") 一個高效的低延遲視頻語義分割算法
一個高效的低延遲視頻語義分割算法
在自動駕駛領(lǐng)域,目前基于深度學(xué)習(xí)的分割算法運(yùn)算負(fù)荷仍然較大,不能有效移植到嵌入式端,在車輛上運(yùn)行。在保證分割精度的情況下,如何才能達(dá)到高實時性?CVPR 2018商湯科技論文解讀第4期為您帶來解讀。
以下是在自動駕駛場景理解領(lǐng)域,商湯科技發(fā)表的一篇亮點報告(Spotlight)論文,提出極低延遲性的視頻語義分割算法。
簡介
近年來由于深度神經(jīng)網(wǎng)絡(luò),尤其全卷經(jīng)神經(jīng)網(wǎng)絡(luò)的迅速發(fā)展,圖像語義分割取得了飛速的進(jìn)展,但是如何高效的實現(xiàn)視頻語義分割仍然是一個極富挑戰(zhàn)性的問題。其困難在于:
與圖像分割相比,視頻分割通常涉及更多的數(shù)據(jù)。比如,視頻每秒通常包含15~30幀,分析視頻因而需要更多的計算資源;
許多實際應(yīng)用(如自動駕駛)中的視頻分割模塊需要實現(xiàn)視頻分割的低延遲性。
對于視頻語義分割任務(wù),大部分現(xiàn)有工作關(guān)注如何在每幀計算量和分割精度之間的達(dá)到一個平衡點,卻并沒有深入的思考和探討算法延遲性這個因素。現(xiàn)有工作可以被大致分為兩類:
高層特征的時序建模方法
中間層特征傳播的方法
前者主要在一個完整的逐幀模型上增加一些提取時序信息的操作,因此不能減少計算量。后者(如Clockwork Net、Deep Feature Flow等工作)通過重用歷史幀的特征來加速計算,這類方法可以減少視頻整體計算量,然而忽略了延遲方面的因素。這類方法的延遲和精度對比(如圖1所示),可以看出這類方法很難同時實現(xiàn)低延遲和高精度。我們的工作則立足降低每幀平均計算量的同時,實現(xiàn)分割的高精度,降低算法的最大延遲。
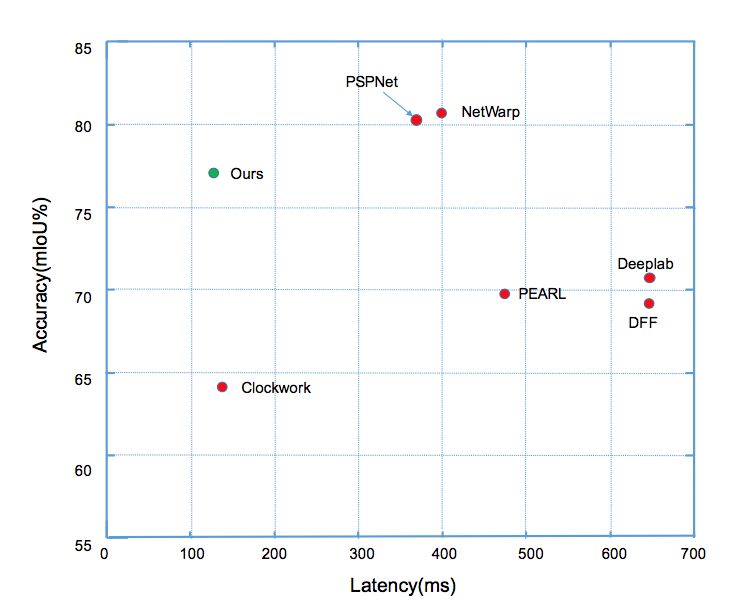
圖1:
Cityscapes數(shù)據(jù)集上
不同方法延遲和分割精度的對比
算法核心思想
本文算法使用視頻分割中經(jīng)典的基于關(guān)鍵幀調(diào)度的模式來有效平衡計算量和精度。具體來說,如果當(dāng)前處理幀為關(guān)鍵幀,則使用整個分割網(wǎng)絡(luò)來獲得語義分割的標(biāo)簽,如圖2左部分所示;如果當(dāng)前幀不為關(guān)鍵幀,則變換分割網(wǎng)絡(luò)高層歷史幀特征為當(dāng)前幀高層特征,再使用分割網(wǎng)絡(luò)的語義分類操作獲得當(dāng)前幀的語義標(biāo)簽,如圖2右部分所示。關(guān)鍵幀的選擇和特征跨幀傳播兩個操作均基于同樣的網(wǎng)絡(luò)低層特征,具體操作在之后章節(jié)詳述。在劃分分割網(wǎng)絡(luò)結(jié)構(gòu)時,算法盡量保證低層網(wǎng)絡(luò)的運(yùn)行時間遠(yuǎn)小于高層網(wǎng)絡(luò),(如圖2所示)低層網(wǎng)絡(luò)耗時61ms,而高層網(wǎng)絡(luò)耗時300ms。這樣考慮的出發(fā)點在于:
因低層網(wǎng)絡(luò)的計算代價很小,算法可以基于低層網(wǎng)絡(luò)提取的特征,增加少部分額外的計算來完成關(guān)鍵幀選擇和特征跨幀傳播;
當(dāng)前幀的低層特征同樣包含當(dāng)前幀的信息,可以互補(bǔ)來自不同時間的傳播特征;
所有的操作均復(fù)用了逐幀模型的結(jié)構(gòu),算法整體模型更加簡潔。
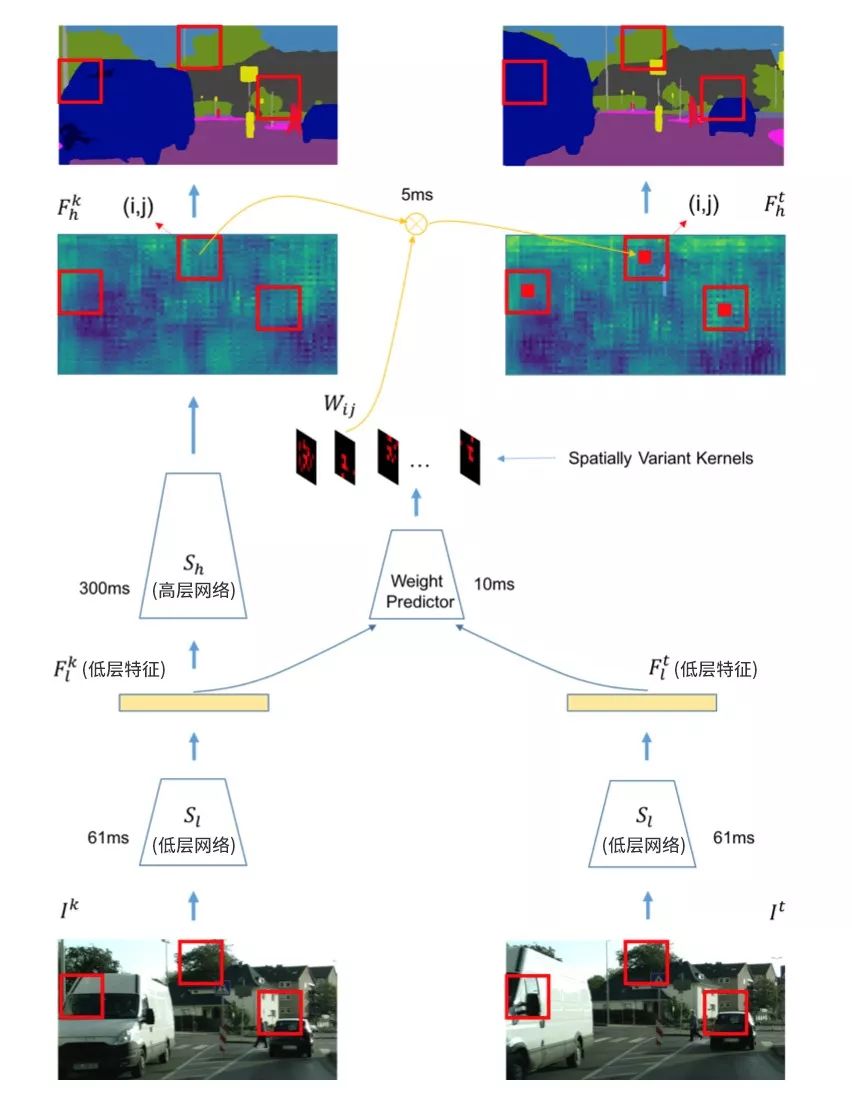
圖2:
自適應(yīng)特征傳播模塊
自適應(yīng)特征跨幀傳播
特征傳播關(guān)注如何從歷史幀傳播高層特征到當(dāng)前幀,降低模型總體計算量,先前的變換方法主要分為兩類:
基于圖像或底層特征獲取的光流信息,跨幀傳播不同幀的語義分類特征。這類方法雖然有效,但是計算光流往往代價太大,而獲得當(dāng)前幀的語義標(biāo)簽并不需要嚴(yán)格的點到點映射。
平移不變性卷積。這種操作在每個位置均使用相同的卷積核來映射特征,因此不能適應(yīng)不同位置的內(nèi)容變化。
本文設(shè)計了一個位置相關(guān)的卷積操作來進(jìn)行跨幀特征傳播。它的計算量相對較低,同時又能適應(yīng)不同位置的特征進(jìn)行自適應(yīng)傳播。不同位置的卷積核參數(shù)通過一個小的網(wǎng)絡(luò)回歸學(xué)習(xí)獲得(如圖2中weight predictor所示),其能很好的適應(yīng)不同空間位置內(nèi)容的變化。整體特征傳播模塊(包含當(dāng)前幀低層網(wǎng)絡(luò)、卷積核預(yù)測和空間變化卷積)包含兩大優(yōu)勢:
總體計算量相較高層網(wǎng)絡(luò)部分計算量大為減小,因而可以快速的獲得當(dāng)前幀的語義標(biāo)簽;
可以很好的保持視頻鄰近幀的抖動或者其他快速變化,實驗結(jié)果表明這種卷積操作融合方法能夠有效的提升7% mIOU的精度。
整體結(jié)果如表1所示,結(jié)果展示了本文算法復(fù)用逐幀網(wǎng)絡(luò)的優(yōu)勢,可以從低層網(wǎng)絡(luò)提取的特征來互補(bǔ)跨幀傳播的特征。

表1:
不同特征傳播模塊對最終分割精度的影響
自適應(yīng)關(guān)鍵幀調(diào)度
視頻處理算法中,一個好的關(guān)鍵幀選擇算法能夠隨視頻內(nèi)容變化自適應(yīng)的調(diào)整關(guān)鍵幀選擇頻率,在視頻內(nèi)容變化大的時間區(qū)間更多的選擇關(guān)鍵幀,而在視頻變化緩慢的區(qū)間較少的選擇關(guān)鍵幀,從而在有效保持視頻流中信息的前提下,降低整體計算量。現(xiàn)有的關(guān)鍵幀調(diào)度算法分為固定長度調(diào)度和基于閾值調(diào)度兩種方案,前者每隔n幀選擇一次關(guān)鍵幀,這種方式不能適應(yīng)不同視頻幀之間內(nèi)容的變化,后者則通過計算當(dāng)前幀高層特征和歷史幀高層特征之間的差值,通過設(shè)定一個閾值來決定是否是否選擇當(dāng)前幀為關(guān)鍵幀,這種方法能一定程度的適應(yīng)不同幀之間的內(nèi)容變化,但是特征的差值容易波動,較難設(shè)定一個統(tǒng)一的閾值。
本文算法使用當(dāng)前幀語義標(biāo)簽和前一個關(guān)鍵幀語義標(biāo)簽的差異值來作為視頻內(nèi)容變化程度的判斷依據(jù),如圖3所示,若當(dāng)前幀距上一個關(guān)鍵幀越遠(yuǎn),則語義標(biāo)簽的差值就越大。當(dāng)差值超過某個閾值的時候,則選擇該幀作為關(guān)鍵幀。但是直接計算這樣一個差異值較為困難,本文在Cityscapes和Camvid兩個數(shù)據(jù)集上發(fā)現(xiàn)低層特征和語義標(biāo)簽的變化值有很大的關(guān)聯(lián),因而利用低層特征來預(yù)測這樣該差值,即輸入歷史幀低層特征和當(dāng)前幀低層特征到一個回歸器來回歸該差異值。不同的關(guān)鍵幀選擇策略的結(jié)果如圖4所示,所有的策略均采用本文提出的自適應(yīng)特征傳播方法,可以看出提出的自適應(yīng)關(guān)鍵幀調(diào)度方法明顯優(yōu)于基于固定間隔和基于高層特征差值閾值的調(diào)度策略。
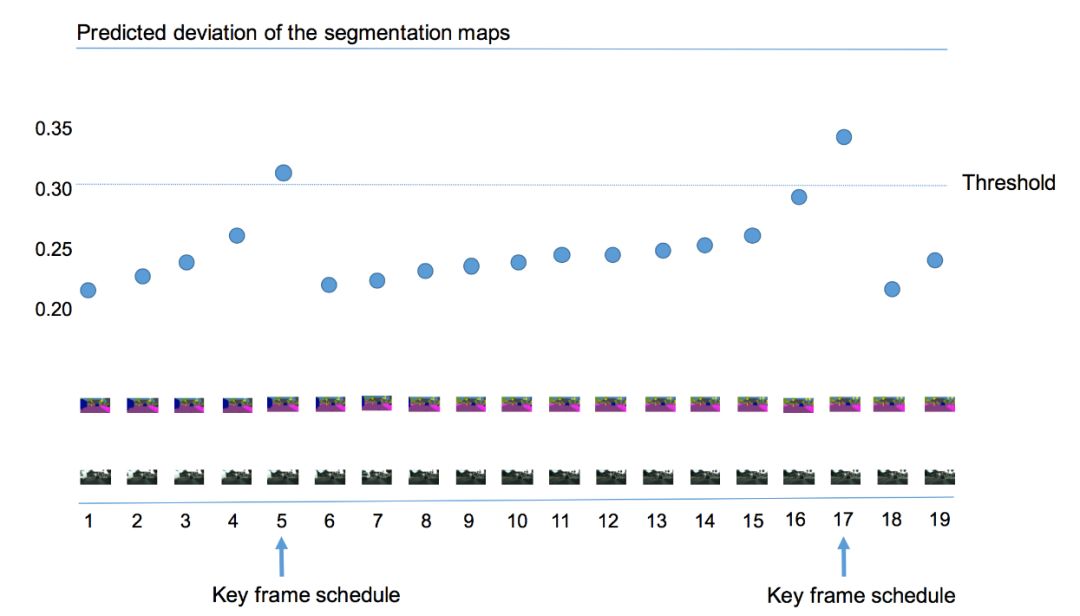
圖3:
自適應(yīng)的關(guān)鍵幀選擇
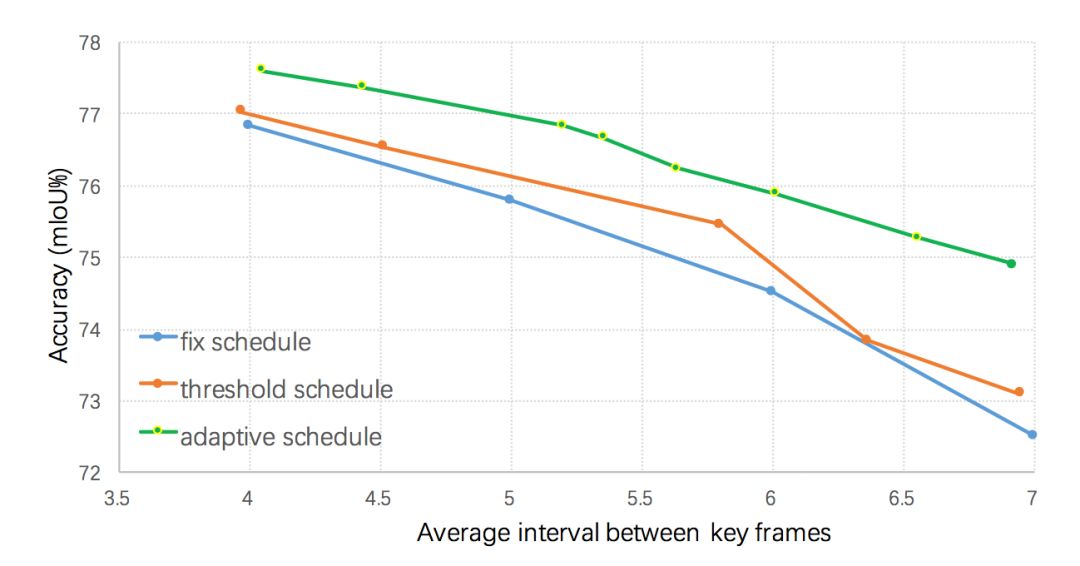
圖4:
不同調(diào)度策略對最終分割性能的影響
整體系統(tǒng)框架
本文算法整體框架如圖5所示,當(dāng)視頻的序列幀不斷輸入時,在第一幀時刻,進(jìn)行初始化操作,即輸入圖片幀給整個網(wǎng)絡(luò),獲得低層特征和高層特征。在接下來的時刻t進(jìn)行自適應(yīng)的計算,首先計算低層特征:輸入和上一個關(guān)鍵幀低層特征至自適應(yīng)關(guān)鍵幀選擇模塊,判斷當(dāng)前幀是否為關(guān)鍵幀。若為關(guān)鍵幀,則輸入底層特征至高層網(wǎng)絡(luò)獲得高層特征;否則輸入底層特征至自適應(yīng)特征傳播模塊獲得當(dāng)前幀高層特征,進(jìn)而通過語義分類獲得當(dāng)前幀語義標(biāo)簽。
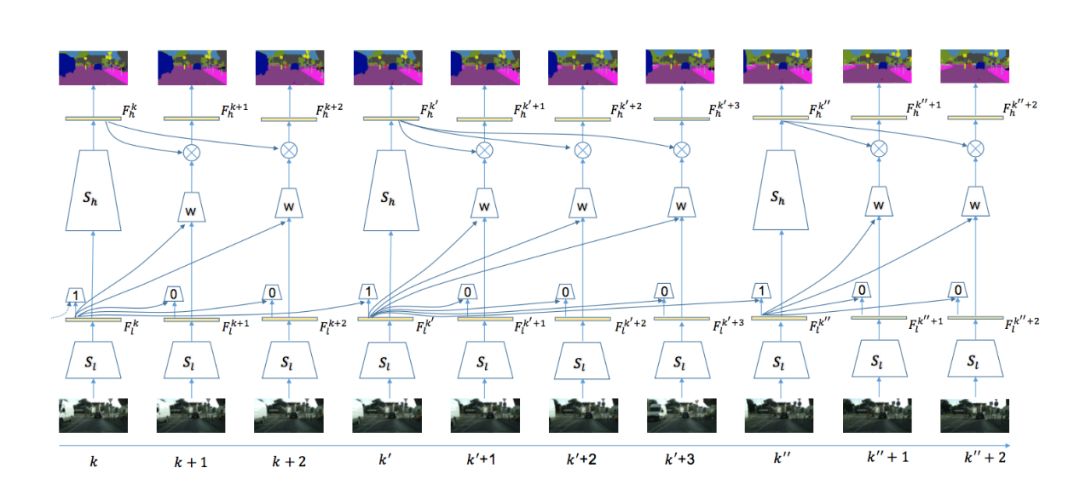
圖5:
系統(tǒng)整體框架示意圖
該系統(tǒng)極大的減少了整體耗時,其中判斷關(guān)鍵幀操作耗時僅20ms,跨幀特征傳播僅需38ms,而高層網(wǎng)絡(luò)計算高層特征則需要299ms。通過這種方式,整個系統(tǒng)可以明顯的降低系統(tǒng)的平均每幀計算量(如表2所示),自適應(yīng)調(diào)度策略和自適應(yīng)特征傳播方法可以把每幀平均計算時間由360ms減為171ms,精度僅損失3.4% mIOU。
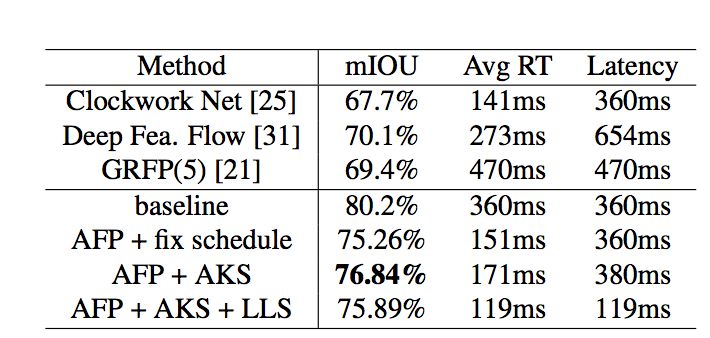
表2:
Cityscape數(shù)據(jù)集上
與目前先進(jìn)方法結(jié)果的對比
同時本文設(shè)計了一種低延遲的調(diào)度策略進(jìn)一步減少整體系統(tǒng)的延遲,適用于自動駕駛等需要及時響應(yīng)的系統(tǒng)。具體而言,當(dāng)前幀被判斷為關(guān)鍵幀時,低延遲調(diào)度策略仍然從歷史幀傳播特征到當(dāng)前幀并將其緩存為當(dāng)前幀高層特征,同時啟用一個后臺線程來計算當(dāng)前幀高層特征(如果直接運(yùn)行高層網(wǎng)絡(luò)部分會造成299ms的延遲),一旦計算完成就取代緩存的高層特征。實驗結(jié)果表明(如表2所示),這種低延遲的調(diào)度策略能夠?qū)⒀舆t由360ms降為119ms,同時只損失較小的分割精度(由78.84%降為75.89%)。
結(jié)論
本文提出了一個高效的低延遲視頻語義分割算法,其主要由自適應(yīng)特征傳播和自適應(yīng)關(guān)鍵幀調(diào)度模塊組成。該算法在關(guān)注平衡精度和計算量的同時力求降低系統(tǒng)的延遲,Cityscapes和Camvid兩個數(shù)據(jù)集上的實驗結(jié)果證明了該方法的有效性。作者希望在未來工作中在模型壓縮和模型設(shè)計方面進(jìn)一步降低算法的總體延遲和計算量。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100896 -
視頻
+關(guān)注
關(guān)注
6文章
1949瀏覽量
72974 -
自動駕駛
+關(guān)注
關(guān)注
784文章
13867瀏覽量
166601
原文標(biāo)題:CVPR 2018 | 商湯科技Spotlight論文詳解:極低延遲性的視頻語義分割
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于TICA和GMM的視頻語義概念檢測算法
聚焦語義分割任務(wù),如何用卷積神經(jīng)網(wǎng)絡(luò)處理語義圖像分割?
Facebook AI使用單一神經(jīng)網(wǎng)絡(luò)架構(gòu)來同時完成實例分割和語義分割

語義分割算法系統(tǒng)介紹
語義分割方法發(fā)展過程
分析總結(jié)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

全局雙邊網(wǎng)絡(luò)語義分割算法綜述
語義分割數(shù)據(jù)集:從理論到實踐
語義分割標(biāo)注:從認(rèn)知到實踐
PyTorch教程-14.9. 語義分割和數(shù)據(jù)集

深度學(xué)習(xí)圖像語義分割指標(biāo)介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論