 GAN又開辟了新疆界,MirrorGAN有多強?
GAN又開辟了新疆界,MirrorGAN有多強?
浙大、悉尼大學等高校研究員提出MirrorGAN,作為全局-局部注意和語義保持的文本-圖像-文本框架,解決文本描述和視覺內容之間的語義一致性問題,并在COCO數據集上刷新了記錄。
GAN又開辟了新疆界。
去年英偉達的StyleGAN在生成高質量和視覺逼真的圖像,騙過了無數雙眼睛,隨后一大批假臉、假貓、假房源隨之興起,可見GAN的威力。
StyleGAN生成假臉
雖然GAN在圖像方面已經取得了重大進展,但是保證文本描述和視覺內容之間的語義一致性上仍然是非常具有挑戰性的。
最近,來自浙江大學、悉尼大學等高校的研究人員,提出一種新穎的全局-局部注意和語義保持的文本-圖像-文本(text-to-image-to-text)框架來解決這個問題,這種框架稱為MirrorGAN。

MirrorGAN有多強?
在目前較為主流的數據集COCO數據集和CUB鳥類數據集上,MirrorGAN都取得了最好成績。
目前,論文已被CVPR2019接收。
MirrorGAN:解決文本和視覺之間語義一致性
文本生成圖像(T2I)在許多應用領域具有巨大的潛力,已經成為自然語言處理和計算機視覺領域的一個活躍的研究領域。
與基本圖像生成問題相反,T2I生成以文本描述為條件,而不是僅從噪聲開始。利用GAN的強大功能,業界已經提出了不同的T2I方法來生成視覺上逼真的和文本相關的圖像。這些方法都利用鑒別器來區分生成的圖像和相應的文本對以及ground-truth圖像和相應的文本對。
然而,由于文本和圖像之間的區域差異,當僅依賴于這樣的鑒別器時,對每對內的基礎語義一致性進行建模是困難且低效的。
近年來,針對這一問題,人們利用注意機制來引導生成器在生成不同的圖像區域時關注不同的單詞。然而,由于文本和圖像模式的多樣性,僅使用單詞級的注意并不能確保全局語義的一致性。如圖1(b)所示:
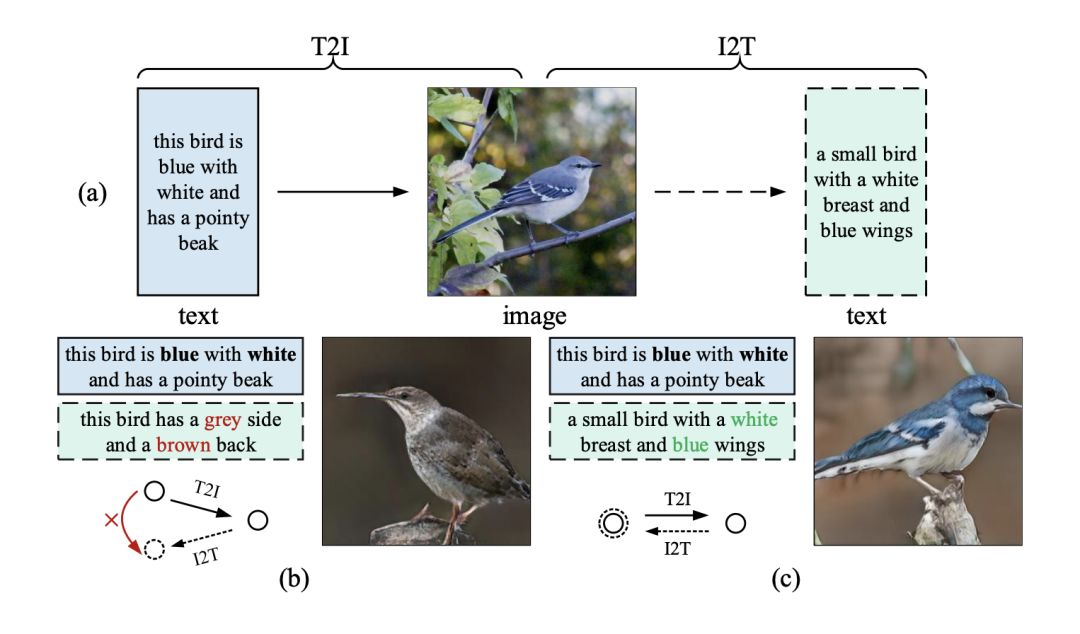
圖1 (a)鏡像結構的說明,體現了通過重新描述學習文本到圖像生成的思想;(b)-(c)前人的研究成果與本文提出的MirrorGAN分別生成的語義不一致和一致的圖像/重新描述。
T2I生成可以看作是圖像標題(或圖像到文本生成,I2T)的逆問題,它生成給定圖像的文本描述。考慮到處理每個任務都需要對這兩個領域的底層語義進行建模和對齊,因此在統一的框架中對這兩個任務進行建模以利用底層的雙重規則是自然和合理的。
如圖1 (a)和(c)所示,如果T2I生成的圖像在語義上與給定的文本描述一致,則I2T對其重新描述應該與給定的文本描述具有完全相同的語義。換句話說,生成的圖像應該像一面鏡子,準確地反映底層文本語義。
基于這一觀察結果,論文提出了一個新的文本-圖像-文本的框架——MirrorGAN來改進T2I生成,它利用了通過重新描述學習T2I生成的思想。
解剖MirrorGAN三大核心模塊
對于T2I這一任務來說,主要的目標有兩個:
視覺真實性;
語義
且二者需要保持一致性。
MirrorGAN利用了“文本到圖像的重新描述學習生成”的思想,主要由三個模塊組成:
語義文本嵌入模塊(STEM);
級聯圖像生成的全局-局部協同關注模塊(GLAM);
語義文本再生與對齊模塊(STREAM)。
STEM生成單詞級和句子級的嵌入;GLAM有一個級聯的架構,用于從粗尺度到細尺度生成目標圖像,利用局部詞注意和全局句子注意,逐步增強生成圖像的多樣性和語義一致性;STREAM試圖從生成的圖像中重新生成文本描述,該圖像在語義上與給定的文本描述保持一致。
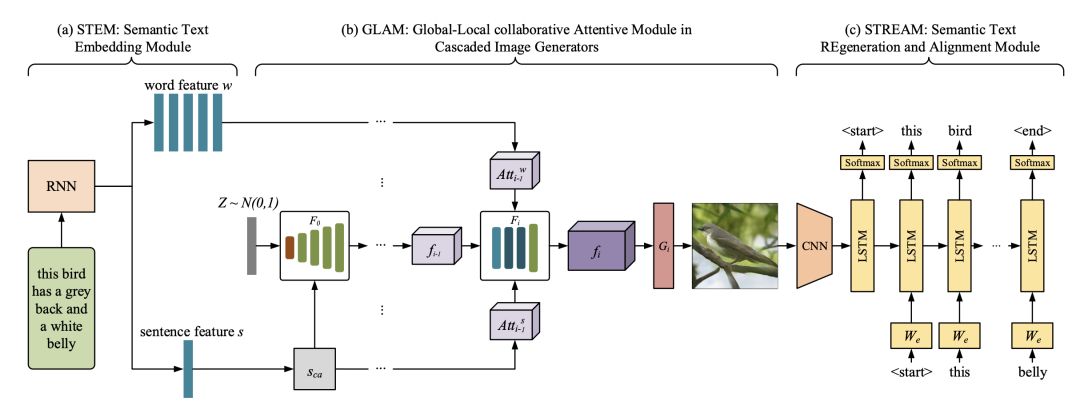
圖2 MirrorGAN原理圖
如圖2所示,MirrorGAN通過集成T2I和I2T來體現鏡像結構。
它利用了通過重新描述來學習T2I生成的想法。 生成圖像后,MirrorGAN會重新生成其描述,該描述將其基礎語義與給定的文本描述對齊。
以下是MirrorGAN三個模塊組成:STEM,GLAM和STREAM。
STEM:語義文本嵌入模塊
首先,引入語義文本嵌入模塊,將給定的文本描述嵌入到局部詞級特征和全局句級特征中。
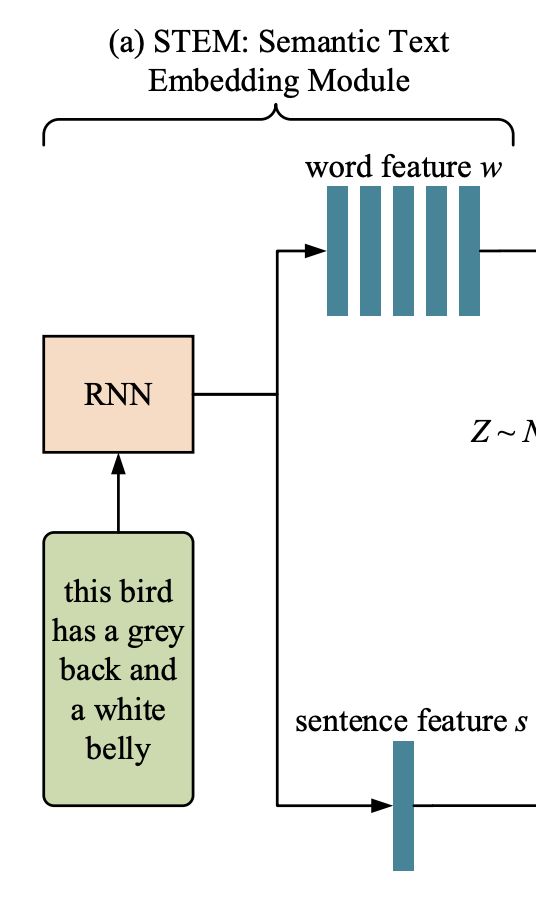
如圖2最左邊所示(即上圖),使用一個遞歸神經網絡(RNN)從給定的文本描述中提取語義嵌入T,包括一個嵌入w的單詞和一個嵌入s的句子。
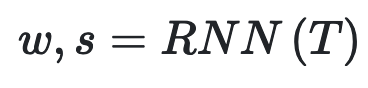
GLAM:級聯圖像生成的全局-局部協同關注模塊
接下來,通過連續疊加三個圖像生成網絡,構造了一個多級級聯發生器。
本文采用了《Attngan: Fine-grained text to image generation with attentional generative adversarial networks》中描述的基本結構,因為它在生成逼真的圖像方面有很好的性能。
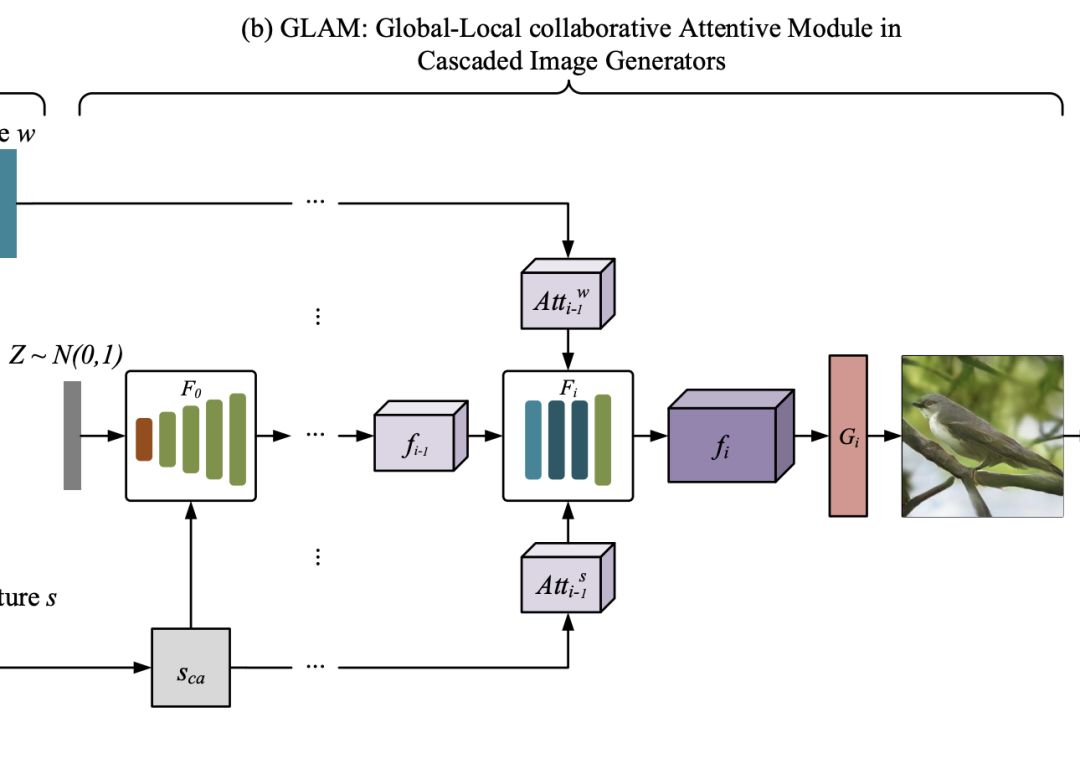
使用{F0,F1,…,Fm-1}來表示m個視覺特征變換器,并使用{G0,G1,…,Gm-1}來表示m個圖像生成器。 每個階段中的視覺特征Fi和生成的圖像Ii可以表示為:
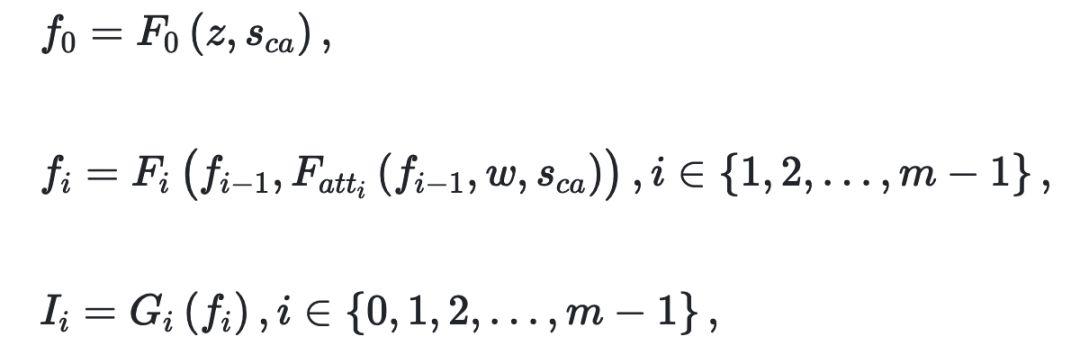
STREAM:語義文本再生與對齊模塊
如上所述,MirrorGAN包括語義文本再生和對齊模塊(STREAM),以從生成的圖像重新生成文本描述,其在語義上與給定的文本描述對齊。
具體來說,采用了廣泛使用的基于編碼器解碼器的圖像標題框架作為基本的STREAM架構。
圖像編碼器是在ImageNet上預先訓練的卷積神經網絡(CNN),解碼器是RNN。由末級生成器生成的圖像Im-1輸入CNN編碼器和RNN解碼器如下:
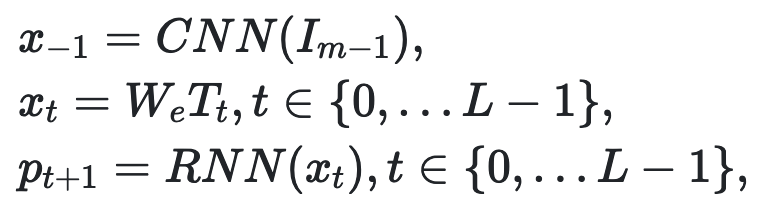
實驗結果:COCO數據集上成績最佳
那么,MirrorGAN的性能有多強呢?
首先來看一下MirrorGAN與其它最先進的T2I方法的比較,包括GAN-INT-CLS、GAWWN、StackGAN、StackGAN ++ 、PPGN和AttnGAN。
所采用的數據集是目前較為主流的數據集,分別是COCO數據集和CUB鳥類數據集:
CUB鳥類數據集包含8,855個訓練圖像和2,933個屬于200個類別的測試圖像,每個鳥類圖像有10個文本描述;
OCO數據集包含82,783個訓練圖像和40,504個驗證圖像,每個圖像有5個文本描述。
結果如表1所示:
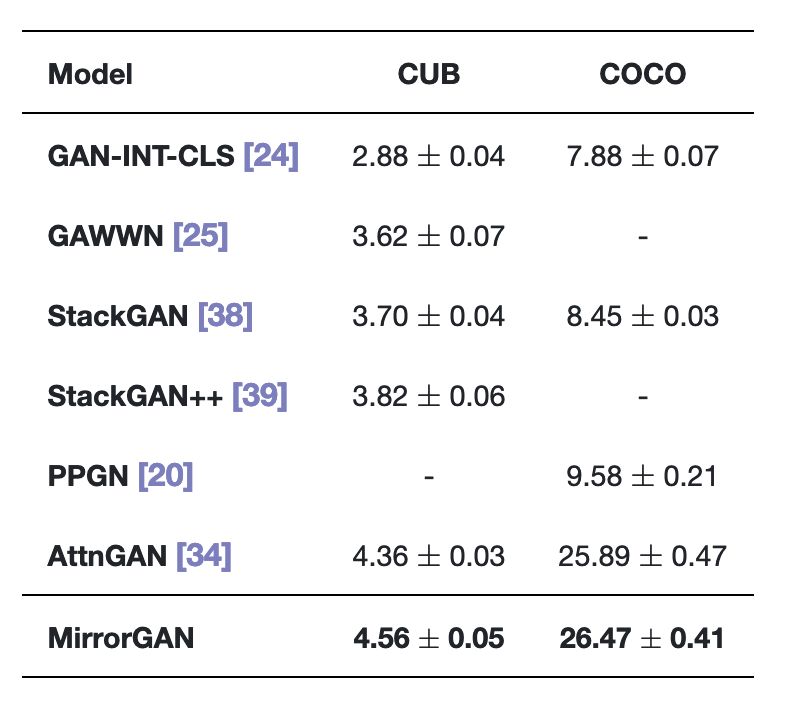
表1 在CUB和COCO數據集上,MirrorGAN和其它先進方法的結果比較
表2展示了AttnGAN和MirrorGAN在CUB和COCO數據集上的R精度得分。
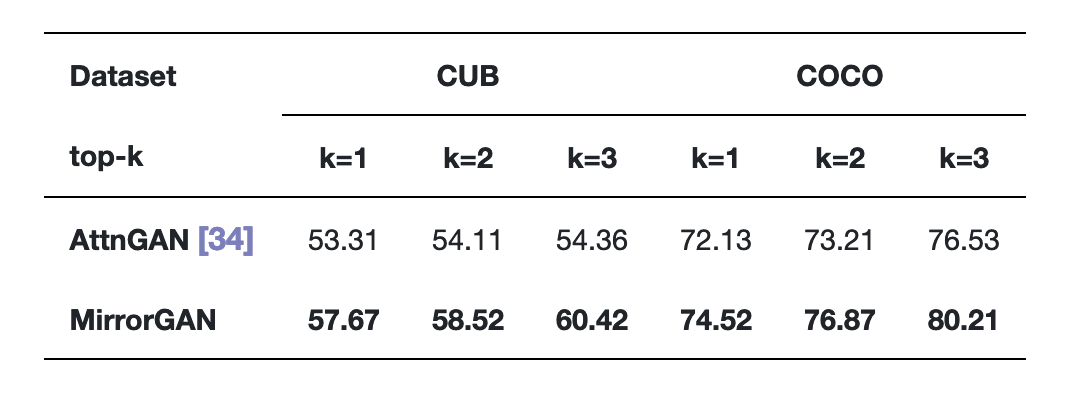
表2 在CUB和COCO數據集上,MirrorGAN和AttnGAN的R精度得分。
在所有實驗比較中,MirrorGAN都表現出了更大的優勢,這表明了本文提出的文本到圖像到文本的框架和全局到本地的協作關注模塊的優越性,因為MirrorGAN生成的高質量圖像具有與輸入文本描述一致的語義。
-
GaN
+關注
關注
19文章
1947瀏覽量
73696 -
鑒別器
+關注
關注
0文章
8瀏覽量
8772 -
數據集
+關注
關注
4文章
1208瀏覽量
24739
原文標題:MirrorGAN出世!浙大等提出文本-圖像新框架,刷新COCO紀錄
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
小劉老師,我是新疆的學生,但是看你好多資料都是網盤下載新疆無法用網盤下載啊
小劉老師,我是新疆的學生,但是看你好多資料都是網盤下載新疆無法用網盤下載啊?還有其他的辦法么?
TI助力GaN技術的推廣應用
51單片機如何開辟棧空間?
基于GaN的開關器件
新疆紅棗質量認證+區塊鏈溯源解決方案
DMA開辟緩存怎么使用動態內存?
新疆為什么禁飛無人機_新疆無人機禁飛區域
新疆聯通攜手國網新疆電力成功在電力鐵塔上部署了5G基站
GaN 為電源應用開辟了新領域





 工商網監
工商網監
評論