") 語言模型、RNN、LSTM以及NLP數(shù)據(jù)預(yù)處理流程
語言模型、RNN、LSTM以及NLP數(shù)據(jù)預(yù)處理流程
編者按:Shopify數(shù)據(jù)科學(xué)家Ruslan Nikolaev通過歌詞生成這一例子介紹了語言模型、RNN、LSTM以及NLP數(shù)據(jù)預(yù)處理流程。
在所有未來的AI應(yīng)用中,一個重頭戲是創(chuàng)建能夠從某個數(shù)據(jù)集中學(xué)習(xí),接著生成原創(chuàng)內(nèi)容。應(yīng)用這一想法到自然語言處理(NLP),AI社區(qū)研發(fā)了語言模型(Language Model)
語言模型的假定是學(xué)習(xí)句子是如何在文本中組織的,并使用這一知識生成新內(nèi)容
在我的案例中,我希望進行一個有趣的業(yè)余項目,嘗試生成說唱歌詞,看看我是否能夠重現(xiàn)很受歡迎的加拿大說唱歌手Drake(#6god)的歌詞。
同時我也希望分享一個通用的機器學(xué)習(xí)項目流程,因為我發(fā)現(xiàn),如果你不是很清楚從哪里開始,自己創(chuàng)建一些新東西經(jīng)常是非常困難的。
1. 獲取數(shù)據(jù)
首先我們需要構(gòu)建一個包含所有Drake歌曲的數(shù)據(jù)集。我編寫了一個python腳本,抓取歌詞網(wǎng)站metrolyrics.com的網(wǎng)頁。
import urllib.request as urllib2
from bs4 importBeautifulSoup
import pandas as pd
import re
from unidecode import unidecode
quote_page = 'http://metrolyrics.com/{}-lyrics-drake.html'
filename = 'drake-songs.csv'
songs = pd.read_csv(filename)
for index, row in songs.iterrows():
page = urllib2.urlopen(quote_page.format(row['song']))
soup = BeautifulSoup(page, 'html.parser')
verses = soup.find_all('p', attrs={'class': 'verse'})
lyrics = ''
for verse in verses:
text = verse.text.strip()
text = re.sub(r"\[.*\]\n", "", unidecode(text))
if lyrics == '':
lyrics = lyrics + text.replace('\n', '|-|')
else:
lyrics = lyrics + '|-|' + text.replace('\n', '|-|')
songs.at[index, 'lyrics'] = lyrics
print('saving {}'.format(row['song']))
songs.head()
print('writing to .csv')
songs.to_csv(filename, sep=',', encoding='utf-8')
我使用了知名的BeautifulSoup包,我花了5分鐘,看了Justin Yek寫的How to scrape websites with Python and BeautifulSoup教程,了解了BeautifulSoup的用法。你可能已經(jīng)注意到了,在上面的代碼中,我迭代了songs這一dataframe。是的,實際上,我預(yù)先定義了想要抓取的歌名。
運行我編寫的python爬蟲后,.csv文件中包含了所有的歌詞。是時候開始預(yù)處理數(shù)據(jù)并創(chuàng)建模型了。
songs = pd.read_csv('data/drake-songs.csv')
songs.head(10)
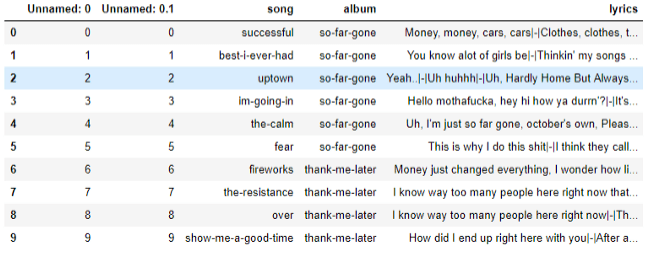
DataFrame中儲存了所有歌詞
關(guān)于模型
現(xiàn)在,我們將討論文本生成的模型,這是本文的重頭戲。
創(chuàng)建語言模型的兩種主要方法:(一)字符層次模型;(二)單詞層次模型
這兩種方法的主要差別在于輸入和輸出。下面我將介紹這兩種方法到底是如何工作的。
字符層次模型
字符層次模型的輸入是一系列字符seed(種子),模型負責(zé)預(yù)測下一個字符new_char。接著使用seed + new_char生成下一個字符,以此類推。注意,由于網(wǎng)絡(luò)輸入必須保持同一形狀,在每一次迭代中,實際上我們將從種子丟棄一個字符。下面是一個簡單的可視化:
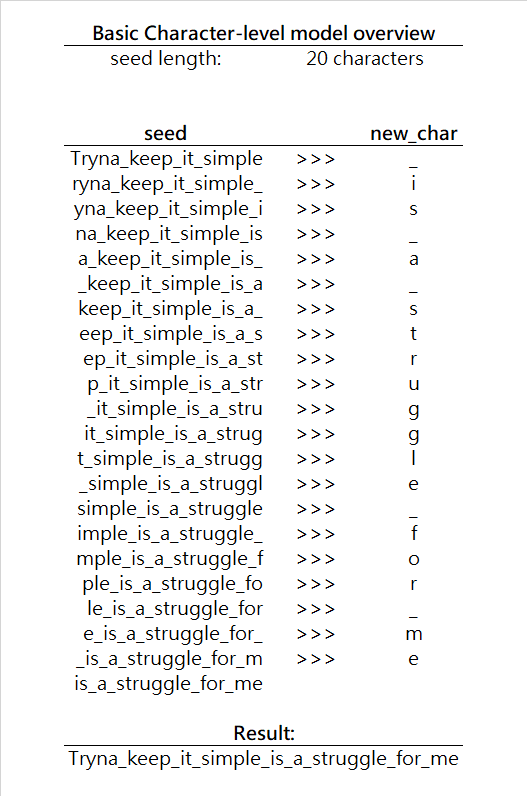
在每一次迭代中,基本上模型根據(jù)給定的種子字符預(yù)測最可能出現(xiàn)的下一個字符,用條件概率可以表達為,尋找P(new_char | seed)的最大值,其中new_char是字母表中的任意字符。在我們的例子中,字符表是所有英語字母,加上空格字符。(注意,你的字母表可能大不一樣,取決于模型適用的語言,字母表可以包含任何你需要的字符。)
單詞層次模型
單詞層次模型幾乎和字符層次模型一模一樣,只不過生成下一個單詞,而不是下一個字符。下面是一個簡單的例子:

在單詞層次模型中,我們預(yù)測的單位不再是字符,而是單詞。也就是,P(new_word | seed),其中new_word是詞匯表中的任何單詞。
注意,現(xiàn)在我們要搜索的空間比之前大很多。在字符層次模型中,每次迭代只需搜索幾十種可能性,而在單詞層次模型中,每次迭代的搜索項多很多。因此,單詞層次算法需要在每次迭代上花費更多的時間,好在由于每次迭代生成的是一個完整的單詞,而不是單個字符,所以其實并沒有那么糟。
另外,在單詞層次模型中,我們可能會有一個非常多樣化的詞匯表。通常,我們通過在數(shù)據(jù)集中查找所有獨特的單詞構(gòu)建詞匯表(一般在數(shù)據(jù)預(yù)處理階段完成)。由于詞匯表可能變得無限大,有很多技術(shù)用于提升算法的效率,比如詞嵌入,以后我會專門寫文章介紹詞嵌入。
就本文而言,我將使用字符層次模型,因為它更容易實現(xiàn),同時,對字符層次模型的理解可以很容易地遷移到單詞層次模型。其實在我撰寫本文的時候,我已經(jīng)創(chuàng)建了一個單詞層次的模型——以后我會另外寫一篇文章加以介紹。
2. 數(shù)據(jù)預(yù)處理
就字符層次模型而言,我們將依照如下方式預(yù)處理數(shù)據(jù):
將數(shù)據(jù)集切分為token我們不能直接將字符串傳給模型,因為模型接受字符作為輸入。所以我們需要將每行歌詞切分為字符列表。
定義字母表上一步讓我們得到了所有可能出現(xiàn)在歌詞中的字符,我們將查找所有獨特的字符。為了簡化問題,再加上整個數(shù)據(jù)集不怎么大(我只使用了140首歌),我將使用英語字母表,加上一些特殊字符(比如空格),并忽略數(shù)字和其他東西(由于數(shù)據(jù)集較小,我將選擇讓模型預(yù)測較少種字符)。
創(chuàng)建訓(xùn)練序列我們將使用滑窗(sliding window)技術(shù),通過在序列上滑動固定尺寸的窗口創(chuàng)建訓(xùn)練樣本集。

每次移動一個字符,我們生成20個字符長的輸入,以及單個字符輸出。此外,我們得到了一個附帶的好處,由于我們每次移動一個字符,實際上我們顯著擴展了數(shù)據(jù)集的尺寸。
標(biāo)簽編碼訓(xùn)練序列最后,由于我們不打算讓模型處理原始字符(不過理論上這是可行的,因為技術(shù)上字符即數(shù)字,你幾乎可以說ASCII為我們編碼了所有字符),我們將給字母表中的每個字符分配一個整數(shù),你也許聽說過這一做法的名稱,標(biāo)簽編碼(Label Encoding)。我們創(chuàng)建了映射character-to-index和index-to-character。有了這兩個映射,我們總是能夠?qū)⑷魏巫址幋a為獨特的整數(shù),同時解碼模型輸出的索引數(shù)字為原本的字符。
one-hot編碼數(shù)據(jù)集由于我們處理的是類別數(shù)據(jù)(字符屬于某一類別),因此我們將編碼輸入列。關(guān)于one-hot編碼,可以參考Rakshith Vasudev撰寫的What is One Hot Encoding? Why And When do you have to use it?一文。
當(dāng)我們完成以上5步后,我們只需創(chuàng)建模型并加以訓(xùn)練。如果你對以上步驟的細節(jié)感興趣,可以參考下面的代碼。
加載所有歌曲,并將其合并為一個巨大的字符串。
songs = pd.read_csv('data/drake-songs.csv')
for index, row in songs['lyrics'].iteritems():
text = text + str(row).lower()
找出所有獨特的字符。
chars = sorted(list(set(text)))
創(chuàng)建character-to-index和index-to-character映射。
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
切分文本為序列。
maxlen = 20
step = 1
sentences = []
next_chars = []
# 迭代文本并保存序列
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
為輸入和輸出創(chuàng)建空矩陣,然后將所有字符轉(zhuǎn)換為數(shù)字(標(biāo)簽編碼和one-hot向量化)。
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
3. 創(chuàng)建模型
為了使用之前的一些字符預(yù)測接下來的字符,我們將使用循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN),具體來說是長短時記憶網(wǎng)絡(luò)(LSTM)。如果你不熟悉這兩個概念,我建議你參考以下兩篇文章:循環(huán)神經(jīng)網(wǎng)絡(luò)入門和一文詳解LSTM網(wǎng)絡(luò)。如果你只是想溫習(xí)一下這兩個概念,或者信心十足,下面是一個快速的總結(jié)。
RNN
你通常見到的神經(jīng)網(wǎng)絡(luò)像是一張蜘蛛網(wǎng),從許多節(jié)點收斂至單個輸出。就像這樣:
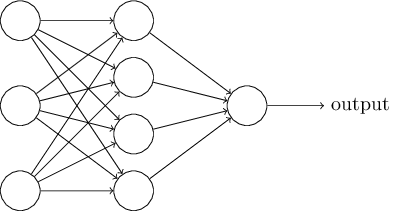
圖片來源:neuralnetworksanddeeplearning.com/
在這里我們有單個輸入和單個輸出。這樣的網(wǎng)絡(luò)對非連續(xù)輸入效果很好,其中輸入的順序不影響輸出。但在我們的例子中,字符的順序非常重要,因為正是字符的特定順序構(gòu)建了單詞。
RNN接受連續(xù)的輸入,使用前一節(jié)點的激活作為后一節(jié)點的參數(shù)。
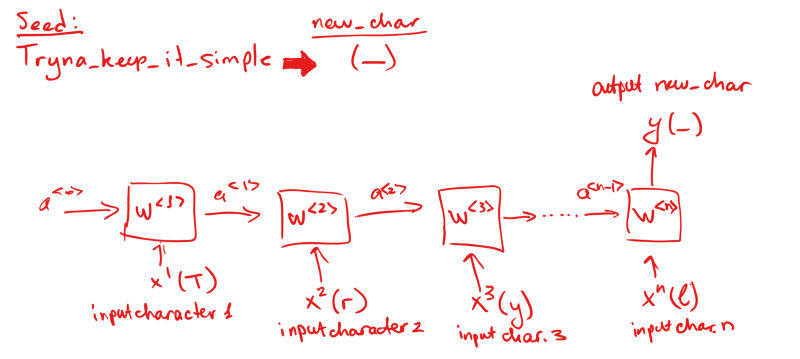
LSTM
簡單的RNN有一個問題,它們不是非常擅長從非常早的單元將信息傳遞到之后的單元。例如,如果我們正查看句子Tryna keep it simple is a struggle for me,如果不能回頭查看之前出現(xiàn)的其他單詞,預(yù)測最后一個單詞me(可能是任何人或物,比如:Bake、cat、potato)是非常難的。
LSTM增加了一些記憶,儲存之前發(fā)生的某些信息。
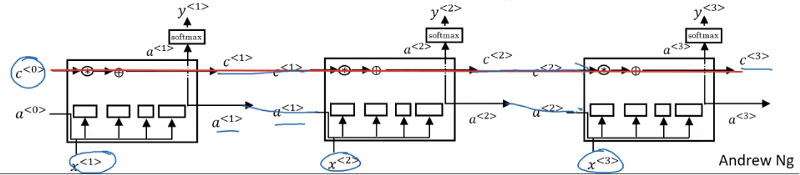
LSTM可視化;圖片來源:吳恩達的深度學(xué)習(xí)課程
除了傳遞a激活之外,同時傳遞包含之前節(jié)點發(fā)生信息的c。這正是LSTM更擅長保留上下文信息,一般而言在語言模型中能做出更好預(yù)測的原因。
代碼實現(xiàn)
我以前學(xué)過一點Keras,所以我使用這一框架構(gòu)建網(wǎng)絡(luò)。事實上,我們可以手工編寫網(wǎng)絡(luò),唯一的差別只不過是需要多花許多時間。
創(chuàng)建網(wǎng)絡(luò),并加上LSTM層:
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
增加softmax層,以輸出單個字符:
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
選擇損失函數(shù)(交叉熵)和優(yōu)化器(RMSprop),然后編譯模型:
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.01))
訓(xùn)練模型(我們使用了batch進行分批訓(xùn)練,略微加速了訓(xùn)練過程):
model.fit(x, y, batch_size=128, epochs=30)
4. 生成歌詞
訓(xùn)練網(wǎng)絡(luò)之后,我們將使用某個隨機種子(用戶輸入的字符串)作為輸入,讓網(wǎng)絡(luò)預(yù)測下一個字符。我們將重復(fù)這一過程,直到創(chuàng)建了足夠多的新行。
下面是一些生成歌詞的樣本(歌詞未經(jīng)審查)。





你也許注意到了,有些單詞沒有意義,這是字符層次模型的一個十分常見的問題,輸入數(shù)據(jù)經(jīng)常在單詞中間切開,使得網(wǎng)絡(luò)學(xué)習(xí)并生成奇怪的新單詞,并通過某種方式賦予其“意義”。
單詞層面的模型能夠克服這一問題,不過對于一個不到200行代碼的項目而言,字符層次模型仍然十分令人印象深刻。
其他應(yīng)用
字符層次網(wǎng)絡(luò)的想法可以擴展到其他許多比歌詞生成更實際的應(yīng)用中。
例如,預(yù)測手機輸入:
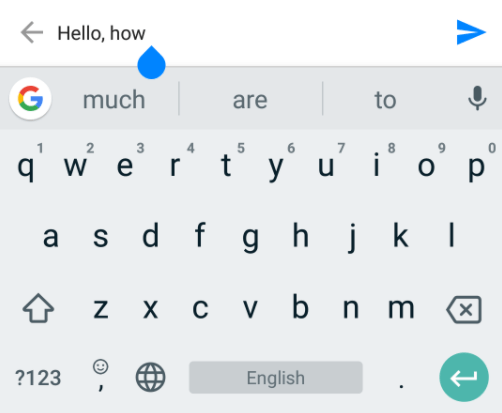
想象一下,如果你創(chuàng)建了一個足夠精確的Python語言模型,它不僅可以自動補全關(guān)鍵字或變量名,還能自動補全大量代碼,大大節(jié)省程序員的時間。
你也許注意到了,這里的代碼并不是完整的,有些部分缺失了,完整代碼見我的GitHub倉庫nikolaevra/drake-lyric-generator。在那里你可以深入所有細節(jié),希望這有助于你自己創(chuàng)建類似項目。
-
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
133024 -
python
+關(guān)注
關(guān)注
56文章
4807瀏覽量
85010 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13396
原文標(biāo)題:使用Keras和LSTM生成說唱歌詞
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【大語言模型:原理與工程實踐】大語言模型的預(yù)訓(xùn)練
FPGA也能做RNN
數(shù)據(jù)探索與數(shù)據(jù)預(yù)處理
深度分析RNN的模型結(jié)構(gòu),優(yōu)缺點以及RNN模型的幾種應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論