 自然語言處理中極其重要的句法分析
自然語言處理中極其重要的句法分析
本文簡要介紹了自然語言處理中極其重要的句法分析,并側重對依存句法分析進行了重點總結,包括定義、重要概念、基本方法、性能評價、依存分析數據集,最后,分享了一些流行的工具以及工具實戰例子。
01
句法分析
句法分析(syntactic parsing)是自然語言處理中的關鍵技術之一,它是對輸入的文本句子進行分析以得到句子的句法結構的處理過程。
對句法結構進行分析,一方面是語言理解的自身需求,句法分析是語言理解的重要一環,另一方面也為其它自然語言處理任務提供支持。例如句法驅動的統計機器翻譯需要對源語言或目標語言(或者同時兩種語言)進行句法分析。
語義分析通常以句法分析的輸出結果作為輸入以便獲得更多的指示信息。根據句法結構的表示形式不同,最常見的句法分析任務可以分為以下三種:
句法結構分析(syntactic structure parsing),又稱短語結構分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是識別出句子中的短語結構以及短語之間的層次句法關系。
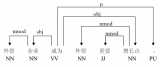
依存關系分析,又稱依存句法分析(dependency syntactic parsing),簡稱依存分析,作用是識別句子中詞匯與詞匯之間的相互依存關系。
深層文法句法分析,即利用深層文法,例如詞匯化樹鄰接文法(Lexicalized Tree Adjoining Grammar,LTAG)、詞匯功能文法(Lexical Functional Grammar,LFG)、組合范疇文法(Combinatory Categorial Grammar,CCG)等,對句子進行深層的句法以及語義分析。
02
依存句法定義
維基百科是這樣描述的:The dependency-based parse trees of dependency grammars see all nodes as terminal, which means they do not acknowledge the distinction between terminal and non-terminal categories. They are simpler on average than constituency-based parse trees because they contain fewer nodes.
依存句法是由法國語言學家L.Tesniere最先提出。它將句子分析成一顆依存句法樹,描述出各個詞語之間的依存關系。也即指出了詞語之間在句法上的搭配關系,這種搭配關系是和語義相關聯的。
在自然語言處理中,用詞與詞之間的依存關系來描述語言結構的框架稱為依存語法(dependence grammar),又稱從屬關系語法。利用依存句法進行句法分析是自然語言理解的重要技術之一。
03
重要概念
依存句法認為“謂語”中的動詞是一個句子的中心,其他成分與動詞直接或間接地產生聯系。
依存句法理論中,“依存”指詞與詞之間支配與被支配的關系,這種關系不是對等的,這種關系具有方向。確切的說,處于支配地位的成分稱之為支配者(governor,regent,head),而處于被支配地位的成分稱之為從屬者(modifier,subordinate,dependency)。
依存語法本身沒有規定要對依存關系進行分類,但為了豐富依存結構傳達的句法信息,在實際應用中,一般會給依存樹的邊加上不同的標記。
依存語法存在一個共同的基本假設:句法結構本質上包含詞和詞之間的依存(修飾)關系。一個依存關系連接兩個詞,分別是核心詞(head)和依存詞(dependent)。依存關系可以細分為不同的類型,表示兩個詞之間的具體句法關系。
04
常見方法
基于規則的方法:早期的基于依存語法的句法分析方法主要包括類似CYK的動態規劃算法、基于約束滿足的方法和確定性分析策略等。
基于統計的方法:統計自然語言處理領域也涌現出了一大批優秀的研究工作,包括生成式依存分析方法、判別式依存分析方法和確定性依存分析方法,這幾類方法是數據驅動的統計依存分析中最為代表性的方法。
基于深度學習的方法:近年來,深度學習在句法分析課題上逐漸成為研究熱點,主要研究工作集中在特征表示方面。傳統方法的特征表示主要采用人工定義原子特征和特征組合,而深度學習則把原子特征(詞、詞性、類別標簽)進行向量化,在利用多層神經元網絡提取特征。
05
依存分析器的性能評價
通常使用的指標包括:無標記依存正確率(unlabeled attachment score,UAS)、帶標記依存正確率(labeled attachment score, LAS)、依存正確率(dependency accuracy,DA)、根正確率(root accuracy,RA)、完全匹配率(complete match,CM)等。這些指標的具體意思如下:
無標記依存正確率(UAS):測試集中找到其正確支配詞的詞(包括沒有標注支配詞的根結點)所占總詞數的百分比。
帶標記依存正確率(LAS):測試集中找到其正確支配詞的詞,并且依存關系類型也標注正確的詞(包括沒有標注支配詞的根結點)占總詞數的百分比。
依存正確率(DA):測試集中找到正確支配詞非根結點詞占所有非根結點詞總數的百分比。
根正確率(RA):有二種定義,一種是測試集中正確根結點的個數與句子個數的百分比。另一種是指測試集中找到正確根結點的句子數所占句子總數的百分比。
完全匹配率(CM):測試集中無標記依存結構完全正確的句子占句子總數的百分比。
06
數據集
Penn Treebank:Penn Treebank 是一個項目的名稱,項目目的是對語料進行標注,標注內容包括詞性標注以及句法分析。
SemEval-2016 Task 9 中文語義依存圖數據:http://ir.hit.edu.cn/2461.html
下載地址:
https://github.com/HIT-SCIR/SemEval-2016
CoNLL 經常開放句法分析的學術評測,比如:
2018年的通用句法分析評測任務:
http://universaldependencies.org/conll18/
2009年多語言多語言的句法依存和語義角色聯合評測任務:http://ufal.mff.cuni.cz/conll2009-st/
2008年英語的依存句法-語義角色聯合評測任務:https://www.clips.uantwerpen.be/conll2008/
2007年多語言依存分析評測:https://www.clips.uantwerpen.be/conll2007/
07
工具推薦
1. StanfordCoreNLP
斯坦福大學開發的,提供依存句法分析功能。
Github 地址:
https://github.com/Lynten/stanford-corenlp
官網:
https://stanfordnlp.github.io/CoreNLP/
2. HanLP
HanLP 是一系列模型與算法組成的 NLP 工具包。提供了中文依存句法分析功能。
Github 地址:
https://github.com/hankcs/pyhanlp
官網:
http://hanlp.linrunsoft.com/
3. SpaCy
工業級的自然語言處理工具,遺憾的是目前不支持中文。
Gihub 地址:
https://github.com/explosion/spaCy
官網:
https://spacy.io/
4. FudanNLP
復旦大學自然語言處理實驗室開發的中文自然語言處理工具包,包含信息檢索: 文本分類、新聞聚類;中文處理: 中文分詞、詞性標注、實體名識別、關鍵詞抽取、依存句法分析、時間短語識別;結構化學習: 在線學習、層次分類、聚類。
Github 地址:
https://github.com/FudanNLP/fnlp
代碼已上傳:
https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/Dependency.ipynb
參考:
1.統計自然語言處理
2.中文信息處理報告-2016
-
機器翻譯
+關注
關注
0文章
139瀏覽量
14914 -
深度學習
+關注
關注
73文章
5507瀏覽量
121272 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13581
原文標題:別說還不懂依存句法分析
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自然語言處理技術介紹
NLPIR語義分析是對自然語言處理的完美理解
hanlp漢語自然語言處理入門基礎知識介紹
【推薦體驗】騰訊云自然語言處理
基于本體和句法分析的領域分詞的實現
自然語言處理怎么最快入門_自然語言處理知識了解
自然語言處理入門基礎之hanlp詳解
什么是句法分析





 工商網監
工商網監
評論