 攝像頭相關的人工智能研究成果
攝像頭相關的人工智能研究成果
本文來自馭勢科技人工智能組組長潘爭在LiveVideoStackCon 2017大會上的分享,并由LiveVideoStack整理而成。潘爭回顧了AI在圖像識別領域的歷史與難點,以及在安防和自動駕駛方面的實現思路。
谷歌的人工智能平臺Alpha Go讓AI再次進入了普通老百姓的視野,我記得2016年3月時Alpha Go第一輪測試結果就令大家十分震驚。隨著技術的進步,AI的能力一定會越來越強。我們可以看到近兩年AI在深度學習方面的技術進展成果顯著。今天我為大家準備了一些最近與攝像頭相關的人工智能研究成果。
概覽:
攝像頭里的數據寶藏
視覺識別的挑戰與應對
AI+安防實踐
AI+自動駕駛實踐

今天我的分享內容主要分為以下幾點:第一是我們生活中的這些攝像頭所采集的數據中隱藏了哪些值得挖掘的寶藏,以及如果要去挖掘有價值的數據需要面臨的一些挑戰與應對的方法;第二是我在安防與自動駕駛領域應用AI的一些實踐經驗。
1. 攝像頭里的數據寶藏
大家可以設想一下自己周圍有多少觀察我們的攝像頭,有我們隨身攜帶的手機、平板電腦等移動設備的前后攝像頭;如果你開車,你的車至少會有一兩個攝像頭;當你走在大街上或商場、超市里時,隨便一抬頭都能看到一個監控攝像頭。可以說我們的生活布滿了攝像頭,其中記錄了我們生活一點一滴的數據便具有了非凡價值。例如商場的管理人員可通過攝像頭判斷此時商場里有多少顧客,大致掌握顧客的男女比例,年齡層次,從而掌握潛在消費群體的實時動向;也可以通過攝像頭搜尋經常前來消費的顧客,并在正確的位置精準投放相應廣告吸引其消費從而增加銷售額。而在安防領域,警察可通過安裝在街道上的攝像頭監控預防群體事件的發生,迅速識別定位逃犯并掌握其逃跑路徑從而實現快速抓捕。還有在自動駕駛領域,通過汽車上集成的多部攝像頭獲取的數據可以告訴自動駕駛系統周圍汽車的數量、相對速度與距離等,也可識別車道線位置,推斷汽車是否偏離車道,并在需要變道或剎車時及時作出反應,保障自動駕駛系統的正常運行。從攝像頭中發掘有價值的數據并加以有效利用,無論對安防領域還是自動駕駛領域而言都非常重要。當然數據挖掘與處理的過程也充滿挑戰。
2. 視覺識別問題中的挑戰與應對
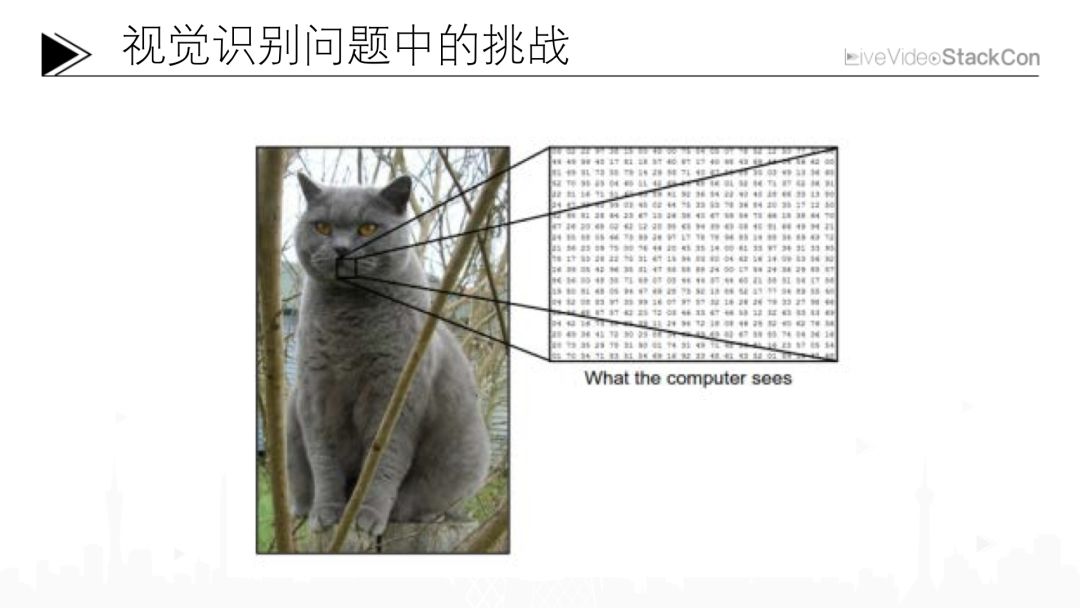
例如上面的這張圖,也許一個三歲的小孩也能夠識別出圖片中的物體是一只貓,而對計算機來說,這張圖可能只是一系列的數字。如果我們想通過這一系列的數字識別出這是一只貓則可能會遇到非常多的挑戰。
挑戰1:視角變化
而隨著視角的變化,例如上圖的同一張人臉會呈現出非常明顯的差異
挑戰2:光影變化
光影的變化同樣至關重要,由于光源位置的不同,同樣的幾只企鵝,有可能是全黑的,也有可能是全白的,這對視覺識別也非常具有挑戰性。
挑戰3:尺度變化
姚明與小孩雖存在明顯的尺度差異,但都屬于人類。視覺識別系統必須能夠對不同尺度的物體準確進行歸類。
挑戰4:形狀變化
處于不同形態的同一物體同樣是識別的難點,例如無論“大黃蜂”處于汽車形態還是機器人形態,視覺識別系統都應將其識別成“大黃蜂”。
挑戰5:遮擋變化
更大的挑戰在于很多視覺識別都需要面臨的遮擋變化,我們必須保證在復雜環境的遮擋下仍能夠準確識別圖片中的一匹馬與騎馬的人。
挑戰6:背景干擾
還需要解決的是背景干擾問題,我們可以輕易識別出上圖中的人與金錢豹,但對計算機而言,因為目標主體的紋理與背景幾乎難以分別,能夠準確識別出同樣結果的難度非常大。
挑戰7:類內差距
最后一項挑戰是類內差距,雖然都是椅子,但設計與用處的不同使其外觀差距非常大,而我們希望視覺識別算法都能將其識別為一張椅子。
如何有效解決視覺識別領域上述這么多挑戰?
2.1 深度學習——卷積神經網絡

如果讓大家完成這樣一個Python函數,輸入一張圖片的數據,輸出我們期望得到的圖片類型,該如何完成?其實這個問題已經困擾了計算機視覺科學家大概半個多世紀的時間,從計算機被發明開始大家就在思考這個問題,直到最近幾年才有了一個比較正式的回答,就是我們經常提到的深度學習,具體來說是一個多層卷積神經網絡。上圖展示了這樣一個卷積神經網絡的例子,在卷積神經網絡的左邊輸入的是一張圖像的數據,右邊輸出的是我們期待的圖像所屬類別。在這個網絡中我們可以看到每一個藍色的方框都代表一次卷積操作,之所以叫它多層卷積神經網絡就是因為一張圖片從輸入原始數據到輸出對應類別需要經過多次卷積操作,像這個網絡需要經過22層卷積才能準確識別出圖像所屬的類別屬性。每個卷積都會有一個卷積核,這個卷積核就是我們希望從海量數據中學習到的參數,學習不同的任務可以得出不同的參數。而這個學習訓練的算法一般是根據具體任務通過使用反向傳播算法進行精準識別并去學習出每一個卷積核的對應參數來。那么這樣一個卷積神經網絡可以達到怎樣的圖像識別性能呢?

這個問題也是在近幾年才有了一個比較好的回答,我給大家舉個例子: ImageNet比賽是一項解決通用圖像識別分類問題的比賽,通過統計計算機識別并歸類數據集中一千類圖片的錯誤率來衡量其視覺識別能力的高低。人如果參加ImageNet,錯誤率會保持在5.1%左右。而在深度學習面世之前的2011年,ImageNet冠軍的錯誤率可達到25.8%,但在2012深度學習面世以后,ImageNet冠軍的錯誤率一下降到了16.4%,并且從那之后一直處于直線下降的狀態,直到2015年的正確率已經下降到比人還低的3.57%。在人工智能的圍棋還未超越人類的2015年,計算機在通用圖像識別領域的性能已經超越了人類,能達到這樣的成績,卷積神經網絡功不可沒。
2.2 進一步發展的卷積神經網絡
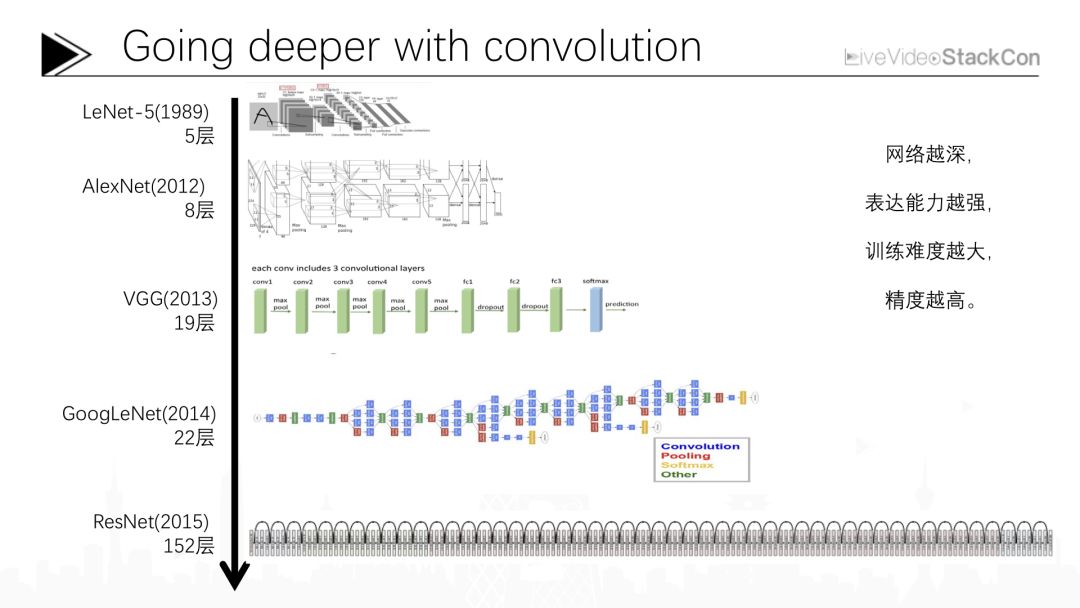
上圖是近幾年我們常用的深度卷積神經網絡的大概結構,深度卷積神經網絡最早是由Yann LeCun在1989年提出,當時是一個僅有5層的卷積神經網絡,現在Yann LeCun在Facebook的人工智能研究院作為主任繼續推進卷積神經網絡的研究。最初卷積神經網絡的層數非常的淺,僅有5層,并且那時只能完成一些手寫體方面的簡單識別任務。在那之后人們對卷積神經網絡的研究持續了二十多年,一直到2012年,人們才提出能夠勝任像ImageNet這樣復雜識別任務的更先進的卷積神經網絡。AlexNet在2012年借助這樣一個8層的卷積神經網絡網絡成為當年ImageNet比賽的冠軍,從那之后,又有很多不同的卷積神經網絡被研發出來,總的趨勢是越來越深。例如2013年達到19層的VGG、2014年Google提出的達到22層的GoogLeNet,而2015年微軟亞洲研究院研制的多達152層的卷積神經網絡ResNet其圖像識別性能已超越人類。從卷積神經網絡的發展我們不難看出,網絡越深其表達能力越強,卷積神經網絡所能表達的數學函數復雜程度就會越高,這就使其在處理復雜圖象識別任務時能夠達到更高的正確率。當然隨著網絡加深增多的是卷積盒的參數,對應計算量與深度學習的訓練難度也會增大,接下來我將講述近幾年大家在研究深度學習時面臨的三項核心問題以及提出的一些能夠解決相應問題的算法思想。
2.3 視覺問題的深度學習方法

之前提到的ImageNet比賽是一個通用的模擬圖像識別與分類的比賽,并不解決實際問題。與圍棋類似,并不能為我們創造任何經濟價值。如果想應用于實際中的視覺識別情景則還需解決以下幾大類問題:語義分割、物體檢測、對比驗證。
2.3.1 語義分割
圖像分類問題需要識別一張圖片并告訴我們這張圖片中物體的類別,簡而言之就是輸入一張圖片,給出一個類別。語義分割就是希望針對一張圖片中的每個像素都輸出一個類別,其中有很多解決方案,例如這幾年提出的FCN、Enet、PSPNet或ICnet等等。這些方法背后的基本框架都是全卷積網絡。這里的全卷積網絡與剛才提到的分類網絡唯一不同之處在于全卷積網絡并不只輸出一個分類標簽,而是輸出多個分類結果,每個分類結果都對應了圖像中的一個像素的類型值。訓練時會對每個像素分類的結果進行誤差計算,并用反向傳播算法得出訓練后的網絡參數。
2.3.2 物體檢測
初期的物體檢測準確率很低,無法滿足應用需求。近幾年隨著Faster RCNN、RFCN、SSD等方法的出現,物體檢測的準確率已經基本達到實際應用的需求。以上這些基于深度學習的物體檢測方法同樣使用全卷積網絡來預測出物體的每一個位置,在推斷出此區域是否屬于某個物體的同時對物體的類別、位置與大小進行預測。與之前的預測相比,物體檢測增加了位置與大小兩個預測維度。如果對這樣的預測的結果還不滿意的話也可像Faster RCNN這樣將相應區域的圖片或特性分離出并再過一次網絡進行第二次的分類與回歸,這種對目標的多重計算有助于提升輸出結果的準確性。目前最好的物體檢測方法就是類似于Faster RCNN這樣分兩階段的方法,如果大家想嘗試這種物體檢測方面的應用也可從此方法開始。
2.3.3 對比驗證
對比驗證簡單來說就是對兩個圖像進行對比并推斷這兩個圖像是否為同一個類別,最簡單的應用就是人臉識別。例如借助計算機將手機拍攝的一張人像照片與一張身份證上的照片進行對比并推斷是否為同一個人。這項技術在淘寶、支付寶等平臺都有應用,也可用與跟蹤和ReID等方面。這里的跟蹤是指用一個攝像頭拍攝連續多幀照片后,識別并鎖定第一幀里的某個物體,然后跟蹤后續幀中這個物體的移動軌跡。
如果這些用于跟蹤物體的圖片來自不同的攝像頭,那么這就變成了一個ReID問題。ReID在安防領域是一個非常重要的應用,例如一個小偷在A攝像頭下作案時被拍攝圖像后,我希望根據這張圖像在其他攝像頭中搜尋并鎖定這個小偷,以此來推測其作案移動的路徑,毫無疑問這會為警方的刑偵破案提供很大幫助。無論是人臉識別還是RelD,其技術背景都是Siamese network。
它的原理很簡單,就是將兩張圖片經過同一個網絡提取特征。在訓練此網絡時我們希望盡量縮小同一張人臉照片輸出結果的差距,擴大不同人臉照片輸出結果的差距。通過這種訓練方式能夠讓網絡學習到如何分析比對同一張人臉具有什么相似的特征,不同的人臉具有什么不同的特征。在人臉識別方面,計算機更早地超過人類。大概2013年在LFW人臉驗證比賽上,人類對于臉部的識別驗證準確率在97%左右,而計算機已可達到99%以上,這無疑是深度學習在人臉驗證領域的突破。
之前我與大家分享的都是一些籠統的方法,接下來我會結合過去我在安防與自動駕駛領域的工作經驗為大家介紹一些研究成果,
3. AI+安防
首先說一下安防,在安防領域有以下幾類大家比較關心的問題。第一個問題是通過攝像頭確認目標的位置也就是“人在哪里?”。知道人在哪里之后就需要明確目標屬性“你是誰?”、“你從哪里來?”、“你要到哪里去?”這些看似充滿哲學意味的問題同樣也是安防領域最重要的三個問題。回答這三個問題之后我們還希望確認目標的行為特征“人做了什么?”這對安防領域而言同樣重要。接下來讓我們看一下,如何解決這幾個問題。
3.1 “人在哪里?”
首先我們需要確認“人在哪里?”。安防領域中最基礎的便是對物體的檢測,例如上圖展示了一個在安防場景里進行人物檢測的實例。我們使用類似Faster RCNN技術對這樣一個安防場景中人的上半身進行檢測,檢測上半身主要是因為人最重要的特征集中在上半身,而下半身經常會被其他物體遮擋,同理上半身的特征暴露幾率更高,更容易進行特征識別。因為傳統Faster RCNN方法在識別速度上處于劣勢,所以我們對Faster RCNN進行了一些簡化,使其在識別速度上有了比較大的提升,并且能夠允許我們僅借助移動端GPU就可實現實時檢測的效果。
為了驗證此算法的運行極限,我們進行了一個規模更大的實驗。此實驗場景為北京站前廣場,這里人流密集,比一般的監控場景更復雜,我們想通過此實驗測試我們算法可同時檢測人數的極限。經過測試我們發現即便在如此大的場景之下算法依舊能夠較穩定地檢測出場景中中絕大多數行人,漏檢與誤檢幾率也維持在較低水平。我們在確認目標位置之后需要進一步確認目標的移動軌跡與行為動機。
3.2 “人從哪里來,到哪里去?”
上圖是一個較典型的物體跟蹤實驗情景,我們讓這些群眾演員隨機游走,通過深度學習方法對每個人的運動軌跡進行跟蹤。從左上角的圖中我們可以看到每個人身上都會有一個圈,如果圈的顏色沒有變化說明對這個人保持正常的跟蹤狀態。可以看到利用這種檢測跟蹤技術可穩定地跟蹤大部分目標。借助攝像頭輸出的深度圖,我們還可以如右下角圖片展示的那樣得出每個人在三維空間中的位置并變換視角進行監控,或是如在左下角圖片展示的那樣得到一個俯視的運行軌跡,這樣就可得知每個人在監控畫面當中的位置動態變化軌跡。
3.3 “這些人是誰?”
跟蹤上每一個人之后,更重要的是確認跟蹤目標的身份。安防領域的終極目標就是希望明確監控畫面中每個人的身份信息,而能從一個人的圖像中獲取到的最明顯的身份特征信息就是人臉。我開發了這樣一項技術——遠距離人臉識別。在上圖展示的大場景中我們可以看到其中大部分人離攝像頭的距離至少有30米~40米,在這樣一個遠距離監控場景下人臉采到的圖像質量會出現明顯的損失,例如人臉的位姿變化。我們希望借助在這樣一個不佳的監控場景中獲取的人臉圖片與人臉特征庫中的證件信息進行比對并獲取目標人物的身份信息,其原理也是剛才提到的Siamese Network——通過使用幾千萬甚至上億數據進行訓練,得出一個較為穩定的人臉特征并在人臉庫中檢索出符合此特征的目標人物身份信息,從而識別目標身份。
3.4 “這些人在干什么?”
安防領域最后關心的是目標的行為特征“這個人在干什么?”其本質是明確每個人的各個關節的運動狀態,我們稱之為POSE識別。雖然POSE識別看上去并不屬于檢測、跟蹤或是語義分割的范疇,但我們也可將其歸結為一種物體檢測,只不過我們檢測的不再是人的運動軌跡,而是檢測每個人的脖子、肩膀、肘關節等部分的相對位置,這與之前的物體檢測相比更為復雜。近幾年,借助深度學習技術,POSE識別取得了非常明顯的進步。微軟Xbox 360上配備的kinect便是通過可感知深度的攝像頭對一兩個人進行POSE識別而現在隨著技術的發展,即便僅通過普通的RGB攝像頭也能實現對整個廣場上多個目標同時進行POSE識別,這也是近幾年深度學習的一個重要突破。通過這種實時POSE識別我們不光可識別每個人在廣場中的位置、運動軌跡,還可識別每個人的動作以及動作背后隱藏的人與人之間的關系,從而在監控畫面中獲取更多有價值的信息。
4. AI+自動駕駛

之前我們講述了AI在安防監控領域的一些應用,接下來我會介紹一些最近正在嘗試的有關自動駕駛方面的實踐。其實在自動駕駛領域也需要很多攝像頭數據,我們會在自動駕駛汽車中安裝多個攝像頭。傳統汽車領域車身上的一兩個攝像頭主要用來拍攝汽車周圍的環境圖像,而在自動駕駛領域則需要更多的攝像頭完成更復雜的工作。例如特斯拉已經在其還無法完全實現自動駕駛的汽車上安裝了7個攝像頭;如果想要實現真正的自動駕駛,為了保證畫面的無死角需要安裝更多攝像頭,那么攝像頭采集的數據能夠幫助我們做什么呢?很多信息需要通過攝像頭獲取,例如車道線、前后左右有無行人與車輛等障礙物、紅綠燈識別、可行駛區域識別等都是來源于通過攝像捕獲的數據。
4.1 車道線識別
圖片中展示的車道線識別,也許大家曾在一些行車記錄儀或ADOS中見過。但有別于傳統對單車道線的簡單標記,我們現在更關注的是多車道線識別。以前的車道線識別僅是左右各一根,而我們希望能夠識別一整條馬路上的多根車道線。這種對于多根車道線的識別,一方面可為處于自動駕駛狀態下的車輛提供變道、駛出高速等路徑更改操作必要的數據,另一方面能夠協助汽車進行橫向定位。如果能夠同時識別出所有車道,自動駕駛系統就能確認汽車當前在第幾條車道上,從而計算下一步需要切換到哪一條車道,這對自動駕駛而言十分重要。檢測車道線可歸結為對物體的檢測,大家可以將每條車道線理解為一個物體。當然在面臨彎曲的車道線時還需要估計每條車道曲線的參數,需要更多的處理分析以更好地模擬車道線的變化。
4.2 行人與車輛檢測
除了車道線識別,另外一個比較重要的問題是對行人與車輛的實時檢測。這是安全性上十分重要的兩項指標,需要知曉周圍車輛的位置、距離和速度才能獲取決策所需要的參數。上圖是我們在北京四環這樣相對簡單的封閉道路環境下進行的車輛檢測實驗。檢測車輛的算法與我們之前提到的在安防領域里檢測人的算法類似,都是基于Faster RCNN架構,但自動駕駛領域對計算能力的要求更高。因為汽車的安全永遠擺在第一位,并且經過每一步計算更新出的行駛策略必須符合道路交通安全法規,而我們日常生活中使用的GPU遠無法達到如此嚴格的性能要求。因此我們需要花很多的時間將神經網絡盡可能精簡與壓縮以實現更快的運行速度,從而能夠在有限的硬件性能下滿足對行人與車輛的實時監測要求。
我們還在更復雜的道路環境下測試了檢測算法。上圖是一個人車混行的道路環境,難點一主要在于大量汽車造成的遮擋問題,難點二主要在于身著各色服飾的群眾,這種道路環境無論是對人還是對車輛的檢測而言都是一個非常大的挑戰。當然在如此復雜的環境下我們現有的算法仍會出現一些錯誤,這還需要我們積累更多的數據與改進方案以實現進一步的提升,讓我們的自動駕駛系統能夠通過視覺層面上的識別保證在如此復雜人車混行道路環境下駕駛過程的安全性。
4.3 紅綠燈識別
視覺識別還可幫助我們識別紅綠燈的狀態,同樣是一個比較標準的物體檢測問題。但紅綠燈檢測與之前提到的行人與車輛檢測相比,困難之處在于紅綠燈在圖像中是一個非常小的物體,越小的物體檢測難度越大。為了解決此問題我們提高了標準檢測方法輸出的圖像分辨率,提升最后一層深度學習網絡對細小的物體的檢測敏感度。
這樣便可幫助我們對紅綠燈等小物體實現更準確的檢測。上圖是我們在五道口附近一個道路環境比較復雜的路段測試紅綠燈檢測算法的準確性,可以看到雖然這段路上有很多紅綠燈,但基本上大部分的紅綠燈都可以被準確檢測到。當然紅綠燈不一定需要通過視覺識別進行檢測,有時我們可以結合一些地圖信息進一步提高紅綠燈檢測結果的準確性,盡可能降低依賴純視覺圖像信息進行紅綠燈檢測時出現錯誤的概率。
4.4 可行駛區域識別
對自動駕駛系統而言最后一個關鍵問題是明確汽車的可行駛區域。所謂可行使區域就是理論上路面沒有障礙物,允許汽車安全通過的區域,那么確定汽車可行駛區域的關鍵點就是確定路面上的障礙物,那么如何識別道路上的障礙物呢?障礙物的種類有很多,故我們通過另一種思路來解決這個問題,也就是對可行使區域進行分割,這就使命題變為一個比較標準的圖像語義分割問題。上圖是我們在北京五環路上進行的測試,可以看到道路中的紫色部分為可行駛區域。
在這種封閉環路上測試此技術的效果往往是比較穩定的,但距離將其推廣并應用于類似人車混行等復雜道路環境還很遠,需要積累更多數據才能進一步提高精度滿足道路安全駕駛的需求。同時除了識別可行使區域,大家可以看到圖像中的高亮部分展示的是車道線、交通標識等必要的目標識別。這些識別在為自動駕駛安全穩定運行提供必要的駕駛輔助信息的同時也為深度學習在準確預測可行使區域和監測車輛行人等方面提供了必要的參考數據。
這便意味著這樣一個多任務網絡需要利用有限的計算資源更加迅速地完成多個駕駛行為監測任務,從而在出現行駛突發狀況時更快作出反應與干預,保證人車安全。而在深度學習領域,同時訓練兩個任務相對于單獨訓練一個任務所達成的效果更好。
-
攝像頭
+關注
關注
60文章
4851瀏覽量
95924 -
人工智能
+關注
關注
1792文章
47442瀏覽量
239016 -
自動駕駛
+關注
關注
784文章
13877瀏覽量
166618
原文標題:隱藏在攝像頭里的AI
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌推出用于自拍攝像頭的防臉部失真算法
蘋果變了,竟然允許對外公布人工智能研究成果
百度人工智能大神離職,人工智能的出路在哪?
人工智能就業前景
人工智能的影響超乎你想象
解讀人工智能的未來
人工智能醫生未來或上線,人工智能醫療市場規模持續增長
【HarmonyOS HiSpark AI Camera】智能小車+智能攝像頭
基于Movidius Myriad 2的人臉識別攝像頭解決方案
路徑規劃用到的人工智能技術
人工智能分類垃圾桶原理
人工智能芯片是人工智能發展的
物聯網人工智能是什么?
重塑未來地圖行業的秘密武器:攝像頭+人工智能
dfrobotHUSKYLENS 人工智能攝像頭簡介






 工商網監
工商網監
評論