 Apache Spark上的分布式機器學習的介紹
Apache Spark上的分布式機器學習的介紹
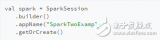
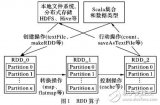
Spark是一個基于內存計算的開源的集群計算系統,目的是讓數據分析更加快速。Spark非常小巧玲瓏,由加州伯克利大學AMP實驗室的Matei為主的小團隊所開發。使用的語言是Scala,項目的core部分的代碼只有63個Scala文件,非常短小精悍。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
intel
+關注
關注
19文章
3483瀏覽量
186114 -
代碼
+關注
關注
30文章
4802瀏覽量
68740 -
機器學習
+關注
關注
66文章
8425瀏覽量
132770
發布評論請先 登錄
相關推薦
RDMA技術在Apache Spark中的應用
背景介紹 在當今數據驅動的時代,Apache?Spark已經成為了處理大規模數據集的首選框架。作為一個開源的分布式計算系統,Spark因其高

spark集群使用hanlp進行分布式分詞操作說明
本篇分享一個使用hanlp分詞的操作小案例,即在spark集群中使用hanlp完成分布式分詞的操作,文章整理自【qq_33872191】的博客,感謝分享!以下為全文: 分兩步:第一步:實現
發表于 01-21 10:45
【學習打卡】OpenHarmony的分布式任務調度
、同步、注冊、調用)機制。分布式任務調度程序是能夠跨多個服務器啟動調度作業或工作負載的軟件解決方案,整個過程是不需要人來值守的。舉個例子,我們可以在一臺或多臺機器上安裝分布式調度器,用
發表于 07-18 17:06
如何使用Apache Spark 2.0
,Spark 2.0現在比以往更易使用。在這部分,我將介紹如何使用Apache Spark 2.0。并將重點關注DataFrames作為新Dataset API的無類型版本。 到
發表于 09-28 19:00
?0次下載
Spark分布式下的模糊C均值算法
針對聚類算法需要處理數據集的規模越來越大、時效性要求越來越高,對算法的大數據適應能力和性能要求更高的問題,提出一種在Spark分布式內存計算平臺下的模糊C均值(FCM)算法Spark-FCM。首先
發表于 12-23 09:59
?0次下載
機器學習實例:Spark與Python結合設計
Apache Spark是處理和使用大數據最廣泛的框架之一,Python是數據分析、機器學習等領域最廣泛使用的編程語言之一。如果想要獲得更棒的機器
發表于 07-01 10:15
?2774次閱讀
spark和hadoop的區別
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。用戶可以在不了解
Apache Ignite上的TensorFlow!分布式內存數據源
另一個基準測試表明 Ignite Dataset 如何與分布式 Apache Ignite 集群協作。這是 Apache Ignite 作為 HTAP 系統的默認用例,它使您能夠在每秒 10 Gb 的網絡集群

Apache Spark 3.2有哪些新特性
單節點機器或集群上執行數據工程、數據科學和機器學習的最廣泛使用的引擎。 Spark 3.2 繼續以使 S
一文詳細了解APACHE SPARK開源框架
Apache Spark 是一個開源框架,適用于跨集群計算機并行處理大數據任務。它是在全球廣泛應用的分布式處理框架之一。
利用Apache Spark和RAPIDS Apache加速Spark實踐
在第三期文章中,我們詳細介紹了如何充分利用 Apache Spark 和 Apache RAPIDS 加速器 Spark 。 大多數團隊






 工商網監
工商網監
評論