 圍繞計算機視覺領域的八大任務,進行了較為詳細的綜述
圍繞計算機視覺領域的八大任務,進行了較為詳細的綜述
編者按:
來自百度的深度學習工程師,圍繞計算機視覺領域的八大任務,包括:圖像分類、目標檢測、圖像語義分割、場景文字識別、圖像生成、人體關鍵點檢測、視頻分類、度量學習等,進行了較為詳細的綜述并形成此文。
這篇綜述中,介紹了這些任務的基本情況,以及目前的技術進展、主要的模型和性能對比等。而且還逐一附上了GitHub傳送門,用于更進一步的學習與安裝實踐指南。其中不少教程還是用中文寫成,非常友好。
總之,這篇綜述全程干貨,推薦收藏閱讀。
上篇
計算機視覺(Computer Vision)是研究如何使機器“看”的科學,更進一步的說,是使用攝像機機和電腦代替人眼對目標進行識別、跟蹤和測量等的機器視覺,并通過電腦處理成為更適合人眼觀察或傳送給儀器檢測的圖像。
形象地說,就是給計算機安裝上眼睛(攝像機)和大腦(算法),讓計算機像人一樣去看、去感知環境。計算機視覺技術作為人工智能的重要核心技術之一,已廣泛應用于安防、金融、硬件、營銷、駕駛、醫療等領域。本文上篇中,我們將介紹基于PaddlePaddle的四種計算機視覺技術及其相關的深度學習模型。
一、圖像分類
圖像分類是根據圖像的語義信息對不同類別圖像進行區分,是計算機視覺中重要的基礎問題,是物體檢測、圖像分割、物體跟蹤、行為分析、人臉識別等其他高層視覺任務的基礎。
圖像分類在許多領域都有著廣泛的應用。如:安防領域的人臉識別和智能視頻分析等,交通領域的交通場景識別,互聯網領域基于內容的圖像檢索和相冊自動歸類,醫學領域的圖像識別等。
得益于深度學習的推動,圖像分類的準確率大幅度提升。在經典的數據集ImageNet上,訓練圖像分類任務常用的模型,包括AlexNet、VGG、GoogLeNet、ResNet、Inception-v4、MobileNet、MobileNetV2、DPN(Dual Path Network)、SE-ResNeXt、ShuffleNet等。
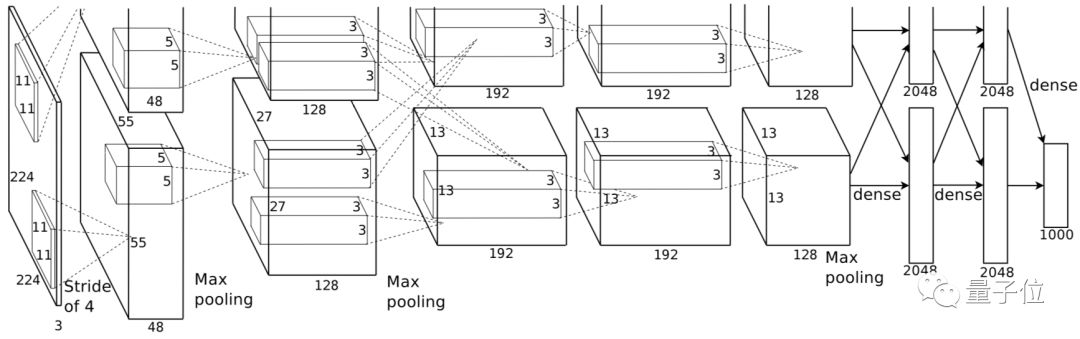
△AlexNet
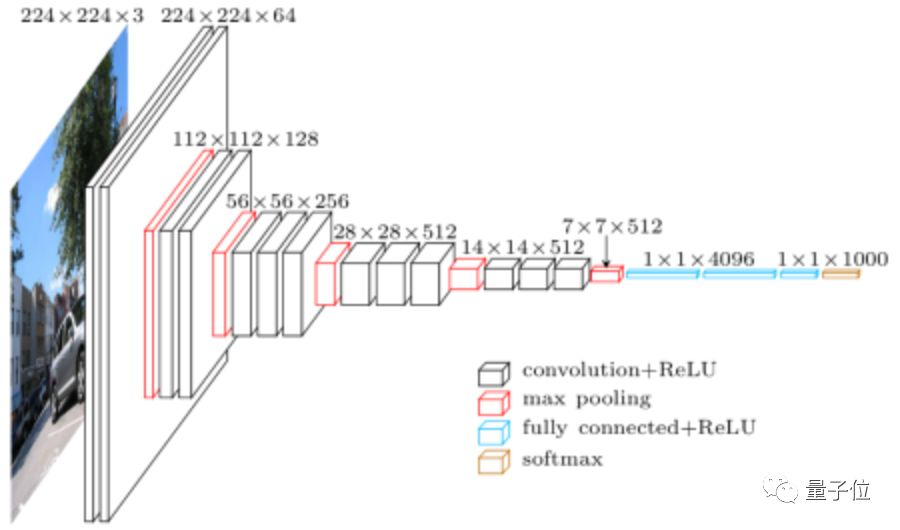
△VGG
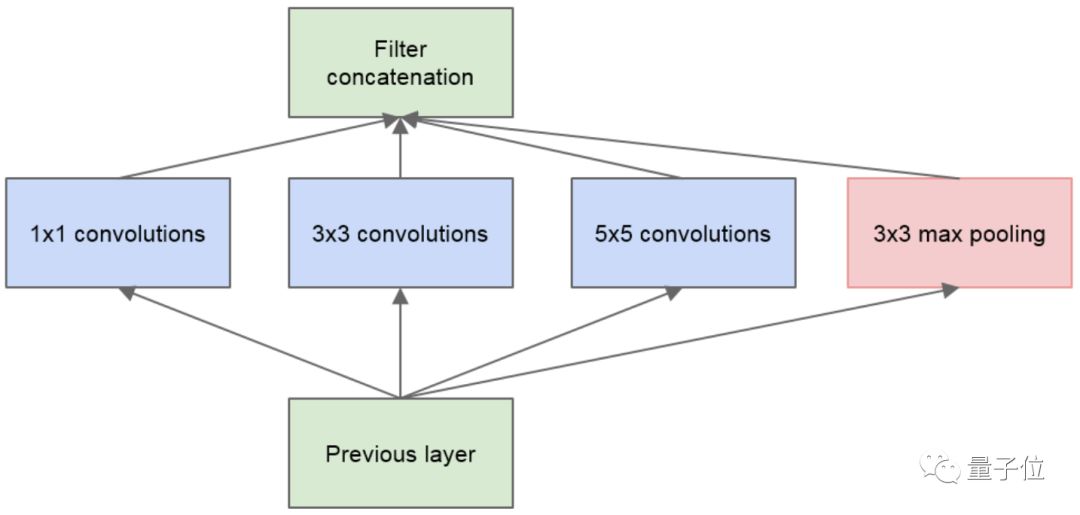
△GoogLeNet
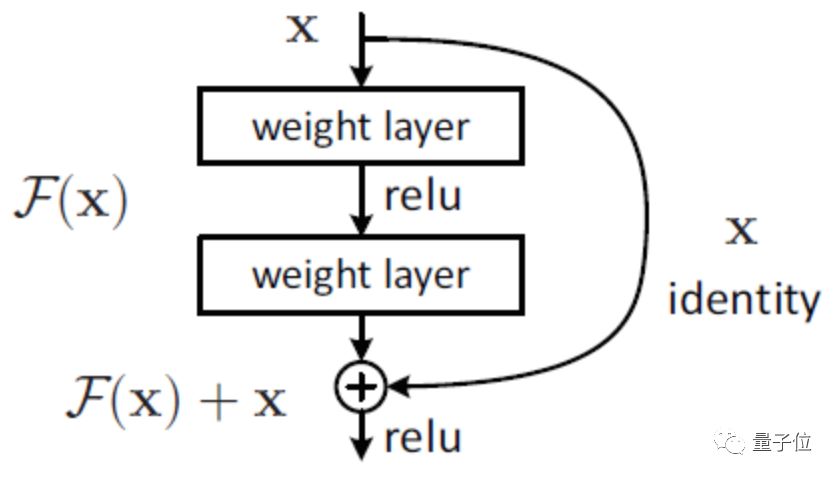
△ResNet
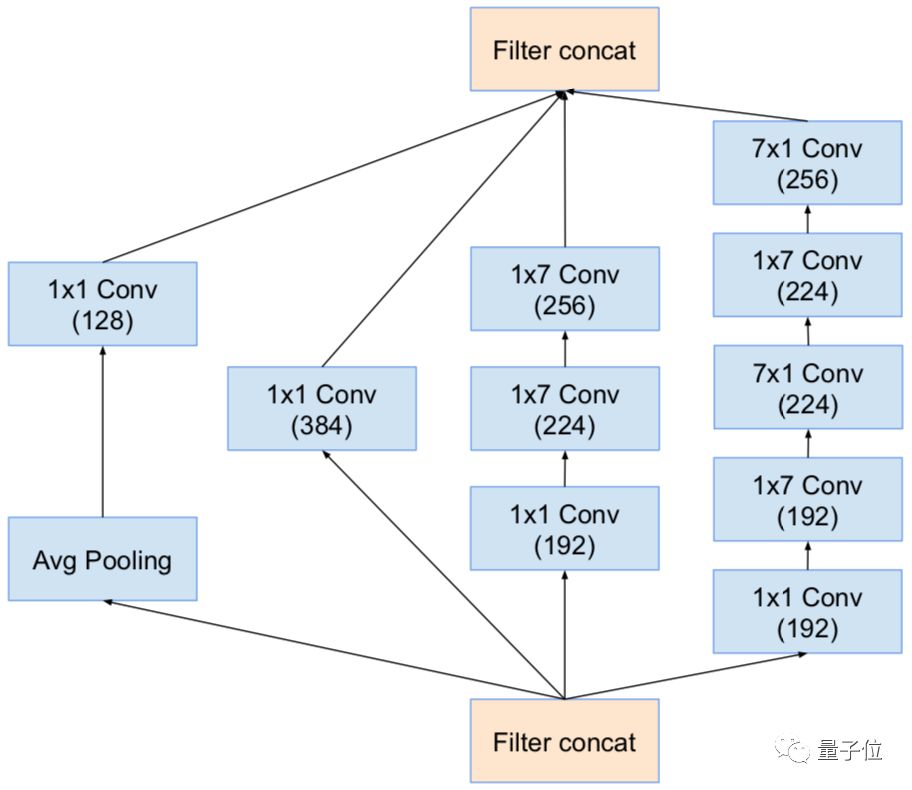
△Inception-v4
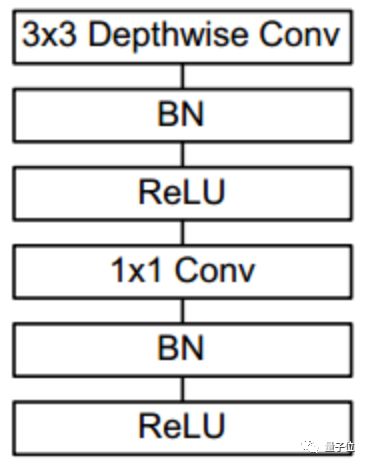
△MobileNet
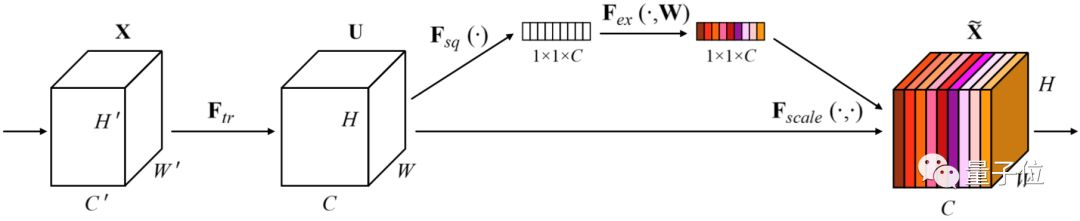
△SE-ResNeXt
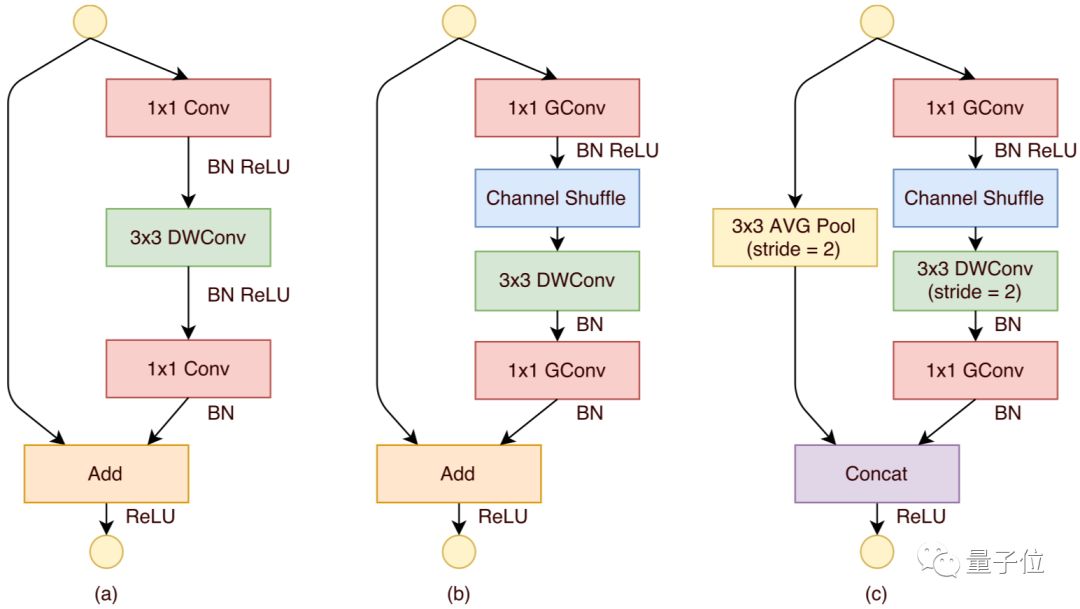
△ShuffleNet
模型的結構和復雜程度都不一樣,最終得到的準確率也有所區別。下面這個表格中,列出了在ImageNet 2012數據集上,不同模型的top-1/top-5驗證準確率。
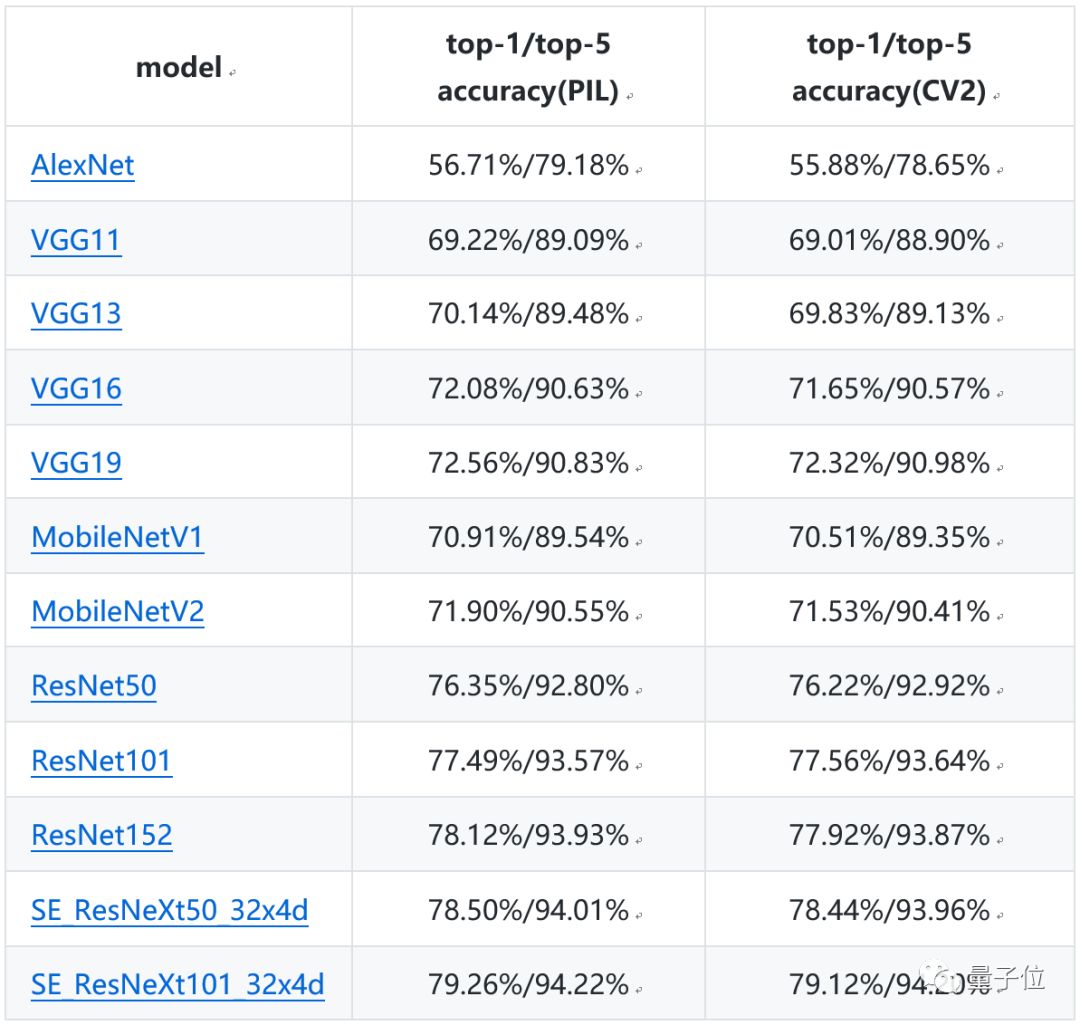
△圖像分類系列模型評估結果
在我們的GitHub頁面上,提供上述與訓練模型的下載。以及詳細介紹了如何使用PaddlePaddle Fluid進行圖像分類任務。包括安裝、數據準備、模型訓練、評估等等全部過程。還有將Caffe模型轉換為PaddlePaddle Fluid模型配置和參數文件的工具。
上述頁面的傳送門在此:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/image_classification

二、目標檢測
目標檢測任務的目標是給定一張圖像或是一個視頻幀,讓計算機找出其中所有目標的位置,并給出每個目標的具體類別。
對于人類來說,目標檢測是一個非常簡單的任務。然而,計算機能夠“看到”的是圖像被編碼之后的數字,很難解圖像或是視頻幀中出現了人或是物體這樣的高層語義概念,也就更加難以定位目標出現在圖像中哪個區域。
與此同時,由于目標會出現在圖像或是視頻幀中的任何位置,目標的形態千變萬化,圖像或是視頻幀的背景千差萬別,諸多因素都使得目標檢測對計算機來說是一個具有挑戰性的問題。
在目標檢測任務中,我們主要介紹如何基于PASCAL VOC、MS COCO數據訓練通用物體檢測模型,包括SSD模型、PyramidBox模型、R-CNN模型。
?SSD模型,Single Shot MultiBox Detector,是一種單階段的目標檢測器。與兩階段的檢測方法不同,單階段目標檢測并不進行區域推薦,而是直接從特征圖回歸出目標的邊界框和分類概率。SSD 運用了這種單階段檢測的思想,并且對其進行改進:在不同尺度的特征圖上檢測對應尺度的目標,是目標檢測領域較新且效果較好的檢測算法之一,具有檢測速度快且檢測精度高的特點。
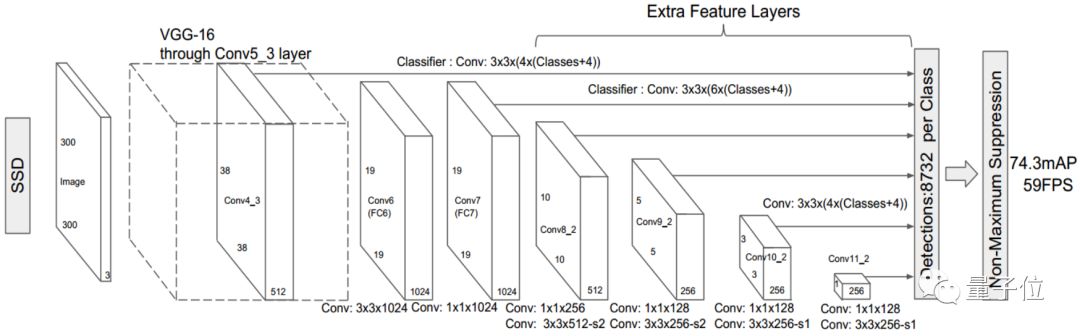
△SSD目標檢測模型結構
△SSD目標檢測可視化

△目標檢測SSD模型評估結果
在GitHub上,我們更詳細的介紹了如何下載、訓練、使用這一模型。
傳送門在此:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/object_detection
?PyramidBox模型,百度自主研發的人臉檢測模型,是一種語境輔助的單次人臉檢測新方法,能夠解決在不受控制的環境中檢測小的、模糊的及部分遮擋的人臉時的問題,模型于18年3月份在WIDER Face數據集上取得第一名。
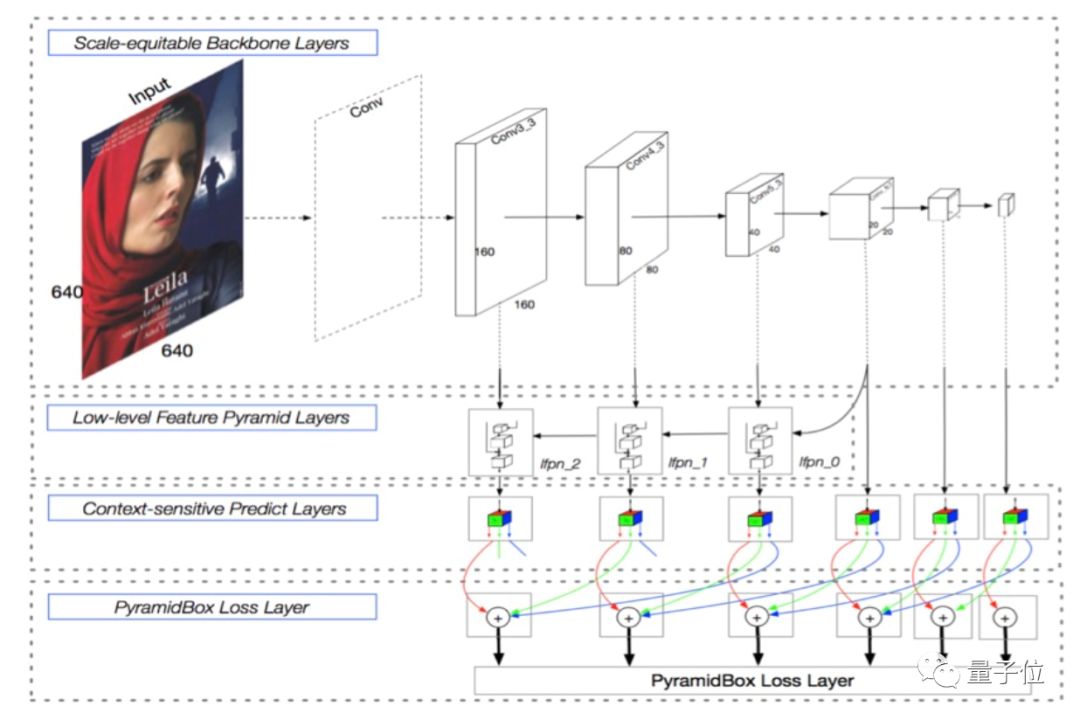
△Pyramidbox 人臉檢測模型
△Pyramidbox 預測可視化

△PyramidBox模型評估結果
如果想進一步了解這個模型,傳送門在此(而且是全中文指導):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/face_detection
?R-CNN系列模型,區域卷積神經網絡(R-CNN)系列模型是典型的兩階段目標檢測器,相較于傳統提取區域的方法,R-CNN中RPN網絡通過共享卷積層參數大幅提高提取區域的效率,并提出高質量的候選區域。Faster R-CNN和Mask R-CNN是R-CNN系列的典型模型。
Faster R-CNN 區域生成網絡(RPN)+Fast R-CNN的實現,將候選區域生成、特征提取、分類、位置精修統一到一個深度網絡框架,大大提高運行速度。
Mask R-CNN在原有Faster R-CNN模型基礎上添加分割分支,得到掩碼結果,實現了掩碼和類別預測關系的解藕,是經典的實例分割模型。
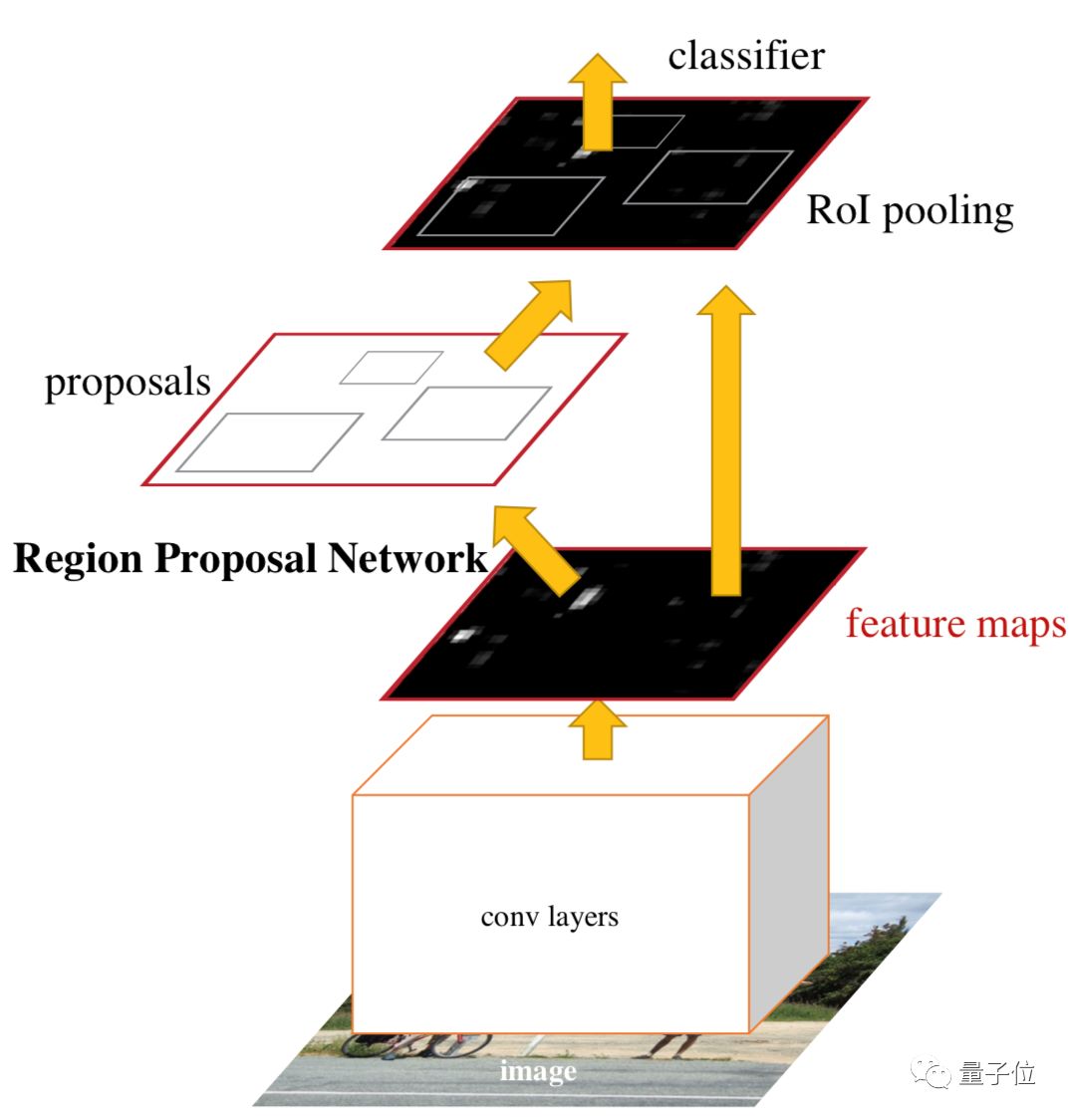
△Faster R-CNN 結構
△Faster R-CNN 預測可視化
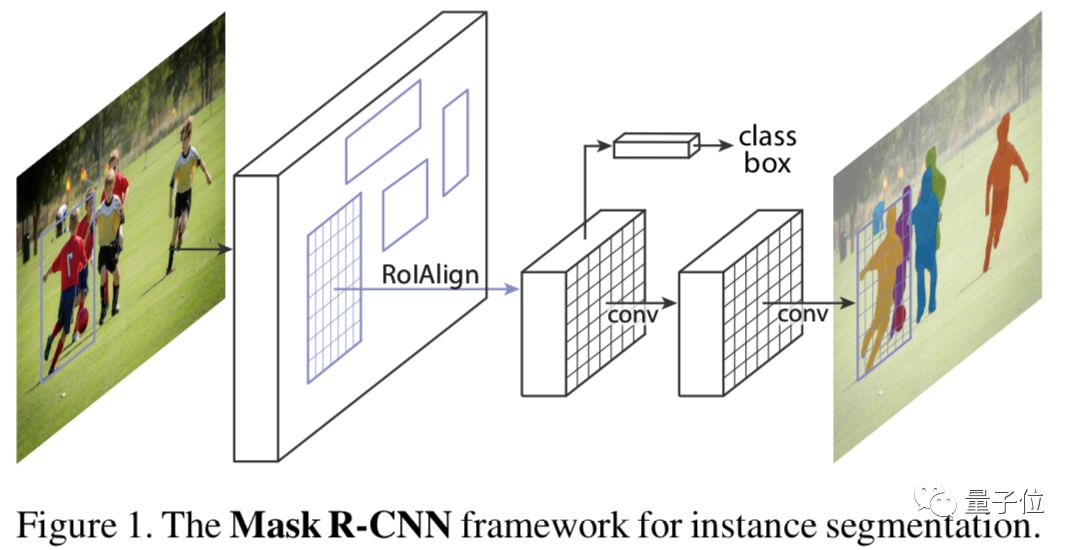
△Mask R-CNN結構
△Mask R-CNN 預測可視化
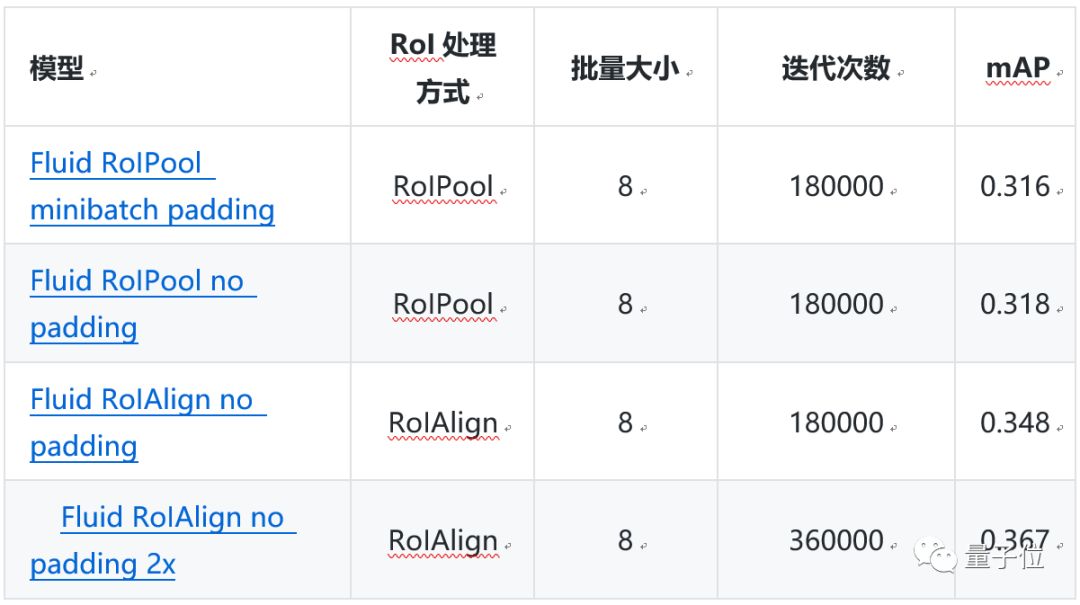
△Faster R-CNN評估結果

△Mask R-CNN評估結果
同樣,如果你想進一步學習R-CNN安裝、準備、訓練等,可以前往下面這個傳送門:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/rcnn
三、圖像語義分割
圖像語意分割,顧名思義是將圖像像素按照表達的語義含義的不同進行分組/分割。
圖像語義是指對圖像內容的理解,例如,能夠描繪出什么物體在哪里做了什么事情等,分割是指對圖片中的每個像素點進行標注,標注屬于哪一類別。近年來用在無人車駕駛技術中分割街景來避讓行人和車輛、醫療影像分析中輔助診斷等。
分割任務主要分為實例分割和語義分割,實例分割是物體檢測加上語義分割的綜合體,上文介紹的Mask R-CNN是實例分割的經典網絡結構之一。在圖像語義分割任務中,我們主要介紹兼顧準確率和速度的ICNet,DeepLab中最新、執行效果最好的DeepLab v3+。
?DeepLab v3+,DeepLab語義分割系列網絡的最新作,通過encoder-decoder進行多尺度信息的融合,同時保留了原來的空洞卷積和ASSP層, 其骨干網絡使用了Xception模型,提高了語義分割的健壯性和運行速率,在 PASCAL VOC 2012 dataset取得新的state-of-art performance,89.0mIOU。
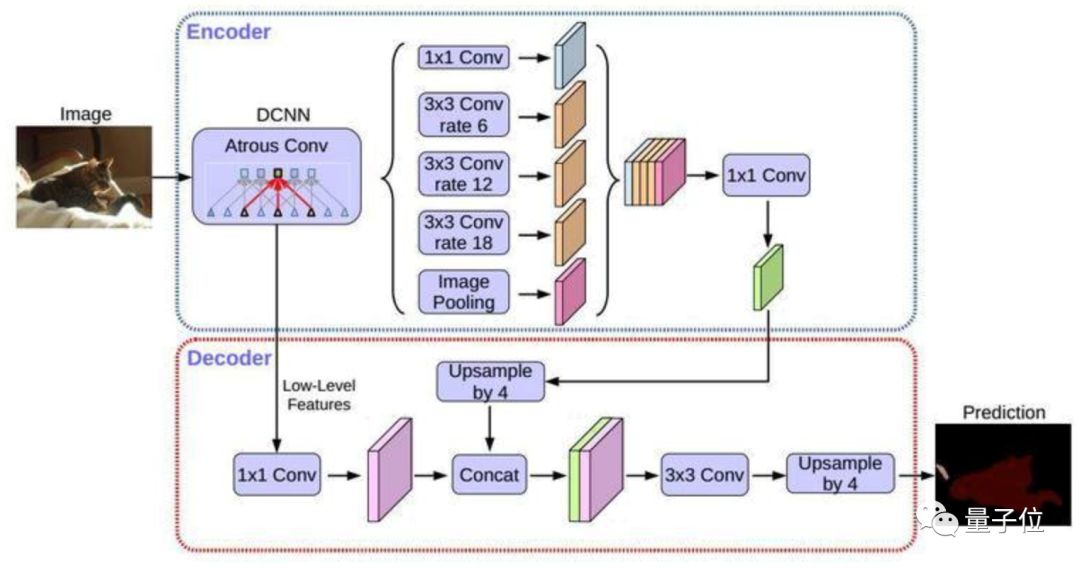
△DeepLab v3+ 基本結構
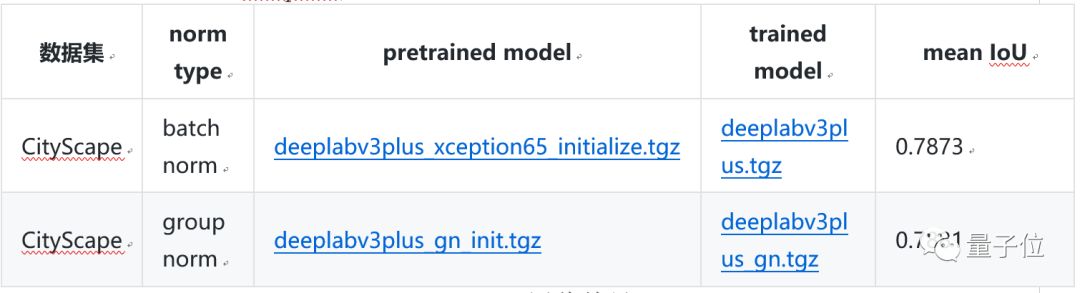
△DeepLab v3+ 評估結果
照例,GitHub傳送門在此(中文):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/deeplabv3%2B
?ICNet,Image Cascade Network,主要用于圖像實時語義分割,主要思想是將輸入圖像變換為不同的分辨率,然后用不同計算復雜度的子網絡計算不同分辨率的輸入,然后將結果合并。ICNet由三個子網絡組成,計算復雜度高的網絡處理低分辨率輸入,計算復雜度低的網絡處理分辨率高的網絡,通過這種方式在高分辨率圖像的準確性和低復雜度網絡的效率之間獲得平衡。
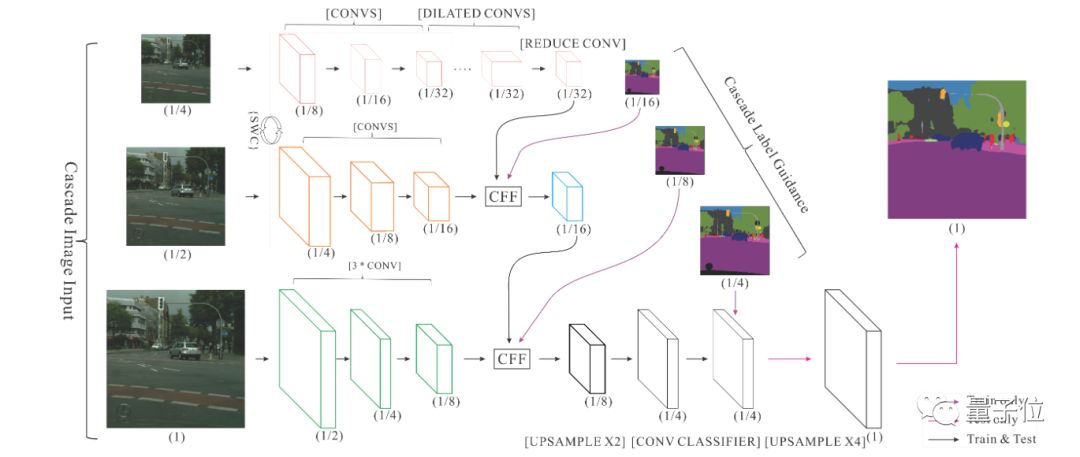
△ICNet網絡結構
△ICNet可視化

△ICNet評估結果
進一步上手實踐的傳送門在此(也是中文):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/icnet
四、場景文字識別
許多場景圖像中包含著豐富的文本信息,對理解圖像信息有著重要作用,能夠極大地幫助人們認知和理解場景圖像的內容。場景文字識別是在圖像背景復雜、分辨率低下、字體多樣、分布隨意等情況下,將圖像信息轉化為文字序列的過程,可認為是一種特別的翻譯過程:將圖像輸入翻譯為自然語言輸出。場景圖像文字識別技術的發展也促進了一些新型應用的產生,如通過自動識別路牌中的文字幫助街景應用獲取更加準確的地址信息等。
在場景文字識別任務中,我們介紹如何將基于CNN的圖像特征提取和基于RNN的序列翻譯技術結合,免除人工定義特征,避免字符分割,使用自動學習到的圖像特征,完成字符識別。這里主要介紹CRNN-CTC模型和基于注意力機制的序列到序列模型。
?CRNN-CTC模型,采取CNN+RNN+CTC架構,卷積層使用CNN,從輸入圖像中提取特征序列、循環層使用RNN,預測從卷積層獲取的特征序列的標簽(真實值)分布、轉錄層使用CTC,把從循環層獲取的標簽分布通過去重整合等操作轉換成最終的識別結果。
?基于注意力機制的序列到序列模型,提出了基于attention機制的文本識別方法,不需要檢測,直接輸入圖片進行識別,對于識別字符類別數很少的場景很實用,例如車牌識別、自然場景圖片的主要關鍵詞提取等。同時也不要求識別文本必須單行排列,雙行排列,多行排列都可以。在訓練過程中則不需要文本框的標注,訓練數據的收集變得很方便。
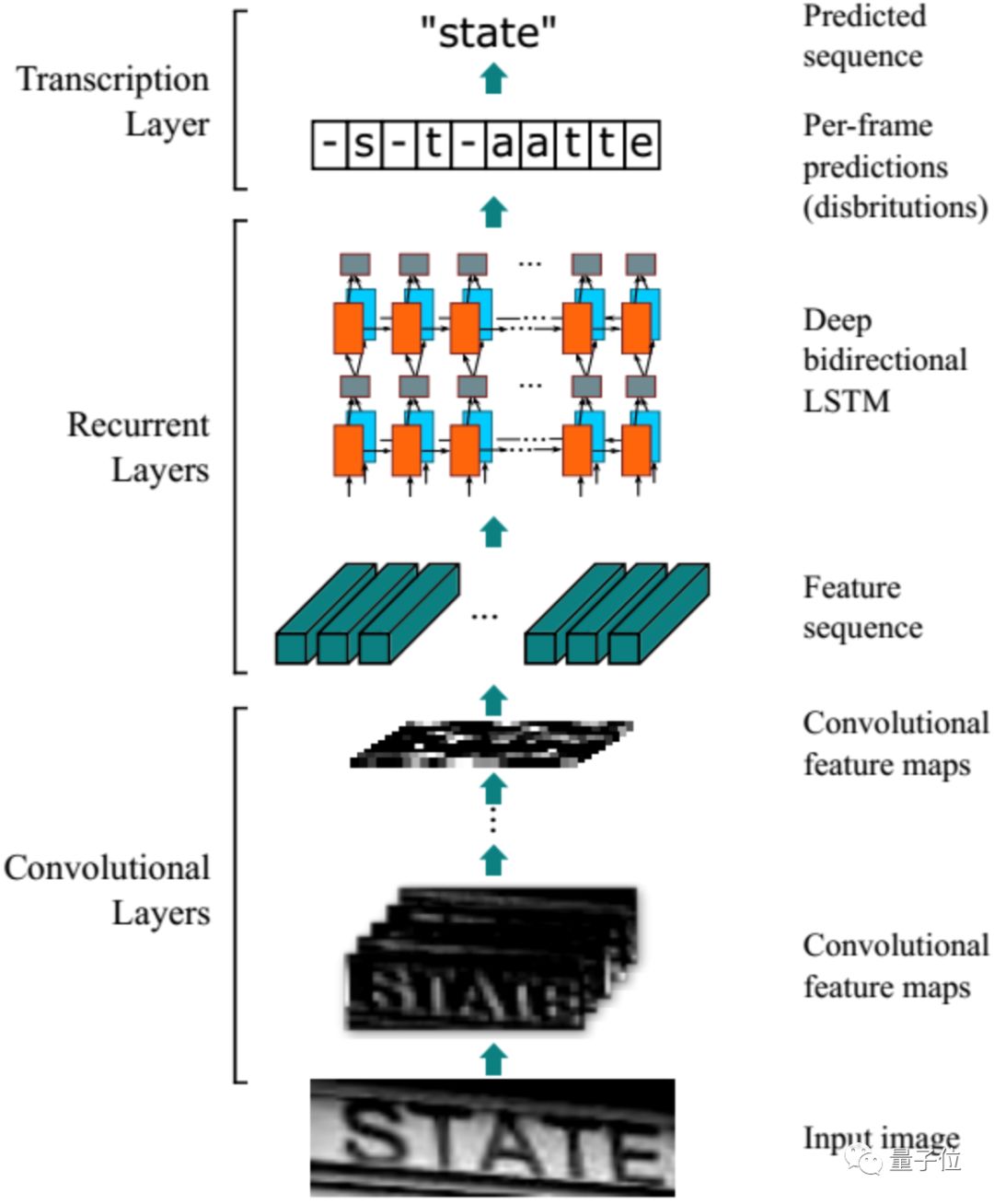
△CRNN-CTC模型結構
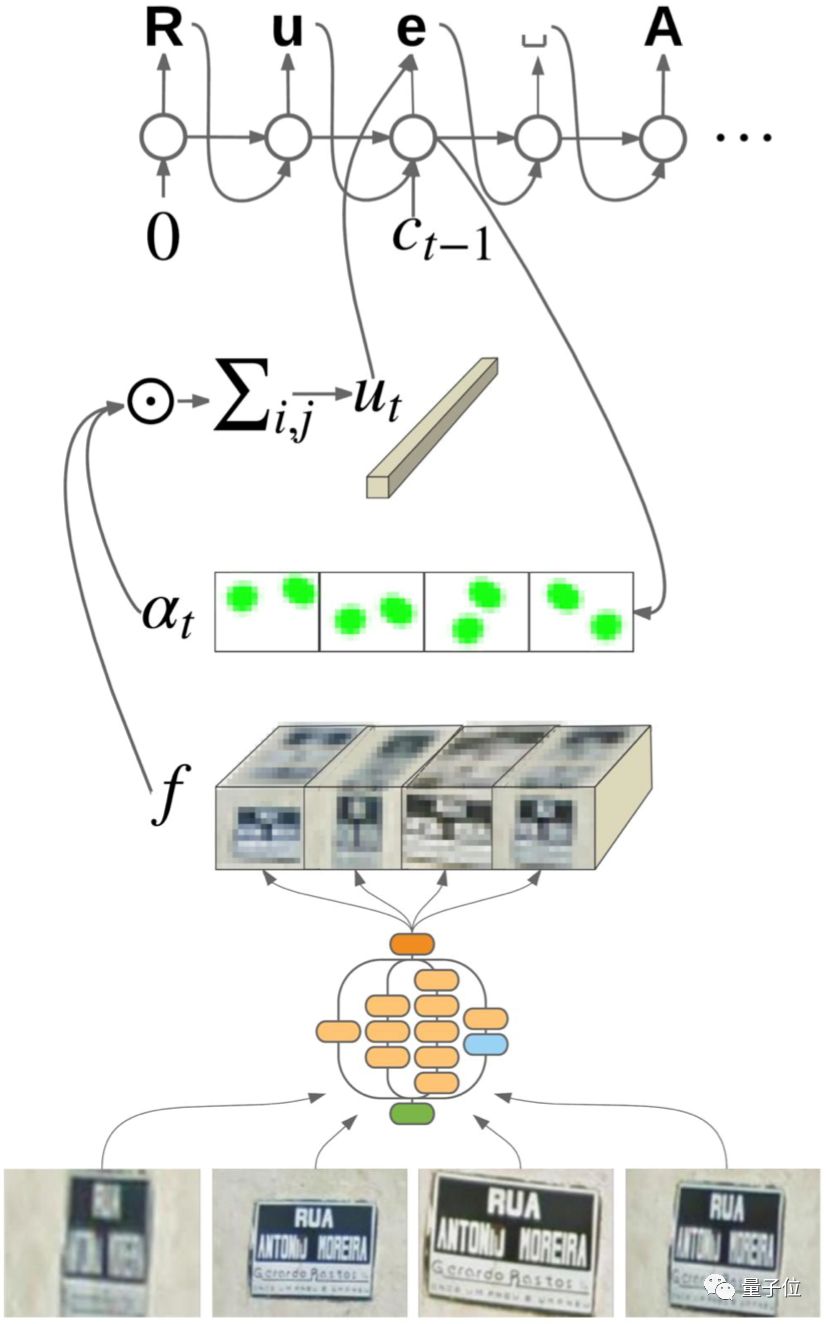
△基于注意力機制的序列到序列模型結構
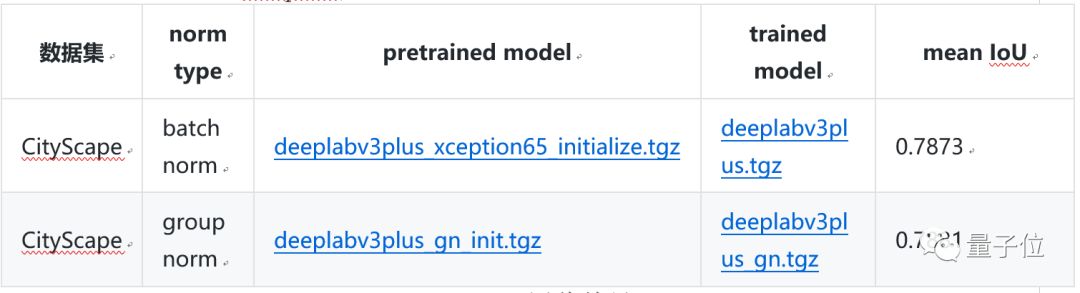
△OCR模型評估結果
GitHub傳送門在此(中文友好):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/ocr_recognition
下篇
上篇中我們介紹了計算機視覺技術在圖像分類、目標檢測、圖像語義分割、場景文字識別四大基本任務場景下,如何幫助計算機從單個或者一系列的圖片中提取分析和理解的關鍵信息。當下,視頻在人們生活中越來越重要,伴隨著技術成熟度的提高,計算機視覺技術的突破也從靜態圖像識別的“看到”轉向了視頻理解的“看懂”。
接下來,我們一起探索基于PaddlePaddle的圖像生成、人體關鍵點檢測、視頻分類相關的深度學習模型。
一、圖像生成
圖像生成是指根據輸入向量,生成目標圖像。這里的輸入向量可以是隨機的噪聲或用戶指定的條件向量。具體的應用場景有:手寫體生成、人臉合成、風格遷移、圖像修復、超分重建等。當前的圖像生成任務主要是借助生成對抗網絡(GAN)來實現。
生成對抗網絡(GAN)由兩種子網絡組成:生成器和識別器。生成器的輸入是隨機噪聲或條件向量,輸出是目標圖像。識別器是一個分類器,輸入是一張圖像,輸出是該圖像是否是真實的圖像。在訓練過程中,生成器和識別器通過不斷的相互博弈提升自己的能力。
在圖像生成任務中,我們主要介紹如何使用DCGAN和ConditioanlGAN來進行手寫數字的生成,另外還介紹了用于風格遷移的CycleGAN。
?ConditioanlGAN,顧名思義是帶條件約束的生成對抗模型,它在生成模型和判別模型的建模中均引入了額外的條件變量,對于生成器對數據的生成具有指導作用。ConditioanlGAN是把無監督的GAN變成有監督模型的改進,為后續的工作提供了指導作用。
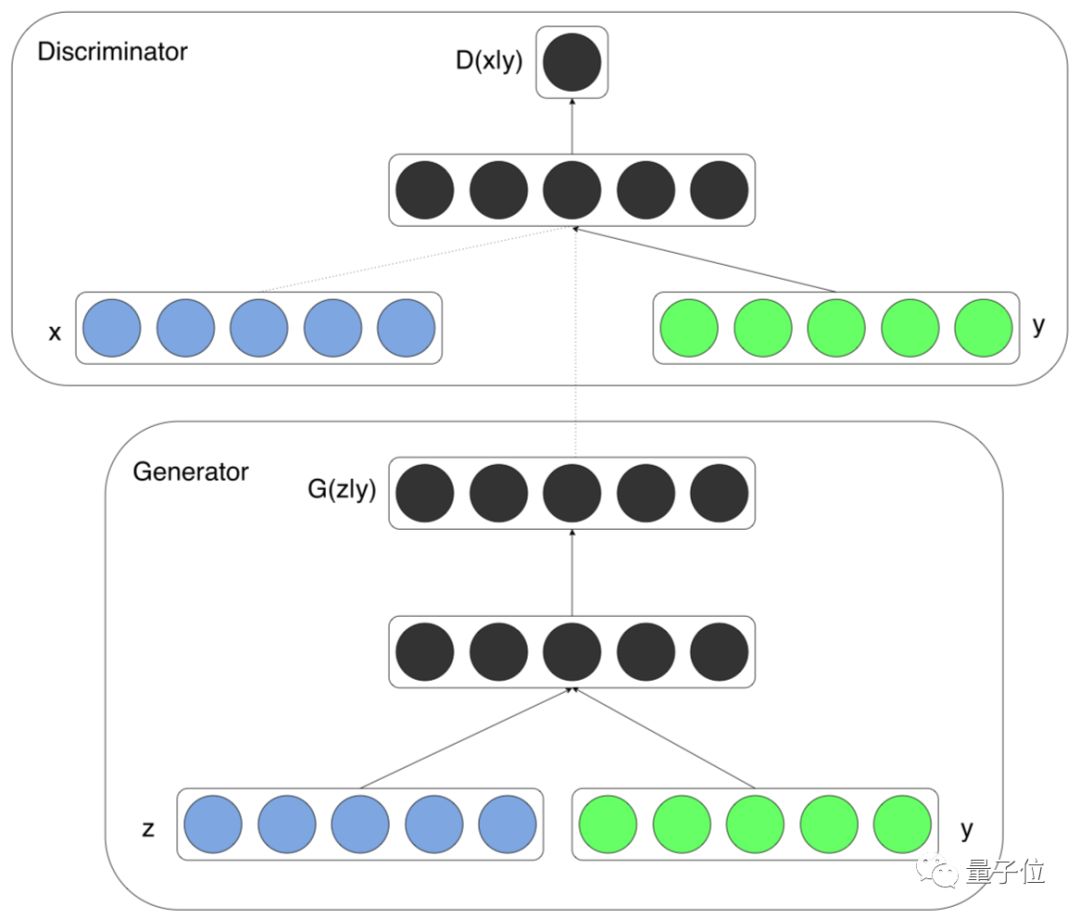
△ConditioanlGAN結構
△ConditioanlGAN預測效果圖
傳送門(中文):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/c_gan
?DCGAN,為了填補CNN在監督學習和無監督學習之間的gap,此篇論文提出了將CNN和GAN結合的DCGAN(深度卷積生成對抗網絡),并且DCGAN在無監督學習中取得不錯的結果。
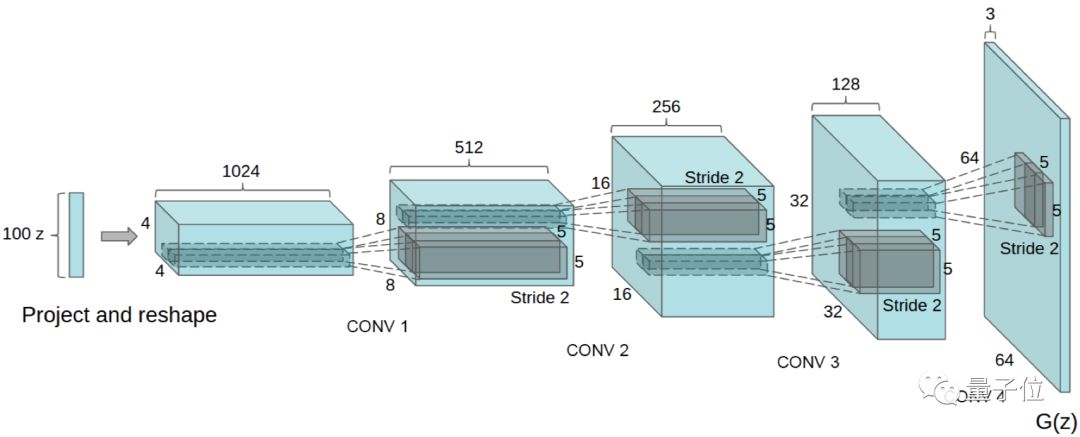
△DCGAN結構
△DCGAN預測效果圖
傳送門(中文):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/c_gan
?CycleGAN,將一類圖片轉換成另一類圖片。傳統的 GAN 是單向生成,CycleGAN 是互相生成,本質上是兩個鏡像對稱的GAN,構成了一個環形網絡,所以命名為 Cycle。風格遷移類任務一般都需要兩個域中具有相同內容的成對圖片作為訓練數據,CycleGAN的創新點就在于其能夠在沒有成對訓練數據的情況下,將圖片內容從源域遷移到目標域。
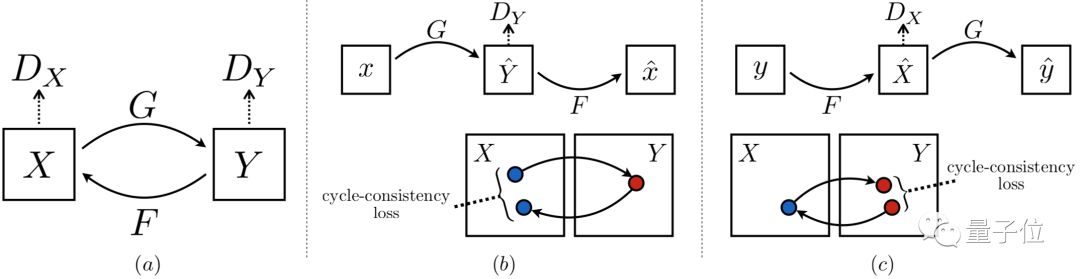
△CycleGAN 結構

△CycleGAN預測可視化
傳送門(中文):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/cycle_gan
二、人體關鍵點檢測
人體關鍵點檢測,通過人體關鍵節點的組合和追蹤來識別人的運動和行為,對于描述人體姿態,預測人體行為至關重要,是諸多計算機視覺任務的基礎,例如動作分類,異常行為檢測,以及自動駕駛等等,也為游戲、視頻等提供新的交互方式。
在人體關鍵點檢測任務中,我們主要介紹網絡結構簡單的coco2018關鍵點檢測項目的亞軍方案。
?Simple Baselines for Human Pose Estimation in Fluid,coco2018關鍵點檢測項目的亞軍方案,沒有華麗的技巧,僅僅是在ResNet中插入了幾層反卷積,將低分辨率的特征圖擴張為原圖大小,以此生成預測關鍵點需要的Heatmap。沒有任何的特征融合,網絡結構非常簡單,但是達到了state of the art效果。
△視頻Demo: Bruno Mars - That’s What I Like [官方視頻]

△Simple Baselines for Human Pose Estimation in Fluid 評估結果
GitHub傳送門:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/human_pose_estimation
三、視頻分類
視頻分類是視頻理解任務的基礎,與圖像分類不同的是,分類的對象不再是靜止的圖像,而是一個由多幀圖像構成的、包含語音數據、包含運動信息等的視頻對象,因此理解視頻需要獲得更多的上下文信息,不僅要理解每幀圖像是什么、包含什么,還需要結合不同幀,知道上下文的關聯信息。
視頻分類方法主要包含基于卷積神經網絡、基于循環神經網絡、或將這兩者結合的方法。
在視頻分類任務中,我們主要介紹視頻分類方向的多個主流領先模型,其中Attention LSTM,Attention Cluster和NeXtVLAD是比較流行的特征序列模型,TSN和StNet是兩個End-to-End的視頻分類模型。
Attention LSTM模型速度快精度高,NeXtVLAD是2nd-Youtube-8M比賽中最好的單模型, TSN是基于2D-CNN的經典解決方案。Attention Cluster和StNet是百度自研模型,分別發表于CVPR2018和AAAI2019,是Kinetics600比賽第一名中使用到的模型。
?Attention Cluster模型為ActivityNet Kinetics Challenge 2017中最佳序列模型,通過帶Shifting Opeation的Attention Clusters處理已抽取好的RGB、Flow、Audio數據。
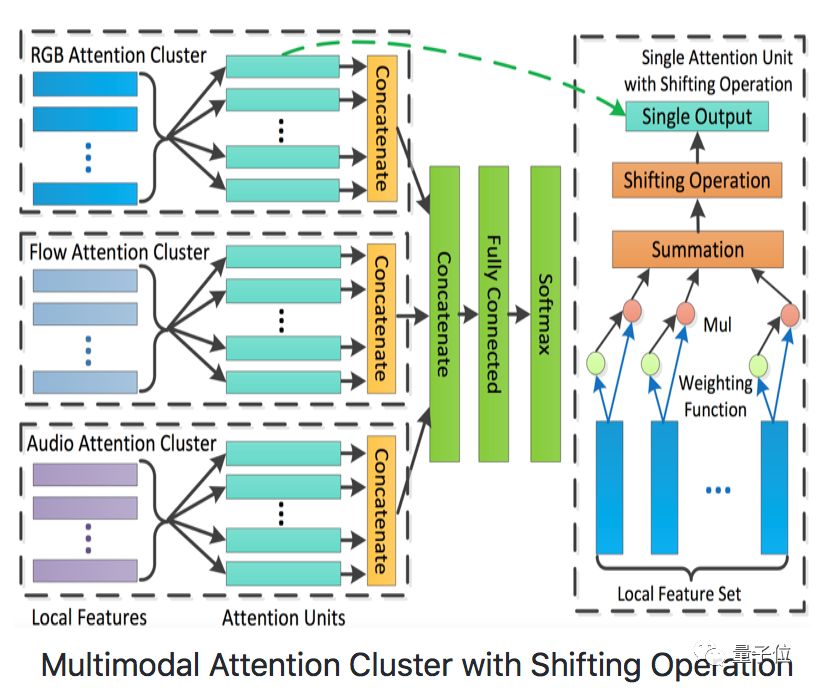
△Attention Cluster模型結構
Attention LSTM 模型,采用了雙向長短記憶網絡(LSTM),將視頻的所有幀特征依次編碼。與傳統方法直接采用LSTM最后一個時刻的輸出不同,該模型增加了一個Attention層,每個時刻的隱狀態輸出都有一個自適應權重,然后線性加權得到最終特征向量。
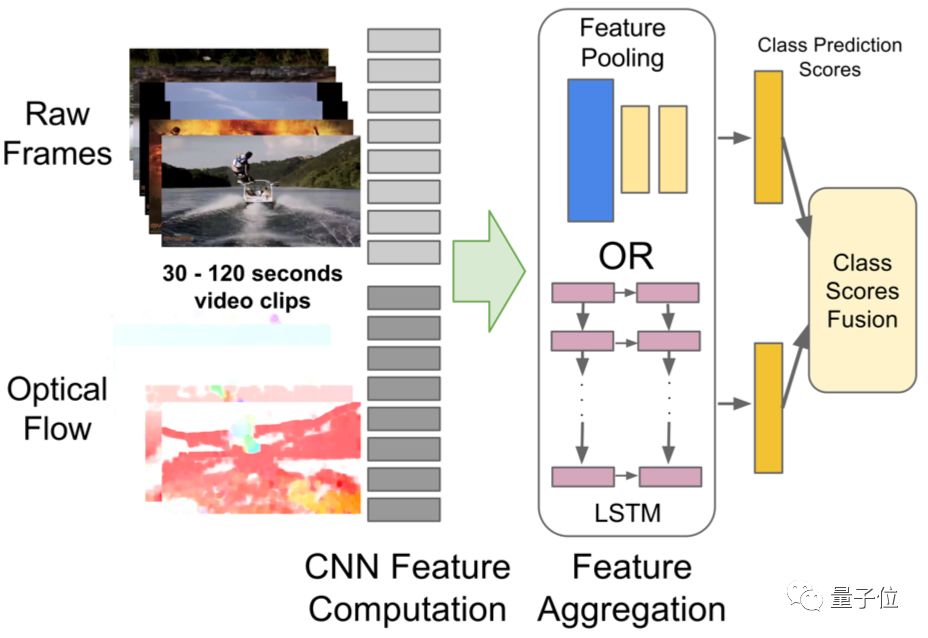
△Attention LSTM 模型結構
?NeXtVLAD模型,第二屆Youtube-8M視頻理解競賽中效果最好的單模型,提供了一種將楨級別的視頻特征轉化并壓縮成特征向量,以適用于大尺寸視頻文件的分類的方法。其基本出發點是在NetVLAD模型的基礎上,將高維度的特征先進行分組,通過引入attention機制聚合提取時間維度的信息,這樣既可以獲得較高的準確率,又可以使用更少的參數量。
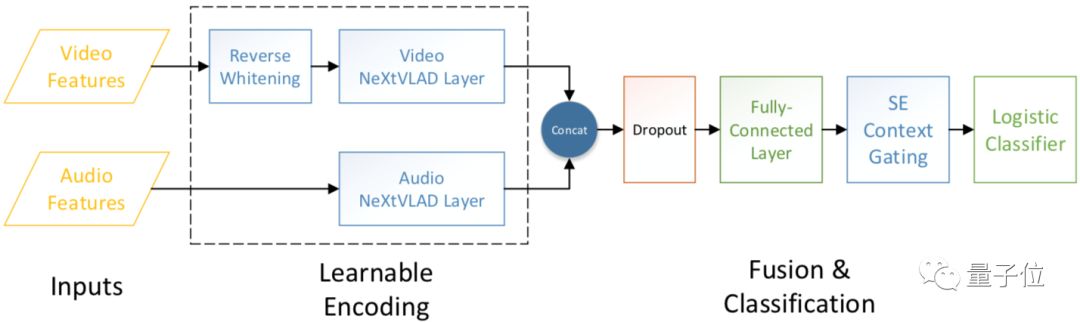
△NeXtVLAD模型結構
?StNet模型,框架為ActivityNet Kinetics Challenge 2018中奪冠的基礎網絡框架,提出“super-image”的概念,在super-image上進行2D卷積,建模視頻中局部時空相關性。另外通過temporal modeling block建模視頻的全局時空依賴,最后用一個temporal Xception block對抽取的特征序列進行長時序建模。
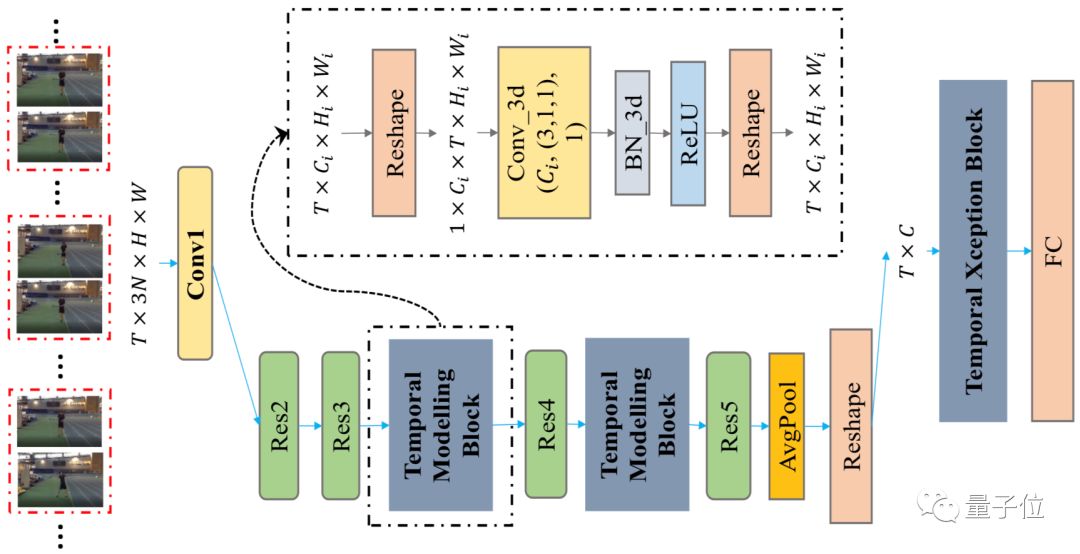
△StNet模型結構
?Temporal Segment Network (TSN),視頻分類領域經典的基于2D-CNN的解決方案,主要解決視頻的長時間行為判斷問題,通過稀疏采樣視頻幀的方式代替稠密采樣,既能捕獲視頻全局信息,也能去除冗余,降低計算量。最終將每幀特征平均融合后得到視頻的整體特征,并用于分類。
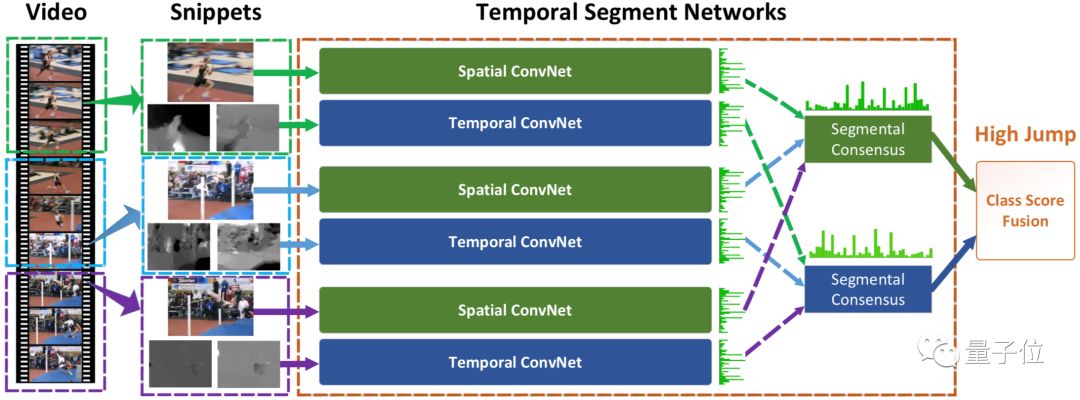
△TSN模型結構

△基于Youtube-8M數據集的視頻分類模型 評估結果

△基于Kinetics數據集的視頻分類模型 評估結果
這部分的詳情,可以移步GitHub,全程中文。傳送門:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/video
四、度量學習
度量學習也稱作距離度量學習、相似度學習,通過學習對象之間的距離,度量學習能夠用于分析對象時間的關聯、比較關系,在實際問題中應用較為廣泛,可應用于輔助分類、聚類問題,也廣泛用于圖像檢索、人臉識別等領域。
以往,針對不同的任務,需要選擇合適的特征并手動構建距離函數,而度量學習可根據不同的任務來自主學習出針對特定任務的度量距離函數。度量學習和深度學習的結合,在人臉識別/驗證、行人再識別(human Re-ID)、圖像檢索等領域均取得較好的性能,在這個任務中我們主要介紹基于Fluid的深度度量學習模型,包含了三元組、四元組等損失函數。
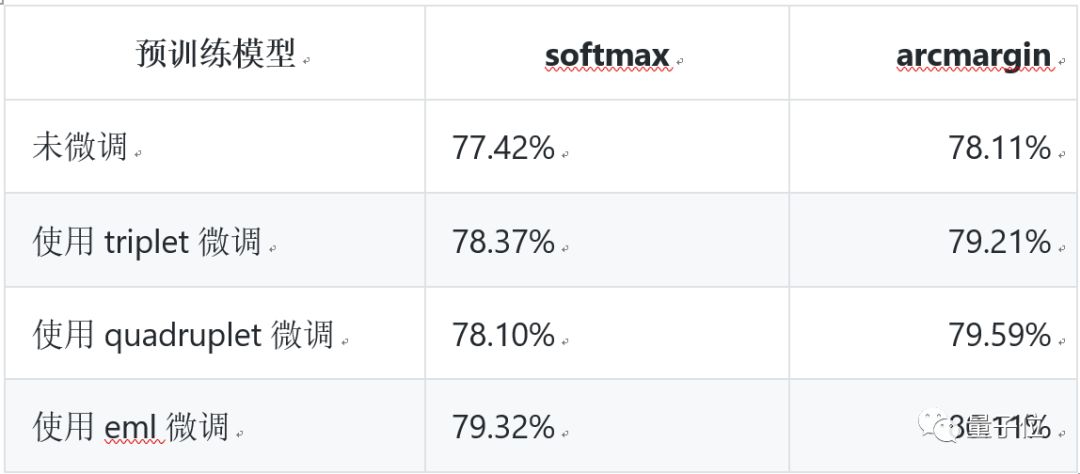
△度量學習模型 評估結果
GitHub的頁面上有安裝、準備、訓練等方面的指導,傳送門:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/metric_learning
-
機器視覺
+關注
關注
162文章
4405瀏覽量
120698 -
圖像分類
+關注
關注
0文章
93瀏覽量
11956 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46121
原文標題:計算機視覺八大任務全概述:PaddlePaddle工程師詳解熱門視覺模型
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
最適合 AI 應用的計算機視覺類型是什么?
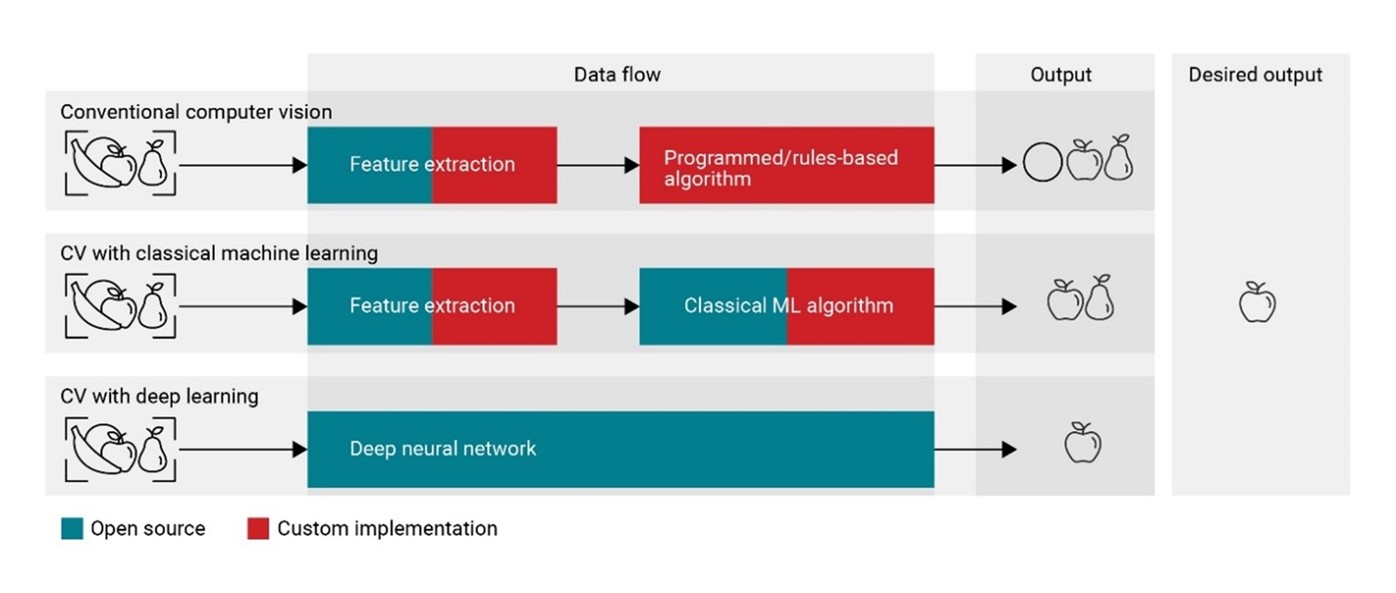
機器視覺與計算機視覺的關系簡述
自動駕駛系統要完成哪些計算機視覺任務?
對電力系統計算機應用存在問題及解決方法進行了探討
深度學習與傳統計算機視覺簡介
DNA計算機的研究現狀
簡單闡述一下計算機視覺的幾大任務!

最適合AI應用的計算機視覺類型是什么?
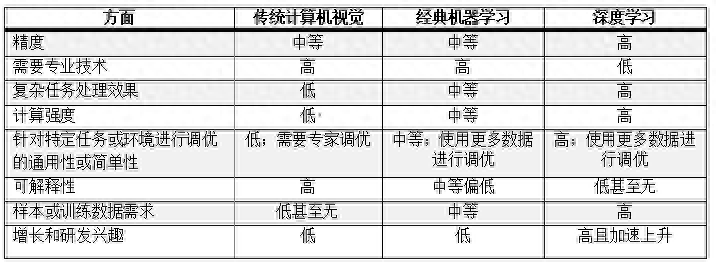
計算機視覺的十大算法






 工商網監
工商網監
評論