 有了OpenAI Five,它已經可以在比賽中擊敗業余玩家
有了OpenAI Five,它已經可以在比賽中擊敗業余玩家
編者按:關于OpenAI的那篇博客,相信很多玩家一早起來就已經看過了。昨晚打完Dota2時,云玩家小編也在Reddit上看了相關視頻,還和隊友一起推測了會兒內在機制。但不曾想,我這一睡就又錯過了頭條。本文會重新編譯原博內容,并補上被大家忽視的一些關鍵點。
去年,OpenAI的強化學習bot在中路solo中擊敗職業選手Dendi,贏得眾人矚目,但Dota2是一個5人游戲,在那之后,我們目標是制作一個由神經網絡構成的5人團隊,它能在8月份舉辦的Ti8國際邀請賽上,用有限的英雄擊敗職業隊。時至今日,我們有了OpenAI Five,它已經可以在比賽中擊敗業余玩家。
OpenAI Five玩的是限制版的Dota2,它只會瘟疫法師、火槍、毒龍、冰女和巫妖5個英雄,因為鏡像訓練,它的對手也只能玩這5個。游戲的“限制性”主要體現在以下幾方面:
英雄受限(上述5個);
沒有假眼和真眼;
沒有肉山;
不能隱身(消耗品和相關物品,可以理解為沒有霧、微光、隱刀、大隱刀、隱身符等);
沒有召喚物和分身(沒有分身斧、分身符、支配頭盔等);
沒有圣劍、魔瓶、補刀斧、飛鞋、知識之書、凝魂之露(沒有骨灰?);
每隊五只無敵信使(和加速模式一樣);
不能掃描。
這些限制使OpenAI Five的游戲和正常游戲有一定區別,尤其是隊長模式,但總體而言,它和隨機征召等模式差別不大(對于冰女這樣的五號位,沒有眼完全沒法玩吧!)。
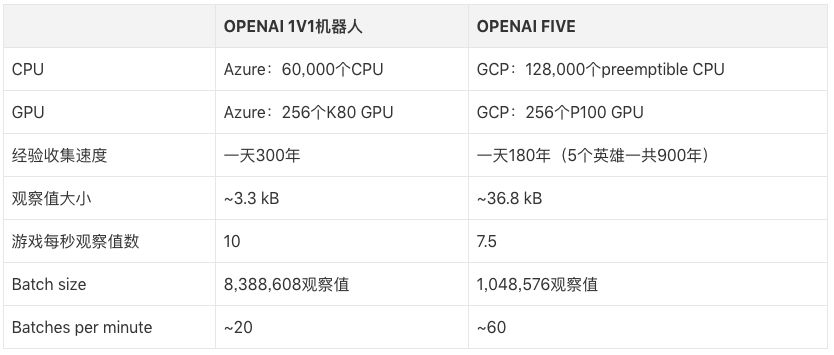
OpenAI Five每天玩的游戲量相當于人類玩家180年的積累,和圍棋AI一樣,它從自學中提取經驗。訓練設備是256個GPU和128,000個CPU,使用的強化學習算法是近端策略優化(PPO)。因為不同英雄間技能、出裝各異,這5個英雄使用的是5個獨立的LSTM,無人類數據,由英雄從自己的數據中學習可識別策略。
實驗表明,在沒有根本性進展的前提下,強化學習可以利用LSTM進行大規模的、可實現的長期規劃,這出乎我們的意料。為了考察這個成果,7月28日,OpenAI Five會和頂級玩家進行比賽,屆時玩家可以在Twitch上觀看實況轉播。
OpenAI Five擊敗OpenAI員工隊伍
問題
如果一個AI能在像星際、Dota這樣復雜的游戲里超越人類水平,那它就是一個里程碑。相較于AI之前在國際象棋和圍棋里取得的成就,游戲能更好地捕捉現實世界中的混亂和連續性,這就意味著能解決游戲問題的AI系統具有更好的通用性。醉翁之意不在酒,它的目標也不僅僅是游戲。
Dota2是一款實時戰略游戲,一場比賽由2支隊伍構成,每支隊伍5人,在游戲中,每個玩家需要操控一個“英雄”單位。如果AI想玩Dota2,它必須掌握以下幾點:
時間較長。Dota2的運行幀數是30幀每秒,一場游戲平均45分鐘,也就是一場游戲要跑80,000幀左右。在游戲中,大多數動作(action,例如讓英雄移動到某一位置)產生的獨立影響相對較小,但一些獨立動作,比如TP,就可能會對游戲戰略產生重大影響。同時,游戲中也存在一些貫徹始終的戰略,比如推線、farm(刷錢)和gank(抓人)。OpenAI Five的觀察頻率是4幀一次,也就是場均20,000個動作,而國際象棋一般在40步以內就能決出勝負,圍棋是150步。這些動作幾乎都具有戰略性意義。
視野有限。在Dota2中,地圖本身是黑的,只能靠英雄和建筑提供一定視野(禁止插眼),這就意味著比賽要根據不完整的數據信息進行推斷,同時預測敵方英雄的發育進度。國際象棋和圍棋都是全知視角。
高維的、連續的動作空間。在比賽中,一個英雄可以采取的動作有數十個,其中有些是對英雄使用的,有些是點地面的。對于每個英雄,我們把這些連續的動作空間分割成170,000個可能的動作(有CD,不是每個都能用),除去其中的連續部分,平均每幀約有1000個動作可以選擇。而在國際象棋中,每個節點的分支因子只有35個,圍棋則是平均250個。
高維的、連續的觀察空間。Dota2的地圖相當豐富,比如一場比賽中有10個英雄、幾十個建筑、多個NPC單位,以及包括神符、樹木、圣壇(火鍋)等在內的諸多要素。我們的模型通過V社的Bot API觀察游戲狀態,用20,000個數據(大多數是浮點數據)總結了整張地圖的所有信息。相較之下,國際象棋只有約70個(8×8棋盤),圍棋只有約400個(19×19棋盤)。
Dota2的游戲規則非常復雜——它已經被積極開發了十幾年,游戲邏輯代碼也有數十萬行。對于AI來說,這個邏輯需要幾毫秒才能執行,而國際象棋和圍棋只需幾納秒。目前,游戲還在以每兩周一次的頻率持續更新,不斷改變語義環境。
我們的方法
我們使用的算法是前陣子剛推出的PPO,這次用的是它的大規模版本。和去年的1v1機器人一樣,OpenAI Five也是從自學中總結游戲經驗,它們從隨機參數開始訓練,不使用任何人類數據。
強化學習(RL)研究人員一般認為,如果想讓智能體在長時間游戲中表現出色,就難免需要一些根本上的新突破,比如hierarchical reinforcement learning(分層強化學習)。但實驗結果表明,我們應該給予已有算法更多信任,如果規模夠大、結構夠合理,它們也能表現出色。
智能體的訓練目標是最大化未來回報,這些回報被折扣因子γ加權。在OpenAI Five的近期訓練中,我們把因子γ從0.998提高到了0.9997,把評估未來獎勵的半衰期從46秒延長到了五分鐘。為了體現這個進步的巨大,這里我們列幾個數據:在PPO這篇論文中,最長半衰期是0.5秒;在Rainbow這篇論文中,最長半衰期是4.4秒;而在Observe and Look Further這篇論文中,最長半衰期是46秒。
盡管當前版本的OpenAI Five在“補刀”上表現不佳(大約是Dota玩家的中位數),但它對于經驗、金錢的的優先級匹配策略和專業選手基本一致。為了獲得長期回報,犧牲短期回報是很正常的,就好比隊友抱團推塔時,玩家不該自己在線上補刀刷錢。這是個振奮人心的發現,因為我們的AI系統真的在進行長期優化。
模型結構
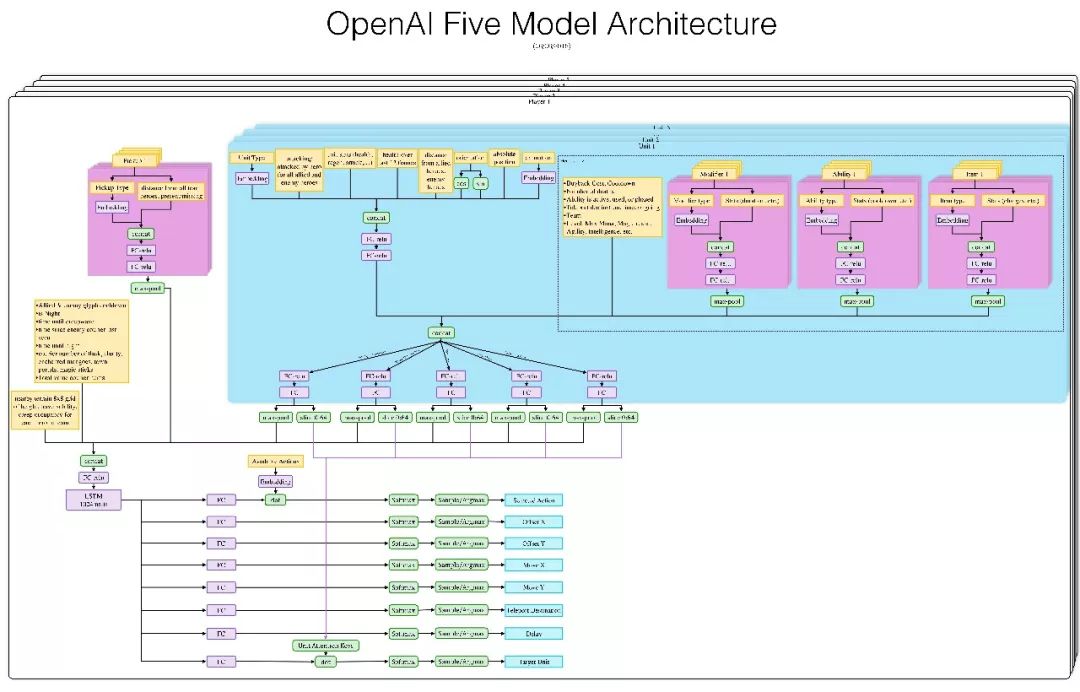
看不清圖請向論智君索取
每個OpenAI Five神經網絡都包含一個單層的LSTM(左下淡紫),其中有1024個神經元。輸入當前的游戲狀態(從Valve的Bot API中提取)后,它會單獨計算各個action head(輸出動作標簽),如圖中下方亮藍色方框中的X坐標、Y坐標、目標單位等,再把所有action head合并成一系列動作。
下圖是OpenAI Five使用的觀察空間和動作空間的交互式演示。它把整張地圖看做一個有20,000個數據的列表,并通過8個列舉值的列表來采取行動。這個場景是夜魘上天輝高地,我們選中冰女,可以發現,冰女腳下的9×9小方格表示她可以前進位置,其中白色目標方塊的坐標是(-300,0)。大方框表示可以放Nova地方,目標分別是投石車、小兵、毒龍、巫妖、瘟疫法師和另一個冰女。
OpenAI Five可以就自己觀察到的內容對缺失信息做出反應。例如火槍的一技能是榴霰彈,這是一個范圍傷害,雖然除了星際玩家以外的正常玩家都看得到這個區域,但它并不屬于OpenAI Five的觀察范圍。即便“看不到”,每當AI走進霰彈區時,它們還是會急著走出來,因為那時它們的血量在不斷下降。
探索
既然AI可以學會“深謀遠慮”,那接下來的問題就是環境探索。前文提到了,OpenAI Five玩的是限制版Dota2,即便少了很多復雜內容,它還有上百種道具、數十種建筑物、法術、單位類型和游戲機制要學習——其中某些內容的組合還會產生更強大的東西。對于智能體來說,有效探索這個組合廣闊的空間并不容易。
OpenAI Five的學習方法是自我訓練(從隨機參數開始),這就為探索環境提供了初級經驗。為了避免“戰略崩潰”,我們把自我訓練分成兩部分,其中80%是AI和自己對戰,剩下20%則是AI和上一版AI對戰。經過幾個小時的訓練,帶線、刷錢、中期抓人等戰略陸續出現了。幾天后,它們已經學會了基礎的人類戰略:搶對面的賞金神符,走到己方外塔附近補刀刷錢,不停把英雄送去占線擴大優勢。在這個基礎上,我們做了進一步訓練,這時,OpenAI Five就已經能熟練掌握5人推塔這樣的高級策略了,
2017年3月,我們的第一個智能體擊敗了機器人,卻對人類玩家手足無措。為了強制在戰略空間進行探索,在訓練期間(并且只在訓練期間),我們隨機化了它的各項屬性(血量、移速、開始等級等),之后它開始能戰勝一些玩家。后來,它又在另一名測試玩家身上屢戰屢敗,我們就又增加了隨機訓練,AI變強了,那名玩家也開始輸了。
OpenAI Five使用了我們之前為1v1智能體編寫的隨機數據,它也啟用了一種新的“分路”方法。在每次訓練比賽開始時,我們隨機地將每個英雄“分配”給一些線路子集,并對其進行懲罰以避開這幾路。
上述探索自然離不開回報的指引。我們為Dota2設計的回報機制基于人類玩家對行為的具體評判:團隊作用、技能施放、死亡次數、助攻次數和擊殺次數等。為了防止智能體鉆漏洞,我們的方法是計算另一隊的平均表現,然后用本隊英雄表現減去這個值來具體評判。
英雄的技能點法、裝備和信使管理都從腳本導入。
團隊合作
Dota2是個團隊合作游戲,但OpenAI Five的5名英雄間不存在神經網絡上的明確溝通渠道。他們的團隊合作由一個名為“team spirit”的超參數控制,范圍是0到1,由它給每個英雄的加權,讓它們知道這時是團隊利益更重要還是個人刷錢更重要。
Rapid
這個AI是在我們的強化學習訓練系統Rapid上實現的,后者可以應用于Gym環境庫。我們已經用Rapid解決了OpenAI的許多其他問題,比如Competitive Self-Play。
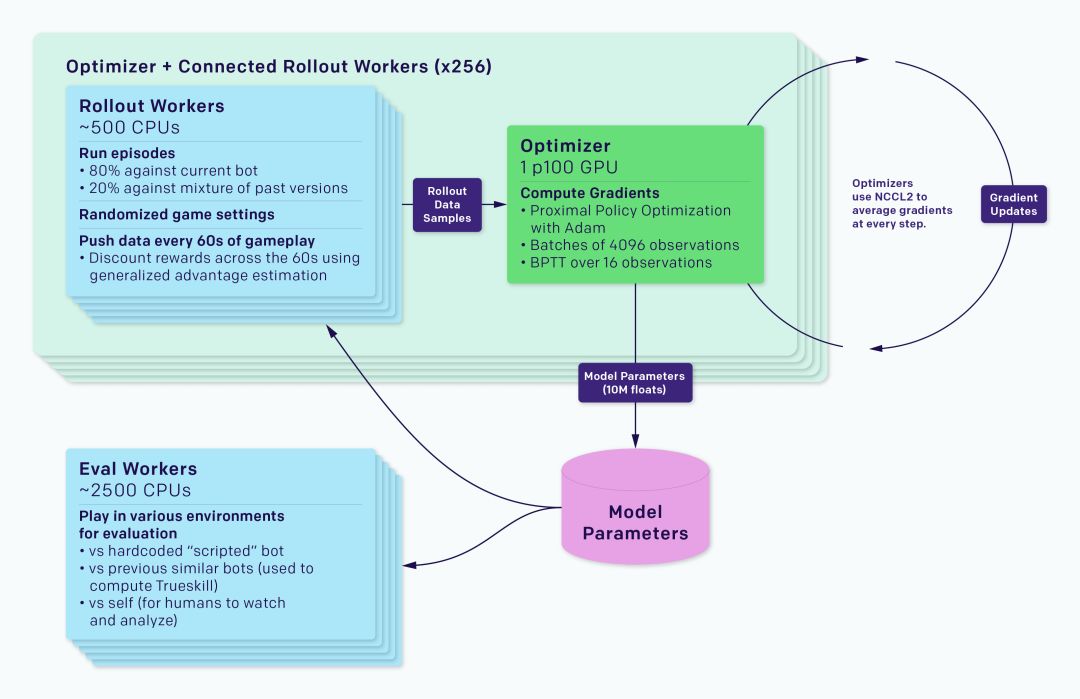
整個訓練系統被分為rollout workers和optimizer兩部分,其中前者運行一個游戲副本,并用一個智能體收集經驗,后者則在一系列GPU中執行同步梯度下降。rollout workers通過Redis跟optimizer同步經驗。如上圖所示,每個實驗還包括一個Eval workers的過程,它的作用是評估經過訓練的智能體和參考智能體。除此之外還有一些監控軟件,如TensorBoard、Sentry和Grafana。
在同步梯度下降過程中,每個GPU在各自batch計算梯度,然后再對梯度進行全局平均。我們最初使用MPI的allreduce進行平均,但現在用我們自己的NCCL2封裝來并行GPU計算和網絡數據傳輸。
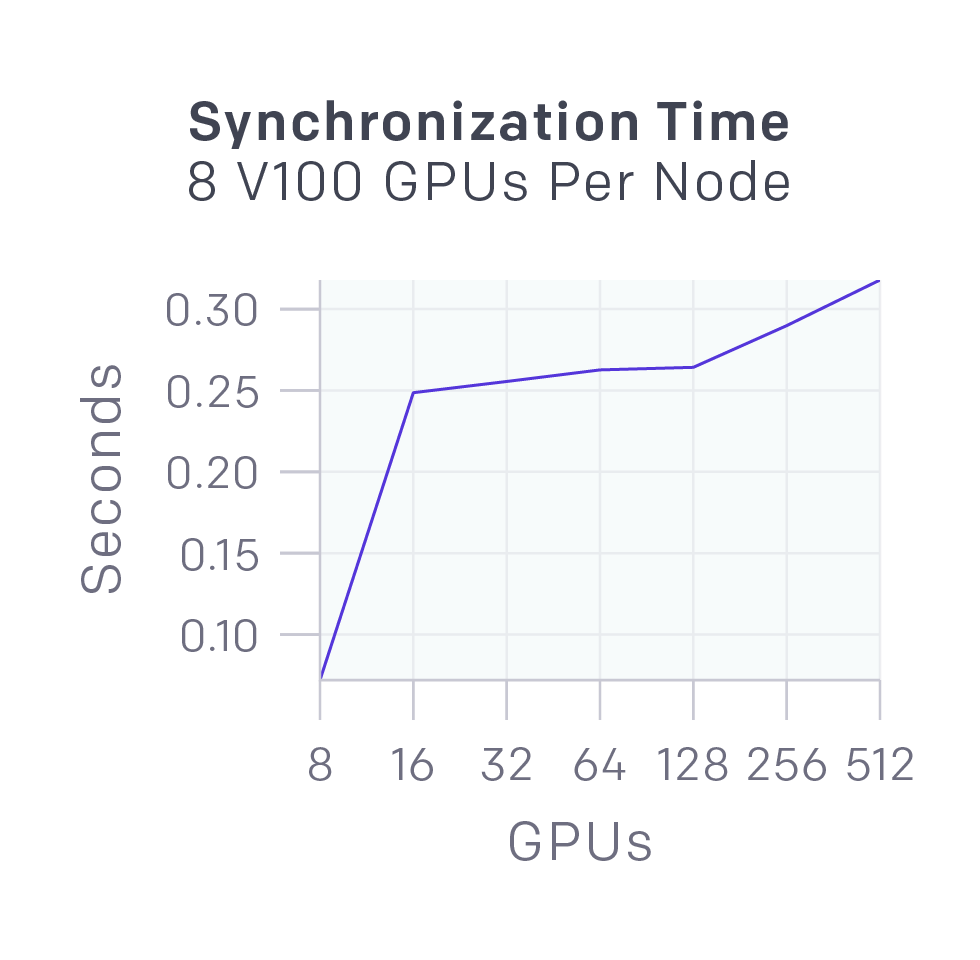
上圖顯示了不同數量的GPU同步58MB數據(OpenAI Five參數)的延遲,幾乎可以被并行運行的GPU計算所掩蓋。
我們還為Rapid開發了Kubernetes、Azure和GCP后端。
游戲
到目前為止,OpenAI Five已經在限制版Dota2中獲得了非常輝煌的戰績:
頂級OpenAI員工隊伍:天梯分2500+(前46%玩家)
觀看比賽的最強觀眾隊(包括解說Blitz):天梯分4000-6000(前90-99%玩家)——非開黑
V社員工隊伍:天梯分2500-4000(前46-90%玩家)
業余選手隊伍:天梯分4200(前93%玩家)——開黑隊
半職業隊:天梯分5500(前99%玩家)——開黑隊
4月23日,OpenAI Five首次擊敗機器人腳本;5月15日,它在和OpenAI員工隊的較量中1勝1負,首次戰勝人類玩家;6月6日,它突破OpenAI隊、觀眾隊和V社隊的封鎖,決定性地贏得了所有的比賽。之后我們又和業余隊、半職業隊進行了非正式比賽,OpenAI Five沒有像預想中那樣一敗涂地,而是在和兩個隊的前三場比賽中都贏了兩場。
這些AI機器人的團隊合作幾乎是壓倒性的,它們就像5個無私的玩家,知道最好的總體戰略。——Blitz
我們也從OpenAI Five的比賽中觀察到了一些東西:
它們會為了搶奪敵方優勢路舍棄自家優勢路(天輝的下路和夜魘的上路),使對方無力回防。這種戰略近幾年常出現在職業隊伍比賽中,解說Blitz也稱自己是從液體(李逵)那里得知這點的。
推動局勢轉變,比對面更快地把戰局從前期推進中期。這樣做的具體方法是:(1)如下圖所示,成功的gank;(2)在對面抱團后,及時反制。
它們在少數領域背離了目前的游戲風格,比如AI前期會給輔助更多經驗和錢,讓它們在強勢期打足傷害,擴大局面優勢,打贏團戰,然后抓住對方失誤快速致勝。
AI和人類的差別
OpenAI Five可以觀察的信息和人類玩家相同,游戲里有什么數據,它就看到什么數據。比如玩家需要手動去檢查英雄位置、血量情況和身上的裝備。我們的方法并沒有從根本上與觀察狀態相關聯,但僅從游戲渲染像素看,它就需要數千個GPU。
對于許多人關心的APM問題,OpenAI Five只有150-170(每4幀一次動作,理論上最高有450)。但需要注意的是,這150是有效操作,不是逛街和打字嘲諷,它的平均反應時間為80ms,比人類快。
這兩個差異在1v1中最為重要,但在比賽中,我們發現人類玩家可以輕松適跟上AI的節奏,所以雙方競技還是比較公平的。事實上去年Ti7期間,一些職業玩家也和我們的1v1 AI做了多次訓練,根據Blitz的說法,1v1 AI改變了人們對1v1的看法(AI采用了快節奏的游戲風格,現在每個人都適應了)。
令人驚訝的發現
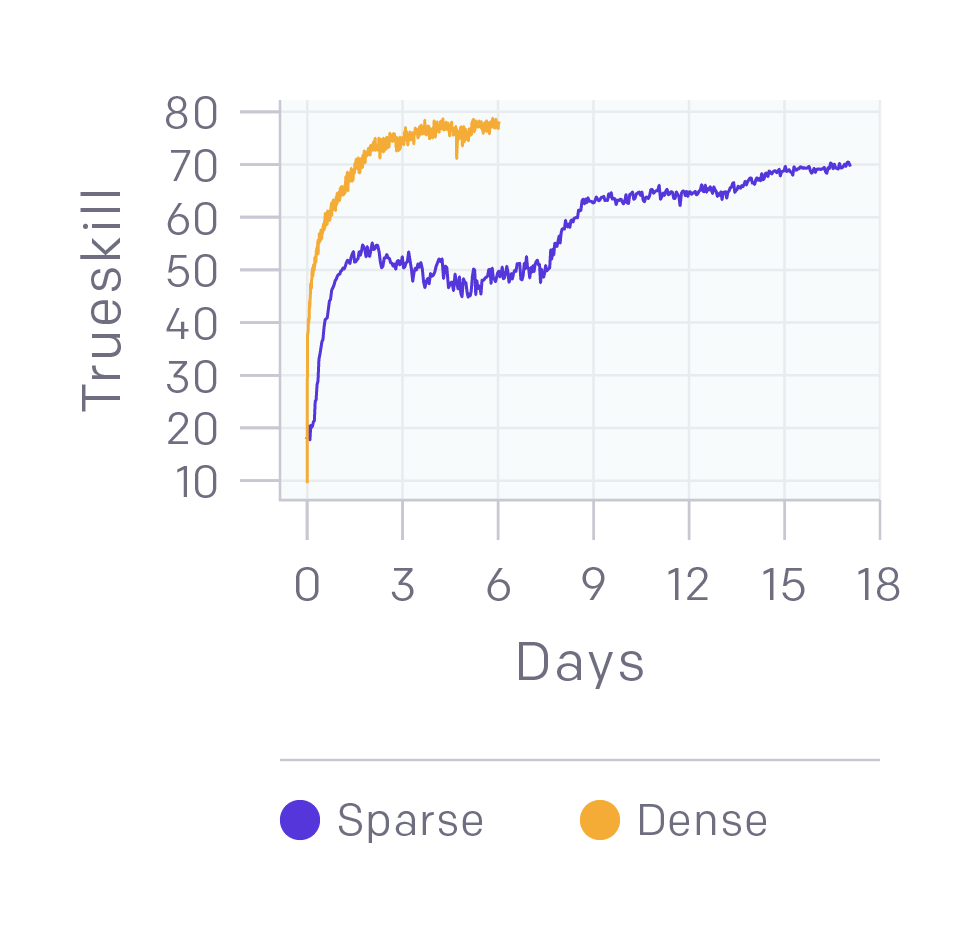
二元回報能夠提供良好的表現。1v1模型的回報是多尺度的,包括擊殺英雄、連續擊殺等。我們做了一個實驗,讓智能體只能從輸贏中獲得回報。如上圖所示,和常見的平滑曲線(黃線)相比,雖然它(紫線)在訓練中期出現了一個較慢并且稍微平穩的階段,但它的訓練結果和黃線很接近。這個實驗用了4,500個CPU和16個k80 GPU,模型性能達到半專業級(70個TrueSkill),而我們的1v1模型是90個TrueSkill。
可以自學卡兵。在去年的1v1模型中,我們獨立訓練模型卡兵,并附加一個“卡兵塊”獎勵。我們團隊的一名員工在訓練2v2模型時,因為要休假,于是建議他(現在的)妻子看看要花多久才能提高性能。令人驚訝的是,這個模型居然在沒有任何特殊指引和回報激勵的情況下得出了卡兵會產生優勢的結論。
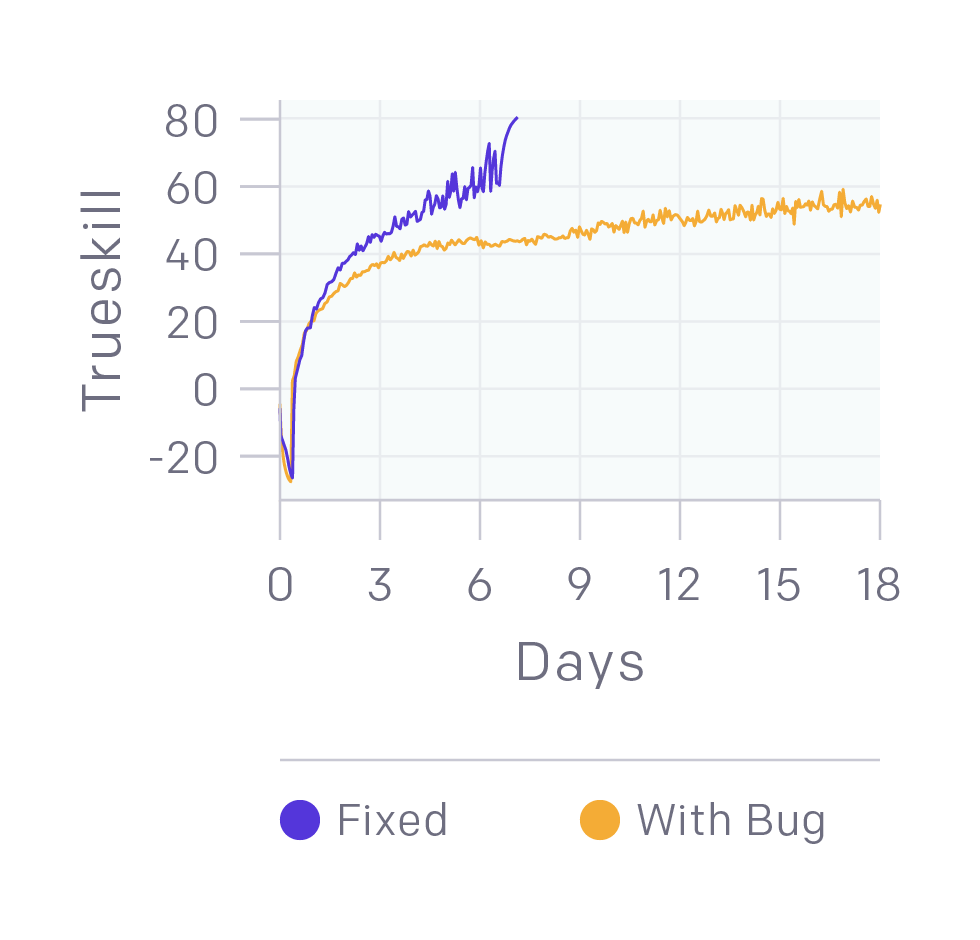
我們仍在修復錯誤。上圖中的黃線模型已經可以擊敗業余玩家,但修復了一些Bug后,它的提升非常明顯。這給我們帶來的啟示是即便已經擊敗更強的人類玩家,我們的模型還是可能隱藏著嚴重錯誤。
-
神經網絡
+關注
關注
42文章
4775瀏覽量
100919 -
AI
+關注
關注
87文章
31158瀏覽量
269530 -
強化學習
+關注
關注
4文章
268瀏覽量
11272
原文標題:一文解析OpenAI Five,一個會打團戰的Dota2 AI
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論