

近日,伯克利大學發布了BDD100K,一個目前來說最大規模也是最多樣化的駕駛視頻數據集,這些數據具有四個主要特征:大規模,多樣化,在真實的街道采集,并帶有時間信息。數據的多樣性對于測試感知算法的魯棒性尤為重要。利用這個數據集,你還可以參加伯克利在CVPR 2018 舉辦的自動駕駛競賽,其在在arXiv上也發表了相關的介紹文章。
BDD100K: A Large-scale Diverse Driving Video Database
伯克利大學發布了BDD100K,一個目前來說最大規模也是最多樣化的駕駛視頻數據集,其中包含了豐富的各種標注信息。
論文:BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling

大規模,多樣化,駕駛,視頻:Pick Four
自動駕駛有望改變每個人的生活。然而,最近的一系列自動駕駛事故表明,還不清楚一個人造的駕駛感知系統如何才能能夠避免在人類看來是明顯的錯誤。作為計算機視覺研究人員,BAIR有興趣探索最前沿的自動駕駛感知算法,使其更安全。為了設計和測試潛在的算法,BAIR希望利用來自真實駕駛平臺收集的數據中的所有信息。這些數據具有四個主要特征:大規模,多樣化,在真實的街道采集,并帶有時間信息。數據的多樣性對于測試感知算法的魯棒性尤為重要。但是,當前的開放數據集只能覆蓋上述屬性的一個子集。因此,在Nexar【4】的幫助下,BAIR發布了BDD100K數據庫,這是迄今為止計算機視覺研究中規模最大,最多樣化的開放式駕駛視頻數據集。該項目是由Berkeley DeepDrive【5】工業聯盟組織和贊助的,該組織負責研究計算機視覺和汽車應用機器學習領域的最新技術。
圖:隨機視頻子集的位置。
正如名稱所示,BAIR的數據集包含100,000個視頻。 每個視頻長約40秒,720p,30 fps。視頻還附帶了由手機記錄的GPS/IMU信息,以顯示粗糙的駕駛軌跡。我們的視頻是從美國各地收集來的,如圖所示。BAIR的數據庫涵蓋了不同的天氣情況,包括晴天、陰天和雨天,以及白天和夜間的不同時段。下表總結了與以前的數據集的比較,這表明BAIR的數據集更大、更多樣化。
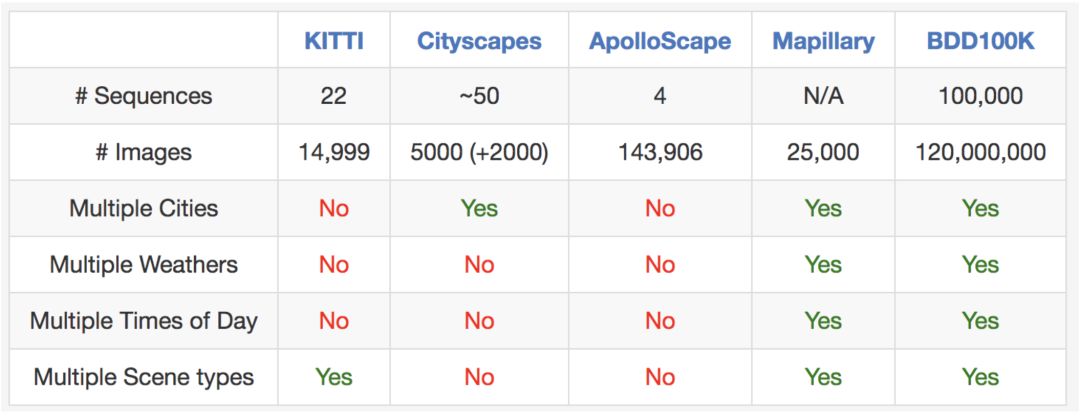
圖:與其他一些街景場景數據集比較。很難公平地比較數據集之間的#images,但我們在這里列出它們作為粗略參考。
這些視頻及其軌跡可以幫助我們模仿學習駕駛法規,如BAIR在CVPR 2017論文【6】中所述。為了便于對大規模數據集進行計算機視覺研究,BAIR還在視頻關鍵幀上做了基本的標注,詳見下一節。 您現在可以在【1】下載數據和標注。
標注(Annotations)
我們在每個視頻的第10秒采樣一個關鍵幀,并為這些關鍵幀提供標注。它們分別在多個層次上被標記:圖像標記,道路對象邊界框,可驅動區域,車道標記和全幀實例分段。這些標注將幫助我們理解不同類型場景中數據和對象統計的多樣性。 我們將在另一篇博文中討論標注的過程。有關標注的更多信息可以在BAIR的arXiv論文【2】中找到。
圖:BAIR標注信息的總覽
BAIR為經常出現在道路上的所有10萬個關鍵幀上的對象標上對象邊界框,以了解對象的分布及其位置。下面的條形圖顯示了對象計數。還有其他方法可以在我們的標注中使用統計信息。例如,我們可以比較不同天氣條件或不同類型場景下的對象數量。該圖表還顯示了BAIR數據集中出現的不同的對象集,以及數據集的規模——超過100萬輛汽車。這里應該提醒讀者,這些是不同的對象, 具有不同的外觀和背景。
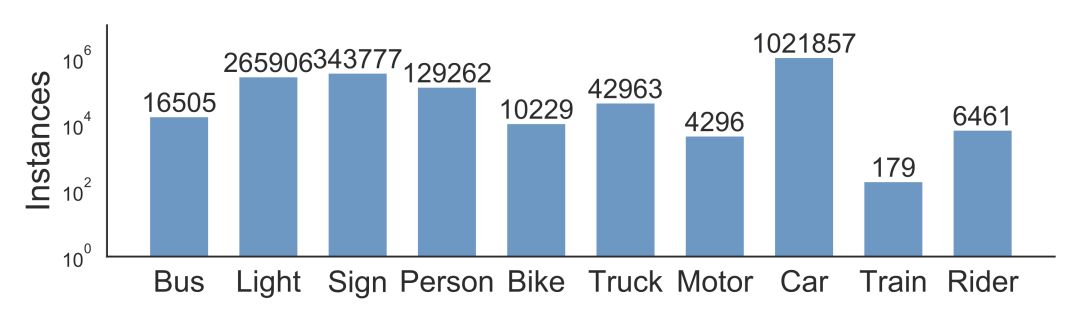
圖:統計不同類型的對象。
BAIR的數據集也適用于研究一些特定的領域。 例如,如果您對檢測和避開街上的行人感興趣,您也有理由研究BAIR數據集,因為它包含比以前的專業數據集更多的行人實例,如下表所示。
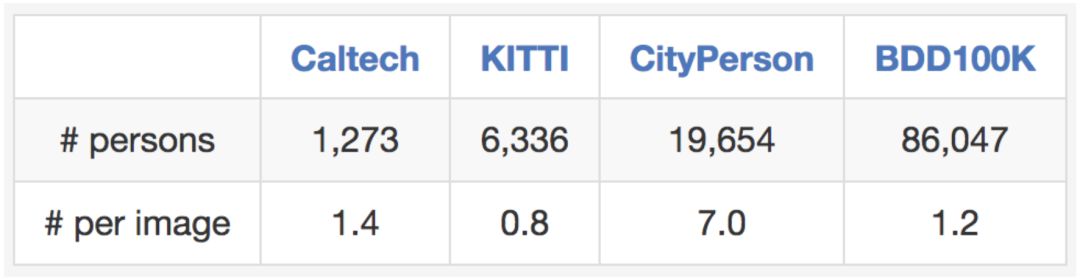
圖:與其他行人數據集關于訓練集大小的比較。
車道標記(Lane Markings)
車道標記是人類駕駛員重要的道路指示。當GPS或地圖沒有精準地全球覆蓋時,它們也是自動駕駛系統駕駛方向和定位的關鍵線索。根據車道如何指示車輛,我們將車道標記劃分為兩種類型。垂直車道標記(在下圖中用紅色標記)表示沿著車道行駛方向的標記。平行車道標記(下圖中以藍色標記)表示車道上的車輛需要停車的標志。BAIR還提供標記的屬性,例如實線與虛線以及雙層與單層。
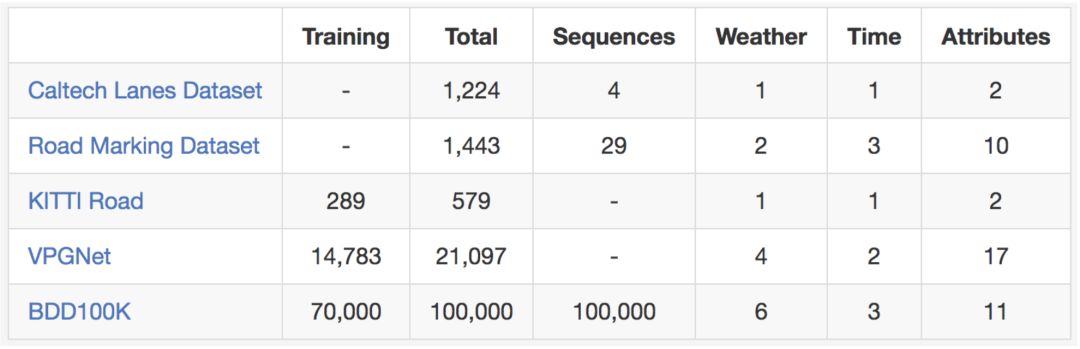
如果您準備嘗試使用您的車道標記預測算法,請不要再觀望。以下是與現有車道標記數據集的比較。
可行駛區域(Drivable Areas)
我們是否可以在道路上行駛不僅取決于車道標記和交通設備,它還取決于與道路上其他物體的復雜交互。最后,了解哪個區域可以開車是很重要的。 為了研究這個問題,我們還提供了可駕駛區域的分段標注,如下所示。我們根據自我車輛的軌跡將可駕駛區域分為兩類:直接可駕駛和替代可駕駛。直接可駕駛,用紅色標記,意味著自我車輛有道路優先權并且可以在那個區域繼續駕駛。另一種可駕駛的,用藍色標記,意味著自我車輛可以在該區域駕駛,但必須謹慎,因為道路優先權可能屬于其他車輛。
全幀分割(Full-frame Segmentation)
在Cityscapes數據集中已經顯示,全幀精細實例分割可以極大地加強密集預測和目標檢測的研究,這是計算機視覺能夠應用廣泛的支柱。由于我們的視頻處于不同的領域,因此我們還提供實例分割標注以便比較不同數據集的相對位置偏移。要獲得全像素級的分割可能是非常昂貴和費力的。幸運的是,使用我們自己的標注工具,標注成本可以降低50%。最后,我們對10K圖像的子集進行全幀實例分割。BAIR的標簽集與Cityscapes中的訓練標注相兼容,以便于研究數據集之間的域轉換。
駕駛挑戰賽(Driving Challenges)
BAIR將在CVPR2018自動駕駛workshop上主持了三項挑戰【7】:道路目標檢測,可駕駛區域預測和語義分割的領域適應。檢測任務要求你的算法在我們的測試圖像中找到所有的目標對象,而可駕駛區域預測需要細分汽車可以駕駛的區域。在域適應中,測試數據在中國收集。 因此系統會受到挑戰,要讓適應美國的模型在中國北京擁擠的街道上工作。您可以在登錄【8】BAIR的在線提交門戶網站后立即提交結果。請務必查看BAIR的工具包【9】,開始您的參與。
未來的工作
自駕車的感知系統絕非僅限于單目視頻。它還可能包括全景和立體聲視頻,以及其他類型的傳感器,如LiDAR和雷達。 BAIR希望在不久的將來能夠提供研究這些多模態傳感器的數據集。
-
機器學習
+關注
關注
66文章
8477瀏覽量
133790 -
數據集
+關注
關注
4文章
1219瀏覽量
25181 -
自動駕駛
+關注
關注
788文章
14102瀏覽量
168659
原文標題:伯克利發布史上最大規模自動駕駛視頻數據集BDD100K
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監

評論