 NIPS 2018 AutoML挑戰賽公布了最終結果,清華大學計算機系朱文武團隊斬獲第二,高校排名雄踞第一!
NIPS 2018 AutoML挑戰賽公布了最終結果,清華大學計算機系朱文武團隊斬獲第二,高校排名雄踞第一!
近期,NIPS 2018 AutoML挑戰賽公布了最終結果。本次賽事共有近三百支隊伍參賽,包括了麻省理工學院、加州大學伯克利分校、德州農工大學、清華大學、北京大學等國內外頂尖高校,微軟、騰訊、阿里巴巴等科技巨頭。清華大學計算機系朱文武團隊斬獲第二,高校排名雄踞第一!
NIPS 2018 AutoML挑戰賽結果出爐:印度團隊autodidact.ai第一,清華計算機系朱文武實驗室Meta_Learners團隊斬獲第二。
值得注意的是,清華Meta_Learners團隊是本次參賽高校成績第一,且僅與冠軍差0.2個排名!
AutoML,全稱為Automated Machine Learning,是機器學習領域的一個新興方向。旨在自動化整個機器學習的流程,降低數據預處理、特征工程、模型選擇、參數調節等環節中的人工成本。
隨著機器學習系統的日益復雜化,AutoML得到了產學研各界的廣泛關注,已成為人工智能領域最熱門的研究方向之一。
本次賽事共有近三百支隊伍參賽,包括了麻省理工學院、加州大學伯克利分校、德州農工大學、清華大學、北京大學等國內外頂尖高校,微軟、騰訊、阿里巴巴等科技巨頭,autodidact.ai、Rapids.ai等新興創業公司,Auto-sklearn、Auto-keras等著名AutoML開源框架的作者團隊。
根據官方公布的排名結果來看,朱文武實驗室Meta_Learners團隊在Set 2和Set 4上的排名均居第一,在其它3個Set上也都取得了較高名次。
全球名校、企業同臺競爭:清華斬獲第二,高校第一!
Meta_Learners團隊成員包括計算機系博士畢業生張文鵬、在讀碩士生熊錚、在讀博士生蔣繼研,由張文鵬擔任隊長,朱文武教授擔任指導教師。
團隊從2015年開始持續關注和布局AutoML領域,目前已經具備了較為豐富的領域知識和較為深厚的技術積累,今年首次參加AutoML比賽即摘得亞軍。
今年的賽事題目聚焦于真實應用場景下存在概念遷移的大規模流式數據中的AutoML問題,對AutoML系統的自適應能力、魯棒性都提出了較以往比賽更高的要求。
比賽分為兩個階段:Feedback階段和AutoML階段。
Feedback階段是代碼提交階段。主辦方會提供5個與第二階段的數據集具有相似特性的訓練數據集;參賽者在訓練數據集上構建AutoML系統,并根據線上運行結果進行優化。
AutoML階段是盲測階段,無法進行代碼提交。參賽者在Feedback階段提交的最后一版代碼會在5個全新的數據集上進行自動化的訓練與測試,得到的盲測結果將作為比賽最終排名的依據。
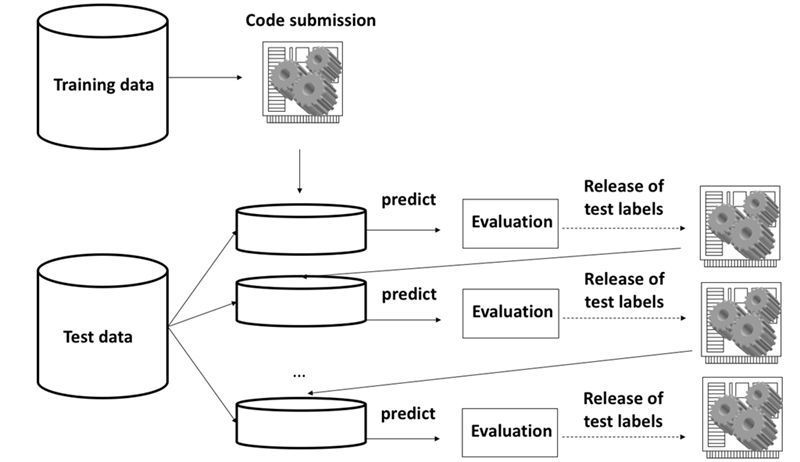
每個數據集內部按時間順序分為10個Batch,每個Batch代表終身(Lifelong)學習場景中的一個階段。
參賽者提交的AutoML系統使用數據集中的第一個Batch作為訓練數據生成初始模型,并在第一個測試Batch(整個數據集中的第二個Batch)上進行預測。隨后,系統將得到當前測試Batch的標簽,并對初始模型進行修正。系統將在后續的所有測試Batch上迭代進行預測與模型修正,直到完成對所有測試Batch的預測。
比賽制勝法寶:做好不同層次的平衡(Tradeoff)
在本次比賽中,Meta_Learners團隊采用了梯度提升樹(Gradient Boosting Tree),在傳統的AutoML框架上,結合本次比賽數據的特性做了有針對性的設計:
特征工程方面,主要針對類別特征高基數、長尾分布的特點,采用了頻數編碼、中值編碼等不同編碼方式,以及離散化、分位數變換等處理技巧。
遷移適應方面,針對數據存在概念遷移的問題采用了自適應的流式編碼技術。
資源控制方面,自動監測系統中各個組件的運算花銷,并使用Bandit技術對搜索空間進行壓縮和剪枝。
團隊認為AutoML比賽的關鍵在于做好不同層次的平衡(Tradeoff)。
首先是宏觀方法論層面的平衡。AutoML比賽和傳統的數據挖掘比賽有很多相似之處,但也有本質的不同。相似之處在于特征工程都發揮著至關重要的作用。不同之處在于,傳統數據挖掘比賽的訓練集和測試集一般來自于同一場景,在第一階段表現好的方法,在第二階段更換新的測試集后一般仍然會好。但是在AutoML比賽中,第二階段會更換嶄新的數據集(與第一階段的數據集有一定相似性,但并不同源)。
因此,AutoML系統如果過分適應第一階段的數據,就會導致在第二階段的排名出現較大波動。所以該團隊的策略是并不刻意追求第一階段的排名,而是注重提升整個系統的泛用性和自適應能力,也就是做好第一階段和第二階段的平衡。
其次是搜索空間和資源約束之間的平衡。搜索空間大會覆蓋更多的候選配置(特征、算法和參數的組合),但太大則會超出系統資源的約束。AutoML系統需要根據不同數據集的大小和數據特性,自適應地設計和分配搜索空間,以保證在不超出資源限制的前提下,選擇出更好的配置。
AutoML技術的關鍵在于如何理解Auto的過程
而此次比賽結果,Meta_Learners團隊與第一名僅差0.2個排名,對此次的惜敗,團隊成員表示時間利用不夠充分是主要理由。
比賽中期,由于一些臨時事件的耽誤,團隊內部交流和討論不夠充分,導致進度停滯了一段時間。
在處理概念遷移的過程中,團隊曾出現技術路線的偏離,在數周內進展緩慢。團隊最初沿著序列化檢測和自適應的思路進行探索,效果并不理想;經過仔細分析,團隊發現Batch間的遷移并無趨同性,不符合序列化模型的場景假設。因此,團隊放棄了該技術路線,但確實耽誤了很多時間。
由于前面時間的耽誤,比賽最后階段,模型整合優化的時間不夠充分,一些在某些數據集上效果良好的算法并沒有納入最終AutoML框架的自動選擇范圍內。例如,遷移學習中基于密度比估計的重要性采樣(Importance sampling),在波動較大的Batch上有很好的效果,但算法本身計算成本高,需要做進一步優化。最終由于時間有限,團隊并沒有把該方法優化得很好,也就沒有把它納入最終的解決方案。
對于AutoML技術本身,團隊認為,關鍵在于如何理解Auto的過程。對此,不同研究者有著不同的視角,進而衍生出了基于貝葉斯優化、強化學習、遷移學習、遺傳算法、Bandit和梯度下降等不同方法的技術路線。更好的理解會有助于產生出更優化的算法。
學術界和產業界都關注如何提高AutoML算法的性能和效率。相對而言,有一些問題學術界會關注得更多一點,比如,算法的最優性保證、算法中的Auto可以做多少層等;與此相對應,產業界可能會更關注一些具體實際場景中的AutoML問題,比如,本次比賽關注存在概念遷移的大規模流式數據中的AutoML問題。當然,團隊也從中提取了一些有研究價值的學術問題。
團隊介紹
Meta_Learners團隊由清華大學博士張文鵬、碩士研究生熊錚、博士研究生蔣繼研組成,由張文鵬擔任隊長。
在本次比賽中,張文鵬負責技術路線的選擇和比賽節奏的把控;熊錚負責基礎框架、控制模塊的構建和部分特征工程;蔣繼研負責概念遷移的處理和部分特征工程。
該團隊從2015年開始關注AutoML領域,當時谷歌還沒有提出相關概念。最初,張文鵬發現神經網絡的調參非常復雜,進而意識到AutoML的價值和潛力。朱文武老師也非常認同,果斷組建團隊開始該領域的研究。在該團隊中,熊錚主要關注基于貝葉斯優化的AutoML系統,蔣繼研則關注Bandit方法在AutoML中的應用。
2017年,該團隊提出了利用強化學習構建決策樹模型的元學習算法并發表于NIPS 2017的Meta Learning Workshop,這也是國內相關領域最早的研究成果之一。
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46074 -
深度學習
+關注
關注
73文章
5512瀏覽量
121405 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13614
原文標題:清華朱文武團隊斬獲NIPS 2018 AutoML挑戰賽亞軍,高校排名第一
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
優秀獎及決賽陣容震撼公布 第二屆OpenHarmony創新應用挑戰賽決戰在即
EDA精英挑戰賽賽果公布!思爾芯“戰隊”薪火相承斬獲“麒麟杯”

清華大學創新領軍工程博士團隊調研芯和半導體
50萬獎金池!開放原子大賽——第二屆OpenHarmony創新應用挑戰賽正式啟動
微處理器如何控制計算機系統
AI4Science黑客松光子計算挑戰賽成功舉辦
熱烈歡迎清華大學電子工程系學子來武漢六博光電交流實踐!

計算機系統的組成和功能
第三屆CCF“司南杯”量子計算編程挑戰賽獲獎名單公布!







 工商網監
工商網監
評論