 幾個在工業領域數據驅動價值創造的案例
幾個在工業領域數據驅動價值創造的案例
工業大數據是互聯網、大數據和工業產業結合的產物,是中國制造2025、工業互聯網、工業4.0等國家戰略在企業的落腳點。
對于企業而言,了解工業大數據產生的背景,歸納工業企業大數據的分類和特點,從數據流推動工業價值創造的視角看待、重造工業價值流程,將具有很強的現實意義。文章最后,筆者分享幾個在工業領域數據驅動價值創造的案例,希望起到拋磚引玉的作用。
01
工業大數據產生的背景
在工業生產中,無時不刻都在產生數據。生產機床的轉速、能耗,食品加工的溫濕度,火力發電機組的燃燒和燃煤消耗,汽車的裝備數據,物流車隊的位置和速度等,都是在生產過程中的數據。
自從工業從社會生產中獨立成為一個門類以來,工業生產的數據采集、使用范圍就逐步加大。從泰勒拿著秒表計算工人的用鐵鍬送煤到鍋爐的時間開始,是對制造管理數據的采集和使用;福特汽車的流水化生產,是對汽車生產過程的工業數據的采集和工廠內使用;豐田的精益生產模式,將數據的采集和使用擴大到工廠和上下游供應鏈;核電站發電過程中全程自動化將生產過程數據的自動化水平提高到更高程度。
任何數據的采集和使用都是有成本的,工業數據也不例外。但隨著信息、電子和數學技術的發展,傳感器、物聯網等技術的發展,一批智能化、高精度、長續航、高性價比、微型傳感器面世,以物聯網為代表的新一代網絡技術在移動數據通信的支持下,能做到任何時間、任何地點采集、傳送數據。以云計算為代表的新型數據處理基礎架構,大幅降低工業數據處理的技術門檻和成本支出。以工業領域的SCADA系統為例,傳統模式下每個電網、化工企業都需要建立一套SCADA系統,成本在千萬以上,如果采用云架構模式,成本將可以降低7成以上。
社會需求變革是最大拉動力。在商品過剩經濟時代,以個性化為代表的消費文化,使得工業企業的產出物,要最大限度匹配個性需求。從服裝定制,車輛選配,到T恤的印花和個性化教育。
要響應個性化需求,有兩種方式,以服裝定制為例,就是靠老師傅用尺子量,眼見手摸,憑借經驗,確定服裝的裁剪和版型,這種我們可以稱之為模擬方式,效率和質量難以保證,耗時長,個性化定制的成本高;還有一種是數字方式,就是通過制訂一套數據采集手段,由前臺的客戶代表測量采集用戶身形數據,然后將數據傳回總部,將結合生產原材料數據,將需求分解為一項一項的生產工藝動作,最后也生產出達到定制化要求服裝。
當然了,工廠也會聘請資深的老師傅,他們的主要工作不是面對一個個客戶的定制化需求,而是去研究更好的生產工藝,對數據和工藝分解進行把控。這種模式下,效率和質量得到保證,效率隨著生產線的擴容線性提升,有一批專家隊伍不斷研究提升工藝能力,定制化生產的成本將得以顯著攤薄。從發展趨勢看,后者這種數字模式的個性化生產將是未來選擇。
國策方針是重要影響力。完成了工業自動化過程的德國工業界,在自動化基礎上,以工業數據為基礎,引入云計算和人工智能技術,提升工業的智能化水平,以滿足大批量個性化定制的社會生產需求;美國擁有強大的云計算、互聯網及數據處理能力,基于此,提出工業互聯網戰略,將單個設備、單條生產線、單個工廠的數據聯網,通過大數據處理后,在診斷、預測、后服務等方面挖掘工業服務的價值。
中國相對于德國、美國而言,在工業自動化、在云計算等領域都處于發展期,因此提出中國制造2025計劃,通過工業化和信息化融合發展的方式,將工業化和信息化整體規劃,并制定一系列的重點工程和推進計劃。
02
工業大數據的特點和分類
不管是工業自動化、還是工業智能化(工業4.0)、或者是工業互聯網概念,他們的基礎是工業數據。
隨著行業發展,工業企業收集的數據維度不斷擴大。主要體現在三個方面:
一是時間維度不斷延長。經過多年的生產經營,積累下來歷年的產品數據、工業數據、原材料數據和生產設備數據;
二是數據范圍不斷擴大。隨著企業信息化建設的過程,一方面積累了企業的財務、供應商數據,也通過CRM系統積累了客戶數據,通過CAD等積累了研發過程數據,通過攝像頭積累了生產安全數據等,另一方面越來越多的外部數據也被收集回來,包括市場數據、社交網絡數據、企業輿情數據等;
三是數據粒度不斷細化。從一款產品到多款、多系列產品使得產品數據不斷細化,從單機機床到聯網機床,使得數據交互頻率大大增強;加工精度從1mm提升到0.2mm,從5分鐘每次的統計到每5秒的全程監測,都使得采集到的數據精細度不斷提升。
以上三個維度最終導致企業所積累的數據量以加速度的方式在增加,構成了工業大數據的集合。不管企業是否承認,這些數據都堆砌在工廠的各個角落,而且在不斷增加。
再從企業經營的視角來看待這些工業數據。可以按照數據的用途分成三類:
第一類是經營性數據,比如財務、資產、人事、供應商基礎信息等數據,這些數據在企業信息化建設過程中陸陸續續積累起來,表現了一個工業企業的經營要素和成果。
第二類是生產性數據,這部分是圍繞企業生產過程中積累的數據,包括原材料、研發、生產工藝、半成品、成品、售后服務等。隨著數字機床、自動化生產線、SCADA系統的建設,這些數據也被企業大量記錄下來。這些數據是工業生產過程中價值增值的體現,是決定企業差異性的核心所在。
第三類是環境類數據,包括布置在機床的設備診斷系統,庫房、車間的溫濕度數據,以及能耗數據,廢水廢氣的排放等數據。這些數據對工業生產過程中起到約束作用。
從目前的數據采用情況看,經營類數據利用率最高,生產性數據和環境類數據相比差距比較大。從未來數據量來說,生產線數據在工業企業數據中的占比將越來越大,環境類數據也將越來越多樣化。
一般意義上,大數據有具有數據量大、數據種類多、商業價值高、處理速度高,在此基礎上,工業大數據還有兩大特點。
一是準確率高,大數據一般的應用場景是預測,在一般性商業領域,如果預測準確率達到90%已經是很高了,如果是99%就是卓越了。但在工業領域的很多應用場景中,對準確率的要求達到99.9%甚至更高,比如軌道交通自動控制,再比如定制生產,如果把甲乙客戶的訂單參數搞混了,就會造成經濟損失。
二是實時性強,工業大數據重要的應用場景是實時監測、實時預警、實時控制。一旦數據的采集、傳輸和應用等全處理流程耗時過長,就難以在生產過程中發揮價值。
03
工業大數據應用案例
企業所積累的數據量以越來越快的速度在增加,很多企業也就順勢將大數據技術引入企業的生產經營中。大數據在工業企業的應用主要體現在三方面:
一是基于數據的產品價值挖掘。通過對產品及相關數據進行二次挖掘,創造新價值。
日本的科研人員日前設計出一種新型座椅,能夠通過分析相關數據識別主人,以此確保汽車的安全。這種座椅裝有360個不同類型的感應器,可以收集并分析駕駛者的體重、壓力值,甚至坐到座椅上的方式等多種信息,并將它們與車載系統中內置的車主信息進行匹配,以此判斷駕駛者是否為車主,從而決定是否開動汽車。實驗數據顯示,這種車座的識別準確率高達98%。
三一公司的挖掘機指數也是如此。通過在線跟蹤銷售出去的挖掘機的開工、負荷情況,就能了解全國各地基建情況,進而對于宏觀經濟判斷、市場銷售布局、金融服務提供調整依據。
二是提升服務型生產。提升服務型生產就是增加服務在生產(產品)的價值比重。主要體現在兩個方向。一是前向延伸,就是在售前階段,通過用戶參與、個性化設計的方式,吸引、引導和鎖定用戶。比如紅領西服的服裝定制,通過精準的量體裁衣,在其他成衣服裝規模關店的市場下,能保持每年150%的收入和利潤增長,每件衣服的成本僅比成衣高10%。當然了,小米手機也屬于這一類。二是后向延伸,通過銷售的產品建立客戶和廠家的互動,產生持續性價值。蘋果手機的硬件配置是標準的,但每個蘋果手機用戶安裝的軟件是個性化的,這里面最大的功勞是APPStore。蘋果通過銷售蘋果終端產品只是開始,通過APPStore建立用戶和廠商的連接,滿足用戶個性化需求,提供差異性服務,年創造收入在百億美金。
三是創新商業模式。商業模式創新主要體現在兩個方面,一是基于工業大數據,工業企業對外能提供什么樣的創新性商業服務;二是在工業大數據背景下,能接受什么樣的新型的商業服務。最優的情況是,通過提供創新性商業模式能獲得更多的客戶,發掘更多的藍海市場,贏取更多的利潤;同時通過接受創新性的工業服務,降低了生產成本、經營風險。
比如,GE不銷售發動機,而是將發動機租賃給航空公司使用,按照運行時間收取費用,這樣GE通過引入大數據技術監測發動機運行狀態,通過科學診斷和維護提升發動機使用壽命,獲得的經濟回報高于發動機銷售。
在接受服務方面,目前國內外有一批企業提供云服務架構的工業大數據平臺。包括海爾收購GE的白電業務的一攬子合作中,就包括GE的Predix工業大數據平臺向海爾開放,接入海爾的工廠,提供工業大數據服務。九次方大數據也在聯合各省市建立云化的工業大數據平臺,向當地的工業企業開放大數據采集、大數據存儲、大數據挖掘和應用能力。
04
工業大數據實踐指導
工業大數據是企業生產經營的一次重大變革,對于工業化、信息化都還沒有完成的工業企業而言,數據化時代又到來了,挑戰很大。
工業大數據建設,首先是一種思維變革,改變以前以要素競爭為主的工業生產模式,進入到數據和創新競爭為主的新生產時代。其次,正如清華大學王建民教授所言“工業大數據不存在交鑰匙工程”,因此,需要企業領導人、管理層、員工和相關人都投身其中,各司其職,才有所成。
最后,工業大數據建設抓住兩個板子作為突破點。一個是最長的板,也就是梳理產品(工業)競爭力最強的在哪里,繼續深挖下面的數據價值,圍繞這一塊的工業數據構建產品和服務能力;另一個是最短的板,就是影響工業企業發展的痛點在哪里,成本、市場、還是供應鏈,還是能耗?在數據化時代下,尋找機遇大數據的解決方案。
藍海長青科技發展
以恒逸石化為例,如何實現“數采- 建模 -應用 - 反饋 - 服務”閉環?
導讀:關于數據驅動的價值理念,卻很少在實踐中完整閉環應用,這造成了盡管是很好的理念和思想,但要想在企業和場景中應用,確實是一件不太容易的事情。
本文內容節選于畢馬威和阿里研究院聯合發布的《從工具革命到決策革命——通向智能制造的轉型之路》(版權歸發布者所有),選擇了《恒逸石化– 用工業大腦實現能耗優化》的案例,重點闡釋“數據采集 - 模型搭建 -模型應用 - 反饋控制 - 服務提升”,實現鍋爐燃燒能耗優化的全過程。
過去十多年來物聯網、人工智能、數字孿生等科技的爆發性發展帶來了算力和算法的巨大進步,傳統制造業的數字化發展又帶來了海量的數據。三者的日益融合逐漸形成了以“數據 + 算力 + 算法”為核心的智能制造技術體系。
數據是基礎,也是智能經濟的核心生產資料,在產業鏈各環節產生的大量數據是驅動智能制造提高精準度的核心;
數據(Big Data):工業數據的收集和分析早在傳統工業信息化時期就一直在進行,有大量的數據來自于研發端、生產制造過程、服務環節。而工業從數據到大數據,最大的區別是實現數據的兩化融合,將工業化數據與自動化域數據的疊加。在工業互聯網時代,還需要納入更多來自產業鏈上下游以及跨界的數據。實現工業大數據的主要核心技術包括物聯網 (IoT)、MEMS 傳感器和大數據技術等,其中尤以物聯網和 MEMS 傳感器為代表:
物聯網(IoT):物聯網是指通過嵌入電子傳感器,執行器或其他數字設備的方式將所有物品通過網絡鏈接起來,通過萬物互聯來收集和交換數據,從而實現智能化識別、定位、跟蹤、監控和管理。物聯網的幾大關鍵技術包括傳感器技術、RFID 標簽和嵌入式系統技術。這些技術可以實現透明化生產、數字化車間、智能化工廠,減少人工干預,提高工廠設施整體協作效率、提高產品質量一致性。
傳感器MEMS全稱為 Micro Electro Mechanical System,即微機電系統,是集微傳感器、微執行器、微機械結構、微電源微能源、信號處理和控制電路、高性能電子集成器件、接口、通信等于一體的微型器件或系統,是一個獨立的智能系統,可大批量生產,其系統尺寸在幾毫米乃至更小,其內部結構一般在微米甚至納米量級。
有了海量數據,就需要強有力的算力進行處理,而以云計算、邊緣計算為代表的計算技術,為高效、準確地分析大量數據提供了有力支撐;
但是,僅有了數據和算力依然不夠,沒有先進的算法也很難發揮出數據真正的價值。以人工智能、機理模型等為代表的算法技術幫助智能制造發現規律并提供智能決策支持;
與此同時,以 5G、TSN 為代表的現代通訊網絡憑借其高速度、廣覆蓋、低時延等特點起到了關鍵的連接作用。它將三大要素緊密地連接起來,讓它們協同作業,發揮出巨大的價值。
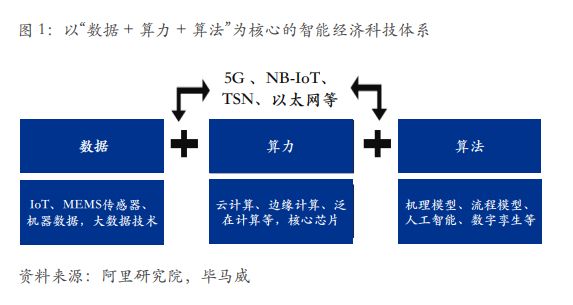
由核心技術集群使能的“數據 + 算法 + 算力”模式使得制造領域中的數字世界、物理世界以及人三者間產生了融合,其中數字世界是指工業軟件和管理軟件、工業設計、互聯網和移動互聯網等;物理世界是指能源、工作環境、工廠以及機器設備、原料與產品等。
基于數據驅動和算法模型推動形成的應用服務,構成了智能化的邏輯閉環。只有在形成有效閉環,才可釋放數據的價值,才能創造直接或間接的經濟效益,制造企業客戶才會買單。
【案例】恒逸石化– 用工業大腦實現能耗優化
【背景介紹】:恒逸石化是中國的一家大型化纖生產企業。化纖屬于高耗能行業,公司每年煤炭消耗高達幾億元人民幣。為了實現“十三五”計劃所明確的以創新驅動,綠色低碳發展的行業發展目標,企業引入工業大腦的決策流程,通過數據采集 - 模型搭建 -模型應用 - 反饋控制 - 服務提升,實現鍋爐燃燒能耗優化。
其本質是通過“數據 + 模型”,構建新型服務體系。
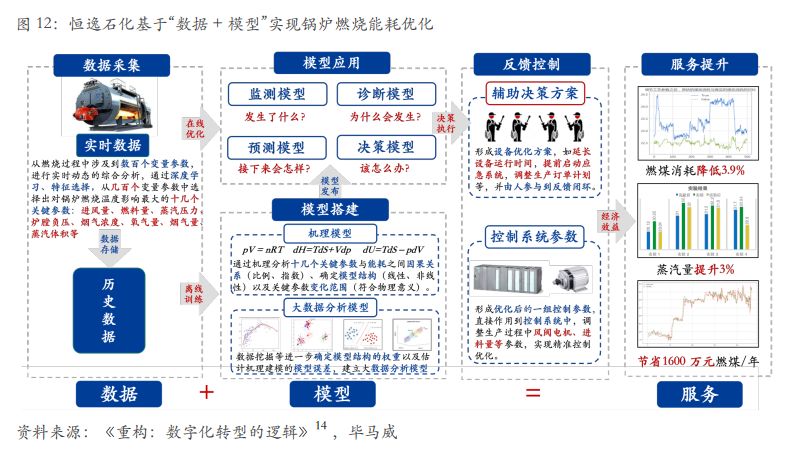
1.數據采集。恒逸石化對燃燒過程中涉及到的數百個變量參數進行深度挖掘,識別出對鍋爐燃燒能耗影響最大的十幾個關鍵參數,如進風量、燃料量、蒸汽壓力、爐膛負壓、煙氣濃度、氧氣量、煙氣量、蒸汽體積等,并重點采集十幾個關鍵參數與燃燒能耗一段時間內的歷史數據,形成離線學習樣本集。
2.模型搭建。基于確定的十幾個關鍵參數,一方面,通過數理分析、機理推導,得出關鍵參數與燃燒能耗之間的機理模型,并基于機理模型定性分析出關鍵參數(控制量)與燃燒能耗(被控量)之間的變量關系(增減、比例、指數)、模型結構(一次、二次、高次),以及部分關鍵參數在一定物理條件下的合理變化范圍,初步確定模型部分結構信息。
另一方面,基于大量的離線學習樣本數據,通過數據挖掘(回歸、聚類、分類、關聯等)方法對已確定的機理模型進行反復訓練優化,得到離線數據學習下精確的模型。
3.模型應用。訓練后的模型可以部署在本地也可部署在云端,一旦模型部署應用,新的在線數據將源源不斷輸入到離線訓練的模型中,一方面,基于在線優化算法可以動態優化,進一步完善模型參數。
另一方面,模型輸出結果可以形成四類模型,用來解釋工業現場四個基本問題:一是解釋發生了什么,即監測模型,如故障報警,超界響鈴等;二是解釋為什么會發生,即診斷模型,如故障診斷模型、故障定位模型;三是解釋接下來會怎樣,即預測模型,如剩余壽命預測模型,功率預測模型;四是解釋該怎么辦,即決策模型,如維護策略模型,控制策略模型。
4.反饋控制。所有的模型最終都需要將輸出的結果反饋給實際對象形成閉環,反饋控制存在兩種方式:一種是模型輸出輔助決策方案,如是否需要延長設備運行時間、提前啟動應急系統,調整生產訂單計劃等,并由人參與到反饋閉環。
另一種是模型直接輸出優化后的一組控制參數,直接作用到控制系統中,調整生產過程中風閥電機、進料量等參數,實現精準控制優化。當前,企業中廣泛采用的是基于模型的輔助決策,并由人參與到反饋閉環過程。在環境擾動較小、系統模型相對簡單生產過程中可采用直接作用到控制回路的方式。
5.服務提升。無論是優化后的決策方案還是優化后的控制參數一旦作用到實際物理對象中,都能夠對設備運行的各項相關參數進行優化調整,進而改變系統整體能耗、停機維修成本等,產生實際的經濟效益。恒逸石化基于“數據 + 模型”構建新型服務體系,實現燃煤消耗降低 4%左右,蒸汽量提升約 3%,每年節省 1000 多萬元燃煤成本。
-
互聯網
+關注
關注
54文章
11158瀏覽量
103351 -
工業4.0
+關注
關注
48文章
2014瀏覽量
118646 -
工業大數據
+關注
關注
0文章
72瀏覽量
7844
原文標題:一文讀懂工業大數據
文章出處:【微信號:wulianwang66,微信公眾號:互聯網工業】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NTC熱敏電阻在工業領域的應用
如何利用大型語言模型驅動的搜索為公司創造價值

FPGA在自動駕駛領域有哪些應用?
人工智能大模型在工業網絡安全領域的應用
高精度定位技術在工業控制領域有哪些應用呢

PID在工業控制領域的應用
工業平板電腦在新能源的應用
邊緣計算工業網關在工業生產中的價值與應用

淺析樂華工業平板電腦應用領域
邊緣計算網關的工作原理及其在工業領域的應用價值

工業物聯網平臺在智慧水務領域的智能應用





 工商網監
工商網監
評論