 基于二叉樹的ensemble異常檢測算法
基于二叉樹的ensemble異常檢測算法
iForest (Isolation Forest)是由Liu et al. [1] 提出來的基于二叉樹的ensemble異常檢測算法,具有效果好、訓練快(線性復雜度)等特點。
1. 前言
iForest為聚類算法,不需要標記數據訓練。首先給出幾個定義:
劃分(partition)指樣本空間一分為二,相當于決策樹中節點分裂;
isolation指將某個樣本點與其他樣本點區分開。
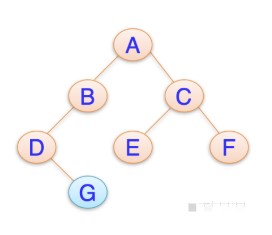
iForest的基本思想非常簡單:完成異常點的isolation所需的劃分數大于正常樣本點(非異常)。如下圖所示:
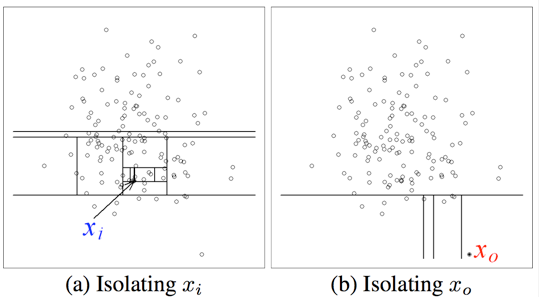
xi 樣本點的isolation需要大概12次劃分,而異常點x0指需要4次左右。因此,我們可以根據劃分次數來區分是否為異常點。但是,如何建模呢?我們容易想到:劃分對應于決策樹中節點分裂,那么劃分次數即為從決策樹的根節點到葉子節點所經歷的邊數,稱之為路徑長度(path length)。假設樣本集合共有n個樣本點,對于二叉查找樹(Binary Search Tree, BST),則查找失敗的平均路徑長度為
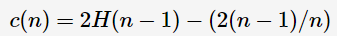
其中,H(i)為harmonic number,可估計為ln(i)+0.5772156649。那么,可建模anomaly score:
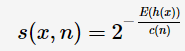
其中,h(x)為樣本點x的路徑長度,E(h(x))為iForest的多棵樹中樣本點x的路徑長度的期望。特別地,

當s值越高(接近于1),則表明該點越可能為異常點。若所有的樣本點的s值都在0.5左右,則說明該樣本集合沒有異常點。
2. 詳解
iForest采用二叉決策樹來劃分樣本空間,每一次劃分都是隨機選取一個屬性值來做,具體流程如下:

停止分裂條件:
樹達到了最大高度;
落在孩子節點的樣本數只有一個,或者所有樣本點的值均相同;
為了避免錯檢(swamping)與漏檢(masking),在訓練每棵樹的時候,為了更好地區分,不會拿全量樣本,而會sub-sampling樣本集合。iForest的訓練流程如下:

sklearn給出了iForest與其他異常檢測算法的比較。
-
檢測算法
+關注
關注
0文章
119瀏覽量
25220 -
二叉樹
+關注
關注
0文章
74瀏覽量
12332
原文標題:異常檢測算法:Isolation Forest
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
二叉樹算法在單總線技術中的應用
基于二叉樹分解的自適應防碰撞算法
基于二叉樹的時序電路測試序列設計
二叉樹層次遍歷算法的驗證
二叉樹,一種基礎的數據結構類型
二叉樹操作的相關知識和代碼詳解





 工商網監
工商網監
評論