 電子發燒友App
電子發燒友App


應用貝葉斯網絡分類器進行分類主要分成兩階段。第一階段是貝葉斯網絡分類器的學習,即從樣本數據中構造分類器,包括結構學習和CPT 學習;第二階段是貝葉斯網絡分類器的推理,即計算類結點的條件概率,對分類數據進行分類。這兩個階段的時間復雜性均取決于特征值間的依賴程度,甚至可以是NP 完全問題,因而在實際應用中,往往需要對貝葉斯網絡分類器進行簡化。根據對特征值間不同關聯程度的假設,可以得出各種貝葉斯分類器,Naive Bayes、TAN、BAN、GBN 就是其中較典型、研究較深入的貝葉斯分類器。
貝葉斯分類器的分類原理是通過某對象的先驗概率,利用貝葉斯公式計算出其后驗概率,即該對象屬于某一類的概率,選擇具有最大后驗概率的類作為該對象所屬的類。也就是說,貝葉斯分類器是最小錯誤率意義上的優化。目前研究較多的貝葉斯分類器主要有四種,分別是:Naive Bayes、TAN、BAN和GBN。
貝葉斯分類器
貝葉斯分類器的分類原理是通過某對象的先驗概率,利用貝葉斯公式計算出其后驗概率,即該對象屬于某一類的概率,選擇具有最大后驗概率的類作為該對象所屬的類。也就是說,貝葉斯分類器是最小錯誤率意義上的優化。目前研究較多的貝葉斯分類器主要有四種,分別是:Naive Bayes、TAN、BAN和GBN。
訓練
和所有監督算法一樣,貝葉斯分類器是利用樣本進行訓練的,每個樣本包含了一個特征列表和對應的分類。假定我們要對一個分類器進行訓練,使其能夠正確的判斷出:一個包含“python”的文檔究竟是編程語言的,還是關于蛇的。
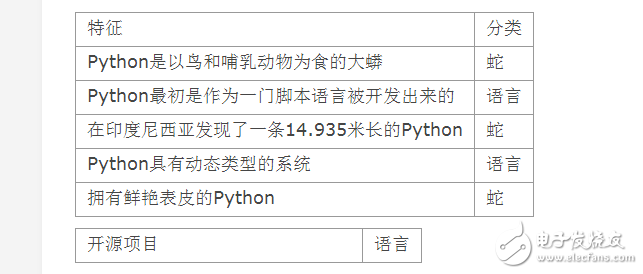
分類器記錄了它迄今為止見過的所有特征,以及這些特征與某個特定分類相關的數字概率。分類器逐一接受樣本的訓練。 當經過某個樣本的訓練之后,分類器會更新該樣本中特征與分類的概率,同時還會生成一個新的概率,即:在一篇屬于某個分類的文檔中,含有指定單詞的概率。例如
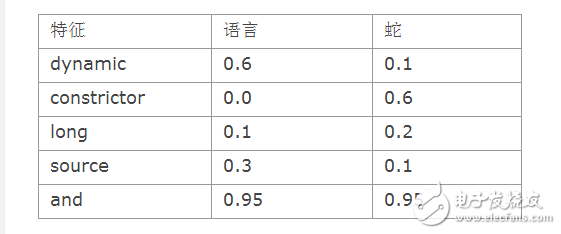
從上表中我們可以看到,經過訓練之后,特征與各種分類的關聯性更加明確了。單詞“constrictor”屬于蛇的分類概率更大,而單詞“dynamic”屬于編程語言的概率更大。
另一方便,有些特征的所屬分類則沒有那么明確。比如:單詞“and”出現在兩個分類中的概率是差不多的(單詞and幾乎會出現在每一篇文檔中,不管它屬于哪一個分類。)分類器在經過訓練之后。只會保留一個附有相應概率的特征列表,與某些其他的分類方法不同,此處的原始數據在訓練之后,就沒有必要再加以保存了。
分類
當一個貝葉斯分類器經過訓練之后,我們就可以利用它來對新的項目進行自動分類了。假定我們有一篇新的文檔,包含了“long” “dynamic” 和 “source”。
樸素貝葉斯分類器是通過下面的公式將概率組合起來的: P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document)
此處:
P( Document | Category) = P (Word1 | Category ) * P( Word2) / P(Category )
p( Document | Category) 的取值來自于上表,比如 P( dynamic | language) = 0.6
p(Category) 的取值則等于某個分類出現的總體概率,因為“ language ” 有一般的機會都會出現,所以 P(language ) 的值為0.5 。無論是哪個分類,只要其P( Category | Document) 的值相對較高,它就是我們預期的分類。
我們需要一個定義一個特征提取函數,該函數的作用是將我們用以訓練或分類的數據轉化成一個特征列表。
docclass.getwords(‘python is a dynamic language’) {‘python’:1,‘dymaic’:1,‘language’:1}
上述函數可用于創建一個新的分類器,針對字符串進行訓練: cl = docclass.nativebayes(docclass.getwords)cl.setdb(‘test.db’) cl.train(‘pythons are constrictors’,‘snake’) cl.train(‘python has dynamic types’,‘language’)cl.train(‘python was developed as a scripting language’,‘language’)
然后進行分類 cl.classify(‘dynamic programming’) u‘language’ cl.classify(‘boa constrictors’) u‘snake’
對于允許使用的分類數量,此處并沒有任何的限制,但是為了使分類器有一個良好的表現,我們需要為每個分類提供大量的樣本。
貝葉斯分類器優點和缺點
樸素貝葉斯分類器與其他方法相比最大的優勢或許就在于,它在接受大數據量訓練和查詢時所具備的的高速度。即使選用超大規模的訓練集,針對每個項目通常也只會有相對較少的特征數,并且對項目的訓練和分類頁僅僅是針對特征概率的數學運算而已。
尤其當訓練量逐漸遞增時則更加如此--在不借助任何舊有訓練數據的前提下,每一組新的訓練數據都有可能會引起概率值變化。對于一個如垃圾郵件過濾這樣的應用程序而言,支持增量式訓練的能力是非常重要的,因為過濾程序時常要對新到的郵件進行訓練,然后必須即可進行相應的調整;更何況,過濾程序也未必有權限訪問已經收到的所有郵件信息。
樸素貝葉斯分類器的另一大優勢是,對分類器實際學習狀況的解釋還是相對簡單的。由于每個特征的概率值都被保存了起來,因此我們可以在任何時候查看數據庫,找到最合適的特征來區分垃圾郵件和非垃圾郵件,或是編程語言和蛇。保存在數據庫中的這些信息都很有價值,它們有可能被用于其他的應用程序,或者作為構筑這些應用程序的一個良好基礎。
樸素貝葉斯分類器的最大缺陷就是,它無法處理基于特征組合所產生的變化結果。假設有如下這樣一個場景,我們正在嘗試從非垃圾郵件中鑒別出垃圾郵件來:假設我們構建的是一個Web應用程序,因為單詞“online”市場會出現在你的工作郵件中。而你的好友則在一家藥店工作,并且喜歡給你發一些他碰巧在工作中遇到的奇聞趣事。同時,和大多數不善于嚴密保護自己郵件地址的人一樣,偶爾你也會收到一封包含單詞”online pharmacy“的垃圾郵件。
也許你已經看出此處的難點--我們往往會告訴分類器”onlie“和”pharmacy“是出現在非垃圾郵件中的,因此這些單詞相對于非垃圾郵件的概率會高一些。當我們告訴分類器有一封包含單詞”onlie pharmacy“ 的郵件屬于垃圾郵件時,則這些單詞的概率又會進行相應的調整,這就導致了一個經常性的矛盾。由于特征的概率是單獨給出的,因此分類器對于各種組合的情況一無所知。在文檔分類中,這通常不是什么大問題,因為一封包含單詞”online pharmacy“的郵件中可能還會有其他的特征可以說明它是垃圾郵件,但是在面對其他問題時,理解特征的組合可能是至關重要的。










 工商網監
工商網監
評論