") 分享下Kaiming大神在CVPR‘18 又有了什么新成果?
分享下Kaiming大神在CVPR‘18 又有了什么新成果?
一年一度的CVPR這就來(lái)了,各種前沿的、新奇的、驚人的成果又將給我們帶來(lái)全新的認(rèn)知。忍不住想去關(guān)注大神們的杰出工作,其中曾獲得兩次CVPR最佳論文的Kaiming是第一個(gè)想要檢索的對(duì)象。在今年的主論壇上,共有四篇論文出現(xiàn)了Kaiming He的身影,他們分別是:
圖像分割領(lǐng)域的:Learning to Segment Every Thing;
利用數(shù)據(jù)蒸餾的全向監(jiān)督學(xué)習(xí):Data Distillation:Toward Omni-Supervised Learning;
研究人與物互動(dòng):Detecting and Recognizing Human-Object Interactions;
一種非局域的神經(jīng)網(wǎng)絡(luò)結(jié)果:Non-Local Neural Netwroks。
(另一位著名的rbg大牛也是這四篇論文的共同作者>>http://www.rossgirshick.info/)
下面就讓我們一起來(lái)學(xué)習(xí)這四篇論文中的精妙思想吧!

目標(biāo)檢測(cè)中最有趣的工作之一就是預(yù)測(cè)被檢測(cè)物體的前景掩膜了,這項(xiàng)被稱為實(shí)例分割的任務(wù)能將每個(gè)物體所包含的像素精確的預(yù)測(cè)出來(lái)。但在實(shí)際中的系統(tǒng)只包含了視覺(jué)世界的一小類物體,大約100中的目標(biāo)分類限制了它的應(yīng)用。這主要是由于先進(jìn)的實(shí)例分割算法需要強(qiáng)監(jiān)督樣本進(jìn)行訓(xùn)練。目前的訓(xùn)練數(shù)據(jù)類別有限而增添一個(gè)新類別的強(qiáng)監(jiān)督實(shí)例分割樣本十分耗時(shí)耗力。但另一方面,邊界框標(biāo)記的樣本卻十分豐富也容易獲取。于是研究人員提出了一個(gè)想法:有沒(méi)有可能不依靠完整的實(shí)例分割標(biāo)記來(lái)生成對(duì)于所有類都有效的高質(zhì)量分割模型呢?在這個(gè)想法的指導(dǎo)下,這篇論文引入了一種新的部分監(jiān)督實(shí)例分割任務(wù),并提出了一種新穎的遷移學(xué)習(xí)方法來(lái)解決這一問(wèn)題。
這一新的半監(jiān)督問(wèn)題定義如下:1.訓(xùn)練數(shù)據(jù)中包含很多類對(duì)象,只有很小的子集類別擁有實(shí)例掩膜標(biāo)注而其余只有邊界框標(biāo)記;2.實(shí)例分割算法需要充分利用這些數(shù)據(jù)來(lái)生成一個(gè)可以為數(shù)據(jù)集中所有類別預(yù)測(cè)實(shí)例分割的模型。由于訓(xùn)練數(shù)據(jù)是強(qiáng)標(biāo)記(掩膜)和弱標(biāo)記(邊框)數(shù)據(jù)的混合,所以將這一任務(wù)稱為部分監(jiān)督學(xué)習(xí)。
部分監(jiān)督任務(wù)最主要的優(yōu)點(diǎn)在于可以通過(guò)對(duì)已有小類別掩膜標(biāo)記數(shù)據(jù)和大類被邊框標(biāo)記數(shù)據(jù)的探索,建立大規(guī)模的實(shí)例分割模型,得以將在小類別上表現(xiàn)優(yōu)異的先進(jìn)模型拓展到上千個(gè)分類中去,這對(duì)于實(shí)際生活中的使用至關(guān)重要。
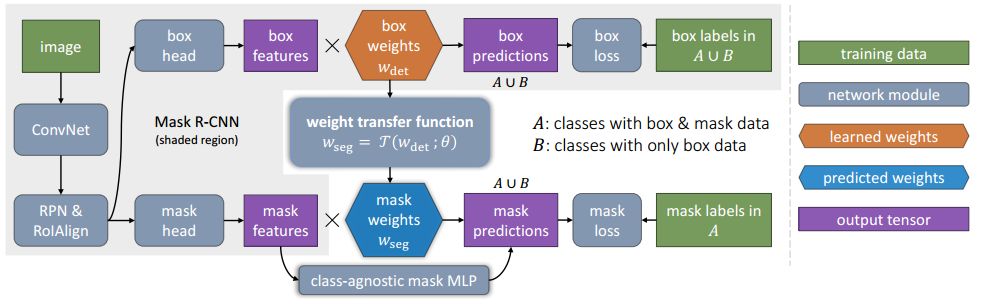
在具體實(shí)現(xiàn)過(guò)程中,基于Mask R-CNN提出了一種新穎的遷移學(xué)習(xí)方法。Mask R-CNN可以將實(shí)例分割問(wèn)題分解為邊框目標(biāo)檢測(cè)和掩膜預(yù)測(cè)兩個(gè)子任務(wù)。在訓(xùn)練中分類信息會(huì)被編碼到邊框頭單元中,就可以將這一視覺(jué)類別信息遷移到部分監(jiān)督的掩膜頭中去。其次,作者還提出了一個(gè)稱為權(quán)重遷移函數(shù)的單元用于從邊框參數(shù)預(yù)測(cè)出每一分類的分割參數(shù)。在預(yù)測(cè)時(shí),它將用于對(duì)每一類物體預(yù)測(cè)實(shí)例分割的參數(shù),包括在訓(xùn)練時(shí)沒(méi)有掩膜標(biāo)記的類別。
圖中綠框表示擁有掩膜標(biāo)記的類別和紅框則表示只有邊框標(biāo)記,而后預(yù)測(cè)出掩膜的類別。
最終通過(guò)學(xué)習(xí)小類別中邊框到分割的權(quán)重遷移函數(shù),成功地通過(guò)混合數(shù)據(jù)的訓(xùn)練實(shí)現(xiàn)了部分監(jiān)督學(xué)習(xí),將強(qiáng)大的圖像分割模型拓展到了3000類物體中。也開(kāi)拓了非全監(jiān)督條件下大規(guī)模實(shí)例分割的研究方向。
論文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Learning_to_Segment_CVPR_2018_paper.pdf

這篇文章同樣是關(guān)于充分利用數(shù)據(jù)方面的工作,探索了一種稱為全向監(jiān)督學(xué)習(xí)的機(jī)制來(lái)使得模型盡可能的利用標(biāo)記數(shù)據(jù),并提供了潛在的無(wú)限制的無(wú)標(biāo)記數(shù)據(jù),它屬于半監(jiān)督學(xué)習(xí)的一個(gè)特殊領(lǐng)域。但目前大多數(shù)研究人員研究半監(jiān)督問(wèn)題主要從標(biāo)記數(shù)據(jù)中分割出標(biāo)記和未標(biāo)記數(shù)據(jù)來(lái)模擬這樣的數(shù)據(jù)集,這樣的方法就決定了其上限是利用所有標(biāo)記數(shù)據(jù)來(lái)實(shí)現(xiàn)的全監(jiān)督學(xué)習(xí)。而全向監(jiān)督學(xué)習(xí)則是利用所有的標(biāo)記數(shù)據(jù)得到的精確結(jié)果作為模型的下限,來(lái)探索超越全監(jiān)督學(xué)習(xí)基線的可能性。
這篇文章在模型精煉思想的啟發(fā)下提出了數(shù)據(jù)精餾的方法來(lái)處理全向監(jiān)督問(wèn)題。首先了利用大規(guī)模標(biāo)記數(shù)據(jù)訓(xùn)練的模型來(lái)為無(wú)標(biāo)簽數(shù)據(jù)創(chuàng)建標(biāo)簽;隨后又將新得到的標(biāo)簽數(shù)據(jù)與原數(shù)據(jù)一起訓(xùn)練新的模型。為了避免模型預(yù)測(cè)的數(shù)據(jù)標(biāo)簽沒(méi)有意義,研究人員利用的單個(gè)模型對(duì)不同變換后(翻轉(zhuǎn)和尺度變換)未標(biāo)記數(shù)據(jù)進(jìn)行處理并組合了它們的結(jié)果,通過(guò)數(shù)據(jù)變化來(lái)增強(qiáng)單個(gè)模型的精度。
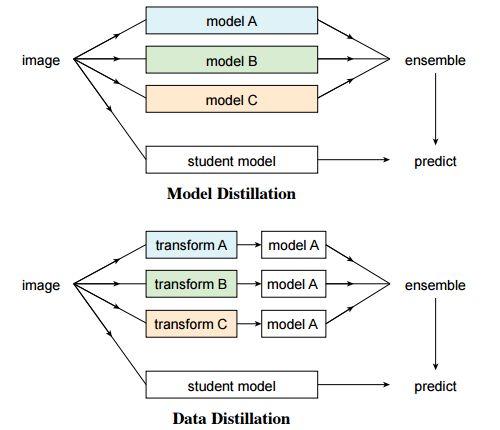
實(shí)驗(yàn)證明這樣的變換可以提供不尋常的信息。換句話說(shuō),和利用多個(gè)模型來(lái)精煉知識(shí)的預(yù)測(cè)方法相比,這種方法通過(guò)單個(gè)模型在不同變化下的非標(biāo)簽數(shù)據(jù)中進(jìn)行了數(shù)據(jù)精餾。
由于全監(jiān)督學(xué)習(xí)模型的飛速發(fā)展,目前的模型產(chǎn)生的錯(cuò)誤越來(lái)越少,對(duì)于未知數(shù)據(jù)的預(yù)測(cè)結(jié)果也越來(lái)越可信。所以數(shù)據(jù)精餾無(wú)需改變識(shí)別模型,并且可以用于規(guī)模化的處理大規(guī)模未標(biāo)記數(shù)據(jù)。
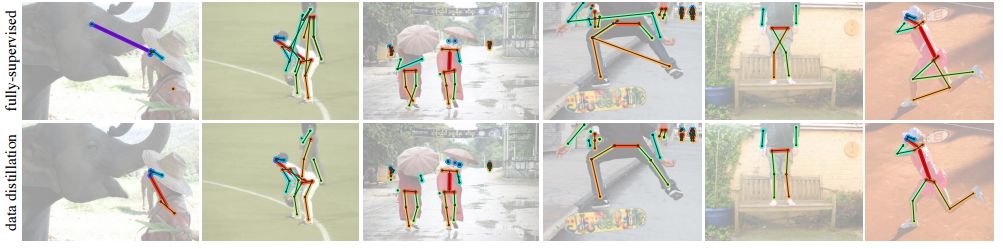
為了驗(yàn)證對(duì)于全向監(jiān)督學(xué)習(xí)的數(shù)據(jù)蒸餾是否有效,在COCO數(shù)據(jù)集上對(duì)人體關(guān)鍵點(diǎn)檢測(cè)任務(wù)進(jìn)行了測(cè)評(píng)。通過(guò)原始標(biāo)記的COCO數(shù)據(jù)集和連一個(gè)大規(guī)模非標(biāo)記數(shù)據(jù)集(Sports-1M)進(jìn)行數(shù)據(jù)精餾并訓(xùn)練了Mask R-CNN模型。
通過(guò)模型對(duì)未標(biāo)記數(shù)據(jù)生成的標(biāo)注
通過(guò)對(duì)未標(biāo)記數(shù)據(jù)的精餾,研究人員觀察到了留存驗(yàn)證集上精度的明顯提升:對(duì)于基準(zhǔn)Mask R-CNN提升了2個(gè)點(diǎn)AP;作為參考的是利用相同數(shù)據(jù)量的手工標(biāo)記數(shù)據(jù)得到了近3個(gè)點(diǎn)的提升,這說(shuō)明利用本文的方法是有希望利用未標(biāo)記數(shù)據(jù)提高模型表現(xiàn)的。
利用數(shù)據(jù)精餾實(shí)現(xiàn)的結(jié)果
總結(jié)一下,本文主要探索了利用全向監(jiān)督學(xué)習(xí)(omni-supervised)的方法超越大規(guī)模全監(jiān)督學(xué)習(xí)的可能性,利用所有的監(jiān)督數(shù)據(jù)與非監(jiān)督數(shù)據(jù)的精餾來(lái)實(shí)現(xiàn)提升。
論文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Radosavovic_Data_Distillation_Towards_CVPR_2018_paper.pdf

第三篇文章提出了一種以人為中心的思想,通過(guò)圖像中出現(xiàn)的人作為一個(gè)強(qiáng)大的線索來(lái)定為與之交互的對(duì)象,并基于這個(gè)想法開(kāi)發(fā)了稱為InteractNet的模型,檢測(cè)<人、動(dòng)作、對(duì)象>三元組,實(shí)現(xiàn)人與物之間交互的檢測(cè)與識(shí)別。
在視覺(jué)任務(wù)中,理解圖像中發(fā)生了什么除了檢測(cè)出其中的對(duì)象,還需要識(shí)別出對(duì)象間的關(guān)系,這篇文章主要集中與解決人與物的交互。識(shí)別人與物之間的交互關(guān)系可以被表示為檢測(cè)<人、動(dòng)作、對(duì)象>三元組的過(guò)程。在互聯(lián)網(wǎng)的圖片中有很大部分包含了人物,所以以人為中心的理解具有很大的現(xiàn)實(shí)意義。事實(shí)上在研究者看來(lái),圖片中的任務(wù)提供了豐富的動(dòng)作信息,并銜接了與其發(fā)生交互的物體。但對(duì)于細(xì)粒度的人體行為及其交互的多種類的對(duì)象識(shí)別比起單純的對(duì)象檢測(cè)來(lái)說(shuō)還面臨著一系列挑戰(zhàn)。
研究人員們發(fā)現(xiàn)圖片中的人物的行為和姿態(tài)中包含了大量與之交互物體的位置信息,所以基于這一前提相關(guān)物體的搜索范圍可以大大縮小。雖然每幅圖像中會(huì)檢測(cè)大大量物體,但由人體預(yù)測(cè)的目標(biāo)位置可以幫助模型迅速地找到與特定動(dòng)作相關(guān)的目標(biāo)物體。研究人員把這一想法稱為“以人為中心”的識(shí)別,并利用Faster R-CNN框架進(jìn)行了實(shí)現(xiàn)。
具體來(lái)說(shuō),在與人物相關(guān)的ROI中,這個(gè)分支實(shí)現(xiàn)了行為分類和對(duì)行為目標(biāo)物體的密度估計(jì)。密度估計(jì)器生成一個(gè)四維的高斯分布,對(duì)于每一種行為模型將會(huì)把目標(biāo)對(duì)象的位置與人物聯(lián)系起來(lái)。這個(gè)以人為中的識(shí)別分支與另一個(gè)簡(jiǎn)單的對(duì)偶交互分支一起組成了多任務(wù)的學(xué)習(xí)系統(tǒng),并可以聯(lián)合優(yōu)化。
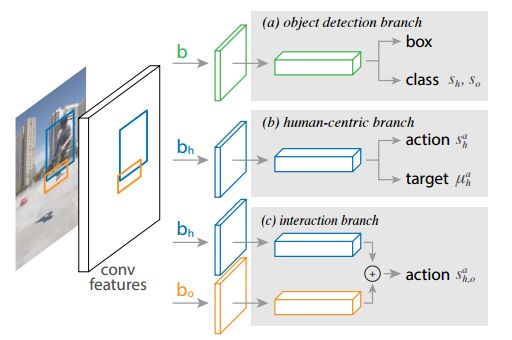
基于faster R-CNN的三分支架構(gòu)
作者最后在V-COCO數(shù)據(jù)集上進(jìn)行了測(cè)評(píng),實(shí)現(xiàn)了26%的AP(31.8to40.0)提升,這主要來(lái)自于利用與人物相關(guān)的目標(biāo)位置。同時(shí)這一稱為InteractNet的模型在HICO-DET數(shù)據(jù)集上實(shí)現(xiàn)了27%的提升。在復(fù)雜任務(wù)中達(dá)到了135ms/image的速度,具有潛在的實(shí)用性。
與動(dòng)作相關(guān)目標(biāo)區(qū)域的估計(jì)
一些結(jié)果展示
想了解實(shí)現(xiàn)的細(xì)節(jié),請(qǐng)看論文中的具體描述:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Gkioxari_Detecting_and_Recognizing_CVPR_2018_paper.pdf

第四篇論文提出了一非局域化的操作單元來(lái)獲取長(zhǎng)程的依賴信息。在這種構(gòu)建單元的幫助下,模型可以在視頻分類任務(wù)和靜態(tài)目標(biāo)檢測(cè)任務(wù)中得到十分優(yōu)異的表現(xiàn)。
在深度神經(jīng)網(wǎng)絡(luò)中長(zhǎng)程依賴性的抓取是十分重要的,對(duì)于序列數(shù)據(jù)來(lái)說(shuō)一般采用遞歸操作來(lái)實(shí)現(xiàn),而對(duì)于圖像數(shù)據(jù)則主要通過(guò)深層卷積操作的堆疊而實(shí)現(xiàn)大感受野來(lái)實(shí)現(xiàn)。但卷積和遞歸操作主要用于處理時(shí)空局域信息,所以長(zhǎng)程(大范圍)依賴性只能通過(guò)重復(fù)的操作,逐步傳播信號(hào)來(lái)獲取。這樣的重復(fù)操作會(huì)帶來(lái)一系列局限性:首先是計(jì)算效率低;其次導(dǎo)致了優(yōu)化困難;最后這樣的方法使得處理不同節(jié)點(diǎn)間信息來(lái)回傳輸?shù)亩啻畏瓷湟蕾嚹P妥兊檬掷щy。
為了克服這些困難,在這篇文章中作者提出了一種非局域的操作,作為高效、簡(jiǎn)便、通用的模塊用于深度神經(jīng)網(wǎng)絡(luò)來(lái)抽取長(zhǎng)程依賴性。這種操作是傳統(tǒng)非局域化均值操作的泛化,它通過(guò)加權(quán)輸入特征圖的所有位置特征來(lái)計(jì)算某一位置的響應(yīng),而這些位置可以是空間、時(shí)間或者是時(shí)空相關(guān)的,所以它適用于圖像、序列和視頻信號(hào)的處理。
非局域操作的優(yōu)點(diǎn)有以下三個(gè)方面:首先與卷積和遞歸的逐漸傳播過(guò)程相比,非局域操作可以直接通過(guò)計(jì)算位置間的相互作用來(lái)抓取長(zhǎng)程特征;其次高效率的操作在少數(shù)幾層的模型下也能取得很好的結(jié)果;最后它可以適應(yīng)變化大小的輸入并便捷地集成到其他操作中去。
在視頻中像素具有時(shí)空上的長(zhǎng)程相關(guān)性,單個(gè)非局域單元可以直接在前饋中抓取這些時(shí)空相關(guān)性。通過(guò)少數(shù)幾個(gè)非局域單元構(gòu)建的非局域神經(jīng)網(wǎng)絡(luò)來(lái)對(duì)視頻進(jìn)行處理其精度要優(yōu)于傳統(tǒng)的2D/3D卷積網(wǎng)絡(luò)。同時(shí),非局域神經(jīng)網(wǎng)絡(luò)相比于3D卷積計(jì)算更經(jīng)濟(jì)。
其數(shù)學(xué)表示如下:
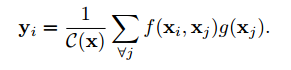
x為輸入信號(hào)(圖像、視頻、序列、特征等)y為相同大小的輸出信號(hào),i表示輸出結(jié)果中位置i的索引,它由所有可能位置j的響應(yīng)結(jié)果來(lái)計(jì)算。其中f用于計(jì)算位置ij之間的關(guān)系,而g用于計(jì)算輸入信號(hào)在位置j出的表示。C表述響應(yīng)的歸一化函數(shù)。
其構(gòu)成的空時(shí)計(jì)算單元結(jié)構(gòu)如下圖所示:
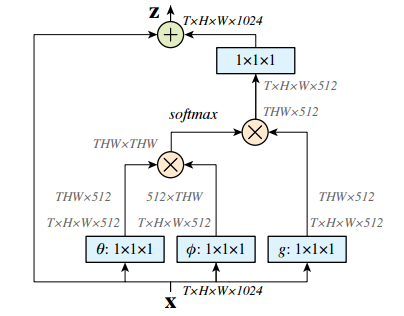
其中輸入為特征張量,其中g(shù)可以通過(guò)1*1卷積實(shí)現(xiàn),而計(jì)算相關(guān)性的函數(shù)可以由高斯和embedded高斯來(lái)實(shí)現(xiàn)。這里使用softmax來(lái)進(jìn)行歸一化。具體實(shí)現(xiàn)請(qǐng)參看論文,其中描述了公式中的每一步包括f的點(diǎn)乘、相互聯(lián)系等方式的實(shí)現(xiàn),以及非局域化單元的實(shí)現(xiàn)。
在Kinetics和Charades數(shù)據(jù)集中,僅僅使用RGB圖像而不使用各種花哨的技巧,這種方法就能得到與當(dāng)前最好算法相比擬(甚至更好)的結(jié)果。同時(shí)在COCO數(shù)據(jù)集上這種方法可以提高目標(biāo)檢測(cè)、分割和位姿估計(jì)三個(gè)任務(wù)的精度,而只需要引入很少的而外計(jì)算。對(duì)于視頻和圖像的處理證明非局域化操作具有通用性,并將成為深度網(wǎng)絡(luò)的基本構(gòu)建單元。
論文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.pdf
除此之外,Kaiming還將在今年的CVPR上帶來(lái)名為Visual Recognition and Beyond的教程,內(nèi)容包括視覺(jué)識(shí)別的前沿研究領(lǐng)域及其在高級(jí)任務(wù)中的應(yīng)用。Kaiming,Ross Girshick,Alex Kirillov將從不同角度闡述圖像分類、目標(biāo)檢測(cè)、實(shí)例分割和語(yǔ)義分割后支撐的方法和原理,而后Georgia Gkioxari和Justin Johnson將會(huì)在兩個(gè)報(bào)告中探索基于行為和推理視覺(jué)識(shí)別的新任務(wù)。感興趣的小伙伴可以關(guān)注:
https://sites.google.com/view/cvpr2018-recognition-tutorial
http://kaiminghe.com/
另外,從Facebook Research的網(wǎng)站查詢后發(fā)現(xiàn),幾年CVPR共接收其論文28篇,除了上述四篇外,各領(lǐng)域文章如下,有興趣的小伙伴可以進(jìn)行更深入的學(xué)習(xí)。(點(diǎn)擊圖片放大)

-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4776瀏覽量
100925 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18021 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24744
原文標(biāo)題:蹭熱度 | 梳理下Kaiming大神在CVPR‘18 又有了什么新成果?(贈(zèng)論文下載工具)
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
北斗在列 中國(guó)八大神器震驚全球
中國(guó)在量子科技領(lǐng)域又有新突破!
ProbeRequest是什么 它又有什么作用
lsh_tracking_cvpr2013英文版資料
國(guó)外大神惡搞iOS10.2.1-10.3越獄, 看的人差點(diǎn)就信了!
大神F2聯(lián)通版性能怎么樣
62篇論文入選十年來(lái)最難CVPR,商湯研究再創(chuàng)佳績(jī)
AI觀察室(三)|頂會(huì)推薦!獲選CVPR oral paper的Xilinx AI研發(fā)團(tuán)隊(duì)最新成果揭秘
CVPR 2021華為諾亞方舟實(shí)驗(yàn)室發(fā)表30篇論文 |CVPR 2021

CVPR2020 | 對(duì)數(shù)字屏幕拍照時(shí)的摩爾紋怎么去除?
CVPR2020 | MAL:聯(lián)合解決目標(biāo)檢測(cè)中的定位與分類問(wèn)題,自動(dòng)選擇最佳a(bǔ)nchor
深蘭團(tuán)隊(duì)已連續(xù)5年在CVPR挑戰(zhàn)賽中斬獲冠軍
高通在2023年國(guó)際計(jì)算機(jī)視覺(jué)與模式識(shí)別會(huì)議上,展示先進(jìn)研究成果并將生成式AI引入邊緣側(cè)
大神手工自制CPU的過(guò)程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論