 電子發燒友App
電子發燒友App


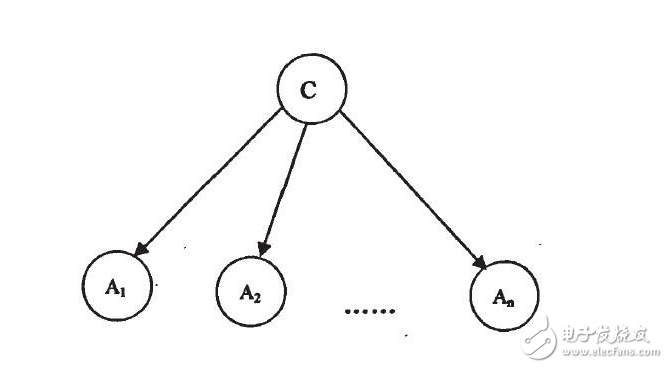
常見算法優缺點比較
機器學習算法數不勝數,要想找到一個合適的算法并不是一件簡單的事情。通常在對精度要求較高的情況下,最好的方法便是通過交叉驗證來對各個算法一一嘗試,進行比較后再調整參數以確保每個算法都能達到最優解,并從優中擇優。但是每次都進行這一操作不免過于繁瑣,下面小編來分析下各個算法的優缺點,以助大家有針對性地進行選擇,解決問題。
?
1.樸素貝葉斯
樸素貝葉斯的思想十分簡單,對于給出的待分類項,求出在此項出現的條件下各個類別出現的概率,以概率大小確定分類項屬于哪個類別。
優點:
1)樸素貝葉斯模型發源于古典數學理論,因此有著堅實的數學基礎,以及穩定的分類效率;
2)算法較簡單,常用于文本分類;
3)對小規模的數據表現很好,能夠處理多分類任務,適合增量式訓練。
缺點:
1)需要計算先驗概率;
2)對輸入數據的表達形式很敏感;
3)分類決策存在錯誤率。
?
2.邏輯回歸
優點:
1)實現簡單,廣泛地應用于工業問題上;
2)可以結合L2正則化解決多重共線性問題;
3)分類時計算量非常小,速度很快,存儲資源低;
缺點:
1)不能很好地處理大量多類特征或變量;
2)容易欠擬合,一般準確度較低;
3)對于非線性特征,需要進行轉換;
4)當特征空間很大時,邏輯回歸的性能不是很好;
5)只能處理兩分類問題(在該基礎上衍生出來的softmax可以用于多分類),且必須線性可分。
?
3.線性回歸
線性回歸與邏輯回歸不同,它是用于回歸的,而不是用于分類。其基本思想是用梯度下降法對最小二乘法形式的誤差函數進行優化。
優點:實現簡單,計算簡單;
缺點:不能擬合非線性數據。
4.最近鄰算法
優點:
1)對數據沒有假設,準確度高;
2)可用于非線性分類;
3)訓練時間復雜度為O(n);
4)理論成熟,思想簡單,既可以用來做分類也可以用來做回歸。
缺點:
1)計算量大;
2)需要大量的內存;
3)樣本不平衡問題(即有些類別的樣本數量很多,而其它樣本的數量很少)。
?
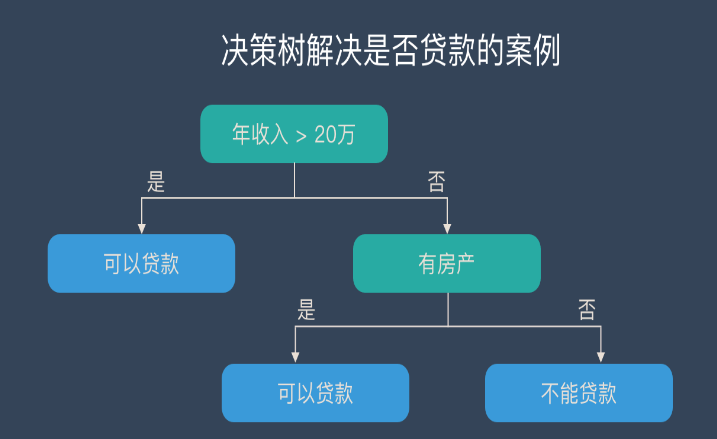
5.決策樹
優點:
1)能夠處理不相關的特征;
2)在相對短的時間內能夠對大型數據源做出可行且效果良好的分析;
3)計算簡單,易于理解,可解釋性強;
4)比較適合處理有缺失屬性的樣本。
缺點:
1)忽略了數據之間的相關性;
2)容易發生過擬合(隨機森林可以很大程度上減少過擬合);
3)在決策樹當中,對于各類別樣本數量不一致的數據,信息增益的結果偏向于那些具有更多數值的特征。












 工商網監
工商網監
評論