") 通過實(shí)戰(zhàn)針對(duì)機(jī)器學(xué)習(xí)之特征工程進(jìn)行處理
通過實(shí)戰(zhàn)針對(duì)機(jī)器學(xué)習(xí)之特征工程進(jìn)行處理
前言
上次對(duì)租金預(yù)測(cè)比賽進(jìn)行的是數(shù)據(jù)分析部分的處理機(jī)器學(xué)習(xí)實(shí)戰(zhàn)--住房月租金預(yù)測(cè)(1),今天繼續(xù)分享這次比賽的收獲。本文會(huì)講解對(duì)特征工程的處理。話不多說,我們開始吧!
特征工程

“數(shù)據(jù)決定了機(jī)器學(xué)習(xí)的上限,而算法只是盡可能逼近這個(gè)上限”,這里的數(shù)據(jù)指的就是經(jīng)過特征工程得到的數(shù)據(jù)。特征工程指的是把原始數(shù)據(jù)轉(zhuǎn)變?yōu)槟P偷挠?xùn)練數(shù)據(jù)的過程,它的目的就是獲取更好的訓(xùn)練數(shù)據(jù)特征,使得機(jī)器學(xué)習(xí)模型逼近這個(gè)上限。特征工程能使得模型的性能得到提升,有時(shí)甚至在簡(jiǎn)單的模型上也能取得不錯(cuò)的效果。特征工程在機(jī)器學(xué)習(xí)中占有非常重要的作用,上面的思維導(dǎo)圖包含了針對(duì)特征工程處理的所有方法。
缺失值處理
1print(all_data.isnull().sum())
使用上面的語(yǔ)句可以查看數(shù)據(jù)集中的缺失值
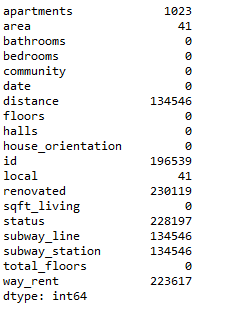
從上面的圖中可以清楚的看到各數(shù)據(jù)的缺失值。
對(duì)于缺失值是任何一個(gè)數(shù)據(jù)集都不可避免的,在數(shù)據(jù)統(tǒng)計(jì)過程中可能是無(wú)意的信息被遺漏,比如由于工作人員的疏忽,忘記而缺失;或者由于數(shù)據(jù)采集器等故障等原因造成的缺失,或者是有意的有些數(shù)據(jù)集在特征描述中會(huì)規(guī)定將缺失值也作為一種特征值,再或者是不存在的,有些特征屬性根本就是不存在的。
缺失值的處理,我們常用的方法有:刪除記錄:對(duì)于樣本數(shù)據(jù)量較大且缺失值不多同時(shí)正相關(guān)性不大的情況下是有效。可以使用pandas的dropna來(lái)直接刪除有缺失值的特征。數(shù)據(jù)填充:數(shù)據(jù)填充一般采用均值,中位數(shù)和中數(shù),當(dāng)然還有其他的方法比如熱卡填補(bǔ)(Hot deck imputation),K最近距離鄰法(K-means clustering)等。不作處理:因?yàn)橐恍┠P捅旧砭涂梢詰?yīng)對(duì)具有缺失值的數(shù)據(jù),此時(shí)無(wú)需對(duì)數(shù)據(jù)進(jìn)行處理,比如Xgboost,rfr等高級(jí)模型,所以我們可以暫時(shí)不作處理。
對(duì)于這次比賽缺失值的處理主要是數(shù)據(jù)的填充。
1cols=["renovated","living_status","subway_distance","subway_station","subway_line"] 2forcolincols: 3kc_train[col].fillna(0,inplace=True) 4kc_test[col].fillna(0,inplace=True) 5 6kc_train["way_rent"].fillna(2,inplace=True) 7kc_test["way_rent"].fillna(2,inplace=True) 8kc_train["area"].fillna(8,inplace=True) 9kc_train=kc_train.fillna(kc_train.mean())10kc_test["area"].fillna(8,inplace=True)11kc_test=kc_test.fillna(kc_test.mean())
對(duì)于裝修狀態(tài),居住狀態(tài),距離,地鐵站點(diǎn)和線路均用0填充,區(qū)均用中位數(shù)8來(lái)填充,出租方式用2填充,同時(shí)做了一個(gè)判斷
1kc_train['is_living_status']=kc_train['living_status'].apply(lambdax:1ifx>0else0)2kc_train['is_subway']=kc_train['subway_distance'].apply(lambdax:1ifx>0else0)3kc_train['is_renovated']=kc_train['renovated'].apply(lambdax:1ifx>0else0)4kc_train['is_rent']=kc_train['way_rent'].apply(lambdax:1ifx0else0)7kc_test['is_subway']=kc_test['subway_distance'].apply(lambdax:1ifx>0else0)8kc_test['is_renovated']=kc_test['renovated'].apply(lambdax:1ifx>0else0)9kc_test['is_rent']=kc_test['way_rent'].apply(lambdax:1ifx
異常值處理
異常值是分析師和數(shù)據(jù)科學(xué)家常用的術(shù)語(yǔ),因?yàn)樗枰芮凶⒁猓駝t可能導(dǎo)致錯(cuò)誤的估計(jì)。 簡(jiǎn)單來(lái)說,異常值是一個(gè)觀察值,遠(yuǎn)遠(yuǎn)超出了樣本中的整體模式。
什么會(huì)引起異常值呢?
主要有兩個(gè)原因:人為錯(cuò)誤和自然錯(cuò)誤
如何判別異常值?
正態(tài)分布圖,箱裝圖或者離散圖。以正態(tài)分布圖為例:符合正態(tài)分布時(shí),根據(jù)正態(tài)分布的定義可知,距離平均值3δ之外的概率為 P(|x-μ|>3δ) <= 0.003 ,這屬于極小概率事件,在默認(rèn)情況下我們可以認(rèn)定,距離超過平均值3δ的樣本是不存在的。 因此,當(dāng)樣本距離平均值大于3δ,則認(rèn)定該樣本為異常值。當(dāng)數(shù)據(jù)不服從正態(tài)分布:當(dāng)數(shù)據(jù)不服從正態(tài)分布,可以通過遠(yuǎn)離平均距離多少倍的標(biāo)準(zhǔn)差來(lái)判定,多少倍的取值需要根據(jù)經(jīng)驗(yàn)和實(shí)際情況來(lái)決定。
異常值的處理方法常用有四種:1.刪除含有異常值的記錄2.將異常值視為缺失值,交給缺失值處理方法來(lái)處理3.用平均值來(lái)修正4.不處理
1all_data=pd.concat([train,test],axis=0,ignore_index=True) 2all_data.drop(labels=["price"],axis=1,inplace=True) 3fig=plt.figure(figsize=(12,5)) 4ax1=fig.add_subplot(121) 5ax2=fig.add_subplot(122) 6g1=sns.distplot(train['price'],hist=True,label='skewness:{:.2f}'.format(train['price'].skew()),ax=ax1) 7g1.legend() 8g1.set(xlabel='Price') 9g2=sns.distplot(np.log1p(train['price']),hist=True,label='skewness:{:.2f}'.format(np.log1p(train['price']).skew()),ax=ax2)10g2.legend()11g2.set(xlabel='log(Price+1)')12plt.show()
查看訓(xùn)練集的房?jī)r(jià)分布,左圖是原始房?jī)r(jià)分布,右圖是將房?jī)r(jià)對(duì)數(shù)化之后的。
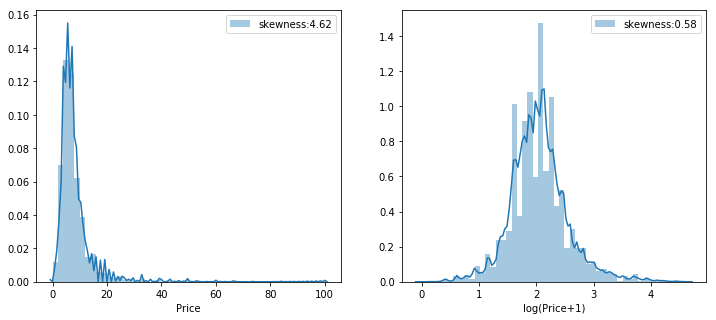
由于房?jī)r(jià)是有偏度的,將房?jī)r(jià)對(duì)數(shù)化并且將有偏的數(shù)值特征對(duì)數(shù)化
1train['price']=np.log1p(train['price'])23#將有偏的數(shù)值特征對(duì)數(shù)化4num_features_list=list(all_data.dtypes[all_data.dtypes!="object"].index)56foriinnum_features_list:7ifall_data[i].dropna().skew()>0.75:8all_data[i]=np.log1p(all_data[i])
根據(jù)上一篇我們篩選出的十個(gè)最相關(guān)的特征值,畫出離散圖,并且對(duì)離散點(diǎn)做處理,這里只取房屋面積舉個(gè)栗子。
1var='sqft_living'2data=pd.concat([train['price'],train[var]],axis=1)3data.plot.scatter(x=var,y='price',ylim=(0,150));

1train.drop(train[(train["sqft_living"]>0.125)&(train["price"]<20)].index,inplace=True)
這里將面積大于0.125且價(jià)格小于20的點(diǎn)全部刪除。
對(duì)于特征工程的處理這是在自己代碼中最重要的兩步--缺失值和異常值的處理,將類別數(shù)值轉(zhuǎn)化為虛擬變量和歸一化的處理效果不是特別好所以沒有貼上,數(shù)據(jù)集中的房屋朝向可以采用獨(dú)熱編碼,感興趣的可以試一下,我一直沒搞懂看了同學(xué)的處理他的代碼量太大,效果也不是特別明顯,自己索性沒去研究。下一次更新將針對(duì)這個(gè)問題進(jìn)行模型選擇。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8425瀏覽量
132773 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1452瀏覽量
34077 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24739
原文標(biāo)題:機(jī)器學(xué)習(xí)實(shí)戰(zhàn)--住房月租金預(yù)測(cè)(2)
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器學(xué)習(xí)算法的特征工程與意義詳解
機(jī)器學(xué)習(xí)實(shí)戰(zhàn)之logistic回歸
【下載】《機(jī)器學(xué)習(xí)》+《機(jī)器學(xué)習(xí)實(shí)戰(zhàn)》
機(jī)器學(xué)習(xí)實(shí)戰(zhàn):GNN加速器的FPGA解決方案
想掌握機(jī)器學(xué)習(xí)技術(shù)?從了解特征工程開始
機(jī)器學(xué)習(xí)特征工程的五個(gè)方面優(yōu)點(diǎn)
機(jī)器學(xué)習(xí)之特征提取 VS 特征選擇

機(jī)器學(xué)習(xí)實(shí)戰(zhàn)的源代碼資料合集

特征選擇和機(jī)器學(xué)習(xí)的軟件缺陷跟蹤系統(tǒng)對(duì)比
機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程1

機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程2

機(jī)器學(xué)習(xí)算法學(xué)習(xí)之特征工程3

數(shù)據(jù)預(yù)處理和特征工程的常用功能
通過強(qiáng)化學(xué)習(xí)策略進(jìn)行特征選擇






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論