 谷歌團隊打造了一個名為JAX的系統
谷歌團隊打造了一個名為JAX的系統
谷歌團隊(非官方發布)打造了一個名為JAX的系統,今日在Reddit引發了熱議。網友紛紛為它叫好——“說不定能夠取代TensorFlow”。本文便帶領讀者一覽JAX的廬山真面目。
它就是JAX,一款由谷歌團隊打造(非官方發布),用于從純Python和Numpy機器學習程序中生成高性能加速器(accelerator)代碼,且特定于域的跟蹤JIT編譯器。
那么JAX到底有哪些威力呢?
JAX使用XLA編譯器基礎結構,來為子程序生成最有利于加速的優化代碼,這些優化子程序可以由任意Python調用和編排;
由于JAX與Autograd完全兼容,它允許Python函數的正、反向模式(forward- and reverse-mode)自動區分為任意順序;
由于JAX支持結構化控制流,所以它可以在保持高性能的同時為復雜的機器學習算法生成代碼;
通過將JAX與Autograd和Numpy相結合,可得到一個易于編程且高性能的ML系統,該系統面向CPU,GPU和TPU,且能擴展到多核Cloud TPU。
此“神器”在Reddit上引發了熱烈的討論,網友紛紛為它叫好:
我的天,“可微分的numpy”實在是太棒了!我對pytorch有一點不是很滿意,他們基本上重新做了numpy所做的一切,但存在一些愚蠢的差異,比如“dim”,而不是“axis”,等等。
JAX系統設計一覽
谷歌團隊通過觀察發現,JAX的ML工作負載通常由PSC子程序控制。
JAX的設計便因此利用了函數通常可以直接在機器學習代碼中識別的特性,使機器學習研究人員可以使用JAX的jit_ps修飾符進行注釋。
雖然手工注釋對非專業用戶和“零工作量知識”優化提出了挑戰,但它為專家提供了直接的好處,而且作為一個系統研究項目,它展示了PSC假設的威力。
JAX跟蹤緩存為跟蹤計算的參數創建了一個monomorphic signature,以便新遇到的數組元素類型、數組維度或元組成員觸發重新編譯。在跟蹤緩存丟失時,JAX執行相應的Python函數,并將其執行跟蹤到具有靜態數據依賴關系的原始函數圖中。
現有的原語不僅包括數組級別的數字內核,包括Numpy函數和其他函數,它們允許用戶通過保留PSC屬性將控制流分段到編譯后的計算中。最后,JAX包含一些用于功能分布式編程的原語,如iterated_map_reduce。
為了生成代碼,JAX將跟蹤轉換為XLA HLO,這是一種中間語言,可以對高度可加速的數組級數值程序進行建模。從廣義上講,JAX可以被看作是一個系統,它將XLA編程模型提升到Python中,并支持使用可加速的子程序,同時仍然允許動態編排。
defxla_add(xla_builder,xla_args,np_x,np_y):returnxla_builder.Add(xla_args[0],xla_args[1])defxla_sinh(xla_builder,xla_args,np_x):b,xla_x=xla_builder,xla_args[0]returnb.Div(b.Sub(b.Exp(xla_x),b.Exp(b.Neg(xla_x))),b.Const(2))defxla_while(xla_builder,xla_args,cond_fun,body_fun,init_val):xla_cond=trace_computation(cond_fun,args=(init_val,))xla_body=trace_computation(body_fun,args=(init_val,))returnxla_builder.While(xla_cond,xla_body,xla_args[-1])jax.register_translation_rule(numpy.add,xla_add)jax.register_translation_rule(numpy.sinh,xla_sinh)jax.register_translation_rule(while_loop,xla_while)
JAX從原語到XLA HLO的翻譯規則
另外,JAX和Autograd完全兼容。
importautograd.numpyasnpfromautogradimportgradfromjaximportjit_psdefpredict(params,inputs):forW,binparamsoutputs=np.dot(inputs,W)+binputs=np.tanh(outputs)returnoutputsdefloss(params,inputs,targets):preds=predict(params,inputs)returnnp.sum((preds-targets)**2)grad_fun=jit_ps(grad(loss))#Compiledgradient-of-lossfunction
一個與JAX完全連接的基本神經網絡
實驗、性能結果比較
為了演示JAX和XLA提供的數組級代碼優化和操作融合,谷歌團隊編譯了一個具有SeLU非線性的完全連接神經網絡層,并在圖1中顯示JAX trace和XLA HLO圖形。
圖1:XLA HLO對具有SeLU非線性的層進行融合。灰色框表示所有的操作都融合到GEMM中。
使用一個線程和幾個小的示例優化問題(包括凸二次型、隱馬爾科夫模型(HMM)邊緣似然性和邏輯回歸)將Python執行時間與CPU上的JAX編譯運行時進行了比較。
對于某些CPU示例來說,XLA的編譯時間比較慢,但將來可能會有顯著的改進,對于經過warmed-up代碼(表1),XLA的編譯速度非常快。
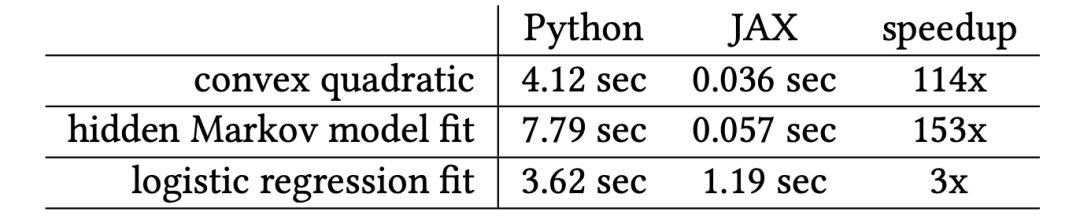
表1:在CPU上Truncated Newton-CG的計時(秒)
在GPU上訓練卷積網絡。谷歌團隊實現了一個all-conv CIFAR-10網絡,只涉及卷積和ReLU激活。谷歌編寫了一個單獨的隨機梯度下降(SGD)更新步驟,并從一個純Python循環中調用它,結果如表2所示。
作為參考,谷歌在TensorFlow中實現了相同的算法,并在類似的Python循環中調用它。

表2:GPU上JAX convnet步驟的計時(msec)
云TPU可擴展性。云TPU核心上的全局批處理的JAX并行化呈現線性加速(圖2,左)。在固定的minibatch / replica中,texec受復制計數的影響最小(在2ms內,右邊)

圖2:為ConvNet訓練步驟在云TPU上進行擴展。
-
谷歌
+關注
關注
27文章
6173瀏覽量
105634 -
編譯器
+關注
關注
1文章
1636瀏覽量
49173 -
機器學習
+關注
關注
66文章
8425瀏覽量
132773
原文標題:試試谷歌這個新工具:說不定比TensorFlow還好用!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論