") BatchNorm是一種旨在通過固定層輸入的分布來改善神經網絡訓練的技術
BatchNorm是一種旨在通過固定層輸入的分布來改善神經網絡訓練的技術
由于BatchNorm可以加速訓練并獲得更加穩(wěn)定的結果,近年來成為了一項在深度學習優(yōu)化過程中被廣泛使用的技巧。但目前人們對于它是如何在優(yōu)化過程中起作用的還沒有達成共識。MIT的研究人員從優(yōu)化過程中對應空間的平滑性這一角度為我們帶來的全新的視角。

在過去的十年中,深度學習在計算機視覺、語音識別、機器翻譯和游戲博弈等眾所周知的各種艱巨任務中都取得了令人矚目的進步。這些進步離不開硬件、數據集、算法以及網絡結構等方面重大進展,批標準化/規(guī)范化(Batch Normalization,簡稱BatchNorm)的提出更是為深度學習的發(fā)展作出了巨大貢獻。BatchNorm是一種旨在通過固定層輸入的分布來改善神經網絡訓練的技術,它通過引入一個附加網絡來控制這些分布的均值和方差。BatchNorm可以實現深度神經網絡更快更穩(wěn)定的訓練,到目前為止,無論是在學術研究中(超過4,000次引用)還是實際應用配置中,它在大多數深度學習模型中都默認使用。
盡管BatchNorm目前被廣泛采用,但究竟是什么原因導致了它這么有效,尚不明確。實際上,現在也有一些工作提供了BatchNorm的替代方法,但它們似乎沒有讓我們更好地深入理解該問題。目前,對BatchNorm的成功以及其最初動機的最廣泛接受的解釋是,這種有效性源于在訓練過程中控制每層輸入數據分布的變化以減少所謂的“Internal Covariate Shift”。那什么是Internal Covariate Shift呢,可以理解為在神經網絡的訓練過程中,由于參數改變,而引起層輸入分布的變化。研究人員們推測,這種持續(xù)的變化會對訓練造成負面影響,而BatchNorm恰好減少了Internal Covariate Shift,從而彌補這種影響。
雖然這種解釋現在被廣泛接受,但似乎仍未出現支持的具體證據。尤其是,我們仍不能理解Internal Covariate Shift和訓練性能之間的聯系。在本文中,作者證明了BatchNorm帶來的性能增益與Internal Covariate Shift無關,在某種意義上BatchNorm甚至可能不會減少Internal Covariate Shift。相反,作者發(fā)現了BatchNorm對訓練過程有著更根本的影響:它能使優(yōu)化問題的解空間更加平滑,而這種平滑性確保了梯度更具預測性和穩(wěn)定性,因此可以使用更大范圍的學習速率并獲得更快的網絡收斂。
作者證明了在一般條件下,在具有BatchNorm的模型中損失函數和梯度的Lipschitzness(也稱為β-smoothness)得到了改善。最后,作者還發(fā)現這種平滑效果并非與BatchNorm唯一相關,許多其他的正則化技術也具有類似的效果,甚至有時效果更強,都能對訓練性能提供類似的效果改善。
研究人員表示深入理解BatchNorm這一基本概念的根源有助于我們更好地掌握神經網絡訓練潛在的復雜性,反過來,也能促進廣大學者們在此基礎上進一步地研究深度學習算法。
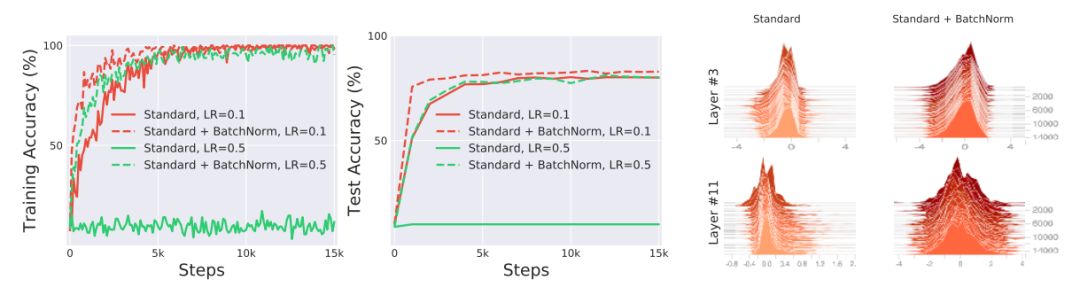
作者探討了BatchNorm,優(yōu)化和Internal Covariate Shift三者之間的關系。作者在CIFAR-10數據集上分別使用和不使用BatchNorm來訓練標準的VGG網絡,如上圖顯示用BatchNorm訓練的網絡在優(yōu)化和泛化性能方面都有著顯著改進。但是,從上圖最右側我們發(fā)現在有和沒有BatchNorm的網絡中,分布(均值和方差的變化)的差異似乎是微乎其微的。那么,由此引發(fā)以下的問題:
1)BatchNorm的有效性是否確實與Internal Covariate Shift有關?
2)BatchNorm固定層輸入的分布是否能夠有效減少Internal Covariate Shift?
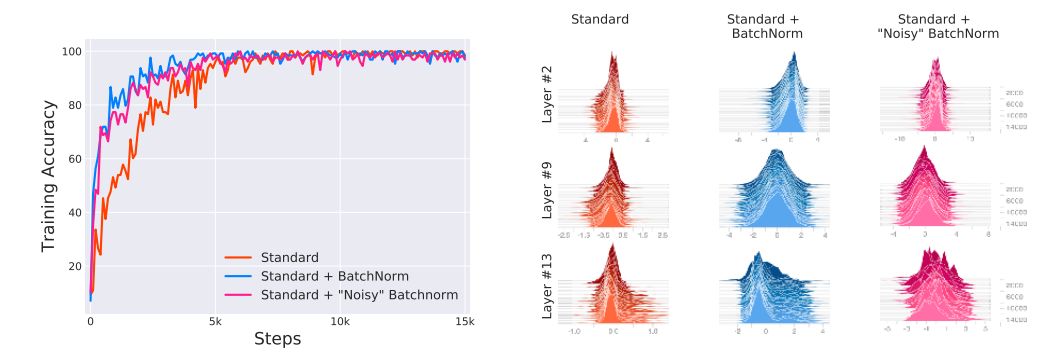
首先我們訓練網絡時,刻意在BatchNorm層后注入隨機噪聲,由此產生明顯的covariate shift。因此,層中的每個單元都會在各個時刻經歷不同的輸入分布。然后,我們測量這種引入的分布不穩(wěn)定性對BatchNorm性能的影響。下圖顯示了標準網絡、加上BatchNorm層的網絡以及在BatchNorm層后加噪聲的網絡的訓練結果。我們發(fā)現,后兩者的性能差異可以忽略,并且都比標準網絡要好。在標準網絡中加BatchNorm之后,即便噪聲的引入使得分布不穩(wěn)定,但在訓練性能仍比標準網絡好。所以,BatchNorm的有效性與Internal Covariate Shift并沒有什么聯系。
僅從輸入分布的均值和方差來看,Internal Covariate Shift似乎與訓練性能并沒有直接聯系,那么從更廣泛的概念上理解,Internal Covariate Shift是否與訓練性能有著直接的聯系呢?如果有,BatchNorm是否真的有效減少了Internal Covariate Shift。把每層看作是求解經驗風險最小化的問題,在給定一組輸入并優(yōu)化損失函數,但對任何先前層的參數進行更新必將改變后面層的輸入,這是Ioffe和Szegedy等研究人員關于Internal Covariate Shift理解的核心。此處,作者更從底層的優(yōu)化任務角度深入探究,由于訓練過程是一階方法,因此將損失的梯度作為研究對象。
為了量化每層中參數必須根據先前層中參數更新“調整”的程度,我們分別測量更新前和更新后每層梯度的變化。作者通過實驗測量了帶有和不帶BatchNorm層的Internal Covariate Shift程度。為分離非線性效應和梯度隨機性,作者還對使用全批梯度下降訓練的(25層)深度線性網絡(DLN)進行分析。最終,我們發(fā)現,在網絡中添加BatchNorm層應該是增加了更新前和更新后層梯度之間的相關性,從而減少Internal Covariate Shift。但令人驚訝的是,我們觀察到使用BatchNorm的網絡經常表現出Internal Covariate Shift的增加(參見下圖),DLN尤其顯著。從優(yōu)化的角度來看,BatchNorm可能甚至不會減少Internal Covariate Shift。
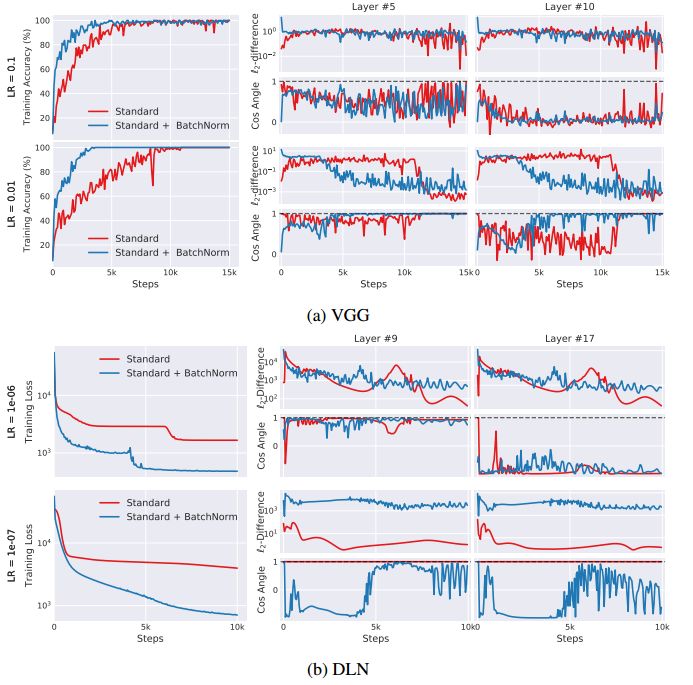
圖中藍色線為添加了BatchNorm的結果,右側描述了對應Internal covariate shift的變化。
那BatchNorm究竟發(fā)揮了什么作用呢?
事實上,我們確定了BatchNorm對訓練過程的關鍵影響:它對底層優(yōu)化問題再參數化,使其解空間更加平滑。首先,損失函數的Lipschitzness得到改進,即損失函數能以較小的速率變化,梯度的幅度也變小。然而效果更強,即BatchNorm的再參數化使損失函數的梯度更加Lipschitz,就有著更加“有效”的β-smoothness。這些平滑效果對訓練算法的性能起到主要的影響。改進梯度的Lipschitzness使我們確信,當我們在計算梯度的方向上采取更大步長時,此梯度方向在之后仍是對實際梯度方向的精準估計。
因此,它能使任何基于梯度的訓練算法采取更大的步長之后,防止損失函數的解空間突變,既不會掉入梯度消失的平坦區(qū)域,也不會掉入梯度爆炸的尖銳局部最小值。這也就使得我們能夠用更大的學習速率,并且通常會使得訓練速度更快而對超參數的選擇更不敏感。因此,是BatchNorm的平滑效果提高了訓練性能。
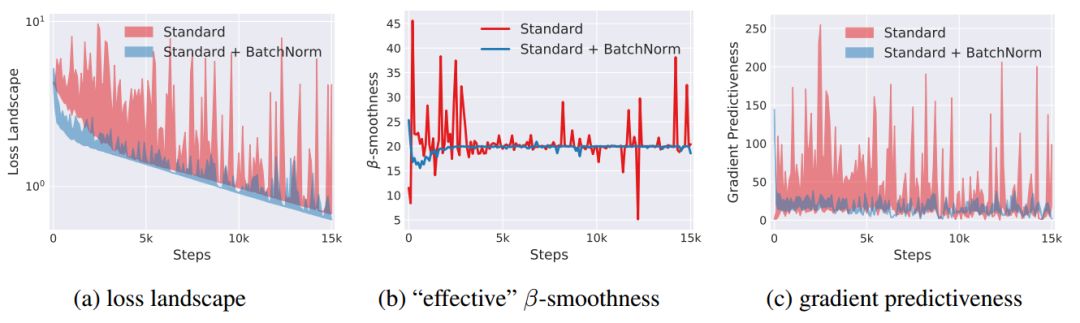
為了證明BatchNorm對損失函數穩(wěn)定性的影響,即Lipschitzness,對訓練過程中每步,我們計算損失函數的梯度,并測量當我們朝梯度方向移動時損失函數如何變化。見下圖中(a),我們看到,與用BatchNorm的情況相反,vanilla網絡的損失函數的確有著大幅波動,特別是在訓練的初始階段。同樣為了證明BatchNorm對損失函數的梯度穩(wěn)定性/ Lipschitzness影響,我們在下圖中(b)繪制了vanilla網絡和BatchNorm 整個訓練過程中的“有效”β-smoothness(“有效”在這里指,朝梯度方向移動時測量梯度的變化),結果差異性很大。
為了進一步說明梯度穩(wěn)定性和預測性的增加,我們測量在訓練給定點處的損失梯度與沿著原始梯度方向的不同點對應的梯度之間的L2距離。如下圖中(c)顯示了vanilla網絡和BatchNorm網絡之間的這種梯度預測中的顯著差異(接近兩個數量級)。我們還考察了線性深度網絡,BatchNorm也有著很好的平滑效果。要強調的是,即使我們值集中探索了沿著梯度方向的損失解空間情況,對于其他任意方向,也有一致的結論。
文中從理論上論證了增加BatchNorm可以降低參數的靈敏度,并很好的改善優(yōu)化問題的解空間。

不同norm下VGG網絡的激活直方圖
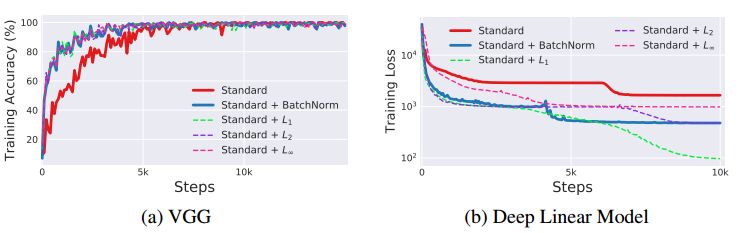
那么BatchNorm是平滑解空間最好且唯一的方法嗎?答案當然不是,作者研究了一些基于自然數據統(tǒng)計的正則化策略,類似BatchNorm修正激活函數一階矩的方案,用p范數均值進行正則化。不同的是,對于這些正則化方案,層輸入的分布不再是高斯(見上圖)。因此,用這種p范數進行正則化并不能保證對分布矩和分布穩(wěn)定性有任何控制。實驗結果如下圖所示,可以觀察到所有的正則化方法都提供了與BatchNorm相媲美的性能。事實上,對于深度線性網絡來說,'L1正則化表現的要比BatchNorm更好。
值得注意的是,p范數正則化方法會導致更大的分布covariate shift。但所有這些技術都提高了解空間的平滑度,這點與BatchNorm的效果相似。以上表明BatchNorm對訓練的積極影響可能實屬偶然。因此,對類似的正則化方案的設計進行深入探索十分有必要,可以為網絡訓練更好的性能。
綜上所述,作者研究了BatchNorm能提高深度神經網絡訓練有效性的根源,并發(fā)現BatchNorm與internal covariate shift之間的關系是微不足道的。特別是,從優(yōu)化的角度來看,BatchNorm并不會減少internal covariate shift。相反,BatchNorm對訓練過程的關鍵作用在于其重新規(guī)劃了優(yōu)化問題,使其Lipschitzness穩(wěn)定和β-smoothness更有效,這意味著訓練中使用的梯度更具有良好的預測性和性能,從而可以更快速、有效地進行優(yōu)化。
這種現象同時也解釋了先前觀察到的BatchNorm的其他優(yōu)點,例如對超參數設置的魯棒性以及避免梯度爆炸或消失。作者也展示了這種平滑效果并不是BatchNorm特有的,其他一些自然正則化策略也具有相似的效果,并能帶來可比較的性能增益。我們相信這些新發(fā)現不僅可以消除關于BatchNorm的一些常見誤解,而且還會使我們在真正意義上理解這種基本技術以及更加好的處理深度網絡的訓練問題。
最后,作者表明雖然重點在于揭示BatchNorm對訓練的影響,但其發(fā)現也可能揭示BatchNorm對泛化能力的改進。具體來說,BatchNorm重新參數化的平滑效應可能會促使訓練過程收斂到更平坦的極小值,相信這樣的極小值會促進更好的泛化。
-
神經網絡
+關注
關注
42文章
4774瀏覽量
100904 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
46033 -
深度學習
+關注
關注
73文章
5507瀏覽量
121298
原文標題:深度 | BatchNorm是如何在深度學習優(yōu)化過程中發(fā)揮作用的?
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論