 BigBiGAN問世,“GAN父”都說酷的無監督表示學習模型有多優秀?
BigBiGAN問世,“GAN父”都說酷的無監督表示學習模型有多優秀?
眾所周知,對抗訓練生成模型(GAN)在圖像生成領域獲得了不凡的效果。盡管基于GAN的無監督學習方法取得了初步成果,但很快被自監督學習方法所取代。
DeepMind近日發布了一篇論文《Large Scale Adversarial Representation Learning》(大規模對抗性表示學習),提出了無監督表示學習新模型BigBiGAN。

致力于將圖像生成質量的提升轉化為表征學習性能的提高,基于BigGAN模型的基礎上提出了BigBiGAN,通過添加編碼器和修改鑒別器將其擴展到圖像學習。作者評估了BigBiGAN模型的表征學習能力和圖像生成功能,證明在ImageNet上的無監督表征學習以及無條件圖像生成,該模型達到了目前的最佳性能。
論文發布后,諸多AI大牛轉發并給出了評價。
“GAN之父”Ian Goodfellow表示這很酷,在他讀博士期間,就把樣本生成雙產物的表示學習感興趣,而不是樣本生成本身。

特斯拉AI負責人Andrej Karpathy則表示,自我監督的學習是一個非常豐富的領域(但需要比ImageNet提供更高的密度和結構),這將避免大規模數據集的當前必要性(或在RL中推出)。

1、介紹
近年來,圖像生成模型快速發展。雖然這些模型以前僅限于具有單模或多模的結構域,生成的圖像結構簡單,分辨率低,但隨著模型和硬件的發展,已有生成復雜、多模態,高分辨率圖像的能力。
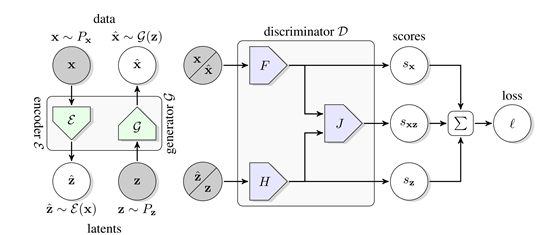
圖1 BigBiGAN框架框圖
聯合鑒別器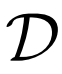
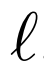 ,輸入是數據潛在對,
,輸入是數據潛在對,
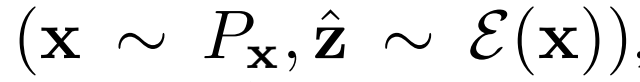
,從數據分布Px和編碼器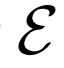 輸出中采樣,或
輸出中采樣,或
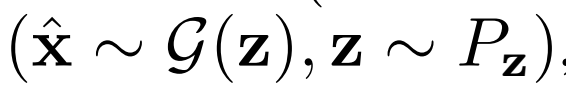
從生成器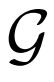 輸出和潛在分布Pz中采樣。損失
輸出和潛在分布Pz中采樣。損失 包括一元數據項
包括一元數據項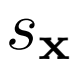 和一元潛在項
和一元潛在項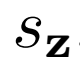 ,以及將數據和潛在分布聯系起來的聯合項
,以及將數據和潛在分布聯系起來的聯合項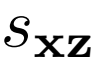 。
。
通過BiGAN或ALI框架學習的編碼器,是ImageNet上用于下游任務的可視化表示學習的有效手段。然而,該方法使用了DCGAN樣式生成器,無法在該數據集上生成高質量圖像,因此編碼器可以建模的語義非常有限。作者基于該方法,使用BigGAN作為生成器,能夠捕獲ImageNet圖像中存在的多模態和出現的大部分結構。總體而言,本文的貢獻如下:
(1)在ImageNet上,BigBiGAN(帶BigGAN的BiGAN生成器)匹配無監督表征學習的最新技術水平
(2)為BigBiGAN提出了一個穩定版本的聯合鑒別器
(3)對模型設計選擇進行了全面的實證分析和消融實驗
(4)表征學習目標還有助于無條件圖像生成,并展示無條件ImageNet生成的最新結果
2、BigBiGAN
BiGAN、ALI方法作為GAN框架的擴展,能夠學習可以用作推理模型或特征表示的編碼器。給定數據項x的分布Px(例如,圖像)和潛在項z的分布Pz(通常是像各向同性高斯N(0;I)的簡單連續分布),生成器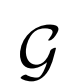 模擬條件概率分布
模擬條件概率分布
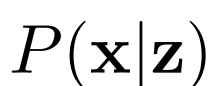
,給定潛在項z后數據項x的概率值,如標準GAN生成器。編碼器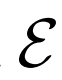 對逆條件分布
對逆條件分布
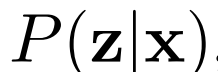
進行建模,預測給定數據項x的情況下,潛在項z的概率值。
除了添加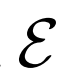 之外,BiGAN框架中對GAN的另一種修改是聯合鑒別器
之外,BiGAN框架中對GAN的另一種修改是聯合鑒別器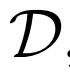 - 潛在項對(x,z)(而不僅僅是標準GAN中的數據項x),并且學習區分數據分布和編碼器對,生成器和潛在分布。具體地說,它的輸入對是
- 潛在項對(x,z)(而不僅僅是標準GAN中的數據項x),并且學習區分數據分布和編碼器對,生成器和潛在分布。具體地說,它的輸入對是
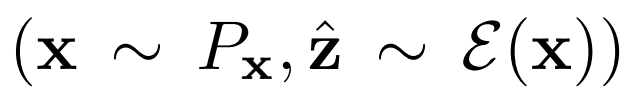
和
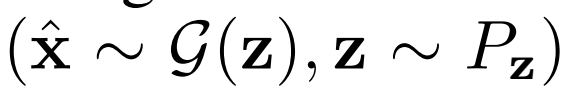
,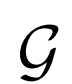 和
和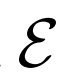 的目標是“欺騙”鑒別器,使得被采樣的兩個聯合概率分布
的目標是“欺騙”鑒別器,使得被采樣的兩個聯合概率分布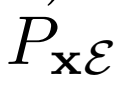 和
和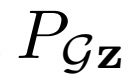 難以區分。GAN框架的目標,定義如下:
難以區分。GAN框架的目標,定義如下:
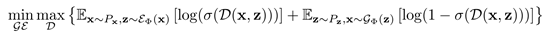
在這個目標下,在最優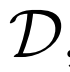
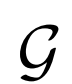 和
和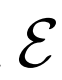 最小化聯合分布
最小化聯合分布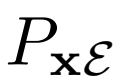 和
和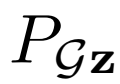 之間的Jensen-Shannon散度,因此在全局最優時,兩個聯合分布
之間的Jensen-Shannon散度,因此在全局最優時,兩個聯合分布
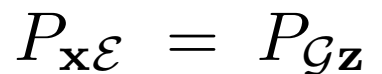
匹配。此外,在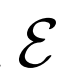 和
和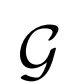 是確定性函數的情況下(即,學習條件分布
是確定性函數的情況下(即,學習條件分布

和
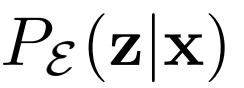
是Dirac δ函數),這兩個函數是全局最優的逆:例如
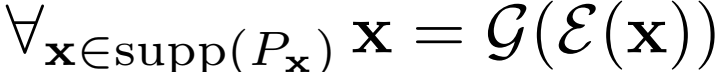
,最佳聯合鑒別器有效地對x和z施加 重建成本。
重建成本。
具體地,鑒別器損失值
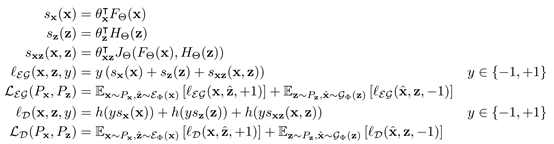
其中
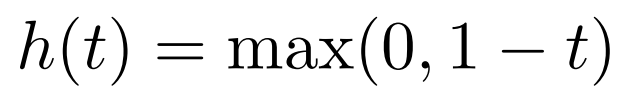
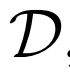
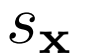
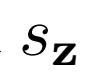
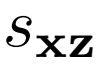
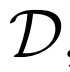
優化 和
和 參數
參數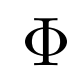
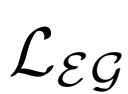
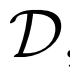
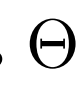
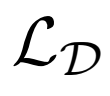
3、評估
作者在未標記的ImageNet上訓練BigBiGAN,固定其表征學習結果,然后在其輸出上訓練線性分類器,使用所有訓練集標簽進行全面監督學習。 作者還測量圖像生成性能,其中
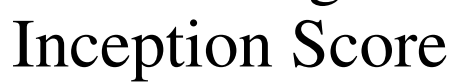
IS)和
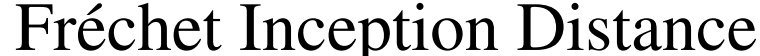
FID)作為標準指標。
3.1 消融
作者先評估了多種模型,見表1。作者使用不同的種子對每個變體進行三次運行并記錄每個度量的平均值和標準差。
潛在分布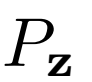 隨機值
隨機值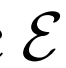 :
:
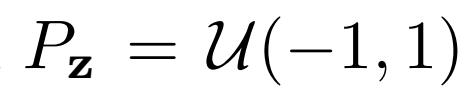
,其中在給定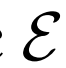 和線性輸出
和線性輸出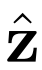 的情況下,預測
的情況下,預測
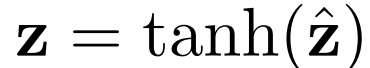
一元損失:
評估刪除損失函數的一元項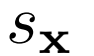
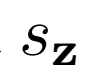 影響。只有z一元項和沒有一元項的IS和FID性能要比只有x一元項和兩者都有的性能差,結果表明x一元項對生成性能有很大的正面影響。
影響。只有z一元項和沒有一元項的IS和FID性能要比只有x一元項和兩者都有的性能差,結果表明x一元項對生成性能有很大的正面影響。
生成器 容量:
容量:
為了證明生成器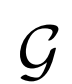 在表征學習中的重要性,作者改變生成器的容量觀察對結果的影響。實驗結果表明,好的圖像生成器模型能提高表征學習能力。
在表征學習中的重要性,作者改變生成器的容量觀察對結果的影響。實驗結果表明,好的圖像生成器模型能提高表征學習能力。
帶有不同分辨率的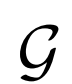 的高分辨率
的高分辨率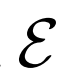 :
:
使用更高的分辨率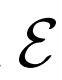 ,盡管
,盡管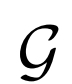 的分辨率相同,但是生成結果顯著改善(尤其是通過FID)。
的分辨率相同,但是生成結果顯著改善(尤其是通過FID)。
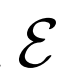 結構:
結構:
使用不同結構的評估性能,結果表明網絡寬度增加,性能會得到提升。
解耦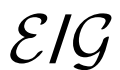 優化:
優化:
將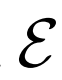 優化器與
優化器與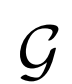 的優化器分離,并發現簡單地使用10倍的E學習速率可以顯著加速訓練并改善最終表征學習結果。
的優化器分離,并發現簡單地使用10倍的E學習速率可以顯著加速訓練并改善最終表征學習結果。
3.2與已有方法比較
表征學習
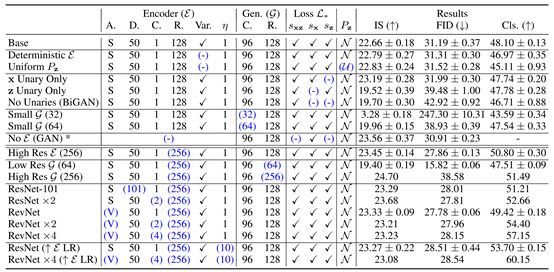
表1:BigBiGAN變體的結果
在生成圖像的IS和FID中,以及ImageNet top-1分類準確率,根據從訓練集中隨機抽樣的10K圖像的分割計算,稱為Train分裂。每行中基本設置的更改用藍色突出顯示。具有誤差范圍的結果(寫為“μ±σ”)是具有不同隨機種子的三次運行的平均值和標準偏差。
表2:使用監督邏輯回歸分類器對官方ImageNet驗證集上的BigBiGAN模型與最近競爭方法的比較
基于10K訓練集圖像的trainval子集的最高精度,選擇BigBiGAN結果并提前停止。ResNet-50結果對應于表1中的行ResNet(“ELR”),RevNet-50×4對應于RevNet×4(“ELR”)

表3:無監督(無條件)生成的BigBiGAN與已有的無監督BigGAN的比較結果
作者將“偽標簽”方法指定為SL(單標簽)或聚類。為了進行比較,訓練BigBiGAN的步數(500K)與基于BigGAN的方法相同,但也可以在最后一行中對1M步驟進行額外訓練,并觀察其變化。上述所有結果均包括中值m以及三次運行的平均μ和標準偏差σ,表示為“m(μ±σ)”。BigBiGAN的結果由最佳FID與Train的停止決定的。
無監督圖像生成
圖2:從無監督的BigBiGAN模型中選擇的重建
上圖2中第一行表示真實數據x~Px;第二行表示由
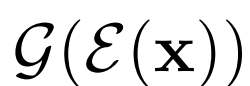
3.3 重建
BiGAN E和G通過計算編碼器預測的潛在表示E(x),然后將預測的潛在表示傳回生成器,得到重建的G(E(x)),從而重構數據實例x。我們在圖2中展示了BigBiGAN重構。這些重構遠非有像素級的完美度,部分原因可能是目標并沒有明確強制執行重構成本,甚至在訓練時也沒有計算重構。然而,它們可能為編碼器學習建模的特性提供一些直觀的認識。例如,當輸入圖像包含一條狗、一個人或一種食物時,重建通常是相同“類別”的不同實例,具有相似的姿勢、位置和紋理。這些重構傾向于保留輸入的高級語義,而不是低級細節,這表明BigBiGAN訓練鼓勵編碼器對前者建模,而不是后者。
4、相關研究
基于自我監督圖像中的無監督表示學習的許多方法被證明是非常成功的。自我監督通常涉及從以某種方式設計成類似于監督學習的任務中學習,但是其中“標簽”可以自動地從數據本身創建而無需人工操作。早期的例子是相對位置預測,其中模型在輸入的圖像塊對上進行訓練并預測它們的相對位置。
對比預測編碼(CPC)是最近的相關方法,其中,給定圖像補丁,模型預測哪些補丁出現在其他圖像位置中。其他方法包括著色、運動分割、旋轉預測和樣本匹配。
對這些方法進行了嚴格的實證比較。相對于大多數自我監督的方法,BigBiGAN和基于生成模型的其他方法的關鍵優勢是它們的輸入可能是全分辨率圖像或其他信號,不需要裁剪或修改所需的數據。這意味著結果表示通常可以直接應用于下游任務中的完整數據,而不會發生域移位(domain shift)。
還提出了許多相關的自動編碼器和GAN變體。關聯壓縮網絡(ACN)學會通過調節其他先前在代碼空間中相似的傳輸數據的數據來壓縮數據集級別,從而產生可以“模糊”語義相似樣本的模型,類似于BigBiGAN重建。VQ-VAE 將離散(矢量量化)編碼器與自回歸解碼器配對,以產生具有高壓縮因子的忠實重建,并在強化學習設置中展示表示學習結果。在對抗性空間中,對抗性自動編碼器提出了一種自動編碼器式編碼器 - 解碼器對,用像素級重建成本訓練,用鑒別器代替VAE中使用的先驗的KL-發散正則化。
在另一個提出的VAE-GAN混合中,在大多數VAE中使用的像素空間重建誤差被替換為距GAN鑒別器的中間層的特征空間距離。AGE和α-GAN等其他混合方法增加了編碼器來穩定GAN訓練。這些方法與BiGAN框架間的一個區別是,BiGAN不會以明確的重建成本訓練編碼器,雖然可以證明BiGAN隱含地使重建成本最小化,但定性重建結果表明這種重建成本具有不同的風格,強調了像素級細節上的高級語義。
5.探討
我們已經證明,BigBiGAN是一種純粹基于生成模型的無監督學習方法,它在ImageNet上實現了圖像表示學習的最好的結果。我們的消融實驗進一步證實強大的生成模型可以有利于表征學習,反過來,學習推理模型可以改善大規模的生成模型。在未來,我們希望表示學習可以繼續受益于生成模型和推理模型的進一步發展,同時擴展到更大的圖像數據庫。
-
GaN
+關注
關注
19文章
1936瀏覽量
73526 -
無監督學習
+關注
關注
1文章
16瀏覽量
2755
原文標題:BigBiGAN問世,“GAN父”都說酷的無監督表示學習模型有多優秀?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時空引導下的時間序列自監督學習框架

java子類可以繼承父類的什么
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
基于FPGA的類腦計算平臺 —PYNQ 集群的無監督圖像識別類腦計算系統
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
跟優秀的人,學習記筆記!文末有看海的點評






 工商網監
工商網監
評論