") 用于學(xué)習(xí)圖結(jié)構(gòu)對象相似性的圖匹配網(wǎng)絡(luò)
用于學(xué)習(xí)圖結(jié)構(gòu)對象相似性的圖匹配網(wǎng)絡(luò)
DeepMind & Google最新論文提出圖匹配網(wǎng)絡(luò),用于相似性學(xué)習(xí)問題,在幾大圖相關(guān)任務(wù)中性能超過了標(biāo)準(zhǔn)圖網(wǎng)絡(luò)GNN和其他模型。
一種新的圖匹配網(wǎng)絡(luò),在幾個圖相關(guān)任務(wù)中均勝過精心設(shè)計的神經(jīng)網(wǎng)絡(luò)模型和基于標(biāo)準(zhǔn)GNN的圖嵌入模型。
本文介紹來自DeepMind & Google的一篇ICML論文:《用于學(xué)習(xí)圖結(jié)構(gòu)對象相似性的圖匹配網(wǎng)絡(luò)》。

地址:
https://arxiv.org/pdf/1904.12787.pdf
這篇論文針對圖結(jié)構(gòu)對象的檢索與匹配這一具有挑戰(zhàn)性的問題,做了兩個關(guān)鍵的貢獻(xiàn)。
首先,作者演示了如何訓(xùn)練圖神經(jīng)網(wǎng)絡(luò)(GNN)在向量空間中生成圖嵌入,從而實現(xiàn)高效的相似性推理。
其次,作者提出了一種新的圖匹配網(wǎng)絡(luò)(Graph Matching Network)模型,給出一對圖形作為輸入,通過一種新的基于注意力的跨圖匹配機制(cross-graph attention-based matching mechanism),對圖對進(jìn)行聯(lián)合推理,計算出一對圖之間的相似度評分。
論文證明了該模型在不同領(lǐng)域的有效性,包括具有挑戰(zhàn)性的基于控制流圖(control-flow-graph)的函數(shù)相似性搜索問題,該問題在軟件系統(tǒng)漏洞檢測中具有重要作用。
實驗分析表明,圖匹配模型不僅能夠在相似性學(xué)習(xí)的背景下利用結(jié)構(gòu),而且還能夠勝過針對這些問題精心手工設(shè)計的領(lǐng)域特定的基線系統(tǒng)。
圖結(jié)構(gòu)對象的相似性學(xué)習(xí)問題
圖是編碼關(guān)系結(jié)構(gòu)的一種自然的表示,這種關(guān)系結(jié)構(gòu)在許多領(lǐng)域都會遇到。通過圖結(jié)構(gòu)數(shù)據(jù)定義的計算被廣泛應(yīng)用于各領(lǐng)域,從用于計算生物學(xué)和化學(xué)的分子分析,到自然語言理解的知識圖或圖結(jié)構(gòu)解析的分析。
近年來,圖神經(jīng)網(wǎng)絡(luò)(GNNs)已成為一種有效的學(xué)習(xí)結(jié)構(gòu)化數(shù)據(jù)表示和解決基于圖的各種監(jiān)督預(yù)測問題的模型。通過迭代地聚合局部結(jié)構(gòu)信息的傳播過程來設(shè)計和計算圖節(jié)點表示,這些模型對圖元素的排列是不變的。然后,這些節(jié)點表示被直接用于節(jié)點分類,或者合并到一個圖向量中用于圖分類。對于GNN,除了監(jiān)督分類或回歸之外的問題的研究相對較少。
本文研究了圖結(jié)構(gòu)對象的相似性學(xué)習(xí)問題(similarity learning),該問題在現(xiàn)實世界中有許多重要的應(yīng)用,尤其是在圖數(shù)據(jù)庫中基于相似性的檢索。
一個應(yīng)用是二進(jìn)制函數(shù)計算機安全問題的相似性搜索,給定一個可能包含或不包含具有已知漏洞代碼的二進(jìn)制,我們要檢查該二進(jìn)制中的任何控制流圖是否與數(shù)據(jù)庫中已知易受攻擊的函數(shù)非常相似。
這有助于在封閉源代碼軟件中識別易受攻擊的靜態(tài)鏈接庫,這是一個反復(fù)出現(xiàn)的問題,目前沒有好的解決方案。
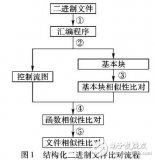
圖1顯示了該應(yīng)用的一個示例,其中二進(jìn)制函數(shù)表示為帶有匯編指令注釋的控制流圖。
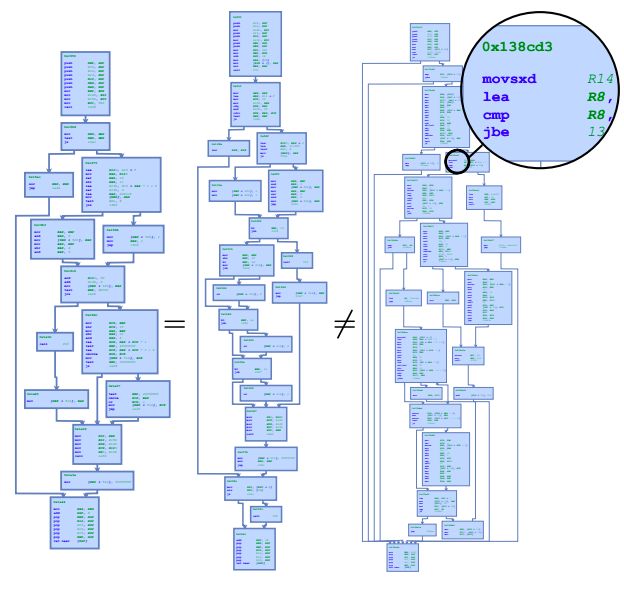
二進(jìn)制函數(shù)相似性學(xué)習(xí)問題
這種相似性學(xué)習(xí)問題非常具有挑戰(zhàn)性,因為細(xì)微的差異就可以使兩個圖在語義上非常不同,而具有不同結(jié)構(gòu)的圖仍然可以是相似的。
因此,一個成功的模型應(yīng)該:
(1)利用圖的結(jié)構(gòu),
(2)能夠從圖的結(jié)構(gòu)和所學(xué)習(xí)的語義推斷出圖的相似性。
為了解決圖的相似度學(xué)習(xí)問題,我們研究了GNN在這種情況下的使用,探討了如何將圖嵌入到向量空間中,并學(xué)習(xí)這種嵌入模型,使相似的圖在向量空間中更接近,而不同的圖在向量空間中距離更大。
該模型的一個重要特性是,它將每個圖獨立地映射到一個嵌入向量,然后所有的相似度計算都在向量空間中進(jìn)行。因此,可以預(yù)先計算和索引大型數(shù)據(jù)庫中的圖嵌入,從而能夠使用快速的最近鄰搜索數(shù)據(jù)結(jié)構(gòu)(如k-d trees)或局部敏感哈希算法(locality sensitive hashing)實現(xiàn)高效檢索。
我們進(jìn)一步提出了一種對GNN的擴(kuò)展,我們稱之為圖匹配網(wǎng)絡(luò)(Graph Matching Networks, GMNs),用于相似性學(xué)習(xí)。
GMN不是單獨計算每個圖的表示,而是通過cross-graph的注意力機制來計算相似度評分,以便跨圖進(jìn)行關(guān)聯(lián)節(jié)點和識別差異。通過使圖表示計算依賴于對(pair),該匹配模型比嵌入模型更強大,提供了良好的精度-計算的權(quán)衡。
我們在三個任務(wù)上評估了所提出的模型和基線模型:一個是合成圖edit-distance學(xué)習(xí)任務(wù),僅捕獲結(jié)構(gòu)相似性;以及兩個現(xiàn)實世界任務(wù)——二進(jìn)制函數(shù)相似性搜索和網(wǎng)格檢索,這兩個任務(wù)都需要對結(jié)構(gòu)相似性和語義相似性進(jìn)行推理。
在所有三個任務(wù)上,我們提出的方法都優(yōu)于已有的基線模型和結(jié)構(gòu)無關(guān)模型;在更詳細(xì)的消融研究中,我們發(fā)現(xiàn)圖匹配網(wǎng)絡(luò)始終優(yōu)于圖嵌入模型和Siamese網(wǎng)絡(luò)。
總結(jié)而言,本文的貢獻(xiàn)在于:
(1)演示了如何使用GNN生成用于相似性學(xué)習(xí)的圖嵌入;
(2)提出了一種新的圖匹配網(wǎng)絡(luò),通過基于cross-graph的注意力匹配來計算相似性;
(3)實證結(jié)果表明,本文所提出的圖相似性學(xué)習(xí)模型在多個應(yīng)用中具有良好的性能,并且優(yōu)于結(jié)構(gòu)無關(guān)模型和已有的基線模型。
深度圖相似性學(xué)習(xí)
給定兩個圖G = (V?, E?)和G? = (V?, E?),我們想要有一個模型來生成它們之間的相似度評分s(G?, G?)。每個圖表示為G = (V, E),即節(jié)點V和邊E的集合,任意一個節(jié)點i∈V都可以與一個特征向量x_i相關(guān)聯(lián),任意一條邊(i, j)∈E都可以與一個特征向量x_ij相關(guān)聯(lián)。這些特征可以表示諸如節(jié)點的類型、邊的方向等。如果一個節(jié)點或一條邊沒有任何相關(guān)的特征,我們就將相應(yīng)的向量設(shè)置為常數(shù)向量1。
我們提出了兩種圖相似度學(xué)習(xí)模型:一種是基于標(biāo)準(zhǔn)GNN的學(xué)習(xí)圖嵌入模型,以及一種新的、更強大的GMN模型。
兩種模型如圖2所示。
圖嵌入模型(Graph Embedding Models)
圖嵌入模型是將每個圖嵌入到一個向量中,然后在該向量空間中使用相似性度量來度量圖之間的相似性。我們的GNN嵌入模型包括三個部分:(1)編碼器,(2)傳播層,(3)聚合器。
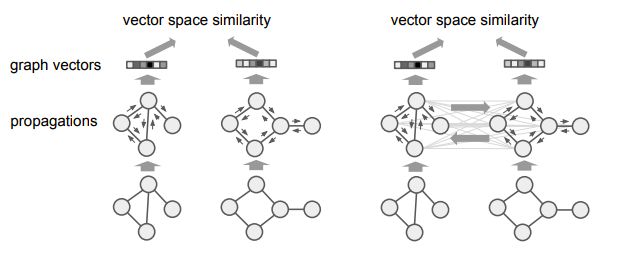
圖2:圖嵌入模型(左)和圖匹配模型(右)
圖匹配網(wǎng)絡(luò)
圖匹配網(wǎng)絡(luò)以一對圖作為輸入,并計算它們之間的相似度評分。與嵌入模型相比,匹配模型是在“對”的基礎(chǔ)上計算相似度的,而不是先將每個圖單獨映射到一個向量。因此,匹配模型可能比嵌入模型更強大,但代價是額外的計算效率。
我們提出如下的圖匹配網(wǎng)絡(luò),改變了每個傳播層中的節(jié)點的更新模塊,不僅考慮每個圖邊緣的聚合信息,也考慮衡量一個節(jié)點在一個圖中匹配其他一個或多個節(jié)點的效果的cross-graph匹配向量:
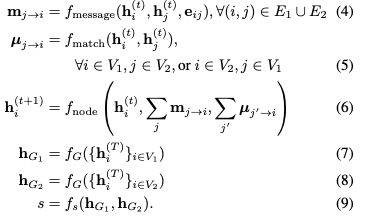
實驗和結(jié)果
本節(jié)在三個任務(wù)上評估了圖相似性學(xué)習(xí)(GSL)框架和圖嵌入網(wǎng)絡(luò)(GNN)和圖匹配網(wǎng)絡(luò)(GMN),并將這些模型與其他競爭方法進(jìn)行了比較。
總體而言,實驗結(jié)果表明,GMN在圖相似度學(xué)習(xí)方面表現(xiàn)優(yōu)異,始終優(yōu)于其他方法。
Learning Graph Edit Distances
圖G?和圖G?之間的圖編輯距離(Graph edit distance)的定義是將G?轉(zhuǎn)換為G2所需的最小編輯操作數(shù)。通常,編輯操作包括添加/刪除/替換節(jié)點和邊緣。
圖的編輯距離自然是圖之間相似性的度量,在圖的相似性搜索中有許多應(yīng)用。通過這個實驗,我們證明了GSL模型可以在極具挑戰(zhàn)性的問題上學(xué)習(xí)圖之間的結(jié)構(gòu)相似性。
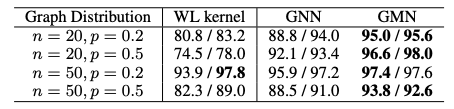
表1:圖嵌入(GNN)和圖匹配(GMN)模型與基線的比較
從表1可以看到,通過學(xué)習(xí)特定分布的圖,GSL模型能夠比一般基線做得更好,而GMN始終優(yōu)于嵌入模型(GNN)。
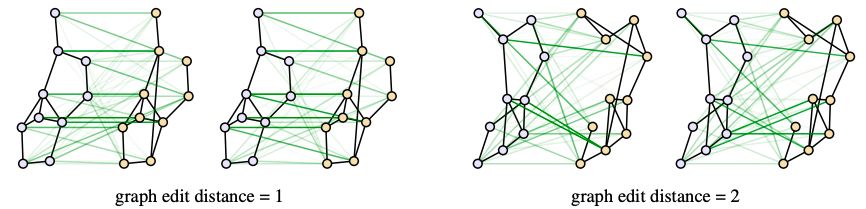
圖3:圖匹配模型cross-graph attention的可視化
對于GMN,我們可以將cross-graph attention可視化,從而進(jìn)一步了解它是如何工作的。圖3顯示了匹配模型的兩個例子,cross-graph注意力權(quán)重以綠色表示,權(quán)重的比例以綠色邊的透明度表示。我們可以看到,當(dāng)兩個圖匹配時,注意力權(quán)重可以很好地對齊節(jié)點,當(dāng)兩個圖不匹配時,注意力權(quán)重往往集中在度數(shù)較高的節(jié)點上。然而,這種模式并不像標(biāo)準(zhǔn)注意力模型那樣具有可解釋性。
基于控制流圖的二進(jìn)制函數(shù)相似性搜索
二進(jìn)制函數(shù)相似性搜索(Binary function similarity search)是計算機安全中的一個重要問題。當(dāng)我們無法訪問源代碼時,例如在處理商業(yè)或嵌入式軟件或可疑的可執(zhí)行程序時,就需要分析和搜索二進(jìn)制文件。結(jié)合反匯編器和代碼分析器,我們可以提取一個控制流圖(CFG),它以結(jié)構(gòu)化格式包含二進(jìn)制函數(shù)中的所有信息。
在CFG中,每個節(jié)點都是組裝指令的基本塊,節(jié)點之間的邊表示控制流,例如在分支、循環(huán)或函數(shù)調(diào)用中使用的跳轉(zhuǎn)或返回指令表示。
本節(jié)中,我們將針對漏洞搜索問題,其中使用已知存在一些漏洞的二進(jìn)制代碼片段作為查詢,并通過一個庫搜索,找到可能具有相同漏洞的類似二進(jìn)制代碼。
結(jié)果如圖4所示,評估了不同模型在不同傳播步數(shù)和不同數(shù)據(jù)設(shè)置下的性能。
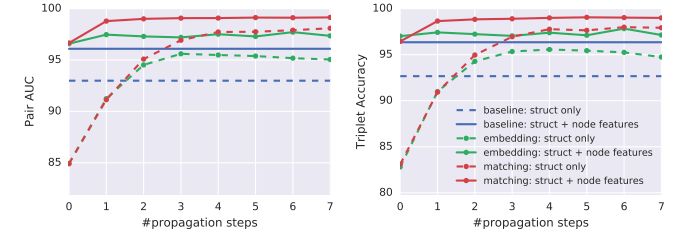
圖4:不同模型在二進(jìn)制函數(shù)相似性搜索任務(wù)中的性能
結(jié)果很顯然:
(1)隨著傳播步數(shù)增加,圖嵌入模型和匹配模型的性能都不斷增高;
(2)在傳播步數(shù)足夠的情況下,圖嵌入模型始終優(yōu)于基線;
(3)圖匹配模型在所有設(shè)置和傳播步數(shù)的情況下都優(yōu)于嵌入模型。

表2:函數(shù)相似性搜索任務(wù)的更多結(jié)果
表2總結(jié)了更多實驗,結(jié)果表明:
(1)GNN嵌入模型是有競爭力的模型(比GCN模型更強大);
(2)利用Siamese網(wǎng)絡(luò)結(jié)構(gòu)在圖表示的基礎(chǔ)上學(xué)習(xí)相似度優(yōu)于使用預(yù)先指定的相似度度量;
(3)在計算過程的早期,GMN優(yōu)于Siamese模型,說明了跨圖信息通信的重要性。
-
谷歌
+關(guān)注
關(guān)注
27文章
6172瀏覽量
105631 -
二進(jìn)制
+關(guān)注
關(guān)注
2文章
795瀏覽量
41689 -
GNN
+關(guān)注
關(guān)注
1文章
31瀏覽量
6357
原文標(biāo)題:超越標(biāo)準(zhǔn) GNN !DeepMind、谷歌提出圖匹配網(wǎng)絡(luò)| ICML最新論文
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
影像匹配中幾種相似性測度的分析
基于相似性的圖像融合質(zhì)量的客觀評估方法
基于相似性度量的高維聚類算法的研究
基于項目相似性度量方法的項目協(xié)同過濾推薦算法
基于網(wǎng)絡(luò)本體語言O(shè)WL表示模型語義的相似性計算方法
一種基于SQL的圖相似性查詢方法
一種新的混合相似性權(quán)重的非局部均值去躁算法
基于劃分思想的文件結(jié)構(gòu)化相似性比較方法
云模型重疊度的相似性度量算法
基于節(jié)點相似性社團(tuán)結(jié)構(gòu)劃分
耦合沖擊濾波器的片相似性各向異性擴(kuò)散模型
如何使用會話時序相似性進(jìn)行矩陣分解數(shù)據(jù)填充
一種快速計算動態(tài)網(wǎng)絡(luò)相似性的方法
PyTorch教程15.7之詞的相似性和類比

基于結(jié)構(gòu)相似性可靠性監(jiān)測結(jié)果





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論