 詞對嵌入技術,可以改善現有模型在跨句推理上的表現
詞對嵌入技術,可以改善現有模型在跨句推理上的表現
詞嵌入現在已經成為任何基于深度學習的自然語言處理系統的標配組件。然而,Glockner等最近的工作(arXiv:1805.02266)表明,當前重度依賴無監督詞嵌入的模型,難以學習詞對之間的隱含關系。而詞對之間的隱含關系,對問答(QA)、自然語言推理(NLI)之類的跨句推理至關重要。
例如,在NLI任務中,給定一個假設“打高爾夫球過于昂貴”(golf is prohibitively expensive),要推斷出猜想“過去打高爾夫球很便宜”(golf is a cheap pastime),需要了解“昂貴”(expensive)和“便宜”(cheap)是反義詞。而現有的基于詞嵌入的模型很難學習這種關系。
有鑒于此,華盛頓大學的Mandar Joshi、Eunsol Choi、Daniel S. Weld和Facebook AI研究院的Omer Levy、Luke Zettlemoyer最近提出了詞對嵌入(pair2vec)技術,可以改善現有模型在跨句推理上的表現。
詞對嵌入表示
直覺
詞對嵌入的直覺很簡單,正如上下文隱含了單詞的語義(詞嵌入),上下文也為詞對之間的關系提供了強力線索。
詞對(斜體)及其上下文(取自維基百科)
不過,總體上來說,詞對一起出現在同一上下文的頻率不高。為了緩解這一稀疏性問題,pair2vec學習兩個復合表示函數R(x, y)和C(c),分別編碼詞對和上下文。
表示
R(x,y)是一個簡單的4層感知器,輸入為兩個詞向量,以及這兩個詞向量的分素乘積:
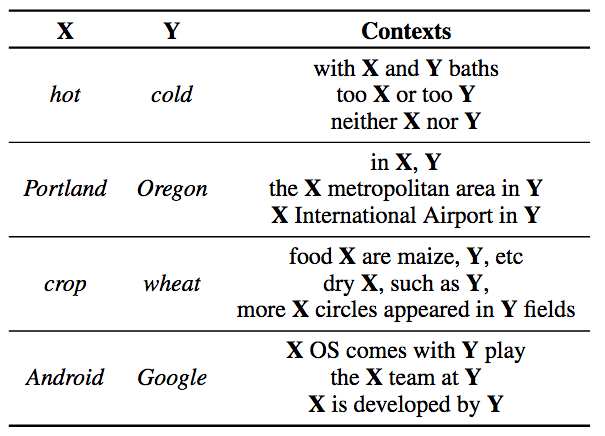
其中,x和y為經過歸一化的基于共享查詢矩陣Ea的嵌入:
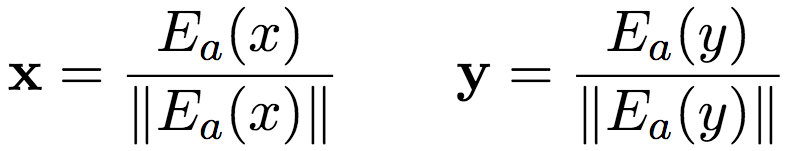
C(n)基于查詢矩陣Ec嵌入每個token ci,然后將嵌入序列傳入一個單層的雙向LSTM,再使用注意力池化加以聚合:
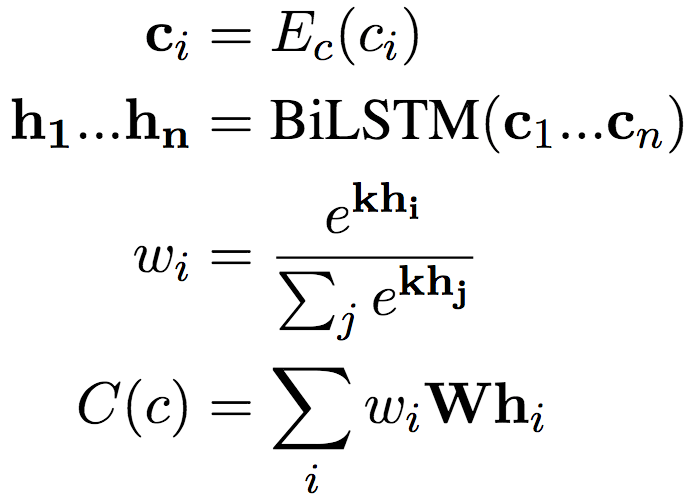
上面所有的參數,包括Ea和Ec,都是可訓練的。
目標
一方面,優化目標需要使在數據中觀測到的一同出現的(x, y, c)對應的R(x, y)和C(c)相似(內積較大);另一方面,又需要使詞對和其他上下文不相似。當然,計算所有其他上下文和詞對的相似性的算力負擔太大了,因此,論文作者采用了負采樣技術,轉而比較隨機采樣的一些上下文。
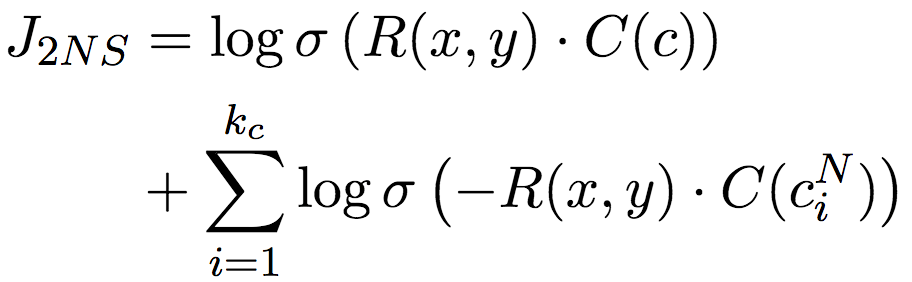
上式中的CN為隨機取樣的上下文。
這種做法其實和詞嵌入一脈相承。詞嵌入同樣面臨計算所有上下文(softmax)過于復雜的問題。因此,word2vec、skip-gram等詞嵌入技術使用了層次softmax(使用二叉樹結構保存所有詞,從而大大縮減計算量)。后來Mikolov等提出,負采樣可以作為層次softmax的替代方案。相比層次softmax,負采樣更簡單。
不過,還記得我們之前提到的詞對稀疏性問題嗎?這種直接借鑒詞嵌入負采樣的方案,也會受此影響。所以論文作者改進了負采樣技術,不僅對上下文c進行負采樣,還對詞對中的單詞x和y分別進行負采樣。這一三元負采樣目標,完整地捕捉了x、y、c之間的交互關系:
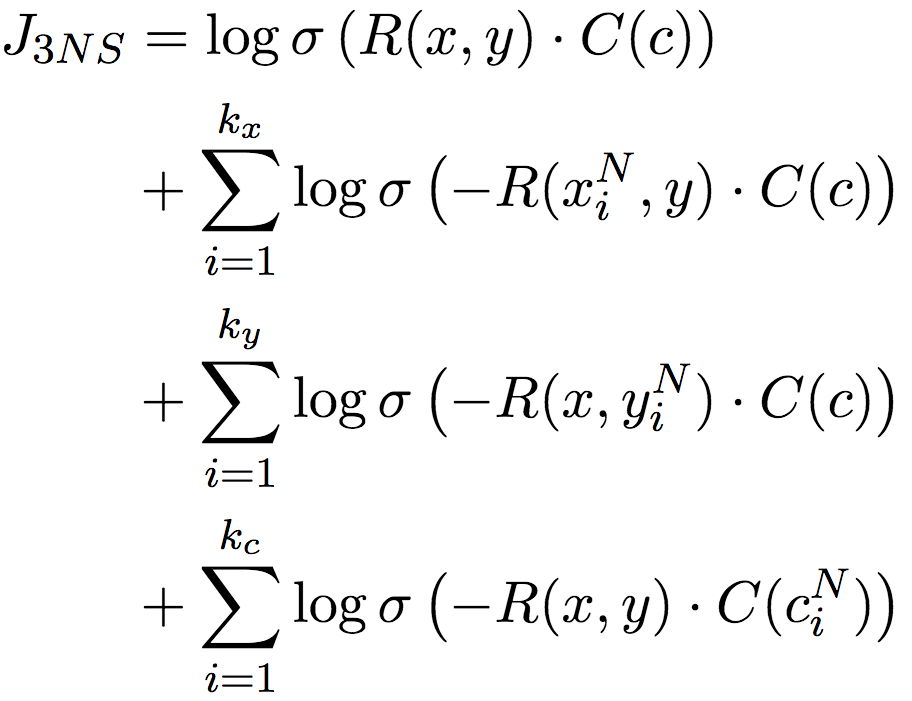
論文作者證明(見論文附錄A.2),目標收斂于:
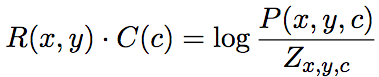
上式中,P表示分素互信息(PMI),分母Zx,y,c為邊緣概率乘積的線性混合:
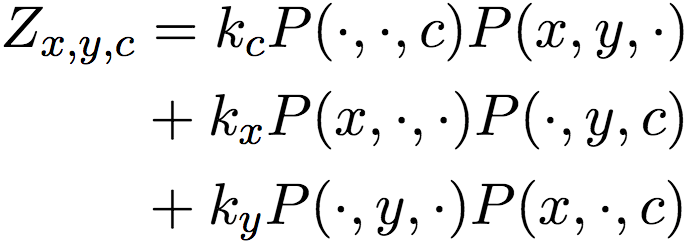
另外,負采樣時,除了從均勻分布中取樣外,還額外從最相似(根據余弦相似度)的100個單詞中均勻取樣。這一類型取樣(typed sampling)方法可以鼓勵模型學習具體實例間的關系。比如,使用California(加州)作為Oregon(俄勒岡州)的負樣本有助于學習“X is located in Y”(X位于Y)這樣的模式適用詞對(Portland, Oregon)(波特蘭是俄勒岡州的城市),但不適用詞對(Portland, California)。
pair2vec加入推理模型
在將pair2vec加入現存跨句推理模型時,論文作者并沒有用pair2vec直接替換傳入編碼器的詞嵌入,而是通過復用跨句注意力權重,將預訓練的詞對表示插入模型的注意力層。
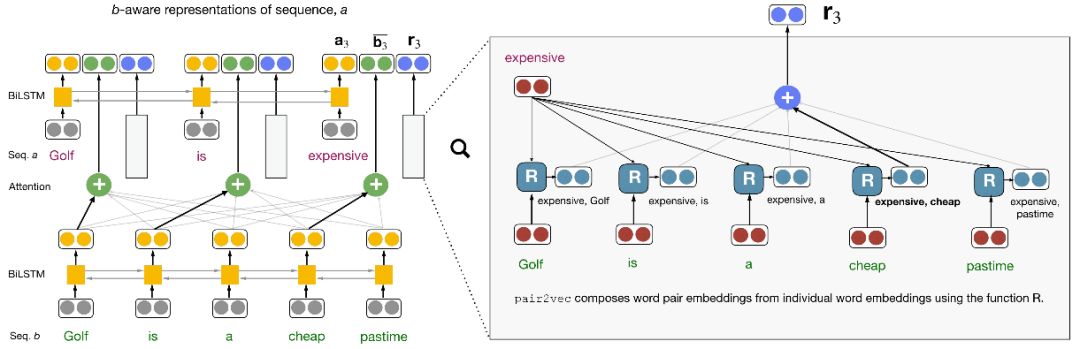
上圖展示了跨句注意力模型的典型架構(左半部分)和pair2vec是如何加入這一架構的(右半部分)。簡單解釋一下,給定兩個序列a和b,對序列a中的單詞ai,模型基于雙向LSTM編碼ai,同時基于序列b的雙向LSTM狀態創建相對于ai的注意力加權表示(圖中加粗的箭頭表示語義對齊)。在此基礎上,加上注意力加權的詞對表示ri(ai, b)。
試驗
數據
論文作者使用了2018年1月的維基百科數據,其中包含九千六百萬句子。基于詞頻限制詞匯量至十萬(預處理階段移除)。在經過預處理的語料庫上,論文作者考慮了窗口大小5以內的所有詞對,并基于詞對概率(閾值為5 × 10-7)降采樣實例。降采樣可以壓縮數據集大小以加速訓練,word2vec等詞嵌入也采用降采樣。上下文從詞對左邊的一個單詞開始,到詞對右邊的一個單詞為止。另外,論文作者用X和Y替換了上下文中的詞對。
超參數
詞對和上下文均使用基于FastText初始化的300維詞嵌入。上下文表示使用的單層雙向LSTM的隱藏層尺寸為100. 每個詞對-上下文元組使用2個上下文負樣本和3個增強負樣本。
預訓練使用隨機梯度下降,初始學習率為0.01,如果損失在30萬步后沒有下降,那么將學習率縮小至原學習率的10%。batch大小為600。預訓練了12個epoch(在Titan X GPU上,預訓練需要一周)。
任務模型均使用AllenNLP的實現,超參數取默認值。在插入pair2vec前后沒有改動任何設置。預訓練的詞對嵌入使用0.15的dropout.
問答任務
在SQuAD 2.0上的試驗表明,pair2vec提升了2.72 F1. 對抗SQuAD數據集上的試驗說明pair2vec同時加強了模型的概括性(F1分別提升7.14和6.11)。
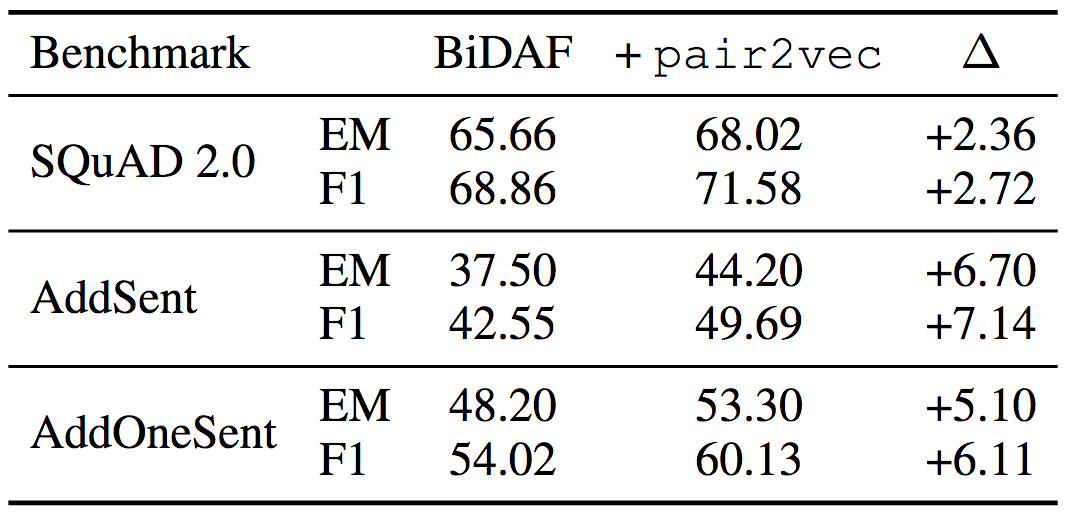
均使用ELMo詞嵌入
自然語言推理
在MultiNLI數據集上,加入pair2vec后,ESIM + ELMo的表現提升了1.3.

Glockner等提出了一個領域外NLI測試集( arXiv:1805.02266),說明除了使用WordNet特征的KIM外,多個NLI模型在比SNLI更簡單的新測試集上的表現反而要差不少,說明這些模型的概括性有問題。而加入pair2vec后的ESIM + ELMo模型達到了當前最先進水平,刷新了記錄。
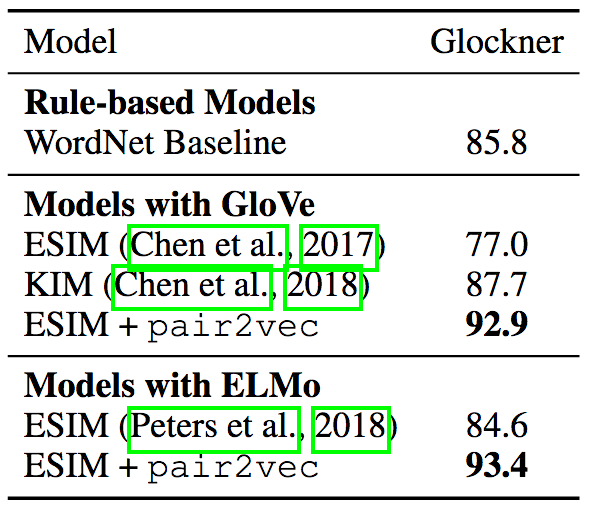
順便提下,KIM的做法是現有研究中最接近pair2vec的。KIM同樣在ESIM模型中加入了詞對向量,但是它的詞對向量是基于WordNet手工編碼得到的。而pair2vec使用的是無監督學習,因此可以反映WordNet中不存在的關系(例如個人-職業),以及WordNet中沒有直接聯系的詞對(例如,bronze(青銅)與statue(塑像))。
詞類比
為了揭示pair2vec加入的額外信息是什么,pair2vec能夠更好地捕捉哪類聯系,論文作者在詞類比數據集上進行了試驗。
詞類比任務是指,給定詞對(a, b)和單詞x,預測滿足a : b :: x : y的單詞y。論文作者使用的是BATS數據集,該數據集包括四種關系:
百科語義(encyclopedic semantics),例如Einstein-physicist(愛因斯坦-物理學家)這樣的個人-職業關系。
詞典語義(lexicographic semantics),例如cheap-expensive(廉價-昂貴)這樣的反義詞。
派生形態(derivational morphology),例如oblige(動詞,迫使)與obligation(名詞,義務)。
屈折形態(inflectional morphology),例如bird-birds(鳥的單數形式和復數形式)。
每種關系各包含10個子類別。
之前我們說過,詞類比任務是要預測滿足a : b :: x : y的單詞y,而相關詞嵌入的差很大程度上能夠反映相似關系,例如,queen(后) - king(王) ≈ woman(女) - man(男)很大程度上意味著queen : king :: woman : man。所以,詞類比問題可以通過優化cos(b - a + x, y)求解(cos表示余弦相似度,a、b、x、y為詞嵌入)。這一方法一般稱為3CosAdd法。
論文作者在3CosAdd中加入了pair2vec,得到α·cos(ra,b, rx,y) + (1-α)·cos(b - a + x, y)。其中r表示pair2vec嵌入,α為線性插值系數,α=0時等價于原3CosAdd法,α=1等價于pair2vec。
下圖顯示了在FastText中插入pair2vec的結果,黃線表示派生形態,棕線表示詞典語義,綠線表示屈折形態,藍線表示百科語義。
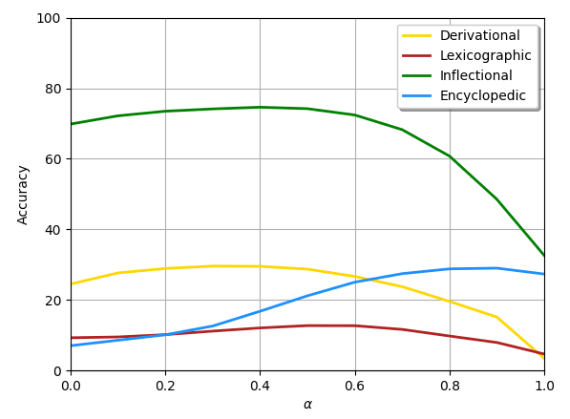
我們可以看到,在所有四個類別上,在3CosAdd上增加pair2vec都取得了顯著的提升,其中百科語義(356%)和詞典語義(51%)提升尤為突出。
下表顯示了提升最明顯的10個子類別,α*為最優插值參數。
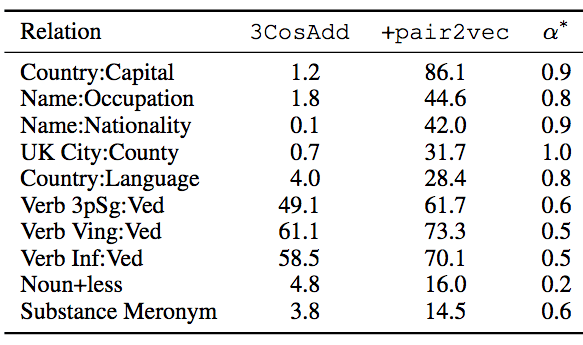
從上表我們可以看到,在FastText嵌入提供的信號十分有限的關系上,提升尤為顯著。論文作者還觀察到,某些情形下pair2vec和FastText存在協同效應,比如,noun+less關系中,3CosAdd原本評分為4.8,pair2vec自身評分為0,但3CosAdd加上pair2vec后,評分為16。
填槽
為了進一步探索pair2vec如何編碼補充信息,論文作者嘗試了填槽(slot filling)任務:給定Hearst式的上下文模式c、單詞x,預測取自整個詞匯表的單詞y。候選單詞y的排序基于訓練目標R(x,y)·C(c)的評分函數,采用固定的關系樣本,并手工定義上下文模式和一小組候選詞x。
下表顯示了評分最高的三個y單詞。
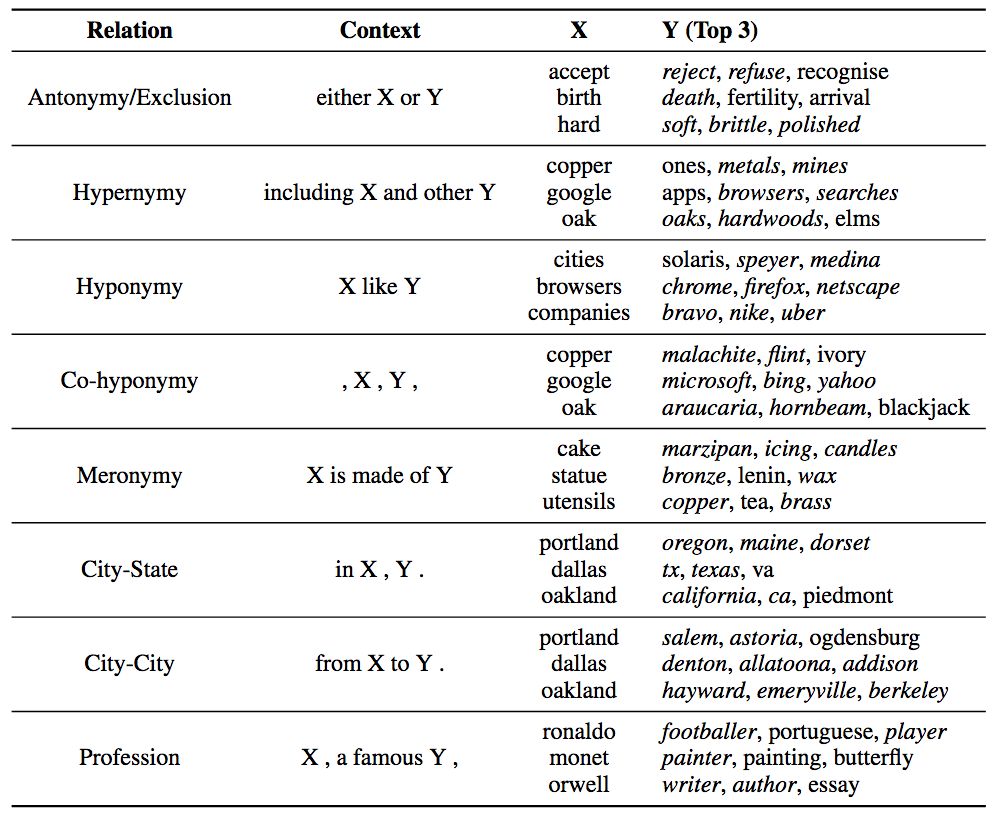
斜體表示正確匹配
上表說明,pair2vec可以捕捉詞對和上下文間的三邊關系,而不僅僅是單個單詞和上下文之間的雙邊關系(詞嵌入)。這一巨大差別使pair2vec可以為詞嵌入補充額外信息。
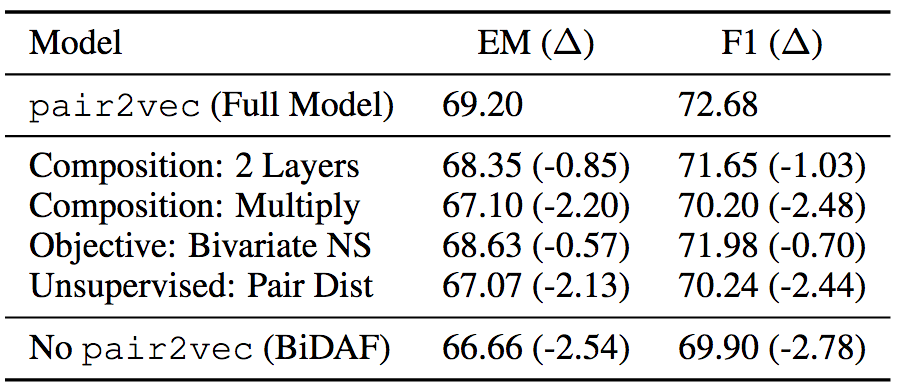
消融測試
為了驗證pair2vec各組件的有效性,論文作者也在SQuAD 2.0的訓練集上做了消融測試。消融測試表明,增強采樣和使用較深的復合函數效果顯著。
結語
pair2vec基于復合函數表示,有效緩解了詞對的稀疏性問題。基于無監督學習預訓練的pair2vec,能夠為詞嵌入補充信息,從而提升跨句推理模型的表現。
-
編碼器
+關注
關注
45文章
3739瀏覽量
136323 -
深度學習
+關注
關注
73文章
5540瀏覽量
122207 -
自然語言處理
+關注
關注
1文章
624瀏覽量
13879
原文標題:pair2vec 基于復合詞對嵌入加強跨句推理模型
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論