 最新加速深度強化學習:谷歌創造
最新加速深度強化學習:谷歌創造
深度強化學習技術可以通過視覺輸入來為復雜任務學習有效策略,這種方法在最近的研究中已經被成功應用經典的雅達利2600系列游戲。最新的研究表明,即使在像Montezuma’s Revenge這樣復雜的游戲中基于深度強化學習依然可以達到超越人類的表現。然而深度強化學習最大的限制在于要達到高水平的效果,需要與環境進行非常多次的交互,遠遠超過了人類學習游戲時與環境交互的次數。這也許是由于人類在游戲時可以有效預測其行為可以長生的結果,有效提升了學習的效率。可以通過行為序列和對應的結果來進行游戲建模。通過為游戲建模并學習選擇行為的策略,是基于模型強化學習(model-based reinforcement learning (MBRL))的主要假設。在先前研究的基礎上,谷歌研究人員在新論文中提出了模擬策略學習算法(Simulated Policy Learning (SimPLe) algorithm),這是一套大幅度提高雅達利游戲主體訓練效率的MBRL框架,在僅僅100k次的交互訓練后就可以達到較好的效果。100k次交互大概等效于人類兩個小時的游戲時間。這一算法通過觀測、建模、模擬學習的方式很好的處理了深度強化學習過程中的效率問題。
學習SimPle環境模型
從宏觀上來看,SimPle主要分為兩個交替進行的學習過程,一個是學習游戲行為并建立環境模型的過程,另一個是在模擬游戲環境中利用這一模型優化策略的過程。學習的流程如下圖所示循環進行。
SimPle的主要流程,主體與環境交互并收集數據更新環境模型,隨后基于環境模型更新策略。
為了訓練一個有效的雅達利游戲模型,后向需要在像素空間生成對未來的預測,換句話說我們需要根據先前的觀察和動作行為預測游戲的下一幀。選擇像素空間來預測的主要原因在于圖像觀測中包含了豐富且稠密的監督信號。一旦完成未來幀預測模型的訓練,算法就可以利用這一信息為游戲主體生成軌跡來訓練好的策略,例如可以基于最大化長期回報來選擇行為。這意味著我們可以替代耗時和 消耗資源的真實游戲序列來訓練策略,直接使用基于環境模型生成的圖像序列來進行策略訓練。
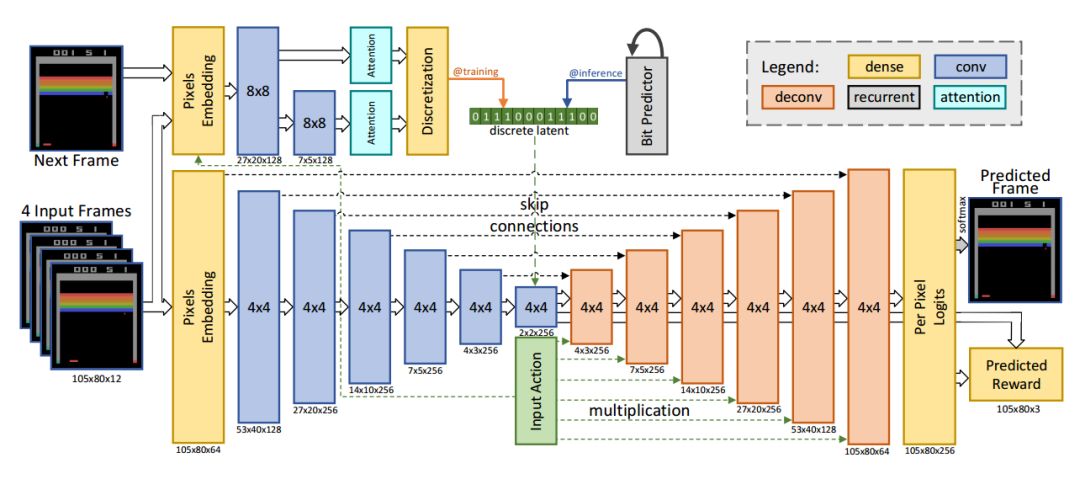
幀預測模型的架構圖
基于前饋卷積網絡研究人員利用4幀輸入預測出下一幀的輸出以及對應的反饋。輸入的像素和動作通過全連接層編碼,輸出則由逐像素的256色softmax構成。模型有兩個主要的部分,下半部分是基于編碼器的卷積,解碼器的每一層與輸入動作都進行了連接。另一部分是推理網絡,在訓練的時候從近似后驗中約化采樣的隱空間編碼被離散成比特,為了保持模型可差分bp繞過了離散部分。在推理時利用網絡自回歸預測隱空間比特。

kufu在功夫大師游戲中,系統錯誤預測了對手的數量。其中左側是預測輸出、中間是基準右邊是逐像素的差別。
這一模型雖然表現良好,但在某些特殊情況下依然會輸出錯誤的結果。例如在Pong游戲中,但球落到幀以外的時候系統就不能有效預測后續幀的結果。在先前工作的啟發下,研究人員利用新的視頻模型架構來解決這類隨機問題。在模型訓練后的每一個迭代中,研究人員利用Monique生成一系列包含動作、觀測和結果的序列,并利用PPO來改進策略。其關鍵在于每一個生成序列都是從真實數據集開始的。考慮到長程序列的時間復雜度和誤差,SimPLe僅僅使用中程序列來進行改進。但PPO算法可以從內部價值函數中學習到行為和結果間的長程作用,使得有限長度的序列在較為稀疏獎勵的游戲中也是足夠的。
高效的SimPLe
為了評測算法的效率,研究人員測評了主體在100k次環境交互后的輸出。研究人員在26個不同游戲中比較了Rainbow和PPO兩種流行的強化學習方法,在大多數情況下SimPLe算法都比其他算法塊兩倍以上。

20中不同游戲的測評,左側是Rainbow算法,右邊是PPO算法,展示了達到SimPLe100k訓練分數所需的交互次數。其中紅線是SimPLe的結果。
效果
SimPLe算法在Pong和Freeway中表現最精彩,在模擬環境中訓練的主體可以達到最高分。同時在Pong,Freeway和Breakout中幾乎可以無誤差預測未來50步的像素幀。
兩種游戲中完美的像素預測結果,最又側是預測的誤差圖,可以看到幾乎與真實情況相同。
但這一算法也在某些情況下無法正確預測,它難以捕捉畫面中很多微小但十分重要的物體,例如游戲中的子彈。同時也無法使用迅速變化的游戲畫面,比如gameover時候的閃爍畫面。
但總的來說,新方法有助于學習模擬器更好的理解周遭的環境并提供了更新更好更快的訓練方法來適應多任務強化學習。雖然目前與最優秀的無模型方法還有差距,但SimPLe具有很大的效率潛力,研究人員將在未來不斷深入改進。
如果你想詳細了解其中的算法流程,可以參看下面的鏈接:
Paper:https://arxiv.org/pdf/1903.00374.pdf
這一部分代碼已經集成到了tensor2tensor的強化學習代碼中:
Code:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/rl/README.md
研究人員還準備了代碼和Colab幫助好學的你復現實驗:
Colab:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t-rl.ipynb
ref:https://arxiv.org/abs/1509.06113http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.329.6065&rep=rep1&type=pdf
logo pic from:https://dribbble.com/shots/4166879-Controllers
-
谷歌
+關注
關注
27文章
6217瀏覽量
106976
原文標題:谷歌新方法加速深度強化學習的訓練過程
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
如何深度強化學習 人工智能和深度學習的進階
深度強化學習是否已經到達盡頭?
DeepMind發布強化學習庫RLax
模型化深度強化學習應用研究綜述

基于深度強化學習仿真集成的壓邊力控制模型
《自動化學報》—多Agent深度強化學習綜述







 工商網監
工商網監
評論