

【導(dǎo)讀】損失函數(shù)對神經(jīng)網(wǎng)絡(luò)的訓(xùn)練有顯著影響,也有很多學(xué)者人一直在探討并尋找可以和損失函數(shù)一樣使模型效果更好的函數(shù)。后來,Szegedy 等學(xué)者提出了標(biāo)簽平滑方法,該方法通過計算數(shù)據(jù)集中 hard target 的加權(quán)平均以及平均分布來計算交叉熵,有效提升了模型的準(zhǔn)確率。近日,Hinton 團(tuán)隊等人在新研究論文《When Does Label Smoothing Help?》中,就嘗試對標(biāo)簽平滑技術(shù)對神經(jīng)網(wǎng)絡(luò)的影響進(jìn)行分析,并對相關(guān)網(wǎng)絡(luò)的特性進(jìn)行了描述。
在開始今天的論文解讀之前,我們先快速了解研究中的主角和相關(guān)知識的概念:
什么是 soft target?計算方法是什么?
使用 soft target,多分類神經(jīng)網(wǎng)絡(luò)的泛化能力和學(xué)習(xí)速度往往能夠得到大幅度提高。文本中使用的soft target 是通過計算hard target 的加權(quán)平均和標(biāo)簽的均勻分布得到的,而這一步驟稱為標(biāo)簽平滑。
標(biāo)簽平滑技術(shù)有什么作用?
標(biāo)簽平滑技術(shù)能夠有效防止模型過擬合,且在很多最新的模型中都得到了應(yīng)用,比如圖片分類、機器翻譯和語音識別。
Hinton 的這個研究想說明什么問題?
本文通過實驗證明,標(biāo)簽平滑不僅能夠提升模型的泛化能力,還能夠提升模型的修正能力,并進(jìn)一步提高模型的集束搜索能力。但在本文的實驗中還發(fā)現(xiàn),如果在teacher model 中進(jìn)行標(biāo)簽平滑,對student model 的知識蒸餾效果會出現(xiàn)下降。
研究中如何解釋發(fā)現(xiàn)的現(xiàn)象?
為了對這一現(xiàn)象進(jìn)行解釋,本文對標(biāo)簽平滑對網(wǎng)絡(luò)倒數(shù)第二層表示的影響進(jìn)行了可視化,發(fā)現(xiàn)標(biāo)簽平滑使同一類訓(xùn)練實例表示傾向于聚合為緊密的分組。這導(dǎo)致了不同類的實例表示中相似性的信息丟失,但對模型的泛化能力和修正能力影響并不明顯。

1、介紹
損失函數(shù)對神經(jīng)網(wǎng)絡(luò)的訓(xùn)練有顯著影響。在 Rumelhart 等人提出使用平方損失函數(shù)進(jìn)行反向傳播的方法后,很多學(xué)者都提出,通過使用梯度下降方法最小化交叉熵,能獲得更好的分類效果。但是學(xué)者對損失函數(shù)對討論從未停止,人們認(rèn)為仍有其他的函數(shù)能夠代替交叉熵以取得更好的效果。隨后,Szegedy等學(xué)者提出了標(biāo)簽平滑方法,該方法通過計算數(shù)據(jù)集中hard target 的加權(quán)平均以及平均分布來計算交叉熵,有效提升了模型的準(zhǔn)確率。
標(biāo)簽平滑技術(shù)在圖片分類、語音識別、機器翻譯等多個領(lǐng)域的深度學(xué)習(xí)模型中都取得了很好的效果,如表1所示。在圖片分類中,標(biāo)簽平滑最初被用于提升 ImageNet 數(shù)據(jù)集上Inception-v2 的效果,并在許多最新的研究中得到了應(yīng)用。在語音識別中,一些學(xué)者通過標(biāo)簽平滑技術(shù)降低了 WDJ 數(shù)據(jù)集上的單詞錯誤率。在機器翻譯中,標(biāo)簽平滑幫助小幅度提升了 BLEU 分?jǐn)?shù)。

表1 標(biāo)簽平滑技術(shù)在三種監(jiān)督學(xué)習(xí)任務(wù)中的應(yīng)用
盡管標(biāo)簽平滑技術(shù)已經(jīng)得到了有效應(yīng)用,但現(xiàn)有研究對其原理及應(yīng)用場景的適用性討論較少。
Hinton 等人的這篇論文就嘗試對標(biāo)簽平滑技術(shù)對神經(jīng)網(wǎng)絡(luò)的影響進(jìn)行分析,并對相關(guān)網(wǎng)絡(luò)的特性進(jìn)行了描述。本文貢獻(xiàn)如下:
基于對網(wǎng)絡(luò)倒數(shù)第二層激活情況的線性映射提出了一個全新的可視化方法;
闡釋了標(biāo)簽平滑對模型修正的影響,并指出網(wǎng)絡(luò)預(yù)測結(jié)果的可信度更多取決于模型的準(zhǔn)確率;
展示了標(biāo)簽平滑對蒸餾的影響,并指出該影響會導(dǎo)致部分信息丟失。
1.1 預(yù)備知識
這一部分提供了標(biāo)簽平滑的數(shù)學(xué)描述。假設(shè)將神經(jīng)網(wǎng)絡(luò)的預(yù)測結(jié)果表示為倒數(shù)第二層的激活函數(shù),公式如下:
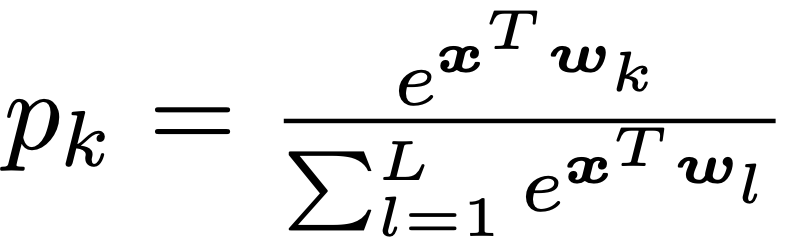
其中 pk 表示模型分類結(jié)果為第 k 類的可能性,wk 表示網(wǎng)絡(luò)最末層的權(quán)重和偏置,x 是包括網(wǎng)絡(luò)倒數(shù)第二層激活函數(shù)的向量。在使用hard target 對網(wǎng)絡(luò)進(jìn)行訓(xùn)練時,我們使用真實的標(biāo)簽 yk 和網(wǎng)絡(luò)的輸出 pk 最小化交叉熵,公式如下:
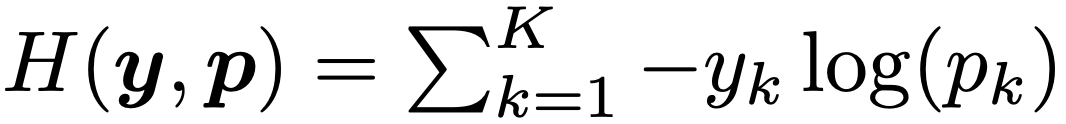
其中當(dāng)分類為正確時, yk 值為1,否則為0。對于使用參數(shù) a 進(jìn)行標(biāo)簽平滑后的網(wǎng)絡(luò),則在訓(xùn)練時使用調(diào)整后的標(biāo)簽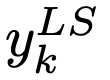 和網(wǎng)絡(luò)的輸出 pk 計算并最小化交叉熵,其中,
和網(wǎng)絡(luò)的輸出 pk 計算并最小化交叉熵,其中,
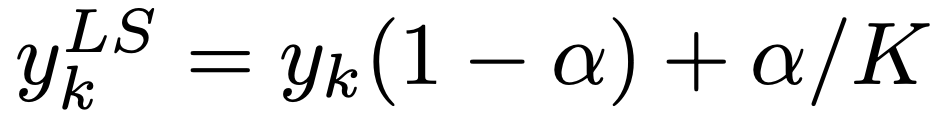
2、倒數(shù)第二層的表示
對于使用參數(shù) a 對網(wǎng)絡(luò)進(jìn)行標(biāo)簽平滑后的神經(jīng)網(wǎng)絡(luò),其正確和錯誤分類的 logit 值之間的差會增大,改變程度與 a 的值相關(guān)。在使用硬標(biāo)簽對網(wǎng)絡(luò)進(jìn)行訓(xùn)練時,正確分類的 logit 值會遠(yuǎn)大于錯誤分類,且不同錯誤分類的值之間差異也較大。一般而言,第 k 個類別的 logit 值可以看作網(wǎng)絡(luò)倒數(shù)第二層的激活函數(shù) x 和標(biāo)準(zhǔn) wk 之間的歐式距離的平方,表示如下:
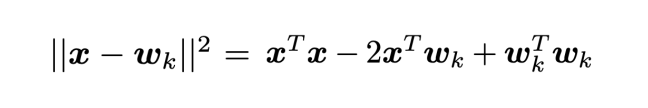
因此,標(biāo)簽平滑會使倒數(shù)第二層的激活函數(shù)與正確分類間的差值減小,并使其與正確和錯誤分類的距離等同。為了對標(biāo)簽平滑的這一屬性進(jìn)行觀察,本文依照以下步驟提出了一個新的可視化方式:(1)選擇三個類別;(2)找到這三個分類的一個標(biāo)準(zhǔn)正交平面,(3)把實例在倒數(shù)第二層的激活函數(shù)投射在該平面上。
圖 1 展示了本文在 CIFAR-10, CIFAR-100 和 ImageNet 三個數(shù)據(jù)集上進(jìn)行圖片分類任務(wù)時,網(wǎng)絡(luò)倒數(shù)第二層的激活函數(shù)的情況,訓(xùn)練使用的網(wǎng)絡(luò)架構(gòu)包括 AlexNet, ResNet-56 和 Inception-v4 。其中,前兩列的模型未進(jìn)行標(biāo)簽平滑處理,后兩列使用了標(biāo)簽平滑技術(shù)。表2展示了標(biāo)簽平滑對模型準(zhǔn)確率的影響。
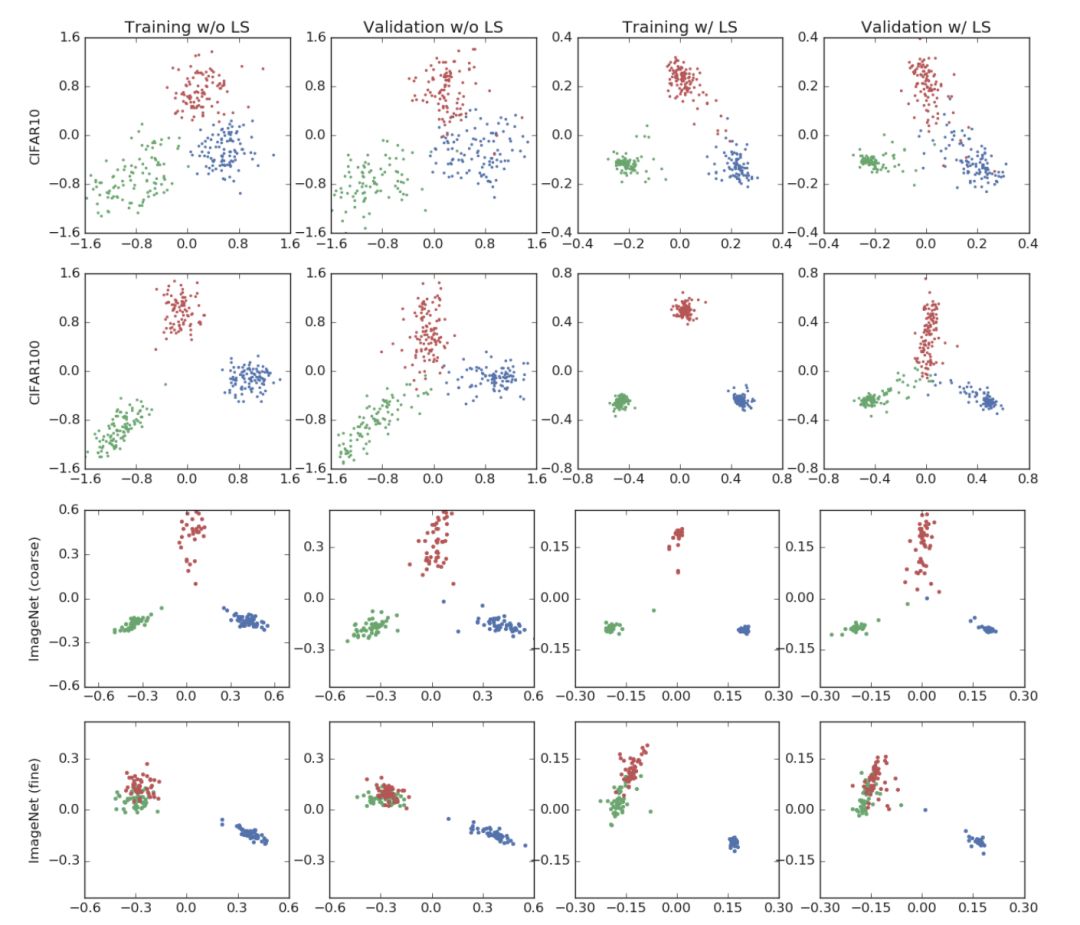
圖 1 圖片分類任務(wù)可視化情況

表2 使用和未使用標(biāo)簽平滑技術(shù)的模型的最高準(zhǔn)確率
第一行可視化使用的數(shù)據(jù)集為 CIFAR-10 ,標(biāo)簽平滑的參數(shù)值為 0.1 ,三個圖片分類分別為“airplane”,“automobil”和“bird”。這些模型的準(zhǔn)確率基本相同。可以發(fā)現(xiàn),在使用標(biāo)簽平滑的網(wǎng)絡(luò)中,聚類更加緊湊。
第二行可視化使用的數(shù)據(jù)集為 CIFAR-100,模型為 ResNet-56 ,選擇的圖片分類為“beaver”,“dolphin”,“otter”。在這次實驗中,使用標(biāo)簽平滑技術(shù)的網(wǎng)絡(luò)獲得了更高的準(zhǔn)確率。
最后,本文使用 Inception-v4 在 ImageNet 數(shù)據(jù)集上進(jìn)行了實驗,并使用具有和不具有語義相似性的分類分別進(jìn)行了實驗。其中,第三行使用的分類不具有語義相似性,分別為“tench”,“meerkat”和“cleaver”。第四行使用了的兩個具有語義相似性的分類“toy poodle”和‘miniature poodle“以及另一個不同的分類“tench, in blue”。對于語義相似的類別而言,即使是在訓(xùn)練集上都很難進(jìn)行區(qū)分,但標(biāo)簽平滑較好地解決了這一問題。
從上述實驗結(jié)果可以發(fā)現(xiàn),標(biāo)簽平滑技術(shù)對模型表示的影響與網(wǎng)絡(luò)結(jié)構(gòu)、數(shù)據(jù)集和準(zhǔn)確率無關(guān)。
3、隱式模型修正
標(biāo)簽平滑能夠有效防止模型過擬合。在本部分,論文嘗試探討該技術(shù)是否能通過提升模型預(yù)測的準(zhǔn)確性改善模型修正能力。為衡量模型的修正能力,本文計算了預(yù)期修正誤差(expected calibration error, ECE)。本文發(fā)現(xiàn),標(biāo)簽平滑技術(shù)能夠有效降低 ECE ,并可用于模型修正過程。
圖片分類
圖2左側(cè)展示了 ResNet-56 在 CIFAR-100 數(shù)據(jù)集上訓(xùn)練后得到的一個可靠性圖表,其中虛線表示理想的模型修正情況。可以發(fā)現(xiàn),使用硬標(biāo)簽的模型出現(xiàn)了過擬合的情況。如果需要對模型進(jìn)行調(diào)整,可以將 softmax 的 temperature 調(diào)至1.9,或者使用標(biāo)簽平滑技術(shù)進(jìn)行調(diào)整。如圖中綠線所示,當(dāng)使用 a = 0.05 進(jìn)行標(biāo)簽平滑處理時,能夠得到相似的模型修正效果。這兩種方法都能夠有效降低 ECE 值。
本文在 ImageNet 上也進(jìn)行了實驗,如圖2右側(cè)所示。使用硬標(biāo)簽的模型仍然出現(xiàn)過擬合情況 ,ECE 高達(dá)0.071。通過使用溫度縮放技術(shù)(T = 1.4),可將 ECE 降低至0.022, 如藍(lán)線所示。當(dāng)使用 a = 0.1 的標(biāo)簽平滑時,能夠?qū)?ECE 降低至0.035。
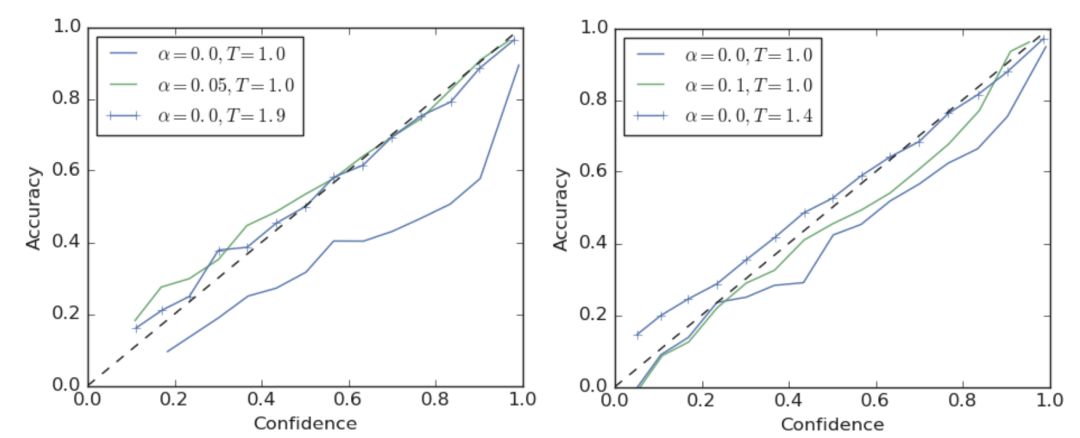
圖2 可信度圖表
機器翻譯
本部分對使用 Transformer 架構(gòu)的網(wǎng)絡(luò)的調(diào)整進(jìn)行了實驗,使用的評測任務(wù)為英譯徳。與圖片分類任務(wù)不同,在機器翻譯中,網(wǎng)絡(luò)的輸出會作為集束搜索算法的輸入,這意味著模型的調(diào)整將對準(zhǔn)確率產(chǎn)生影響。
本文首先比較了使用硬標(biāo)簽的模型和經(jīng)過標(biāo)簽平滑(a = 0.1)的模型的可信度,如圖3所示。可以發(fā)現(xiàn),使用標(biāo)簽平滑的網(wǎng)絡(luò)的調(diào)整情況優(yōu)于使用硬標(biāo)簽的網(wǎng)絡(luò)。
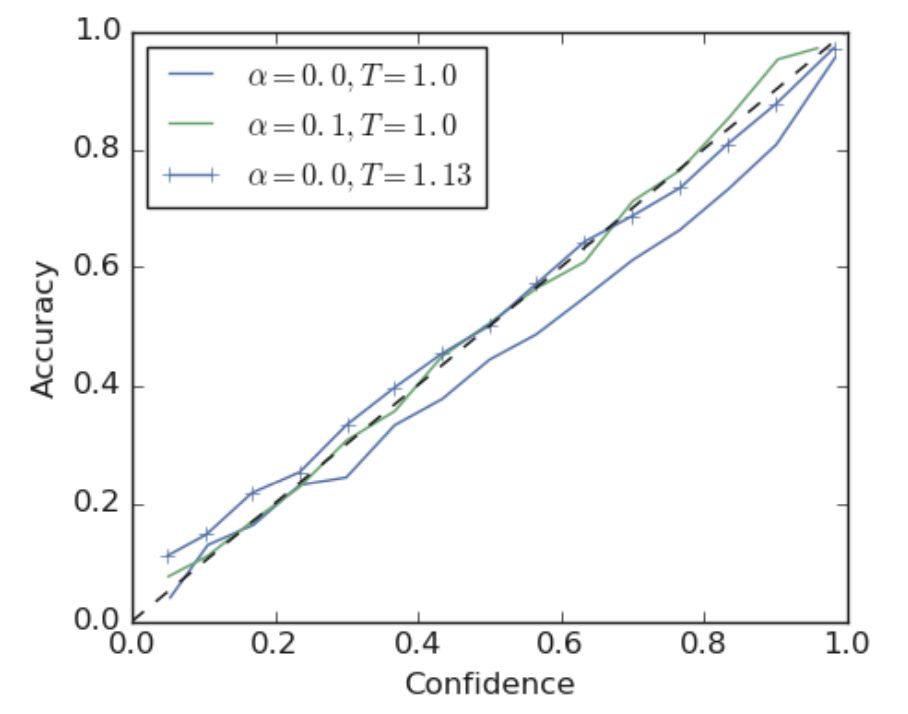
圖3 基于英譯徳任務(wù)訓(xùn)練的Transformer 架構(gòu)的可信度圖表
盡管標(biāo)簽平滑能夠獲得更佳的模型調(diào)優(yōu)和更高的 BLEU 值,其也會導(dǎo)致負(fù)對數(shù)似然函數(shù)(negative log-likelihoods, NLL)的值變差。圖4展示了標(biāo)簽平滑技術(shù)對 BLEU 和 NLL 的影響,藍(lán)線代表 BLEU 值,紅線代表 NLL 值。其中,最左側(cè)的圖為使用硬標(biāo)簽訓(xùn)練的模型的情況,中間的圖為使用標(biāo)簽平滑技術(shù)訓(xùn)練的模型的情況,右側(cè)的圖則展示了兩種模型的 NLL 值變化情況。可以發(fā)現(xiàn),標(biāo)簽平滑在提高 BLEU 分?jǐn)?shù)的同時,也導(dǎo)致了 NLL 的降低。
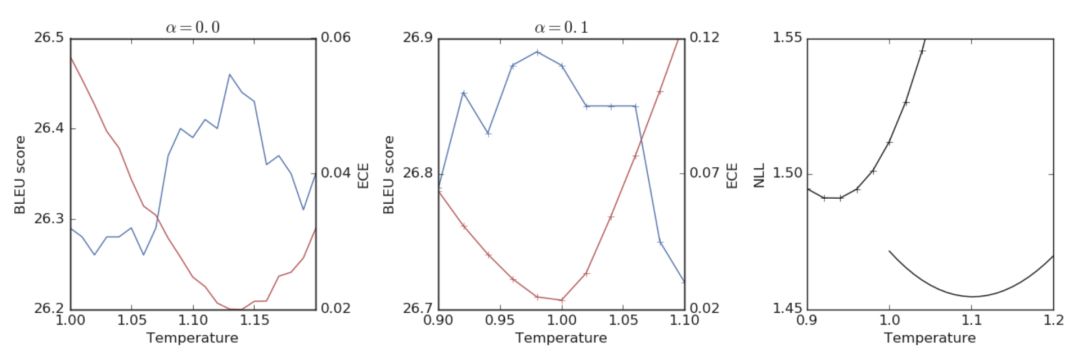
圖4 Transformer 網(wǎng)絡(luò)調(diào)優(yōu)對 BLEU 和 NLL 的影響
4、知識蒸餾
本部分研究了在teacher model 對student model 的知識蒸餾中標(biāo)簽平滑的影響。本文發(fā)現(xiàn),盡管標(biāo)簽平滑能夠提升teacher model 的準(zhǔn)確性,但使用標(biāo)簽平滑技術(shù)的teacher model 所產(chǎn)生的student model 相比于未使用標(biāo)簽平滑技術(shù)的網(wǎng)絡(luò)效果較差。
本文在 CIFAR-10 數(shù)據(jù)集上進(jìn)行了實驗。作者訓(xùn)練了一個 ResNet-56 的teacher model ,并對于一個使用 AlexNet 結(jié)構(gòu)的student model 進(jìn)行了知識蒸餾。作者重點關(guān)注了4項內(nèi)容:
teacher model的準(zhǔn)確度
student model的基線準(zhǔn)確度
經(jīng)過知識蒸餾后student model的準(zhǔn)確度,其中teacher model使用硬標(biāo)簽訓(xùn)練,且用于蒸餾的標(biāo)簽經(jīng)過溫度縮放進(jìn)行調(diào)整
使用固定溫度進(jìn)行蒸餾后的student model的準(zhǔn)確度,其中 T = 1.0 ,teacher model訓(xùn)練使用了標(biāo)簽平滑技術(shù)
圖5展示了這一部分實驗的結(jié)果。作者首先比較了未進(jìn)行蒸餾的teacher model 和student model 的效果,在實驗中,提高 a 的值能夠提升teacher model 的準(zhǔn)確度,但會輕微降低student model 的效果。
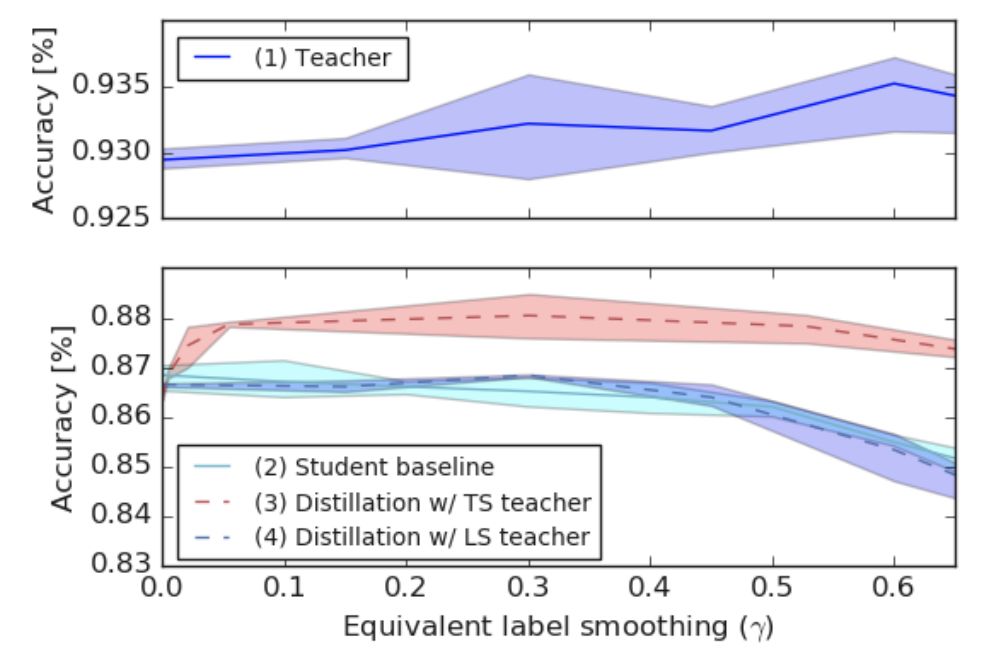
圖5 基于 CIFAR-10 數(shù)據(jù)集從 ResNet-56 向 AlexNet 進(jìn)行蒸餾的效果
之后,作者使用硬標(biāo)簽訓(xùn)練了teacher model 并基于不同溫度進(jìn)行蒸餾,且分別計算了不同溫度下的 y 值,用紅色虛線表示。實驗發(fā)現(xiàn),所有未使用標(biāo)簽平滑技術(shù)的模型效果都優(yōu)于使用標(biāo)簽平滑技術(shù)的模型效果。最后,作者將使用標(biāo)簽平滑技術(shù)訓(xùn)練的具有更高準(zhǔn)確度的teacher model 的知識蒸餾入student model ,并用藍(lán)色虛線進(jìn)行了表示。可以發(fā)現(xiàn),模型效果并未得到顯著提升,甚至有所降低。
5、結(jié)論和未來展望
盡管很多最新技術(shù)都使用了標(biāo)簽平滑方法,該方法的原理和使用情形并未得到充分討論。本文總結(jié)了解釋了在多個情形下標(biāo)簽平滑的應(yīng)用和表現(xiàn),包括標(biāo)簽平滑如何使得網(wǎng)絡(luò)倒數(shù)第二層激活函數(shù)的表示的聚類更加緊密等。為對此問題進(jìn)行探究,本文提出了一個全新的低緯度可視化方法。
標(biāo)簽平滑技術(shù)在提升模型效果的同時,也可能對知識蒸餾帶來負(fù)面的影響。本文認(rèn)為造成該影響對原因是,標(biāo)簽平滑導(dǎo)致了部分信息的丟失。這一現(xiàn)象可以通過計算模型輸入和輸出的互信息來進(jìn)行觀察。基于此,本文提出了一個新的研究方向,即標(biāo)簽平滑和信息瓶頸之間的關(guān)系。
最后,本文針對標(biāo)簽平滑對模型修正的作用進(jìn)行了實驗,提升了模型的可解釋性。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4789瀏覽量
101848 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1217瀏覽量
25098 -
標(biāo)簽
+關(guān)注
關(guān)注
0文章
142瀏覽量
18065
原文標(biāo)題:Hinton等人最新研究:大幅提升模型準(zhǔn)確率,標(biāo)簽平滑技術(shù)到底怎么用?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
用于光譜色散平滑技術(shù)的雙通調(diào)制器實驗研究
小編告訴你:嫁給電子男的N多好處!
資深物聯(lián)網(wǎng)產(chǎn)品經(jīng)理告訴你:如何不花冤枉錢,善用無線接入?
WEBENCH告訴你怎么設(shè)計電源
無源標(biāo)簽系統(tǒng)研究
STM32 3993讀取標(biāo)簽無法操作是什么原因造成的?
GB29768的標(biāo)簽在庫存時,提示無法讀取標(biāo)簽怎么解決?
通用多協(xié)議標(biāo)簽交換技術(shù)研究

RFID標(biāo)簽天線制造技術(shù)研究

電子標(biāo)簽的應(yīng)用場景_電子標(biāo)簽怎么用
邊緣計算生活新常態(tài)是怎樣的用五大場景告訴你
交互設(shè)計到底是什么?這篇文章告訴你!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論