

現在的計算機視覺系統大多基于深度神經網絡,它們可以通過學習大量數據集從而得到將圖像投影到普通的場景描述的功能,簡單說就是見得多了習慣了。
然而和這種神經網絡相比,我們的大腦顯然更加智能,可以利用先前的知識來推理,并做出遠遠超出看到的物品的推論。例如,如果看到桌子的三條腿,那么可以推斷出第四條腿的存在和其位置,基本與實際情況相同;即使看不到房間里的所有東西,你也可以畫出它的布局、想象它的外觀。嬰兒在八九個月時就可以理解“形狀恒常性”的存在,即使用布蓋住他面前的玩具,他也可以腦補出布下面玩具的樣子,而這,恰是深度神經網絡不能識別的。
最近,通過模仿人大腦對環境的處理方法,DeepMind提出了一種新型計算機視覺框架:GQN (the Generative Query Network),這個框架實現了前面提到的功能,可以腦補出環境的另外部分,還可以將2D圖片渲染至3D。
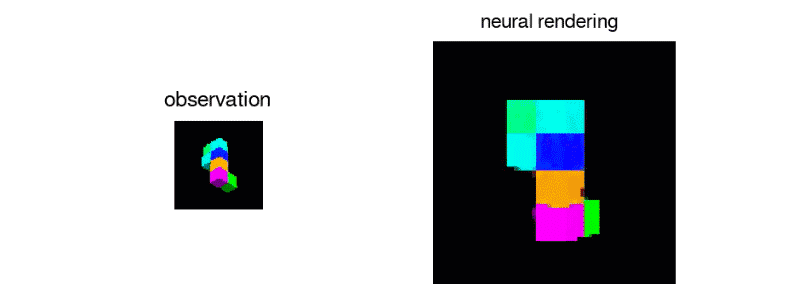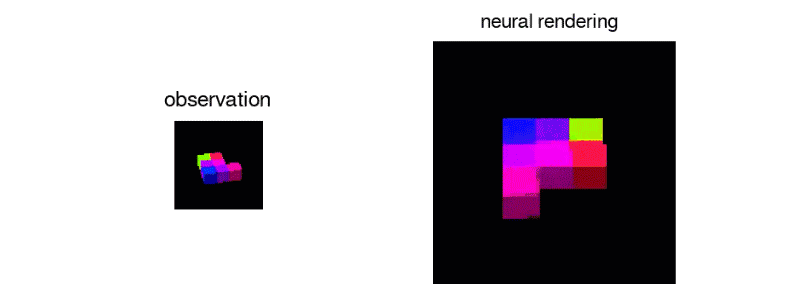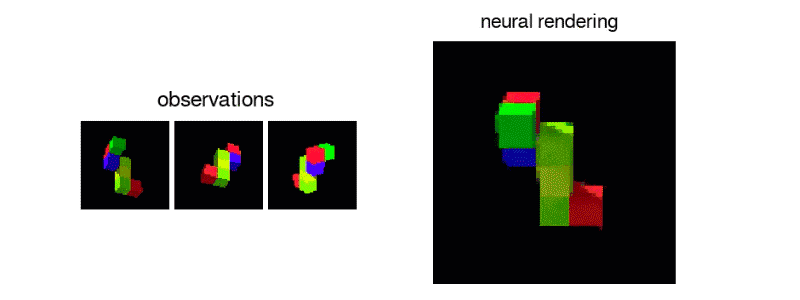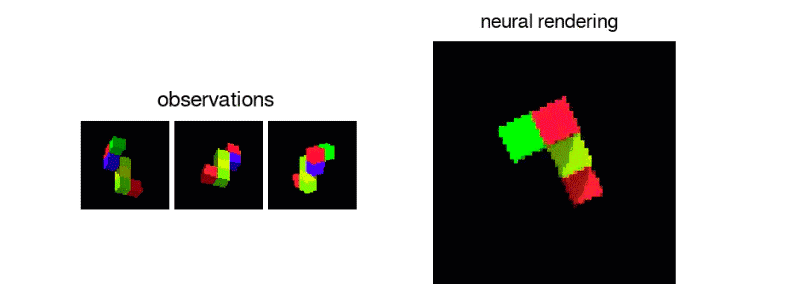
GQN模型由兩部分組成:表示網絡和世代網絡。表示網絡將察結果輸入并對基礎場景產生描述性質的的矢量表示,然后世代網絡從以前未觀察過的角度預測場景的表現。
表示網絡通過以分布式表示捕獲對象位置,顏色和房間布局等元素來實現準確描述場景的真實布局。該網絡能夠以高度壓縮和抽象的方式描述場景,并將其留給世代網絡,從而可以在必要時加入詳細信息。
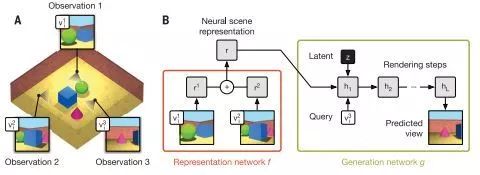
世代網絡就像是一個近似的3D渲染器,它可以以非常精確的方式從新視角預測以前未觀測到的場景。當給出場景和新的攝像機視點時,無需事先規定透視法,遮擋法或照明法,它就可以生成清晰的圖像。
那么,GQN的可行性如何?
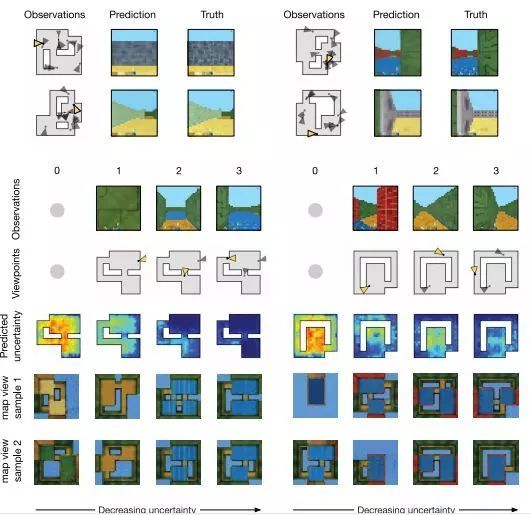
為了評估該框架的可行性,研究人員在模擬的3D環境中進行了一系列嘗試。在第一組實驗中,研究人員采用了包含各種對象的方形房間中的場景,墻面紋理、物體和燈的形狀、位置和顏色都是隨機的,以此有效地實現無限數量的總場景配置;隨后,研究人員使用有限數據集來訓練和測試模型。訓練結束后,GQN通過觀察一個先前未學習的測試場景的圖像來計算其場景表示,隨后的結果顯示,發生器在視點處的預測是高度準確的,大部分與地面事實并沒有區別。
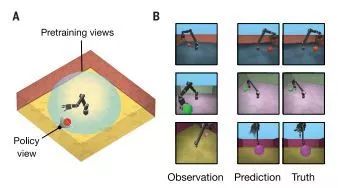
在這個實驗中,GQN不可能通過隨機的方式準確預測結果,它只能通過在場景感知和編碼物體的數量、位置、顏色,還有墻壁的顏色以及光源的間接觀察位置的方式來學習。與傳統的神經網絡學習不同,GQN學習如何從圖像中進行推理,而不需要對場景內容進行任何明確的人為標注。實驗過程中,當場景的內容重度遮擋的情況時,預測模型就會出現不確定的情況,這種情況反映在最終結果的的變化性上。
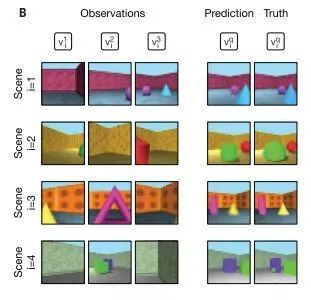
隨后研究人員還采用了更復雜,程序化的迷宮環境來測試GQN的縮放屬性。迷宮由通過走廊連接的多個房間組成,不同場景中迷宮的布局和墻壁的顏色都是隨機的。在這個實驗中,任何一次觀察都會提供有關當前迷宮的少量信息。在進行多次識別觀測后, GQN已經可以在新的攝像機視點做出對迷宮環境正確的預測;在進一步的訓練中,模型甚至還可以高度準確地預測迷宮自上而下的視圖。
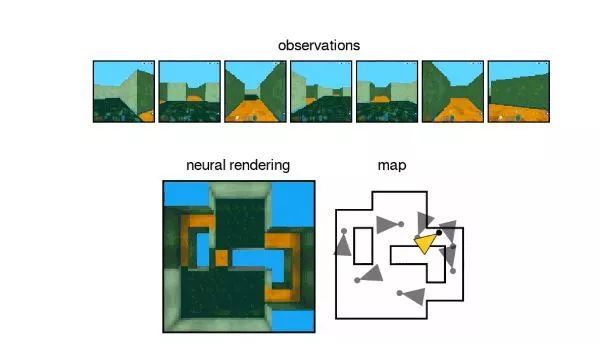
在這個實驗中,預測模型的不確定性隨著觀測數量的增大而降低,經過大約五次觀察后,GQN的不確定性幾乎完全消失。
現在的GQN還只能在實驗室實現,主要是因為需要受控分析、真實數據集的可用性有限、不足以生成復雜的模型等原因,但它的確可以處理視覺的遮擋、場景的組合等問題。隨著新的數據集可用化和建模能力的增強,GQN也會逐漸實現應用。
-
神經網絡
+關注
關注
42文章
4793瀏覽量
101969 -
計算機視覺
+關注
關注
8文章
1704瀏覽量
46377
原文標題:計算機視覺也可以腦補了?
文章出處:【微信號:ARchan_TT,微信公眾號:AR醬】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監

評論