
本文由前向啟創(chuàng)&CTO張暉介紹了前向啟創(chuàng)在TI TDA芯片上,使用深度學(xué)習(xí)方法,解決智能駕駛感知問(wèn)題的一些經(jīng)驗(yàn)。
深度學(xué)習(xí)以其強(qiáng)大的特征表示能力,已經(jīng)在許多應(yīng)用領(lǐng)域中體現(xiàn)出了不俗的性能。而針對(duì)智能駕駛應(yīng)用,深度學(xué)習(xí)應(yīng)該如何落地呢?
前向啟創(chuàng)&CTO張暉認(rèn)為,主要存在有兩大技術(shù)挑戰(zhàn):一是主芯片的選型,二則是針對(duì)特定芯片的深度學(xué)習(xí)算法的設(shè)計(jì)與實(shí)現(xiàn)。
前向啟創(chuàng)&CTO張暉,2004年畢業(yè)于華中科技大學(xué),獲雙學(xué)士學(xué)位;2004-2005年就職于美國(guó)安凱微電子,任算法工程師;005-2013年就職于美國(guó)ZORAN(CSR/Qualcomm)公司,任算法研發(fā)經(jīng)理;近15年算法芯片化與產(chǎn)品化經(jīng)驗(yàn);在ACCV、ICPR等國(guó)際會(huì)議上發(fā)表學(xué)術(shù)論文多篇;擁有多項(xiàng)中美發(fā)明專(zhuān)利。
TI智能駕駛ASIC
針對(duì)智能駕駛產(chǎn)品主處理器芯片進(jìn)行選型,應(yīng)該將汽車(chē)智能駕駛產(chǎn)品的主要訴求——高可靠性與低成本,作為主要參考依據(jù)。
從業(yè)界角度來(lái)看,智能駕駛主芯片可分兩大流派,一派為ASIC,將特定的算法計(jì)算引擎芯片化,代表企業(yè)有如TI、Mobileye、nVidia、Ambarella等;另一派則為FPGA,代表企業(yè)有如Xilinx,Altera等。
而ASIC以其定制性,在成本、功耗、算力、彈性、車(chē)規(guī)、功能安全等級(jí)以及量產(chǎn)周期上達(dá)到了更好的平衡。
TI(Texas Instuments)自2010年起開(kāi)始提供針對(duì)智能駕駛的ASIC芯片TDA(TIDriverAssist)系列,至今已經(jīng)迭代到了第四代。
經(jīng)過(guò)多年的演進(jìn),TI已經(jīng)將多項(xiàng)針對(duì)智能駕駛的算法逐步芯片化、引擎化,其功能安全等級(jí),也達(dá)到了ASIL-C級(jí)。
TI的ASIC芯片TDA(TIDriverAssist)系列
TI的智能駕駛芯片以其優(yōu)異的性價(jià)比,已被全球超過(guò)15家Tier1、25家OEM主機(jī)廠所采用,成功在近100款車(chē)型中量產(chǎn),已累積出貨近4千萬(wàn)片。目前前向啟創(chuàng)也采用TI ASIC芯片。
深度網(wǎng)絡(luò)設(shè)計(jì)
網(wǎng)絡(luò)模型設(shè)計(jì)是深度學(xué)習(xí)應(yīng)用的關(guān)鍵,如何設(shè)計(jì)一個(gè)能滿足產(chǎn)品化要求的智能駕駛感知網(wǎng)絡(luò)呢?
張暉認(rèn)為,主要存在著兩大關(guān)鍵點(diǎn),第一需要貼近任務(wù)和系統(tǒng)需求,即必須針對(duì)智能駕駛系統(tǒng)應(yīng)用對(duì)感知層的需求來(lái)進(jìn)行網(wǎng)絡(luò)設(shè)計(jì),切不可為了使用深度學(xué)習(xí)而選擇深度神經(jīng)網(wǎng)絡(luò);
第二需要考慮到芯片嵌入式平臺(tái)算力受限系統(tǒng),必須因芯設(shè)計(jì),切不可盲目的進(jìn)行網(wǎng)絡(luò)堆砌,導(dǎo)致運(yùn)算量過(guò)大,而造成無(wú)法部署到芯片上的問(wèn)題。
從智能駕駛的任務(wù)來(lái)看,Level2–Level3系統(tǒng)對(duì)感知提出了更高的要求,例如AEB-Cross需要檢測(cè)車(chē)輛側(cè)面狀態(tài),TJA(TrafficJamAssistance)更需要識(shí)別出可通行區(qū)域,即FreeSpace,等等。
針對(duì)車(chē)輛側(cè)面檢測(cè),前向啟創(chuàng)重新設(shè)計(jì)了一套FINet網(wǎng)絡(luò),將傳統(tǒng)的2D-BoundingBox擴(kuò)展到了3D-BoundingBox,可以對(duì)車(chē)輛的多個(gè)表面進(jìn)行檢測(cè)。
前向啟創(chuàng)針對(duì)車(chē)輛側(cè)面檢測(cè)設(shè)計(jì)的FINet網(wǎng)絡(luò)
而針對(duì)FreeSpace任務(wù),前向啟創(chuàng)重新設(shè)計(jì)了的FINet可將此任務(wù)分解為,對(duì)Flat平坦可通行區(qū)域;Step路沿臺(tái)階;以及Obstacle障礙物三大類(lèi)目標(biāo)進(jìn)行分割。
前向啟創(chuàng)針對(duì)FreeSpace任務(wù),F(xiàn)INet分解為三大類(lèi)目標(biāo)
深度網(wǎng)絡(luò)優(yōu)化
常見(jiàn)的深度學(xué)習(xí)網(wǎng)絡(luò)都對(duì)主芯片的算力提出了比較高的要求。
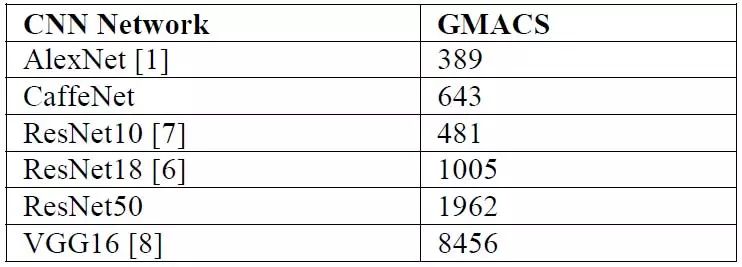
常見(jiàn)網(wǎng)絡(luò)在對(duì)720P@30fps圖像進(jìn)行推理時(shí),對(duì)算力的要求
由上圖可看出,大部分網(wǎng)絡(luò)對(duì)算力的要求超過(guò)了1Tops,而類(lèi)似TITDA2x這類(lèi)低功耗芯片目前達(dá)不到1Tops算力要求。所以在網(wǎng)絡(luò)基礎(chǔ)模型設(shè)計(jì)好后,為了大幅降低模型的GMACS以適應(yīng)算力受限的芯片平臺(tái),就需要針對(duì)芯片進(jìn)行網(wǎng)絡(luò)的細(xì)調(diào)整(FineTuning)及優(yōu)化。
針對(duì)TIASIC的芯片架構(gòu),前向啟創(chuàng)主要采用了兩大方法進(jìn)行網(wǎng)絡(luò)優(yōu)化,第一卷積稀疏化,第二8-BIT量化技術(shù)。
第一,卷積稀疏化方法是通過(guò)調(diào)整損失函數(shù),對(duì)權(quán)重小于動(dòng)態(tài)閾值的卷積核中的系數(shù)進(jìn)行歸零處理,再將此稀疏度的張量重新進(jìn)行調(diào)優(yōu)訓(xùn)練,對(duì)已歸零處理后的系數(shù)不再進(jìn)行反向傳播更新,最后以達(dá)到在保證稀疏度的情況下,訓(xùn)練精度沒(méi)有明顯的下降。
兩種不同稀疏度的目標(biāo)函數(shù)下,通過(guò)調(diào)優(yōu)訓(xùn)練出來(lái)的濾波器的核
第二,動(dòng)態(tài)8-BIT量化技術(shù),動(dòng)態(tài)指的是在8-BIT的最大位寬的前提下,盡量高地提高張量的量化精度,即有符號(hào)與否,定標(biāo)值是多少,都隨張量的范圍而進(jìn)行動(dòng)態(tài)調(diào)整。
在完成以上兩步優(yōu)化后,前向啟創(chuàng)的FINet網(wǎng)絡(luò)在精度下降不到1%的情況下,整體提速了近10倍。
芯片級(jí)部署與實(shí)現(xiàn)
針對(duì)智能駕駛應(yīng)用,TI的TDA系列芯片采用了多核異構(gòu)的芯片架構(gòu)來(lái)達(dá)到算力與功耗平衡,而其中的子處理器是可配置的,如DSP和EVE等子處理器單元數(shù)可以選擇,以求針對(duì)系統(tǒng)要求,達(dá)到更合適的性價(jià)比。
整體芯片架構(gòu)如圖所示
多核異構(gòu)架構(gòu)的最大優(yōu)點(diǎn)就是能夠?qū)⒉煌?lèi)型的計(jì)算或控制任務(wù)異核化,TITDA系列芯片的設(shè)計(jì)初衷中,視覺(jué)感知的中低層計(jì)算任務(wù)主要被集中到了DSP和EVE這兩類(lèi)子處理器上:
TITDA系列芯片的設(shè)計(jì)
EVE作為T(mén)I針對(duì)智能駕駛應(yīng)用而專(zhuān)門(mén)設(shè)計(jì)的向量硬件加速器,在同等功耗下,相比于現(xiàn)有其它智能駕駛芯片,每個(gè)EVE核能夠達(dá)到8倍的計(jì)算性能的提升。
每個(gè)EVE核能夠達(dá)到8倍的計(jì)算性能的提升
針對(duì)深度神經(jīng)網(wǎng)絡(luò)中最耗時(shí)的卷積運(yùn)算部分,在部署階段,前向啟創(chuàng)主要使用了其中的EVE核來(lái)進(jìn)行計(jì)算,利用EVE中的SIMD特性,可以將FINet中的卷積運(yùn)算部分提速8倍左右。
完成在TI芯片上的部署后,前向啟創(chuàng)FINet網(wǎng)絡(luò)整體上能夠達(dá)到實(shí)時(shí)感知的系統(tǒng)性能要求。
在TITDA這類(lèi)成熟的ASIC上,通過(guò)網(wǎng)絡(luò)設(shè)計(jì)、網(wǎng)絡(luò)優(yōu)化以及芯片部署這三大步,就能基本實(shí)現(xiàn)深度神經(jīng)網(wǎng)絡(luò)的初步框架。
在后續(xù)的產(chǎn)品化過(guò)程中,還需根據(jù)實(shí)際的系統(tǒng)需求,對(duì)這三步進(jìn)行閉環(huán)式的迭代,以求達(dá)到系統(tǒng)性能與算力的最佳平衡。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4789瀏覽量
101902 -
智能駕駛
+關(guān)注
關(guān)注
4文章
2682瀏覽量
49348 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5531瀏覽量
122113
原文標(biāo)題:智能駕駛感知產(chǎn)品化:基于TI ASIC深度神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)與實(shí)現(xiàn) | GGAI經(jīng)驗(yàn)談
文章出處:【微信號(hào):ilove-ev,微信公眾號(hào):高工智能汽車(chē)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Nanopi深度學(xué)習(xí)之路(1)深度學(xué)習(xí)框架分析
百度深度學(xué)習(xí)研究院科學(xué)家深度講解人工智能
華為云深度學(xué)習(xí)服務(wù),讓企業(yè)智能從此不求人
硅谷組建團(tuán)隊(duì)、L3產(chǎn)品落地,想法多多的騰訊自動(dòng)駕駛
人工智能、數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的關(guān)系
深度學(xué)習(xí)是什么
智能駕駛的狂想與現(xiàn)實(shí)落地 精選資料分享
智能駕駛域控制器的SoC芯片選型
人工智能深度學(xué)習(xí)未來(lái)應(yīng)該如何發(fā)展的詳細(xì)概述
探討深度學(xué)習(xí)在自動(dòng)駕駛中的應(yīng)用
基于魔視智能先進(jìn)的嵌入式深度學(xué)習(xí)技術(shù)的輔助自動(dòng)駕駛產(chǎn)品正式量產(chǎn)落地
深度學(xué)習(xí)技術(shù)與自動(dòng)駕駛設(shè)計(jì)的結(jié)合





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論