 Linux調度器中的PELT(Per-Entity Load Tracking)
Linux調度器中的PELT(Per-Entity Load Tracking)
一、為何需要per-entity load tracking?
對于Linux內核而言,做一款好的進程調度器是一項非常具有挑戰性的任務,主要原因是在進行CPU資源分配的時候必須滿足如下的需求:
1、它必須是公平的
2、快速響應
3、系統的throughput要高
4、功耗要小
其實你仔細分析上面的需求,這些目標其實是相互沖突的,但是用戶在提需求的時候就是這么任性,他們期望所有的需求都滿足,而且不管系統中的負荷情況如何。因此,縱觀Linux內核調度器這些年的發展,各種調度器算法在內核中來來去去,這也就不足為奇了。當然,2007年,2.6.23版本引入“完全公平調度器”(CFS)之后,調度器相對變得穩定一些。最近一個最重大的變化是在3.8版中合并的Per-entity load tracking。
完美的調度算法需要一個能夠預知未來的水晶球:只有當內核準確地推測出每個進程對系統的需求,她才能最佳地完成調度任務。不幸的是,硬件制造商推出各種性能強勁的處理器,但從來也不考慮預測進程負載的需求。
在沒有硬件支持的情況下,調度器只能祭出通用的預測大法:用“過去”預測“未來”,也就是說調度器是基于過去的調度信息來預測未來該進程對CPU的需求。而在這些調度信息中,每一個進程過去的“性能”信息是核心要考慮的因素。但有趣的是,雖然內核密切跟蹤每個進程實際運行的時間,但它并不清楚每個進程對系統負載的貢獻程度。
有人可能會問:“消耗的CPU時間”和“負載(load)”是否有區別?是的,當然有區別,Paul Turner在提交per-entity load tracking補丁集的時候對這個問題做了回答。一個進程即便當前沒有在cpu上運行,例如:該進程僅僅是掛入runqueue等待執行,它也能夠對cpu負載作出貢獻。
“負載”是一個瞬時量,表示當前時間點的進程對系統產生的“壓力”是怎樣的?顯然runqueue中有10個等待運行的進程對系統造成的“壓力”要大于一個runqueue中只有1個等待進程的場景。與之相對的“CPU使用率(usage)”不一樣,它不是瞬時量,而是一個累積量。有一個長時間運行的進程,它可能上周占用大量的處理器時間,但是現在可能占用很少的cpu時間,盡管它過去曾經“輝煌”過(占用大量CPU時間),但這對現在的系統負荷貢獻很小。
3.8版本之前的內核CFS調度器在計算CPU load的時候采用的是跟蹤每個運行隊列上的負載(per-rq load tracking)。需要注意的是:CFS中的“運行隊列”實際上是有多個,至少每個CPU就有一個runqueue。而且,當使用“按組調度”(group scheduling)功能時,每個控制組(control group)都有自己的per-CPU運行隊列。
對于per-rq的負載跟蹤方法,調度器可以了解到每個運行隊列對整個系統負載的貢獻。這樣的統計信息足以幫助組調度器(group scheduler)在控制組之間分配CPU時間,但從整個系統的角度看,我們并不知道當前負載來自何處。除此之外,per-rq的負載跟蹤方法還有另外一個問題,即使在工作負載相對穩定的情況下,跟蹤到的運行隊列的負載值也會變化很大。
二、如何進行per-entity load tracking?
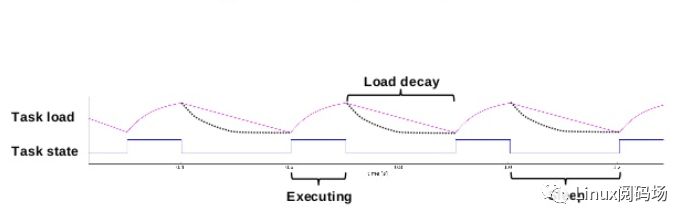
Per-entity load tracking系統解決了這些問題,這是通過把負載跟蹤從per rq推進到per-entity的層次。所謂調度實體(scheduling entity)其實就是一個進程或者control group中的一組進程。為了做到Per-entity的負載跟蹤,時間(物理時間,不是虛擬時間)被分成了1024us的序列,在每一個1024us的周期中,一個entity對系統負載的貢獻可以根據該實體處于runnable狀態(正在CPU上運行或者等待cpu調度運行)的時間進行計算。如果在該周期內,runnable的時間是x,那么對系統負載的貢獻就是(x/1024)。
當然,一個實體在一個計算周期內的負載可能會超過1024us,這是因為我們會累積在過去周期中的負載,當然,對于過去的負載我們在計算的時候需要乘一個衰減因子。如果我們讓Li表示在周期pi中該調度實體的對系統負載貢獻,那么一個調度實體對系統負荷的總貢獻可以表示為:
L = L0+ L1*y + L2*y2+ L3*y3+ ...
其中y是衰減因子。通過上面的公式可以看出:
(1)調度實體對系統負荷的貢獻值是一個序列之和組成
(2)最近的負荷值擁有最大的權重
(3)過去的負荷也會被累計,但是是以遞減的方式來影響負載計算。
使用這樣序列的好處是計算簡單,我們不需要使用數組來記錄過去的負荷貢獻,只要把上次的總負荷的貢獻值乘以y再加上新的L0負荷值就OK了。
在3.8版本的代碼中,y已經確定:y^32等于0.5。這樣選定的y值,一個調度實體的負荷貢獻經過32個周期(1024us)后,對當前時間的的符合貢獻值會衰減一半。
一旦我們有了計算runnable調度實體負荷貢獻值的方法,那么這個負荷值可以向上傳遞,通過累加control group中的每一個調度實體負荷值可以得到該control group對應的調度實體的負荷值。這樣的算法不斷的向上推進,可以得到整個系統的負荷。
當然,計算負荷不是那么簡單。因為調度器本身就會定期的觀察記錄調度實體的信息,計算runnable調度實體的負荷貢獻是容易的。但沒有處于runnable狀態的調度實體就對系統負荷沒有貢獻了嗎?當“密碼破解”進程由于page fault而阻塞,它其實仍然會給 “系統列車”增加“負荷”。因此我們需要有一種計算進入阻塞狀態的進程對系統負載貢獻的方法,當前不是調度器需要關注的。
當然,內核可以選擇記錄所有進入阻塞狀態的進程,像往常一樣衰減它們的負載貢獻,并將其增加到總負載中。但這么做是非常耗費資源的。所以,相反,3.8版本的調度器在每個cfs_rq(每個control group都有自己的cfs rq)數據結構中,維護一個“blocked load”的成員,這個成員記錄了所有阻塞狀態進程對系統負荷的貢獻。
當一個進程阻塞了,它的負載會從總的運行負載值(runnable load)中減去并添加到總的阻塞負載值(blocked load)中。該負載可以以相同的方式衰減(即每個周期乘以y)。當阻塞的進程再次轉換成運行態時,其負載值(適當進行衰減)則轉移到運行負荷上來。因此,跟蹤blocked load只是需要在進程狀態轉換過程中有一點計算量,調度器并不需要由于跟蹤阻塞負載而遍歷一個進入阻塞狀態進程的鏈表。
另外一個比較繁瑣的地方是對節流進程(throttled processes)負載的計算。所謂節流進程是指那些在“CFS帶寬控制器”(CFS bandwidth controller)下控制運行的進程。當這些進程用完了本周期內的CPU時間,即使它們仍然在運行狀態,即使CPU空閑,調度器并不會把CPU資源分配給它們。
因此節流進程不會對系統造成負荷。正因為如此,當進程處于被節流狀態的時候,它們對系統負荷的貢獻值不應該按照runnable進程計算。在等待下一個周期到來之前,throttled processes不能獲取cpu資源,因此它們的負荷貢獻值會衰減。
三、per-entity load tracking有什么好處?
有了Per-entity負載跟蹤機制,在沒有增加調度器開銷的情況下,調度器現在對每個進程和“調度進程組”對系統負載的貢獻有了更清晰的認識。有了更精細的統計數據(指per entity負載值)通常是好的,但人們可能會懷疑這些信息是否真的對調度器有用。
我們可以通過跟蹤的per entity負載值做一些有用的事情。最明顯的使用場景可能是用于負載均衡:即把runnable進程平均分配到系統的CPU上,使每個CPU承載大致相同的負載。如果內核知道每個進程對系統負載有多大貢獻,它可以很容易地計算遷移到另一個CPU的效果。這樣進程遷移的結果應該更準確,從而使得負載平衡不易出錯。目前已經有一些補丁利用per entity負載跟蹤來改進調度器的負載均衡,相信這些補丁會在不久的將來進入到內核主線。
small-task packing patch的目標是將“小”進程收集到系統中的部分CPU上,從而允許系統中的其他處理器進入低功耗模式。在這種情況下,顯然我們需要一種方法來計算得出哪些進程是“小”的進程。利用per-entity load tracking,內核可以輕松的進行識別。
內核中的其他子系統也可以使用per entity負載值做一些“文章”。CPU頻率調節器(CPU frequency governor)和功率調節器(CPU power governor)可以利用per entity負載值來猜測在不久的將來,系統需要提供多少的CPU計算能力。
既然有了per-entity load tracking這樣的基礎設施,我們期待看到開發人員可以使用per-entity負載信息來優化系統的行為。雖然per-entity load tracking仍然不是一個能夠預測未來的水晶球,但至少我們對當前的系統中的進程對CPU資源的需求有了更好的理解。
-
cpu
+關注
關注
68文章
10879瀏覽量
212199 -
Linux
+關注
關注
87文章
11320瀏覽量
209849
原文標題:郭健: Linux調度器中的PELT(Per-Entity Load Tracking)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux的Deadline實時調度算法


Linux2.4與Linux2.6內核調度器的比較研究
Linux系統調度是實現特性的關鍵部分
Linux2.4和Linux2.6的調度器對比分析,Linux2.6對調度器的改進有哪些方面?
嵌入式工程師必會的 Linux 進程調度所有知識點
uClinux進程調度器的實現分析
Linux內核的DL調度器的細節和怎么樣使用DL調度器?

英創信息技術Linux系統調度簡介





 工商網監
工商網監
評論