 FGIA 中的主要問題和挑戰
FGIA 中的主要問題和挑戰
在本文中,來自曠視科技、南京大學和早稻田大學的研究者對基于深度學習的細粒度圖像分析進行了綜述,從細粒度圖像識別、檢索和生成三個方向展開論述。此外,他們還對該領域未來的發展方向進行了討論。
計算機視覺(CV)是用機器來理解和分析圖像的過程,是人工智能中一個重要分支。在 CV 的各個研究領域中,細粒度圖像分析(fine-grained image analysis, FGIA)是一個長期存在的基礎性問題,而且在各種實際應用(比如鳥的種類、汽車模型、商品識別等)中無處不在。由細粒度特性造成的類間(inter-class)小變化和類內(intra-class)大變化使得這一問題具有極大的挑戰性。由于深度學習的蓬勃發展,近年來應用了深度學習的 FGIA 取得了顯著的進步。
本文系統地對基于深度學習的 FGIA 技術進行了綜述。具體來說,本文將針對 FGIA 技術的研究分為三大類:細粒度圖像識別、細粒度圖像檢索和細粒度圖像生成。本文還討論了其他 FGIA 的重要問題,比如公開可用的基準數據集及其在相關領域的特定應用。本文在結尾處強調了未來仍需進一步探討的幾個方向以及待解決的問題。
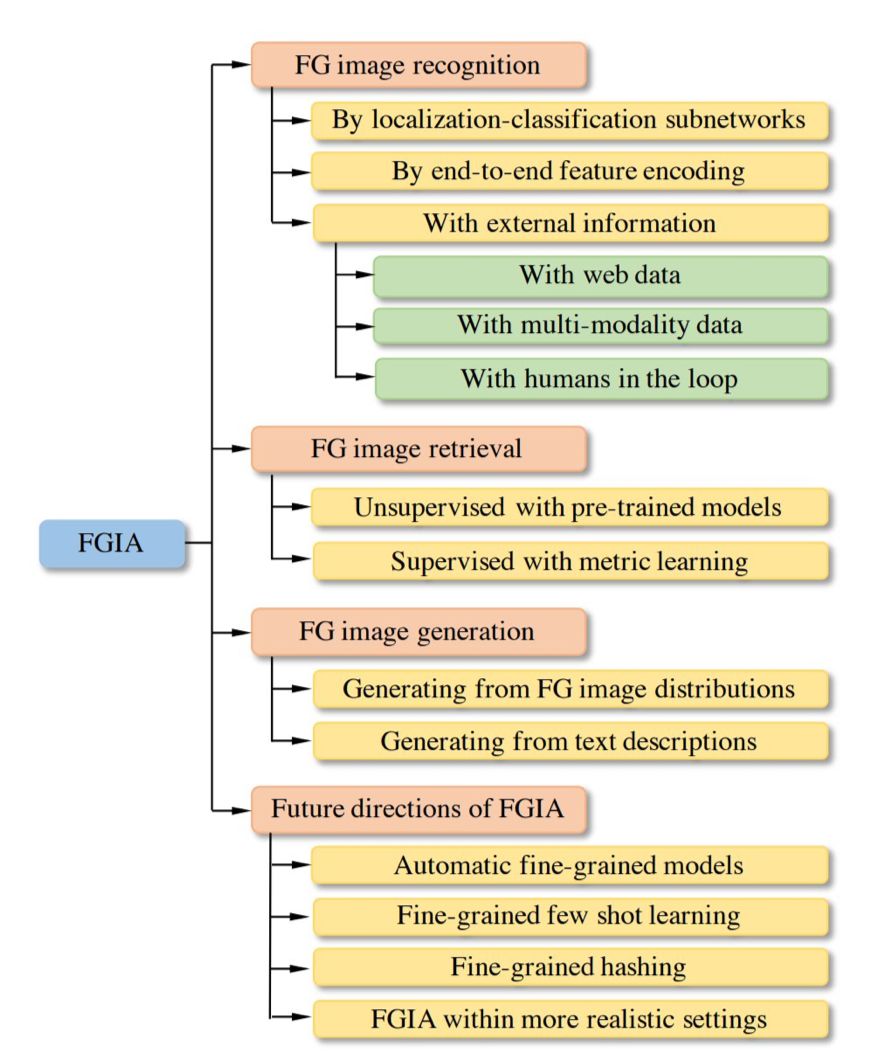
綜述結構。
在環太平洋國家舉辦的另一個重要的 AI 會議中,本文作者(魏秀參、吳建鑫)針對細粒度圖像分析組織了具體的教程。該教程中提供了一些關于細粒度圖像分析的額外的細節信息,所以在此向想深入了解的讀者推薦該教程。

此外,論文作者還開放了一個細粒度圖像分析的主頁,內含代表性論文、代碼、數據集等。

背景:FGIA 中的主要問題和挑戰
FGIA 與一般的圖像分析之間的區別在于:在一般的圖像分析中,目標對象屬于粗粒度的元類別(例如:鳥、橙子和狗),因此它們看起來非常不同。但在 FGIA 中,由于對象都屬于一個元類別的子類,細粒度的特性導致它們看起來非常相似。我們以圖像識別為例。如圖 1 所示。
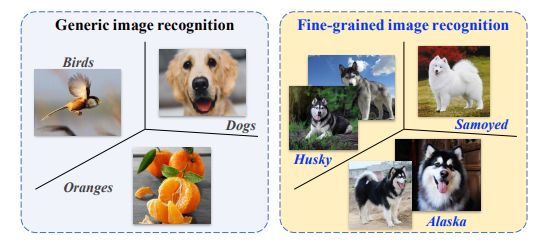
圖 1:細粒度圖像分析(右)與一般的圖像分析(左)
此外,細粒度特性也會導致由子類別高度相似而造成的類間變化較小以及因姿勢、尺寸和角度等不同而造成的類內變化大的問題,如圖 3 所示。

圖 3:細粒度圖像分析的關鍵挑戰
基準數據集
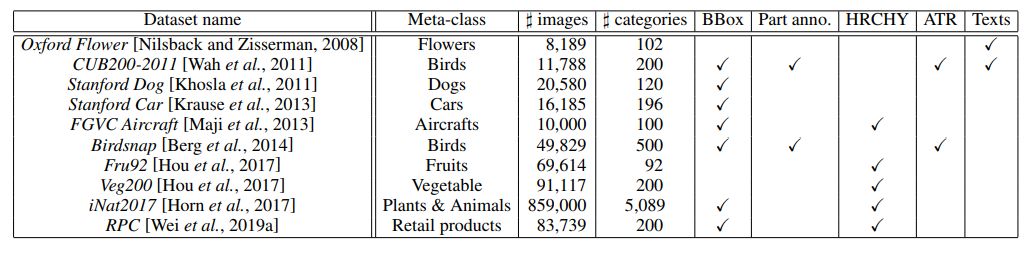
表 1:主流細粒度圖像數據集匯總
表 1 中列出了細粒度問題中常用的圖像數據集,并特地標出了它們的元類別、細粒度圖像的數量、細粒度類別的數量和額外可用的不同種類的監督(即邊界框、部位注釋、層次標簽、屬性標簽以及文本視覺描述等),參見圖 5。
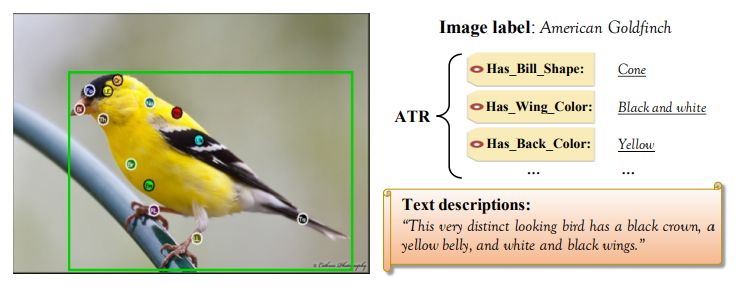
圖 5:帶有 CUB200-2011 監督信息的示例圖像
細粒度圖像識別
這些細粒度識別方法可以總結為三個范式:(1)用定位分類子網絡進行細粒度識別;(2)用端到端的特征編碼進行細粒度識別;(3)用外部信息進行細粒度識別。
其中,第一個范式和第二個范式只用和細粒度圖像相關的監督(比如圖像標簽、邊界框以及部分注釋等)進行了限制。此外,由于細粒度存在的挑戰,自動識別系統還不能實現良好的性能。因此,研究人員逐漸試著在細粒度識別問題中融入外部但易于獲得的信息(比如網頁數據、文本描述等)來進一步提升準確率,這對應了細粒度識別的第三個范式。細粒度識別中常用的評估指標是數據集所有從屬類別的平均分類準確率。
4.1 用定位分類子網絡進行細粒度識別
為了緩解類內變化較大的問題,細粒度社區注重捕獲細粒度對象具有辨別性的語義部分,然后再建立和這些語義部分相關的中級表征用于最后的分類。具體而言,研究人員為了定位這些關鍵部位,設計出了定位子網絡。之后再連接一個用于識別的分類子網絡。這兩個子網絡合作組成的框架就是第一個范式,也就是用定位分類子網絡進行細粒度識別。
有了定位信息(比如部位邊界框或分割掩碼),就可以獲得更有辨別力的中級(部位)表征。此外,它還進一步提高了分類子網絡的學習能力,這可以顯著增強最終識別的準確率。
屬于這一范式的早期工作依賴于額外的密集部位注釋(又稱關鍵點定位)來定位目標的語義關鍵部位(例如頭部、軀干)。它們中的一些學習了基于部位的檢測器 [Zhang et al.,2014;Lin et al.,2015a],還有一些利用分割方法來定位部位。然后,這些方法將多個部位特征當做整個圖像的表征,并將其饋送到接下來的分類子網絡中進行最終的識別。因此,這些方法也稱為基于部位的識別方法。
但這樣的密集部位注釋是勞動密集型工作,限制了細粒度應用在現實世界中的可擴展性和實用性。最近還出現了一種趨勢,在這種范式下,更多只需要圖像標簽 [Jaderberg et al.,2015;Fu et al.,2017;Zheng et al.,2017;Sun et al.,2018] 就可以準確定位這些部位的技術出現了。它們共同的思路是先找到相對應的部位,然后再比較它們的外觀。具體而言,我們希望能捕獲到在細粒度類別中共享的語義部位(比如頭部和軀干),同時還希望發現這些部位表征之間的微小差別。像注意力機制 [Yang et al.,2018] 和多階段策略 [He 和 Peng,2017b] 這樣的先進技術可以對集成的定位分類子網絡進行復雜的聯合訓練。
4.2 用端到端的特征編碼進行細粒度識別
和第一個范式不同,第二個范式是端到端特征編碼,它是通過開發用于細粒度識別的強大深度模型來直接學習更具辨別力的表征實現的。這些方法中最具代表性的方法是雙線性 CNN(Bilinear CNNs[Lin et al.,2015b]),它用來自兩個深度 CNN 池化后的特征的外積來表征圖像,從而對卷積激活的高階統計量進行編碼,以增強中級學習能力。由于其模型容量較高,雙線性 CNN 在細粒度識別中實現了優良的性能。但雙線性特征的維度極高,因此它無法在現實世界中應用,尤其是大規模應用。
最近也有一些嘗試解決這一問題的工作,比如 [Gao et al.,2016;Kong 和 Fowlkes,2017;Cui et al.,2017],[Pham 和 Pagh,2013;Charikar et al.,2002] 試著用張量草圖(tensor sketching)來聚合低維嵌入,該方法可以近似雙線性特征,還可以保持相當程度或更高的準確率。其他工作,比如 [Dubey et al.,2018] 則專門為細粒度量身設計了特定的損失函數,它可以驅動整個深度模型學習具有辨別性的細粒度表征。
4.3 用外部信息進行細粒度識別
如前文所述,除了傳統的識別范式外,另一種范式是利用外部信息(比如網絡數據、多模態數據或人機交互)來進一步幫助細粒度識別。詳細內容參見論文。
細粒度圖像檢索
除了圖像識別,細粒度檢索是 FGIA 的另一個重要方面,它也是當前的研究熱點。在細粒度檢索中,常用的評估指標是平均精度均值(mean average precision,mAP)。在細粒度圖像檢索中,給出同一個子類(比如鳥類或車類)的數據庫圖像和要查詢的圖像,它可以在不依賴任何其他監督信號的情況下,返回與查詢圖像屬于同一類別的圖像,如圖 7 所示。
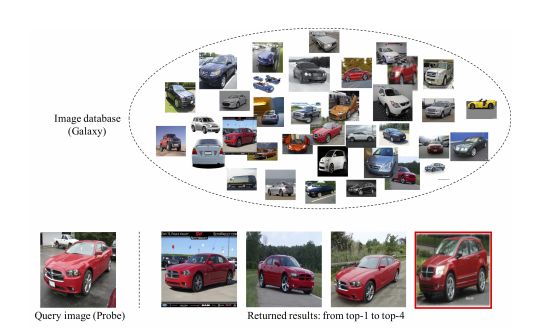
圖 7:細粒度檢索圖示。
一般的圖像檢索是基于圖像內容(比如紋理、顏色和形狀)的相似性來檢索非常相似的圖像,而細粒度檢索則側重于檢索屬于同一類別(比如同一物種的生物或一種車型)的圖像。同時,細粒度圖像中目標的差別很小,而在姿勢、尺寸以及角度等方面存在差異。
[Wei et al.,2017] 首次試著用深度學習進行細粒度圖像檢索。該模型用預訓練的 CNN 模型,在無監督的情況下,通過在細粒度圖像中定位主要目標選出了有意義的深度描述符,進一步揭示了只用去除背景或噪聲的深度描述符可以顯著提高檢索任務的性能。為了打破通過預訓練模型進行無監督細粒度檢索的局限性,一些實驗 [Zheng et al.,2018;Zheng et al.,2019] 傾向于在有監督指標學習范式下,研究出全新的損失函數。與此同時,他們還為細粒度目標量身設計了額外的特定子模塊,例如,[Zheng et al.,2018] 受 [Wei et al.,2017] 啟發后提出的弱監督定位模塊。
細粒度圖像生成
除了監督學習任務,圖像生成也是無監督學習中的代表性主題。它用像 GAN[Goodfellow et al.,2014] 這樣的深度生成模型來學習合成看起來很真實的逼真圖像。隨著生成圖像的質量越來越高,更具挑戰性的任務——細粒度圖像生成,出現了。顧名思義,細粒度生成可以在細粒度類別(比如特定人物的面部或從屬類別中的對象)中合成圖像。
這方面的第一項工作是 [Bao et al.,2017] 提出的 CVAE-GAN,它將變分自編碼器和條件生成過程下的生成對抗網絡結合在一起,來解決這一問題。具體而言,CVAE-GAN 將圖像建模成概率模型中的標簽和隱含屬性的組合。通過改變饋入生成模型的細粒度類別,它就可以生成特定類別的圖像。最近,根據文本描述生成圖像 [Xu et al.,2018b] 因其多樣化和實用性(如藝術生成和計算機輔助設計)而流行起來。執行配備了注意力的生成網絡后,模型可以根據文本描述中的相關細節來合成細微區域的細粒度細節。
與細粒度圖像分析相關領域的特定應用
在真實世界中,基于深度學習的細粒度圖像分析技術在不同領域中都得到了應用,并表現出了很好的性能,例如在推薦系統中檢索衣服或鞋 [Song et al.,2017],在電子商務平臺上識別時尚圖像 [Wei et al.,2016] 以及在智能零售平臺中識別產品 [Wei et al.,2019a] 等。這些應用都和 FGIA 的細粒度檢索與識別高度相關。
此外,如果我們向下移動粒度范圍,極端點說,也可以將人臉識別看作細粒度識別的實例,在這個例子中粒度降到了身份粒度級別之下。此外,人員或機動車的再識別也是細粒度的一項相關任務,這項任務的目標是確定兩張圖像是否屬于同一個特定的人或機動車。顯然,再識別任務的粒度等級也在身份粒度之下。
在實際應用中,這些工作都遵循了 FGIA 的思路,來解決相關領域的特定任務,FGIA 的思路包括捕獲目標極具辨別性的部位(人臉、人和機動車)[Suh et al.,2018]、發現由粗到細的結構信息 [Wei et al.,2018b] 以及開發基于屬性的模型 [Liu et al.,2016] 等等。
未來的方向
在這一部分,研究者明確指出了 FGIA 相關領域中尚未解決的問題,以及一些未來的研究趨勢。
自動細粒度模型
AutoML 和 NAS 的最新方法在計算機視覺的各種應用中都取得了和手工設計架構相媲美、甚至更好的結果。因此,希望可以利用 AutoML 或 NAS 技術開發自動細粒度模型,有望找到更好、更合適的深度模型,同時也可以反向促進 AutoML 和 NAS 研究的進步。
細粒度 few-shot 學習
我們最好的深度學習細粒度系統需要成百上千個標記好的樣本。更糟的是,細粒度圖像的監督不僅耗時而且昂貴,因為細粒度目標是由該領域的專家做準確標記的。因此,現實應用迫切需要開發出基于小樣本的細粒度學習方法(fine-grained few-shot,FGFS)[Wei et al.,2019b]。FGFS 任務需要學習系統以元學習的方式,根據少量(只有一個或少于五個)樣本構建針對全新細粒度類別的分類器。魯棒的 FGFS 方法可以很大程度上地增強細粒度識別的可用性和可擴展性。
細粒度哈希
在像細粒度圖像檢索這樣的實際應用中,會自然地出現這樣的問題——在參考數據非常大的情況下,找到準確的最近鄰的成本是非常高的。哈希 [Wang et al.,2018;Li et al.,2016] 是近似最近鄰搜索中最流行也最有效的技術之一,它有處理大量細粒度數據的潛力。因此,細粒度哈希是 FGIA 中值得進一步探索的方向。
在更實際的環境中進行細粒度分析
細粒度圖像分析還有許多新穎的主題——用域自適應進行細粒度分析、用知識遷移進行細粒度分析、用長尾分布進行細粒度分析以及在資源受限的嵌入設備上運行細粒度分析等。這些更高級也更實際的 FGIA 都很值得進行大量的研究工作。
-
深度學習
+關注
關注
73文章
5507瀏覽量
121272 -
曠視科技
+關注
關注
1文章
153瀏覽量
11192
原文標題:超全深度學習細粒度圖像分析:項目、綜述、教程一網打盡
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
生產HDI線路板需要解決的主要問題
深度學習中RNN的優勢與挑戰
DCS系統實施中的常見挑戰
數字孿生技術實施中的挑戰

康謀分享 | 在基于場景的AD/ADAS驗證過程中,識別挑戰性場景!

高速信號傳輸中的抖動和眼圖挑戰
在物聯網(IoT)應用中實現電磁兼容性所面臨的挑戰

SiC與GaN 功率器件中的離子注入技術挑戰
談電動汽車充電樁電能計量系統主要問題
熒光分光光度計常用的光源是什么 熒光測定中應該注意的主要問題
車內語音識別數據在智能駕駛中的應用與挑戰
環境試驗箱中濕度控制所面臨的挑戰

DC電源模塊在醫療設備中的應用挑戰與解決方案






 工商網監
工商網監
評論