 一種使用卷積神經網絡來預測斗地主游戲中玩家行為的方法
一種使用卷積神經網絡來預測斗地主游戲中玩家行為的方法
近年來,從圍棋到 Dota 團戰賽,深度神經網絡應用在各種游戲競賽中不斷取得突破。這一次,有人把這種方法用到斗地主游戲的研究中,可以說真的很接地氣了!
本論文是 ICLR 2019 的投稿論文,目前該論文還處于雙盲審狀態,因此也還未公布作者。營長在看到這篇論文的時候,就想第一時間分享給大家。接下來,我們就一起來看看這個有趣的研究吧!也預祝作者的論文能夠成功被接收,今后在這個項目上還可以再有進展!
摘要
近幾年,深度神經網絡在圍棋,國際象棋和日本象棋(Shogi)等多款游戲中都能夠擊敗人類。和這些棋類相比,中國的紙牌游戲“斗地主”也是非常出名!斗地主屬于非完整信息類的游戲即不知對方底牌,在游戲過程中包含隱藏信息,具有隨機性,并且多個玩家間存在合作與競爭關系。本文,我們將介紹一種使用卷積神經網絡(CNN)來預測斗地主游戲中玩家行為的方法,它是通過人類的游戲記錄來進行監督訓練。在沒有搜索情況下,此網絡就能以絕大優勢擊敗了性能最好的AI程序;在重復模式(Duplicate Mode)下也能戰勝了頂級的人類業余玩家。
簡介
斗地主(CCP)易于學習但想要擅長或精通卻是難事,它不僅需要數學知識和戰略性的思考,更需要玩家精心策劃每一步。游戲規則我們在這里就不多說了,主要說一下我們的研究思路和成果。
我們選擇 CNN來解決斗地主游戲問題的主要原因如下:
首先,CNN在完善的信息游戲中取得了超越人類的卓越表現
其次,在CCP中存在同一類別不同等級的兩套出牌方式(例如“34567”比“45678”等級來得低,等級低的不能壓等級高的。)
迄今為止,還沒有使用深度神經網絡來研究斗地主游戲的。該網絡是否能夠在游戲輸入信息不完善的情況下選擇合理的操作還有待證明。由于在每局游戲中有隊友的存在,這就出現了兩個問題:一是要教會該網絡進行合作;二是它要具備良好的推理能力。針對這些問題,我們設計了 DeepRocket,它是目前能夠在斗地主游戲中取得最好效果的一種網絡。在下面的實驗中,我們證明了該網絡可以在不完善的信息游戲中學會合作與推理。
Deep Rocket 框架
DeepRocket系統包含三個部分:叫地主模塊、策略網絡以及帶牌(Kicker)網絡。當游戲開始時叫地主模塊會被調用以便計算 DeepRocket的得分(叫地主和搶地主時分數會加倍)。在 DeepRocket出牌之前會先調用策略網絡,策略網絡會依據當前環境預測出最應該執行的策略,其中包括帶牌模式(帶單張或者一對)。當策略中含有帶牌時,Kicker 網路才會被調用。游戲流程如下圖1、2所示。
圖1 DeepRocket游戲流程
圖2 策略網絡和 Kicker 網絡的工作流程
▌叫地主模塊
在分完牌后需要先確定誰是地主,所以我們為此設計了一個基于邏輯代碼的叫地主模塊。叫地主的關鍵因素在于手牌的好壞。是否決定叫地主取決于手牌中是否有大牌(如:“A”、“2”以及大小王)和手牌順不順(有較少的雜牌)。
▌策略網絡
策略網絡采用監督學習的方式。其中該網絡包含 10 層 CNN 層和 1 層全連接層,激活函數采用 Relu。最終的 softmax層輸出所有合理出牌方式 a的概率分布。輸入為當前的游戲狀態。策略網絡的訓練樣本來自于隨機抽樣,這些樣本包含當前狀態以及最優的決策,采用隨機梯度上升的方式訓練網絡,讓策略網絡的出牌與人類的出牌越來越相近。
我們使用 800 萬條游戲記錄來訓練策略網絡,一條記錄代表一場完整的游戲,一局斗地主按回合來分,又能分為許多樣本。
策略網絡的輸入是一個 15×19×21 的三維二元張量。我們用 X、Y和 Z代表三個維度。其中 X代表牌的種類,從 3 到大小王。Y表示每個種類牌的數量(從 1 張到 4 張),以及 CCP中卡牌的組合如單張、對子等。Z代表每一輪的順序信息,作用是在游戲中將可變長度變換為固定長度,具體細節如表 1 所示。

表1 Z的含義
重復試驗之后發現,512 濾波器最為合適,10 層 CNN能使得模型獲得最佳的性能,其中每層都使用不同的步長。當我們將 Kicker網絡加到 DeepRocket中后,策略網絡會輸出 309 個決策的概率。具體的組合情況如表 2 所示。
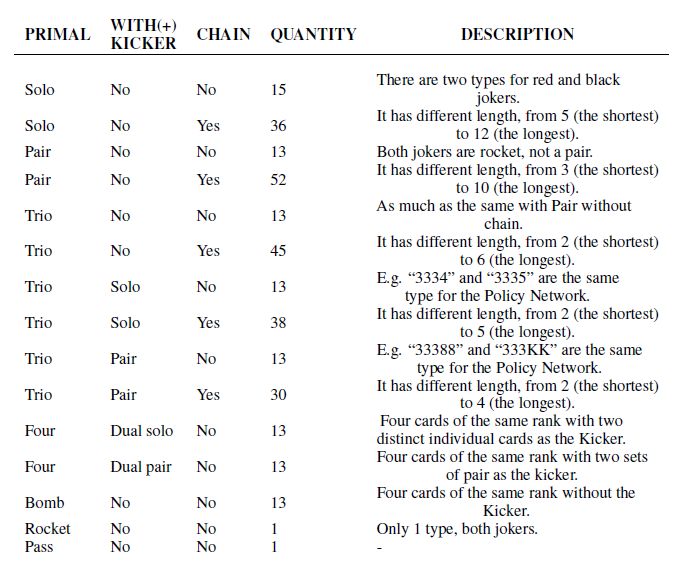
表2 組合類型
▌Kicker 網絡
僅憑叫地主模塊以及策略網絡就足以完成一場游戲,但決定帶牌的類型對游戲來說也至關重要。
我們將帶不同的牌標記為不同的策略。并額外建立了一個 Kicker網絡來預測所帶的牌。策略網絡負責預測 Main Group(如: 3334中的 3 個 3)和所帶牌的種類如單張或者對子。而 Kicker網絡則負責預測所帶的牌具體是哪幾張。
Kicker網絡的輸入包含剩余的牌以及策略網絡的輸出值,它由一個15×9×3的三維二元張量構成。其中 X的含義與策略網絡中相同,而 Y與 Z的含義如表所示。Kicker網絡包含 28 種輸出,其中 15 種為單牌,13 種為對子。
Kicker網絡由 5 層 CNN層和 1 層全連接層構成,輸出為帶牌的概率。Kicker網絡每次僅輸出一個帶牌種類。如果策略網絡預測應該出“333444”以及兩張單牌,這時則要調用兩次 Kicker網絡。
實驗
▌實驗設置
我們獲取了 800 萬條游戲記錄,首先將其劃分為 8000 萬個“狀態-行為”對,90%作為訓練數據集,10%作為測試數據集;然后將其作為網絡的輸入;最后使用 TFRecords 存儲到硬盤中;這樣不僅方便修改網絡參數,也加快了訓練速度。策略網絡的大小為 256,對人類專家的行為預測準確度可達 86%-88%。使用 i7-7900X CPU,NAVIDA 1080Ti GPU以及 Ubuntu 16.04的操作系統計算策略網絡的輸出需要 0.01-0.02 秒。
Kicker網絡同樣是監督式學習,也使用以上的 800 萬條游戲記錄作為數據集,但在訓練之后它能達到 90%的準確度,甚至比策略網絡更高。
▌與目前最好的 AI 對比
在 DeepRocket出現之前,MicroWe是最好的CCP AI。如圖 3 和圖 4 所示,我們進行了 50000 場游戲測試,每一次迭代表示 5000 場。我們將 20 張卡牌直接發給地主,這樣地主的勝率會比平常低。“DR VS MW”代表 DeepRocket是地主,而 MicroWe是農民。從圖中可看出 DR 表現比 MW好。
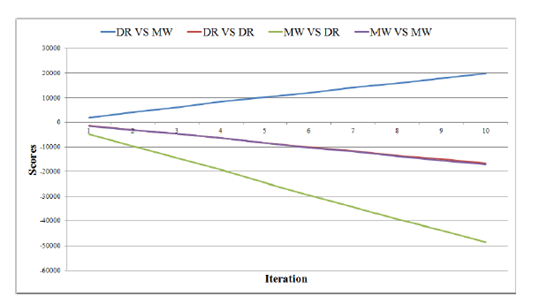
圖3 DR與 MW的比賽結果
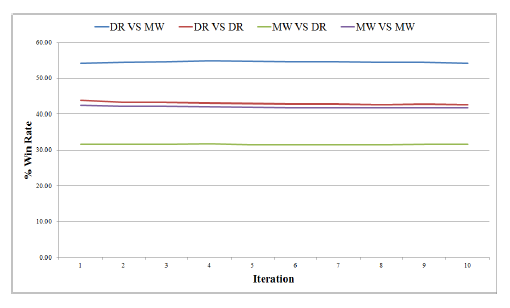
圖4不同 AI之間比賽的勝率
▌與人類專家對比
我們舉辦了一場人機比賽,邀請了四位頂級業余選手,在循環模式下進行了 10 場比賽。結果,DR以 30:24 的分數戰勝了人類團隊。
▌合作與推理
在 DR的游戲記錄中,我們找到了一個典型的例子能夠展現其良好的合作能力(T:10;B:大王;S:小王。其中冒號之前表示玩家,冒號后表示打出的牌,以分號作為某玩家出牌結束標志,0 代表地主)
牌面:
4456777889JKKAA2B;
335567899TTJJKAA2;
4456689TTJQQQK22S;
33Q;
游戲進程:
0,33;1,55;2,66;0,77;1,AA;1,6;2,T;0,J;1,K;0,2;2,S;2,44;0,KK;2,22;2,89TJQK;2,QQ;0,AA;0,56789;1,789TJ;1,3;2,5;
以上加粗部分是關鍵步驟,在游戲的最后 DR打出一張“3”來幫助隊友取得勝利,由此可見 DR具有良好合作能力的。
我們也找到了一個能夠展現 DR推理能力的例子:
牌面:
33345578TTJKKA22S;
34566789TQQQKKAA2;
4456678999TJJQA2B;
78J;
游戲進程:
0,345678;1,56789T;0,6789TJ;0,QQQKK;0,AA;2,22;2,55;2,3334;2,TT;2,A;0,2;
以上加粗部分是關鍵步驟,雖然最后農民輸了,但是他選擇打“A”是一個不錯的選擇,因為地主只剩一張牌,而農民手里還有 (“7, 8, J, A, S”)五張牌,選擇出“A”也是人類專家的正常邏輯,DR 能夠從人類中學到此行為。
展望
雖然,我們已經證明了 CNN能夠預測斗地主游戲中玩家的行為,并與隊友進行合作;在沒有任何的 MCTS之下能達到頂級選手的水平甚至更高。但是,我們也還有許多方面要進行完善。第一個是強化問題,直接將應用在 AlphaGo的方法移植到 CCP中是行不通的;第二個是關于 Monte Carlo搜索或者 MCTS的問題。
在未來,DR可以在以下方面進行改進:
叫地主的方式可以改進,在搶地主的過程中只有 0、1、2 和 3 是正確操作,0 代表玩家不想當地主。我們將嘗試用深度神經網絡去訓練叫地主的方式。
我們將嘗試使用隨機權重訓練模型。
我們將訓練分別代表三個角色的三個輸出模型。
最后預祝作者的論文被成功接收,今后在這個項目上還可以再有進展!
-
神經網絡
+關注
關注
42文章
4793瀏覽量
102043 -
數據集
+關注
關注
4文章
1218瀏覽量
25158
原文標題:來呀!AI喊你斗地主——首個搞定斗地主的深度神經網絡
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論