能。堆外內存可以被精確地申請和釋放,而且序列化的數(shù)據占用的空間可以被精確計算,所以相比堆內內存來說降低了管理的難度,也降低了誤差。
在默認情況下堆外內存并不啟用,可通過配置 spark.memory.offHeap.enabled 參數(shù)啟用,并由 spark.memory.offHeap.size 參數(shù)設定堆外空間的大小。除了沒有 other 空間,堆外內存與堆內內存的劃分方式相同,所有運行中的并發(fā)任務共享存儲內存和執(zhí)行內存。
3內存管理接口
Spark 為存儲內存和執(zhí)行內存的管理提供了統(tǒng)一的接口——MemoryManager,同一個 Executor 內的任務都調用這個接口的方法來申請或釋放內存:
清單 1 。 內存管理接口的主要方法
//申請存儲內存
def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
//申請展開內存
def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
//申請執(zhí)行內存
def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long
//釋放存儲內存
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit
//釋放執(zhí)行內存
def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit
//釋放展開內存
def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unit
我們看到,在調用這些方法時都需要指定其內存模式(MemoryMode),這個參數(shù)決定了是在堆內還是堆外完成這次操作。
MemoryManager 的具體實現(xiàn)上,Spark 1.6 之后默認為統(tǒng)一管理(Unified Memory Manager)方式,1.6 之前采用的靜態(tài)管理(Static Memory Manager)方式仍被保留,可通過配置 spark.memory.useLegacyMode 參數(shù)啟用。兩種方式的區(qū)別在于對空間分配的方式,下面的第二節(jié)會分別對這兩種方式進行介紹。
二、內存空間分配
1靜態(tài)內存管理
在 Spark 最初采用的靜態(tài)內存管理機制下,存儲內存、執(zhí)行內存和其他內存的大小在 Spark 應用程序運行期間均為固定的,但用戶可以應用程序啟動前進行配置,堆內內存的分配如圖 2 所示:
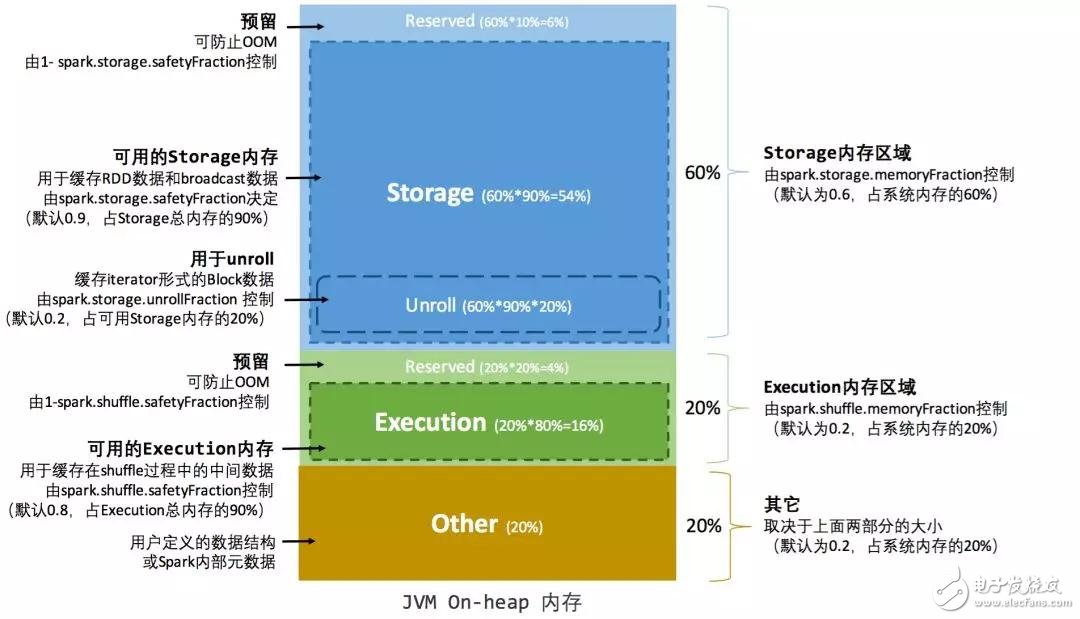
圖 2 . 靜態(tài)內存管理圖示——堆內
可以看到,可用的堆內內存的大小需要按照下面的方式計算:
清單 2 . 可用堆內內存空間
可用的存儲內存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
可用的執(zhí)行內存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
其中 systemMaxMemory 取決于當前 JVM 堆內內存的大小,最后可用的執(zhí)行內存或者存儲內存要在此基礎上與各自的 memoryFraction 參數(shù)和 safetyFraction 參數(shù)相乘得出。上述計算公式中的兩個 safetyFraction 參數(shù),其意義在于在邏輯上預留出 1-safetyFraction 這么一塊保險區(qū)域,降低因實際內存超出當前預設范圍而導致 OOM 的風險(上文提到,對于非序列化對象的內存采樣估算會產生誤差)。值得注意的是,這個預留的保險區(qū)域僅僅是一種邏輯上的規(guī)劃,在具體使用時 Spark 并沒有區(qū)別對待,和“其它內存”一樣交給了 JVM 去管理。
堆外的空間分配較為簡單,只有存儲內存和執(zhí)行內存,如圖 3 所示。可用的執(zhí)行內存和存儲內存占用的空間大小直接由參數(shù) spark.memory.storageFraction 決定,由于堆外內存占用的空間可以被精確計算,所以無需再設定保險區(qū)域。
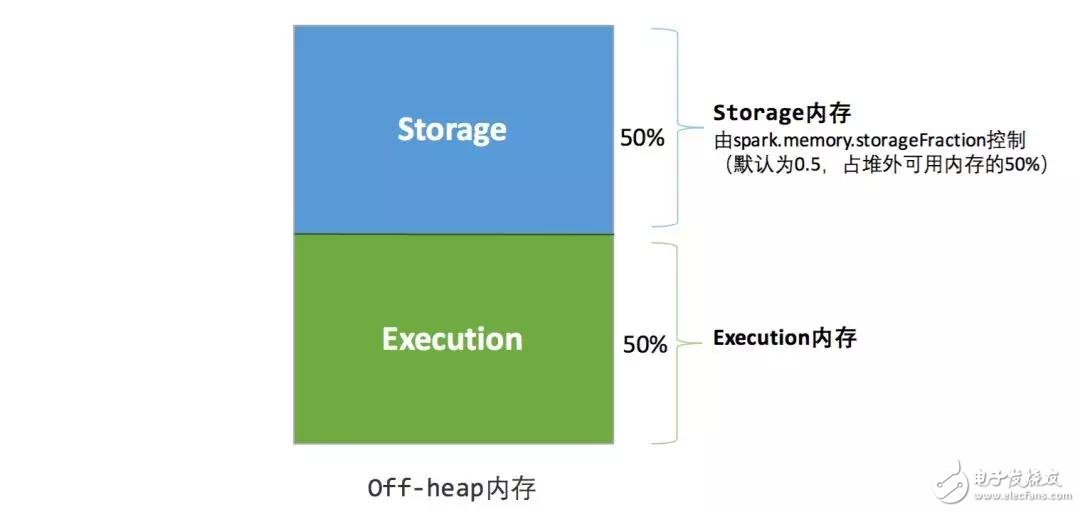
圖 3 . 靜態(tài)內存管理圖示——堆外
靜態(tài)內存管理機制實現(xiàn)起來較為簡單,但如果用戶不熟悉 Spark 的存儲機制,或沒有根據具體的數(shù)據規(guī)模和計算任務或做相應的配置,很容易造成“一半海水,一半火焰”的局面,即存儲內存和執(zhí)行內存中的一方剩余大量的空間,而另一方卻早早被占滿,不得不淘汰或移出舊的內容以存儲新的內容。由于新的內存管理機制的出現(xiàn),這種方式目前已經很少有開發(fā)者使用,出于兼容舊版本的應用程序的目的,Spark 仍然保留了它的實現(xiàn)。
2統(tǒng)一內存管理
Spark 1.6 之后引入的統(tǒng)一內存管理機制,與靜態(tài)內存管理的區(qū)別在于存儲內存和執(zhí)行內存共享同一塊空間,可以動態(tài)占用對方的空閑區(qū)域,如圖 4 和圖 5 所示。
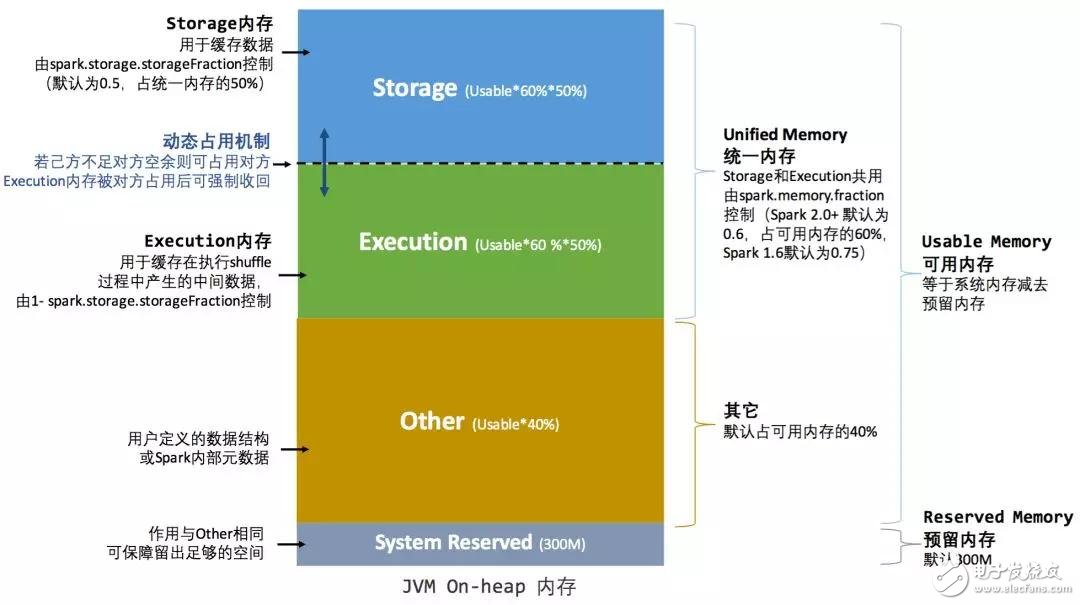
圖 4 . 統(tǒng)一內存管理圖示——堆內?
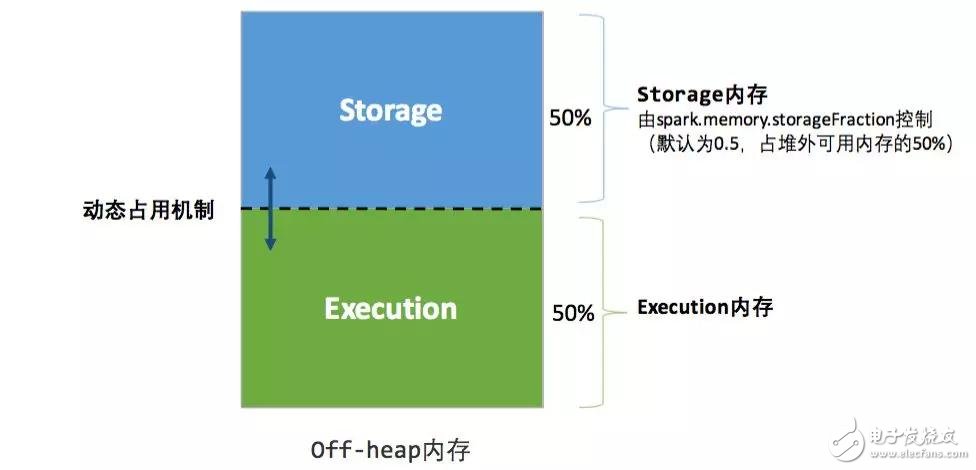
圖 5 . 統(tǒng)一內存管理圖示——堆外
其中最重要的優(yōu)化在于動態(tài)占用機制,其規(guī)則如下:
設定基本的存儲內存和執(zhí)行內存區(qū)域(spark.storage.storageFraction 參數(shù)),該設定確定了雙方各自擁有的空間的范圍;
雙方的空間都不足時,則存儲到硬盤;若己方空間不足而對方空余時,可借用對方的空間(存儲空間不足是指不足以放下一個完整的 Block);
執(zhí)行內存的空間被對方占用后,可讓對方將占用的部分轉存到硬盤,然后“歸還”借用的空間;
存儲內存的空間被對方占用后,無法讓對方“歸還”,因為需要考慮 Shuffle 過程中的很多因素,實現(xiàn)起來較為復雜[4]。?
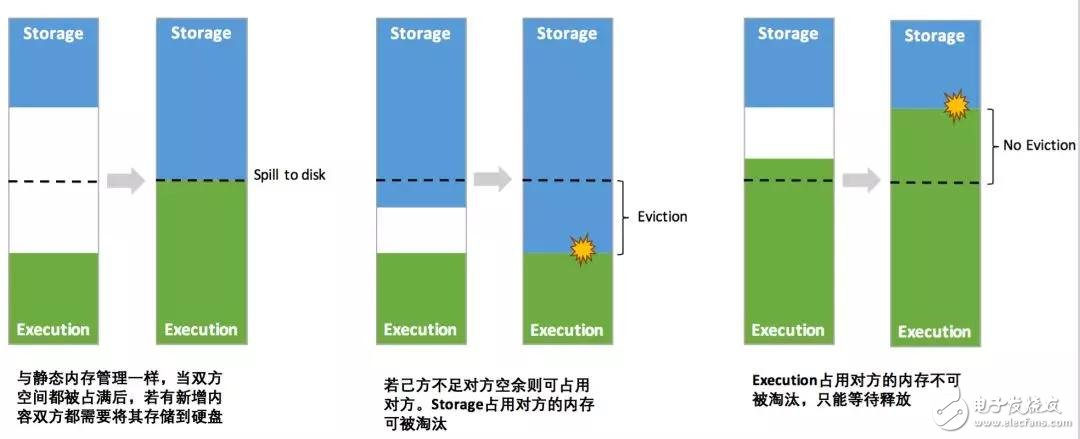
圖 6 . 動態(tài)占用機制圖示
憑借統(tǒng)一內存管理機制,Spark 在一定程度上提高了堆內和堆外內存資源的利用率,降低了開發(fā)者維護 Spark 內存的難度,但并不意味著開發(fā)者可以高枕無憂。譬如,所以如果存儲內存的空間太大或者說緩存的數(shù)據過多,反而會導致頻繁的全量垃圾回收,降低任務執(zhí)行時的性能,因為緩存的 RDD 數(shù)據通常都是長期駐留內存的 [5] 。所以要想充分發(fā)揮 Spark 的性能,需要開發(fā)者進一步了解存儲內存和執(zhí)行內存各自的管理方式和實現(xiàn)原理。
三、存儲內存管理
1RDD 的持久化機制
彈性分布式數(shù)據集(RDD)作為 Spark 最根本的數(shù)據抽象,是只讀的分區(qū)記錄(Partition)的集合,只能基于在穩(wěn)定物理存儲中的數(shù)據集上創(chuàng)建,或者在其他已有的 RDD 上執(zhí)行轉換(Transformation)操作產生一個新的 RDD。轉換后的 RDD 與原始的 RDD 之間產生的依賴關系,構成了血統(tǒng)(Lineage)。憑借血統(tǒng),Spark 保證了每一個 RDD 都可以被重新恢復。但 RDD 的所有轉換都是惰性的,即只有當一個返回結果給 Driver 的行動(Action)發(fā)生時,Spark 才會創(chuàng)建任務讀取 RDD,然后真正觸發(fā)轉換的執(zhí)行。
Task 在啟動之初讀取一個分區(qū)時,會先判斷這個分區(qū)是否已經被持久化,如果沒有則需要檢查 Checkpoint 或按照血統(tǒng)重新計算。所以如果一個 RDD 上要執(zhí)行多次行動,可以在第一次行動中使用 persist 或 cache 方法,在內存或磁盤中持久化或緩存這個 RDD,從而在后面的行動時提升計算速度。事實上,cache 方法是使用默認的 MEMORY_ONLY 的存儲級別將 RDD 持久化到內存,故緩存是一種特殊的持久化。 堆內和堆外存儲內存的設計,便可以對緩存 RDD 時使用的內存做統(tǒng)一的規(guī)劃和管 理 (存儲內存的其他應用場景,如緩存 broadcast 數(shù)據,暫時不在本文的討論范圍之內)。
RDD 的持久化由 Spark 的 Storage 模塊 [7] 負責,實現(xiàn)了 RDD 與物理存儲的解耦合。Storage 模塊負責管理 Spark 在計算過程中產生的數(shù)據,將那些在內存或磁盤、在本地或遠程存取數(shù)據的功能封裝了起來。在具體實現(xiàn)時 Driver 端和 Executor 端的 Storage 模塊構成了主從式的架構,即 Driver 端的 BlockManager 為 Master,Executor 端的 BlockManager 為 Slave。Storage 模塊在邏輯上以 Block 為基本存儲單位,RDD 的每個 Partition 經過處理后唯一對應一個 Block(BlockId 的格式為 rdd_RDD-ID_PARTITION-ID )。Master 負責整個 Spark 應用程序的 Block 的元數(shù)據信息的管理和維護,而 Slave 需要將 Block 的更新等狀態(tài)上報到 Master,同時接收 Master 的命令,例如新增或刪除一個 RDD。
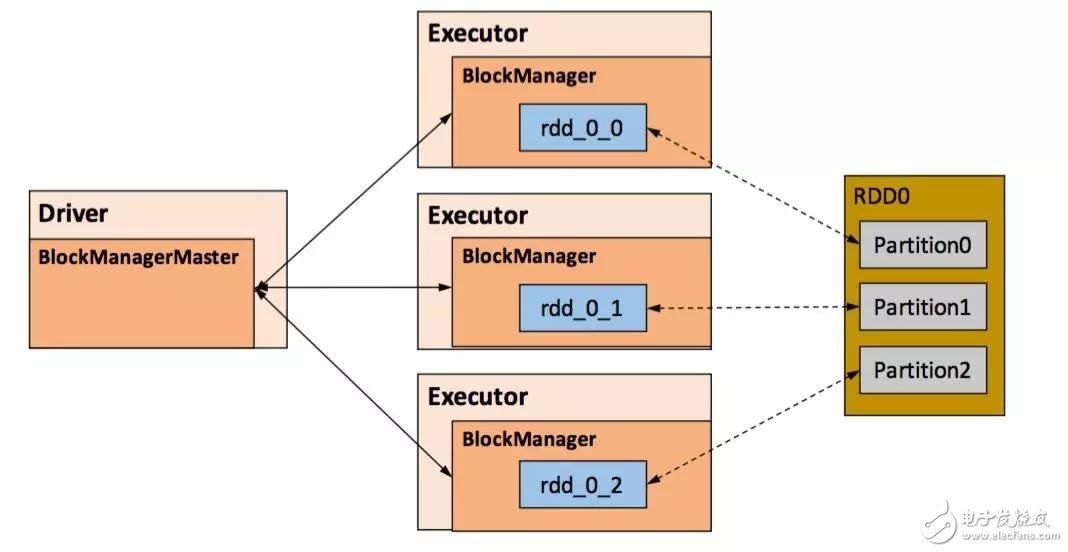
圖 7 . Storage 模塊示意圖
在對 RDD 持久化時,Spark 規(guī)定了 MEMORY_ONLY、MEMORY_AND_DISK 等 7 種不同的 存儲級別 ,而存儲級別是以下 5 個變量的組合:
清單 3 . 存儲級別
class?StorageLevel?private(?
private?var?_useDisk:?Boolean,?//磁盤?
private?var?_useMemory:?Boolean,?//這里其實是指堆內內存?
private?var?_useOffHeap:?Boolean,?//堆外內存?
private?var?_deserialized:?Boolean,?//是否為非序列化?
private?var?_replication:?Int?=?1?//副本個數(shù)?
)?
通過對數(shù)據結構的分析,可以看出存儲級別從三個維度定義了 RDD 的 Partition(同時也就是 Block)的存儲方式:
存儲位置:磁盤/堆內內存/堆外內存。如 MEMORY_AND_DISK 是同時在磁盤和堆內內存上存儲,實現(xiàn)了冗余備份。OFF_HEAP 則是只在堆外內存存儲,目前選擇堆外內存時不能同時存儲到其他位置;
存儲形式:Block 緩存到存儲內存后,是否為非序列化的形式。如 MEMORY_ONLY 是非序列化方式存儲,OFF_HEAP 是序列化方式存儲;
副本數(shù)量:大于 1 時需要遠程冗余備份到其他節(jié)點。如 DISK_ONLY_2 需要遠程備份 1 個副本。
2RDD 緩存的過程
RDD 在緩存到存儲內存之前,Partition 中的數(shù)據一般以迭代器(Iterator)的數(shù)據結構來訪問,這是 Scala 語言中一種遍歷數(shù)據集合的方法。通過 Iterator 可以獲取分區(qū)中每一條序列化或者非序列化的數(shù)據項(Record),這些 Record 的對象實例在邏輯上占用了 JVM 堆內內存的 other 部分的空間,同一 Partition 的不同 Record 的空間并不連續(xù)。
RDD 在緩存到存儲內存之后,Partition 被轉換成 Block,Record 在堆內或堆外存儲內存中占用一塊連續(xù)的空間。將Partition由不連續(xù)的存儲空間轉換為連續(xù)存儲空間的過程,Spark稱之為“展開”(Unroll)。Block 有序列化和非序列化兩種存儲格式,具體以哪種方式取決于該 RDD 的存儲級別。非序列化的 Block 以一種 DeserializedMemoryEntry 的數(shù)據結構定義,用一個數(shù)組存儲所有的對象實例,序列化的 Block 則以 SerializedMemoryEntry的數(shù)據結構定義,用字節(jié)緩沖區(qū)(ByteBuffer)來存儲二進制數(shù)據。每個 Executor 的 Storage 模塊用一個鏈式 Map 結構(LinkedHashMap)來管理堆內和堆外存儲內存中所有的 Block 對象的實例[6],對這個 LinkedHashMap 新增和刪除間接記錄了內存的申請和釋放。
因為不能保證存儲空間可以一次容納 Iterator 中的所有數(shù)據,當前的計算任務在 Unroll 時要向 MemoryManager 申請足夠的 Unroll 空間來臨時占位,空間不足則 Unroll 失敗,空間足夠時可以繼續(xù)進行。對于序列化的 Partition,其所需的 Unroll 空間可以直接累加計算,一次申請。而非序列化的 Partition 則要在遍歷 Record 的過程中依次申請,即每讀取一條 Record,采樣估算其所需的 Unroll 空間并進行申請,空間不足時可以中斷,釋放已占用的 Unroll 空間。如果最終 Unroll 成功,當前 Partition 所占用的 Unroll 空間被轉換為正常的緩存 RDD 的存儲空間,如下圖 8 所示。
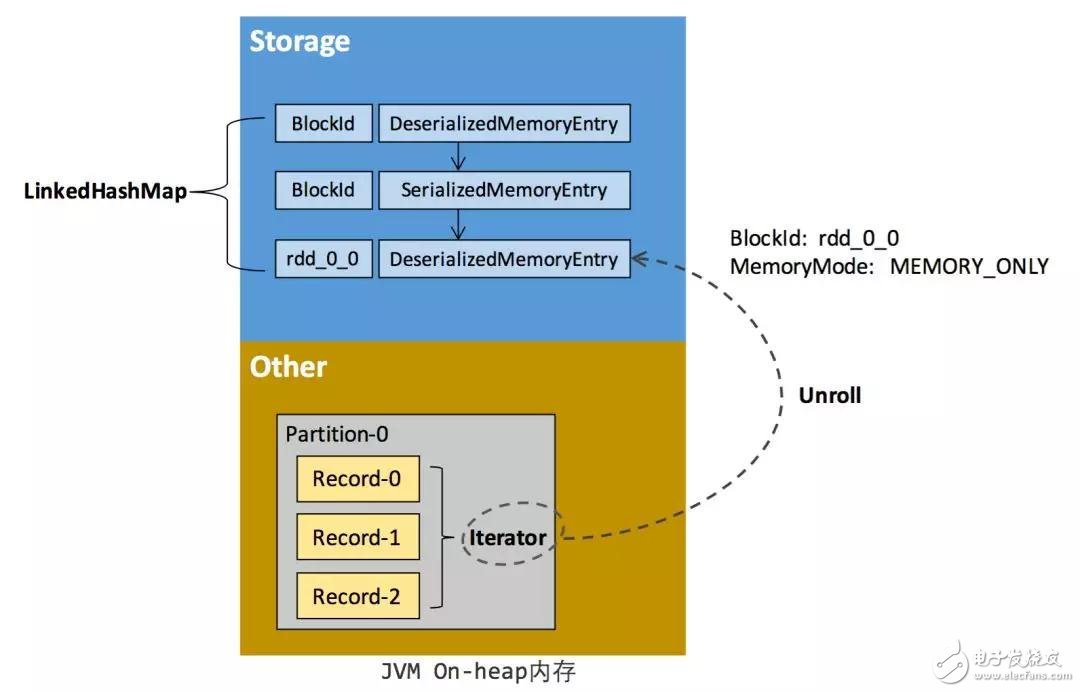
圖 8. Spark Unroll 示意圖
在圖 3 和圖 5 中可以看到,在靜態(tài)內存管理時,Spark 在存儲內存中專門劃分了一塊 Unroll 空間,其大小是固定的,統(tǒng)一內存管理時則沒有對 Unroll 空間進行特別區(qū)分,當存儲空間不足時會根據動態(tài)占用機制進行處理。
3淘汰和落盤
由于同一個 Executor 的所有的計算任務共享有限的存儲內存空間,當有新的 Block 需要緩存但是剩余空間不足且無法動態(tài)占用時,就要對 LinkedHashMap 中的舊 Block 進行淘汰(Eviction),而被淘汰的 Block 如果其存儲級別中同時包含存儲到磁盤的要求,則要對其進行落盤(Drop),否則直接刪除該 Block。
存儲內存的淘汰規(guī)則為:
被淘汰的舊 Block 要與新 Block 的 MemoryMode 相同,即同屬于堆外或堆內內存;
新舊 Block 不能屬于同一個 RDD,避免循環(huán)淘汰;
舊 Block 所屬 RDD 不能處于被讀狀態(tài),避免引發(fā)一致性問題;
遍歷 LinkedHashMap 中 Block,按照最近最少使用(LRU)的順序淘汰,直到滿足新 Block 所需的空間。其中 LRU 是 LinkedHashMap 的特性。
落盤的流程則比較簡單,如果其存儲級別符合_useDisk 為 true 的條件,再根據其_deserialized 判斷是否是非序列化的形式,若是則對其進行序列化,最后將數(shù)據存儲到磁盤,在 Storage 模塊中更新其信息。
四、執(zhí)行內存管理
1多任務間內存分配
Executor 內運行的任務同樣共享執(zhí)行內存,Spark 用一個 HashMap 結構保存了任務到內存耗費的映射。每個任務可占用的執(zhí)行內存大小的范圍為 1/2N ~ 1/N,其中 N 為當前 Executor 內正在運行的任務的個數(shù)。每個任務在啟動之時,要向 MemoryManager 請求申請最少為 1/2N 的執(zhí)行內存,如果不能被滿足要求則該任務被阻塞,直到有其他任務釋放了足夠的執(zhí)行內存,該任務才可以被喚醒。
2Shuffle 的內存占用
執(zhí)行內存主要用來存儲任務在執(zhí)行 Shuffle 時占用的內存,Shuffle 是按照一定規(guī)則對 RDD 數(shù)據重新分區(qū)的過程,我們來看 Shuffle 的 Write 和 Read 兩階段對執(zhí)行內存的使用:
Shuffle Write:
若在 map 端選擇普通的排序方式,會采用 ExternalSorter 進行外排,在內存中存儲數(shù)據時主要占用堆內執(zhí)行空間;
若在 map 端選擇 Tungsten 的排序方式,則采用 ShuffleExternalSorter 直接對以序列化形式存儲的數(shù)據排序,在內存中存儲數(shù)據時可以占用堆外或堆內執(zhí)行空間,取決于用戶是否開啟了堆外內存以及堆外執(zhí)行內存是否足夠。
Shuffle Read:
在對 reduce 端的數(shù)據進行聚合時,要將數(shù)據交給 Aggregator 處理,在內存中存儲數(shù)據時占用堆內執(zhí)行空間;
如果需要進行最終結果排序,則要將再次將數(shù)據交給 ExternalSorter 處理,占用堆內執(zhí)行空間。
在 ExternalSorter 和 Aggregator 中,Spark 會使用一種叫 AppendOnlyMap 的哈希表在堆內執(zhí)行內存中存儲數(shù)據,但在 Shuffle 過程中所有數(shù)據并不能都保存到該哈希表中,當這個哈希表占用的內存會進行周期性地采樣估算,當其大到一定程度,無法再從 MemoryManager 申請到新的執(zhí)行內存時,Spark 就會將其全部內容存儲到磁盤文件中,這個過程被稱為溢存(Spill),溢存到磁盤的文件最后會被歸并(Merge)。
Shuffle Write 階段中用到的 Tungsten 是 Databricks 公司提出的對 Spark 優(yōu)化內存和 CPU 使用的計劃[9],解決了一些 JVM 在性能上的限制和弊端。Spark 會根據 Shuffle 的情況來自動選擇是否采用 Tungsten 排序。Tungsten 采用的頁式內存管理機制建立在 MemoryManager 之上,即 Tungsten 對執(zhí)行內存的使用進行了一步的抽象,這樣在 Shuffle 過程中無需關心數(shù)據具體存儲在堆內還是堆外。
每個內存頁用一個 MemoryBlock 來定義,并用 Object obj 和 long offset 這兩個變量統(tǒng)一標識一個內存頁在系統(tǒng)內存中的地址。堆內的 MemoryBlock 是以 long 型數(shù)組的形式分配的內存,其 obj 的值為是這個數(shù)組的對象引用,offset 是 long 型數(shù)組的在 JVM 中的初始偏移地址,兩者配合使用可以定位這個數(shù)組在堆內的絕對地址;堆外的 MemoryBlock 是直接申請到的內存塊,其 obj 為 null,offset 是這個內存塊在系統(tǒng)內存中的 64 位絕對地址。Spark 用 MemoryBlock 巧妙地將堆內和堆外內存頁統(tǒng)一抽象封裝,并用頁表(pageTable)管理每個 Task 申請到的內存頁。
Tungsten 頁式管理下的所有內存用 64 位的邏輯地址表示,由頁號和頁內偏移量組成:
頁號:占 13 位,唯一標識一個內存頁,Spark 在申請內存頁之前要先申請空閑頁號;
頁內偏移量:占 51 位,是在使用內存頁存儲數(shù)據時,數(shù)據在頁內的偏移地址。
有了統(tǒng)一的尋址方式,Spark 可以用 64 位邏輯地址的指針定位到堆內或堆外的內存,整個 Shuffle Write 排序的過程只需要對指針進行排序,并且無需反序列化,整個過程非常高效,對于內存訪問效率和 CPU 使用效率帶來了明顯的提升[10]。
Spark 的存儲內存和執(zhí)行內存有著截然不同的管理方式:對于存儲內存來說,Spark 用一個 LinkedHashMap 來集中管理所有的 Block,Block 由需要緩存的 RDD 的 Partition 轉化而成;而對于執(zhí)行內存,Spark 用 AppendOnlyMap 來存儲 Shuffle 過程中的數(shù)據,在 Tungsten 排序中甚至抽象成為頁式內存管理,開辟了全新的 JVM 內存管理機制。
五、結束語
Spark 的內存管理是一套復雜的機制,且 Spark 的版本更新比較快,筆者水平有限,難免有敘述不清、錯誤的地方,若讀者有好的建議和更深的理解,還望不吝賜教。











 工商網監(jiān)
工商網監(jiān)
評論