 工業大數據的范疇,為什么大數據上云要輕量化?
工業大數據的范疇,為什么大數據上云要輕量化?
一、工業大數據的范疇
工業大數據包括制造企業信息化數據、工業物聯網數據,以及外部跨界數據。信息化數據包括了ERP中的客戶訂單、生產計劃等信息,工業物聯網數據主要是從生產設備上采集到的各種產質耗數據和智能產品上獲得的運維數據,而外部跨界數據包括環境數據、市場數據和競品數據等,而其中從機器設備上得到的數據比重將越來越大。
工業大數據的特征除了大數據的4V(數據量大、類型多、價值密度低、速度快)以外,還有專業性、關聯性、和時序性特征。工業大數據應該注意特征背后的物理意義以及特征之間關聯性的機理邏輯,互聯網上的大數據可以只針對數據本身進行挖掘和關聯,而不考慮數據本身的意義,挖掘到什么結果就是什么結果。工業大數據的挖掘必須要有明確的挖掘目標,針對應用的功能在此基礎上逐步擴展挖掘的方向。
二、為什么大數據上云要輕量化?
制造企業在構建大數據分析系統時,除了采用傳統的自建數據中心架構以外,還可以采用數據存儲和分析構建在公有云平臺,采用離線訓練模型,結合邊緣計算在生產現場利用實時數據和已經訓練好的模型進行業務應用的兩級架構。
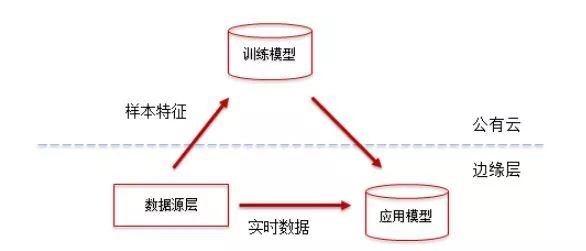
兩級架構的優點主要體現在以下四個方面:
1、降低存儲成本:從設備傳感器上采集的數據點往往是時序連續的過程量,隨著采集頻率的提高和周期延長,數據量是非常大的,如果考慮對海量的數據的存儲、備份和還原全生命周期的管理,往往在公有云上成本更低。
2、提高彈性:在公有云上處理大數據,空間和時間靈活性約高,對數據存儲和計算資源的要求會隨著項目時間越來越長而要求越來越高,而公有云基本能做到想什么時候要就什么時候要,想要多少就要多少。
3、提高容災性:傳統的數據中心的容災備份往往采用兩地三中心的方式,為保證7*24的系統高可用性對系統的要求高,而公有云的IaaS和PaaS的容災備份機制能實現低成本的低數據丟失率和更短恢復間隔。
4、數據共享更便利:企業應該把自身看成“大數據”價值鏈中的一部分,那么企業既是貢獻者也是受益者,工業大數據的價值可以共享給企業上下游使用, 采用統一的公有云平臺,促進數據資源的融會貫通,使得數據共享更方便。
大數據上云以后由于網絡帶寬的限制、對數據處理的時效性要求高、數據存儲成本以及模型訓練復雜程度多方面的原因,也要求在企業邊緣層對原始數據進行一些輕量化處理,在不損失大數據價值性的基礎上減少原始數據量。
三、輕量化的方法
輕量化是在不損失大數據價值性的基礎上減少網絡傳輸、存儲和訓練的數據量,并不是要剔除異常數據。在傳統的儀表數據采集的時候都有一個過濾異常數據的操作,會設定一定的閾值去除儀表讀數的異常跳變,而輕量化的方法不是采用這樣的方法去除異常數據,因為異常的數據有可能對業務分析是有價值的。輕量化的方法是在業務分析人員以價值需求為導向去發現數據和提取數據,主要是通過采樣中的特征選取和數據壓縮兩種方法。
特征選取是在可采集的樣本特征集合中選擇預測能力強的最佳子集,剔除重復,簡化多個特征之間的相互關聯。首先可以對多個特征做相關性分析,如果特征的相關性為1,表示兩個特征的變化是完全相同的,通過找出兩個特征的線性關系,能夠通過一個特征還原另外一個特征,一個簡單的例子如果產品的中文名稱要求是唯一的,那么這個產品的中文名稱和它的編碼相關性就是1,不存在多個編碼的產品取相同的名稱,那么在做數據采集、傳輸、存儲和訓練的時候只需要保留產品編碼,只需要在結果展示的時候通過對應表的方式找出產品名稱。如果在訓練樣本的時候對特征維度有明確的要求,也可以采用PCA方法對特征進行降維,PCA把原先的n個特征用數目更少的m個特征取代,從舊特征到新特征的映射捕獲數據中的固有變異性,盡量使新的m個特征互不相關。還有一些特征之間是有特殊規律可循,比如說某個機臺生產的班次和班組的關系是完全按照四班三運轉模式來排班,這個時候只需要確認班次就可以推導出執行班組信息,這樣的規則如果是固定不變的話,可以在模型訓練時候直接處理特征,而不需要另外做采集和儲存。
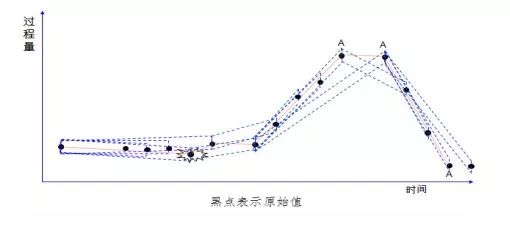
采用壓縮算法也是常用的輕量化手段,在帶有時間戳的時序性連續變量采集中,隨著采集頻率的提高數據量也成級數上升,可以通過偏差檢測處理和羅旋門壓縮過濾,既能反映數據實際趨勢,所需要采集、傳輸和保存的數據也顯著減少。 下面的三張圖簡單展示了數據壓縮的過程。
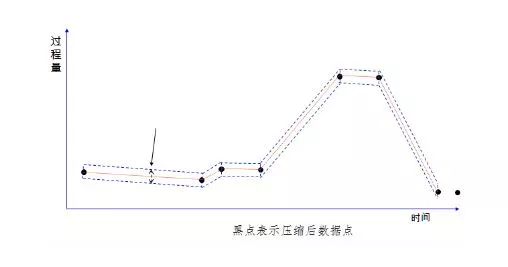
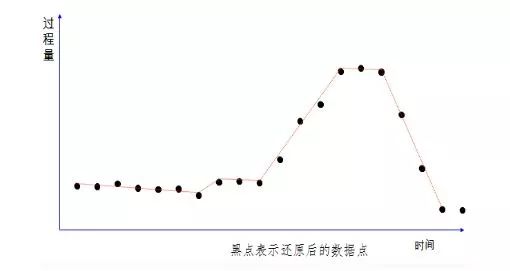
而自編碼神經網絡是結合了以上兩種方式,采用自編碼神經網絡既可以對特征維度進行降維,也會通過編碼方式對數據進行壓縮。自編碼神經網絡是一種無監督學習算法,它使用了反向傳播算法,并讓目標值等于輸入值,可以通過設定神經網絡的隱藏層節點數量來達到數據壓縮的目的。比如我們有100個輸入特征,可以設定隱藏層節點數量為50,最終輸出層還是還原100個輸入特征。模型訓練完成后,我們可以用模型的輸入層到隱藏層作為壓縮算法,把模型的隱藏層到輸出層作為解壓算法,這樣在邊緣層進行模型部署進行壓縮,在公有云利用模型進行解壓。自編碼神經網絡相對PCA來說可以更好的處理特征之間的非線性關系。
四、結語
在越來越多的制造業把大數據放在云端進行處理的時候,在網絡、存儲和計算能力有效的情況下,采用對數據進行壓縮和對數據特征進行選取的方法進行數據輕量化處理,以滿足數據業務分析需求和處理效率的高效。
-
傳感器
+關注
關注
2552文章
51228瀏覽量
754681 -
互聯網
+關注
關注
54文章
11167瀏覽量
103478 -
工業大數據
+關注
關注
0文章
72瀏覽量
7854
原文標題:企業實戰專家:工業大數據如何輕量化上云
文章出處:【微信號:IndustryIOT,微信公眾號:工業互聯網前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論