

編者按:今天論智給大家?guī)淼恼撐氖窍2畞泶髮W(xué)的Aharon Azulay和Yair Weiss近期發(fā)表的Why do deep convolutional networks generalize so poorly to small image transformations?這篇文章發(fā)現(xiàn)當(dāng)小尺寸圖像發(fā)生平移后,CNN會出現(xiàn)識別錯誤的現(xiàn)象,而且這一現(xiàn)象是普遍的。

摘要
通常我們認(rèn)為深度CNN對圖像的平移、形變具有不變性,但本文卻揭示了這樣一個現(xiàn)實:當(dāng)圖像在當(dāng)前平面上平移幾個像素后,現(xiàn)代CNN(如VGG16、ResNet50和InceptionResNetV2)的輸出會發(fā)生巨大改變,而且圖像越小,網(wǎng)絡(luò)的識別性能越差;同時,網(wǎng)絡(luò)的深度也會影響它的錯誤率。
論文通過研究表明,產(chǎn)生這個現(xiàn)象的主因是現(xiàn)代CNN體系結(jié)構(gòu)沒有遵循經(jīng)典采樣定理,無法保證通用性,而常用圖像數(shù)據(jù)集的統(tǒng)計偏差也會使CNN無法學(xué)會其中的平移不變性。綜上所述,CNN在物體識別上的泛化能力還比不上人類。
CNN的失誤
深度卷積神經(jīng)網(wǎng)絡(luò)(CNN)對計算機視覺帶來的革新是天翻地覆的,尤其是在物體識別領(lǐng)域。和其他機器學(xué)習(xí)算法一樣,CNN成功的關(guān)鍵在于歸納偏差的方法,不同架構(gòu)的選擇影響著偏差的具體計算方式。在CNN中,卷積和池化這兩個關(guān)鍵操作是由圖像不變性驅(qū)動的,這意味如果我們對圖像做位移、縮放、變形等操作,它們對網(wǎng)絡(luò)提取特征沒有影響。
但事實真的如此嗎?
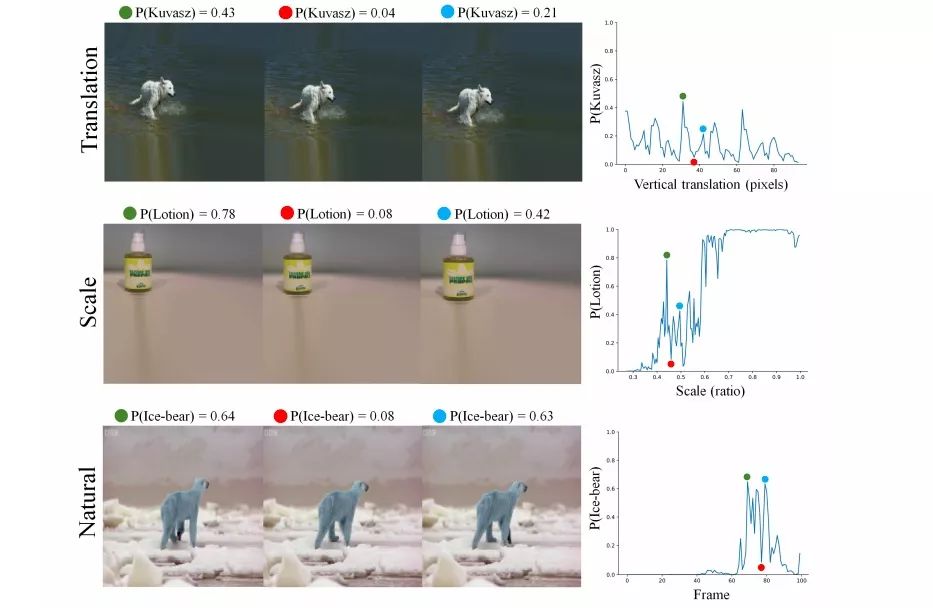
在上圖中,左側(cè)圖像是模型的輸入,右側(cè)折線圖是模型評分,使用的模型是InceptionResNet-V2 CNN。可以發(fā)現(xiàn),作者在這里分別對圖像做了平移、放大和微小形變。在最上方的輸入中,他們只是將圖像從左到右依次下移了一像素,就使模型評分出現(xiàn)了劇烈的波動;在中間的輸入中,圖像被依次放大,模型的評分也經(jīng)歷了直線下降和直線上升;而對于最下方的輸入,這三張圖是從BBC紀(jì)錄片中選取的連續(xù)幀,它們在人類眼中是北極熊的自然運動姿態(tài),但在CNN“眼中”卻很不一樣,模型評分同樣遭遇“滑鐵盧”。
為了找出導(dǎo)致CNN失誤的特征,他們又從ImageNet驗證集中隨機選擇了200幅圖像,并把它們嵌入較大的圖像中做系統(tǒng)性平移,由圖像平移導(dǎo)致的空白區(qū)域已經(jīng)用程序修補過了,在這個基礎(chǔ)上,他們測試了VGG16、ResNet50和InceptionResNetV2三個現(xiàn)代CNN模型的評分,結(jié)果如下:


圖A的縱坐標(biāo)是200張圖像,它用顏色深淺表示模型識別結(jié)果的好壞,其中非黑色彩表示模型存在能對轉(zhuǎn)變后的圖像正確分類的概率,全黑則表示完全無法正確分類。通過觀察顏色變化我們可以發(fā)現(xiàn),無論是VGG16、ResNet50還是InceptionResNetV2,它們在許多圖片上都顯示出了由淺到深的突然轉(zhuǎn)變。
論文作者在這里引入了一種名為jaggedness的量化標(biāo)準(zhǔn):模型預(yù)測準(zhǔn)確率top-5類別中的圖像,經(jīng)歷一次一像素平移就導(dǎo)致分類錯誤(也可以是準(zhǔn)確率低一下子變成準(zhǔn)確率高)。他們發(fā)現(xiàn)平移會大幅影響輸出的圖片占比28%。而如圖B所示,相對于VGG16,ResNet50和InceptionResNetV2因為網(wǎng)絡(luò)更深,它們的“jaggedness”水平更高。
那么,這是為什么呢?
對采樣定理的忽略
CNN的上述失誤是令人費解的。因為從直觀上來看,如果網(wǎng)絡(luò)中的所有層都是卷積的,那當(dāng)網(wǎng)絡(luò)對圖像編碼時,所有表征應(yīng)該也都跟著一起被編碼了。這些特征被池化層逐級篩選,最后提取出用于分類決策的終極特征,理論上來說,這些特征相對被編碼的表征應(yīng)該是不變的。所以問題在哪兒?
這篇論文提出的一個關(guān)鍵思想是CNN存在采樣缺陷。現(xiàn)代CNN中普遍包含二次采樣(subsampling)操作,它是我們常說的降采樣層,也就是池化層、stride。它的本意是為了提高圖像的平移不變性,同時減少參數(shù),但它在平移性上的表現(xiàn)真的很一般。之前Simoncelli等人已經(jīng)在論文Shiftable multiscale transforms中驗證了二次采樣在平移不變性上的失敗,他們在文中說:
我們不能簡單地把系統(tǒng)中的平移不變性寄希望于卷積和二次采樣,輸入信號的平移不意味著變換系數(shù)的簡單平移,除非這個平移是每個二次采樣因子的倍數(shù)。
考慮到現(xiàn)在CNN通常包含很多池化層,它們的二次采樣因子會非常大,以InceptionResnetV2為例,這個模型的二次采樣因子是45,所以它保證精確平移不變性的概率有多大?只有1/452。
下面我們從計算角度看看其中的貓膩:
我們設(shè)r(x)是模型在圖像x處獲得的特征信號,如果把圖像平移δ后,模型獲得的還是同樣的特征信號,那我們就稱這個信號是“卷積”的。注意一點,這個定義已經(jīng)包含輸入圖像進(jìn)入filter提取特征信號等其他線性操作,但不包括二次采樣和其他非線性操作。
觀察
如果r(x)是卷積的,那么全局池化后得到的特征信號 r = ∑xr(x) 應(yīng)該具有平移不變性。
證明
以下論證來自之前我們對“卷積”的定義。如果r(x)是圖像x處的特征信號,而r2(x)是同一圖像平移后的特征信號,那么 ∑xr(x) = ∑xr2(x) 成立,因為兩者是平移前后的特征信號,是不變的。
定義
對于特征信號r(x)和二次采樣因子s,如果信號中x處的任意輸出x是采樣網(wǎng)格的線性插值:

那么我們就認(rèn)為r(x)是“可位移的”(shiftable)。因為參照之前圖像位移的說法,既然采樣后信號具有平移不變性,那原信號載體就是可以移動的。其中xi是二次采樣因子s采樣網(wǎng)格上的信號,Bs(x)是從采樣中重建的r(x)基函數(shù)。
經(jīng)典Shannon-Nyquist定理告訴我們,當(dāng)且僅當(dāng)采樣頻率是r(x)最高頻率的兩倍時,r(x)才可以位移。
論點
如果r(x)可以位移,那么采樣網(wǎng)格全局池化后得到的最終特征信號 r = ∑ir(xi) 應(yīng)該具有平移不變性。
證明
通過計算我們發(fā)現(xiàn)了這么一個事實:采樣網(wǎng)格上的全局池化就相當(dāng)于所有x的全局池化:
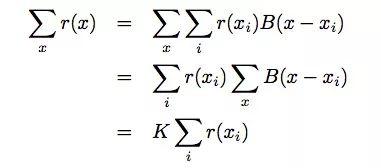
其中,K = ∑xB(x ? xi)和K與xi無關(guān)。
而現(xiàn)代CNN的二次采樣忽視了以上這些內(nèi)容,所以平移不變性是難以保證的。
為什么CNN不能從數(shù)據(jù)中學(xué)習(xí)平移不變性?
雖然上一節(jié)論證了CNN在架構(gòu)上就無法保證平移不變性,但為什么它就不能從大量數(shù)據(jù)里學(xué)到不變性呢?事實上,它確實能從數(shù)據(jù)中學(xué)到部分不變性,那么問題還出在哪兒?
論文的觀點是數(shù)據(jù)集里的圖像自帶“攝影師偏差”,很可惜論文作者做出的解釋很糟糕,一會兒講分布,一會兒講數(shù)據(jù)增強,非常沒有說服力。但是這個觀點確實值得關(guān)注,心理學(xué)領(lǐng)域曾有過關(guān)于“攝影師偏差”對人類視角影響的研究,雖然缺乏數(shù)據(jù)集論證,但很多人相信,同樣的影響也發(fā)生在計算機視覺中。
這里我們引用Azulay和Weiss的兩個更有說服力的點:
CIFAR-10和ImageNet的圖片存在大量“攝影師偏差”,這使得神經(jīng)網(wǎng)絡(luò)無需學(xué)會真實的平移不變性。宏觀來看,只要不是像素級別的編碼,世界上就不存在兩張完全一樣的圖像,所以神經(jīng)網(wǎng)絡(luò)是無法學(xué)到嚴(yán)格的平移不變性的,也不需要學(xué)。
例如近幾年提出的群卷積,它包含的filter數(shù)量比其他不變性架構(gòu)更少,但代價是filter里參數(shù)更多,模型也更不靈活。如果數(shù)據(jù)集里存在“攝影師偏差”,那現(xiàn)有不變性架構(gòu)里的參數(shù)是無法描述完整情況的,因此它們只會獲得一個“模糊”的結(jié)果,而且缺乏靈活性,性能自然也比非不變性架構(gòu)要差不少。
小結(jié)
雖然CNN在物體識別上已經(jīng)取得了“超人”的成果,但這篇論文也算是個提醒:我們還不能對它過分自信,也不能對自己過分自信。隨著技術(shù)發(fā)展越來越完善,文章中提及的這幾個本質(zhì)上的問題也變得越來越難以蒙混過關(guān)。
或許由它我們能引出一個更有趣的問題,如果人類尚且難以擺脫由視覺偏差帶來的認(rèn)知影響,那人類制造的系統(tǒng)、機器該如何超越人類意識,去了解真實世界。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4789瀏覽量
101899 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1217瀏覽量
25109 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22513
原文標(biāo)題:證偽:CNN中的圖片平移不變性
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
不變矩在車牌字符識別中的應(yīng)用
一種自動的輪轂識別分類方法
去降Mallat離散小波變換實現(xiàn)彩色圖像分割
基于尺度不變性的無參考圖像質(zhì)量評價
如何判斷差分方程描述的系統(tǒng)的線性和時變性?《數(shù)字信號處理》考研題
圖像處理學(xué)習(xí)資料之《圖像局部不變性特征與描述》電子教材免費下載
為什么區(qū)塊鏈具有不變性
區(qū)塊鏈中的不變性是什么意思
什么是區(qū)塊鏈不變性
MEGNet普適性圖神經(jīng)網(wǎng)絡(luò) 精確預(yù)測分子和晶體性質(zhì)

機器學(xué)習(xí)在各領(lǐng)域的廣泛應(yīng)用以及促生其在材料領(lǐng)域的應(yīng)用

卷積神經(jīng)網(wǎng)絡(luò)是怎樣實現(xiàn)不變性特征提取的?

為什么卷積神經(jīng)網(wǎng)絡(luò)可以做到不變性特征提取?

圖像匹配算法SIFT算法實現(xiàn)步驟簡述
基于Python和深度學(xué)習(xí)的CNN原理詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論