 機器學習所需的數學知識你能夠有效使用嗎
機器學習所需的數學知識你能夠有效使用嗎
開始機器學習之旅,需要什么層次的數學功底? 尤其是對于那些沒有學過數學和統計學的同學們來說,這個問題當前不甚清楚,在這篇文章中,我將要為那些使用機器學習技術來開發產品或做學術研究的人們提供一些數學背景方面的建議。這些建議源于我與機器學習工程師、研究人員和教育工作者的對話,以及我在機器學習研究和產業方面的獨到經驗。
為了構造(機器學習中)數學的背景,我會先講一些與傳統課堂不同的思維模式和策略。然后,我會概述不同類型機器學習工作所需的具體背景,畢竟機器學習涉及的學科范圍太廣泛了(它涵蓋了高中級別的統計和微積分,也涵蓋了概率圖形模型(PGM)的最新進展)。
我希望讀者們在讀到文章的最后時,能夠知道自己有效使用機器學習所必需的數學知識。
作為這篇文章的前言,我想說:對于不同學習者的個人需求或目標來說,學習的風格、架構和資源都應該是獨一無二的!
數學焦慮癥的小貼士
事實證明,很多人——包括工程師——都害怕數學。首先,我想談談“擅長數學”這類傳說。
事實是,擅長數學的人都做過大量的數學練習。因此,在研究數學問題被卡住時,他們依然能夠“風雨不動安如山”。如最近的研究所示,學生的心態,而非先天才能,才是預測一個人學習數學的能力的主要因素。
要清楚的是,要達到這種境界,需要時間和精力。這顯然不是你天生就有的能力。本文的剩余部分將幫助您確定所需的數學功底,并概述構建它的策略。
萬事開頭難 作為軟性先修數學條件,我們假設你對線性代數/矩陣微積分都有了解,這樣你就不會為奇怪的符號苦惱。同時我們還假設你有基礎的概率知識。我們鼓勵你擁有基本的編程能力,這是領悟機器學習中的數學的有力工具。之后,你可以根據你感興趣的內容調整你的學習重點。
如何在課外學習數學?
我相信學習數學的最佳方式是以學生的身份全職學習。脫離了學校的環境,你可能不太容易獲得系統的知識結構、正能量的同學壓力和其他可用資源。
為了在課外學習數學,我建議大家將學習小組或午餐研討會作為學習的重要途徑。在研究型的實驗室中,這可能以閱讀小組的形式呈現。在構建知識結構方面,你的小組可以把教科書各章節過一遍,并定期對課程進行討論,同時通過Slack平臺的途徑參與遠程問答。
這里,企業文化發揮著重要的作用——這種“額外”的研究學習應該受到管理層的鼓勵和激勵,而不是被視為影響產品交付的消極怠工行為。事實上,雖然短期內會花費一些成本,但是構建同伴驅動的學習環境可以使你在長期的工作中更有效率。
數學與代碼 在機器學習工作流程中,數學和代碼緊密結合。代碼通常直接由數學直覺構建,有時它甚至會和數學符號使用相同的句法。事實上,現代數據科學框架應用(例如NumPy)使得數學運算(例如矩陣/矢量積)與可讀代碼之間的轉換變得直觀和有效。
我鼓勵你將編寫代碼作為鞏固學習的一種方式。學習數學和編寫代碼都依賴于你對問題理解和表述的精準程度。例如,手動編寫損失函數或優化算法,就是真正理解這些基礎概念的好方法。
讓我們來探索一個實際的問題:在你的神經網絡中實現ReLU函數激活的反向傳播(是的,即使Tensorflow / PyTorch可以替你做這個!)。這里簡單介紹一下,反向傳播是一種依賴于微積分鏈式規則來有效計算梯度的技術。為了在這個問題設定下使用鏈式規則,我們將上游導數與ReLU函數的梯度相乘。
我們先將ReLU激活函數進行可視化(就是下圖的樣子),然后這樣定義這個函數:
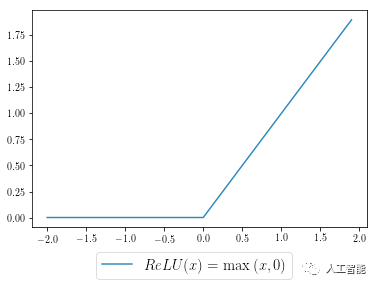
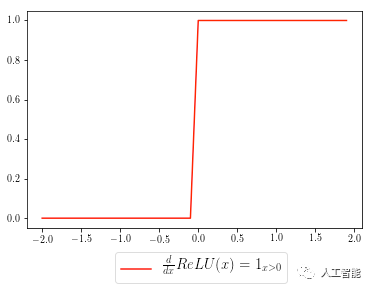
為了計算函數的梯度(直觀來說就是斜率),你可以想象出這樣一下分段函數,如下面的指示函數所示:
NumPy為我們提供了有用且直觀的語法——我們的激活函數(藍色曲線)可以通過代碼表述出來,其中x是我們的輸入,relu是我們的輸出:
relu = np.maximum(x, 0)
ReLU函數的梯度函數(紅色曲線)可以如下所示,grad表示上游梯度:
grad[x < 0] = 0
在沒有首先自己推導梯度公式的情況下,這行代碼可能沒有任何意義。在我們的代碼中,對于滿足[h <0]條件(即x<0)的所有元素,將其對應上游激活函數的梯度(grad)數值設置為0。在數學上,這實際上相當于ReLU梯度函數的分段表示,所有x軸上小于0的數值,當乘以上游梯度時,它的值會變成0。
正如我們所見,通過我們對微積分的基本理解,我們可以清楚地理解代碼的含義。
構建機器學習產品必需的數學知識
為了介紹這一節,我與機器學習工程師進行了交談,確定了數學在調試系統時最有力的地方。以下是工程師基于數學見解回答的問題示例。
如果你還沒有遇到過它們,請不要擔心。希望本節能夠為你提供一些特定問題的相關內容,也許你也會遇到類似的問題并嘗試解決喲!
Q:我該用哪種聚類方法可視化高維的客戶數據呢?
A:PCA或者tSNE。
Q:我該如何校準用來阻隔虛假用戶交易的安全閾值(例如在0.9或0.8的置信水平下)?
A:可以使用概率校準(Probability calibration)。
Q:描述我衛星數據在世界特定地區(如硅谷與阿拉斯加州)的偏差的最佳方法是什么?
A:這是一個開放的研究型問題。也許可以基于“人口平價”(demographic parity,該方法是要求預測必須與某特定敏感屬性不相關)的原則展開。
通常,統計和線性代數可以通過某種方式應用于這些問題中的任何一個。但是,要獲得滿意的答案通常需要針對特定領域的方法。如果是這樣的話,你如何縮小你所需學習的數學范疇呢?
定義一個系統我們并不缺乏資源(例如數據分析使用scikit-learn,深度學習使用keras)去幫助我們進行系統建模。而在建模之前,我們需要圍繞將要被建模的系統考慮這些問題:
系統的輸入/輸出分別是什么?
應該如何準備好合適的數據格式,從而適應系統要求?
如何進行特征建模或數據整理,以便于模型的推廣?
如何為需要解決的問題設定合理的目標?
你會驚訝地發現——要定義一個系統,其實非常復雜。而搭建數據工作流(data pipeline)也并不容易。換句話說,構建一個機器學習產品需要進行大量的繁瑣復雜的工作;而這些工作并不需要太深的數學背景。
數學需要“按需學習”當你一頭扎進一個機器學習的任務中時,會發現其中有些步驟對你來說難以進行,這種情況在進行算法調試時尤為常見。當你停滯其中時,是否知道該如何解決這一窘境呢?你設定的權重是否合理?
為什么模型沒有按照某個損失定義進行收斂?衡量成功的正確指標是什么?此時,有一些方法可以幫助到你:對數據做出假設、以不同方式約束優化、或嘗試不同的算法。
通常,你會發現建模/調試過程中需要數學直覺(例如,選擇損失函數或評估指標),這些直覺可能有助于做出明智的工程決策。 這些是你學習的機會!
來自Fast.ai的Rachel Thomas是這種“按需”方法的支持者——在教育學生時,她發現對于深度學習的學生來說,讓他們對將要學習的內容感到興奮更為重要。之后,針對這些學生的數學教育即可“按需”填補之前未涉及的知識漏洞。
接下來我將介紹對研究性工作中的機器學習方法有用的數學思維方式。批判性的觀點認為,機器學習研究方法就像是就像是“拿來主義”,人們只是通過把更多運算扔進模型中,從而獲得更好的預測表現。在一些圈子里,研究人員對實證研究方法仍然持懷疑態度,認為這些方法缺乏數學上的嚴謹性(例如某些深度學習方法),這些方法是不能將人類智慧發揮到極致的。
值得關注的是,研究界是建立在現有系統和假設的基礎上,而這些系統和假設可能不會擴展我們對該領域的基本理解。研究人員需要提供新的基本模塊,供我們在該領域中獲取全新洞察力和方法。
這可能意味著我們需要像“深度學習教父” Geoff Hinton在他最近的Capsule Networks論文中所做的那樣 ,重新思考構建某些領域的基礎知識(如應用于圖形分類的卷積神經網絡)。
為了邁出下一步,我們需要提一些基本問題。這需要在數學方面的極度熟練——深度學習一書的作者Michael Nielsen稱之為“有趣的探索”。這個過程涉及數千小時停滯、提問、重新思考問題以探索新觀點。
“有趣的探索”使科學家們能夠提出深刻,富有洞察力的問題,而不僅僅是簡單的想法或架構的結合。顯而易見,想要學會機器學習研究領域內需要的所有知識,是不可能的任務!要正確地進行“有趣的探索”,你需要遵循自己的興趣,而不是為最熱門的新結果感到焦慮。
機器學習研究是一個非常豐富的研究領域。當然,它在公平性、可解釋性和可獲得性方面也存在亟待解決的問題。在所有科學學科中都是如此,基本思維的獲得并不能一蹴而就。要在解決關鍵問題所需的高水平數學框架的廣度進行思考,需要長期的耐心。
將機器學習研究“大眾化”希望我沒有把“研究數學”描繪得太深奧,因為這些通過數學而產生的思考應該以直觀的形式呈現!可悲的是,許多機器學習論文仍然充斥著復雜且不一致的術語,使關鍵的直覺難以被辨別。作為一名學生,你可以嘗試將密集的論文翻譯成容易被直觀理解和消化的小塊文章,通過博客和推特等發表,這將對你自己和這個領域大有裨益。你甚至可以從distill.pub中找些例子,當作解釋機器模型研究方法結果的讀物。換句話說,將技術思想的祛魅化作“有趣的探索”手段——你自己的學習(和機器學習Twitter)會感謝你的!主要領悟總的來說,我希望這篇文章為你提供了一個思考研究機器學習所需數學教育的開端。
不同的問題需要不同程度的直覺,我鼓勵你首先弄清楚你的目標是什么。
如果你希望構建產品,請通過問題尋找同行和學習小組,并深入研究最終目標,激發你的學習。
在研究領域,廣泛的數學基礎可以為你提供工具,通過提供新的基礎知識來推動該領域的發展。
-
機器學習
+關注
關注
66文章
8425瀏覽量
132771
原文標題:機器學習的數學焦慮
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
工程電磁場應具備哪些數學知識
【下載】《機器學習》+《機器學習實戰》
一文匯總機器學習和Python(包括數學)速查表
機器學習中所需要的數學知識介紹
機器學習理論:k近鄰算法






 工商網監
工商網監
評論