 一項Gmail新功能-智能撰寫,為電子郵件寫作提供了一種新的方式
一項Gmail新功能-智能撰寫,為電子郵件寫作提供了一種新的方式
在 5 月初的 Google I/O 大會上,我們推出了一項 Gmail 新功能 -智能撰寫,此功能利用機器學習,以交互方式在用戶打字時給出建議,幫助用戶補全句子,從而提高電子郵件的寫作速度。智能撰寫基于為智能回復開發的技術,為電子郵件寫作提供了一種新的方式。無論是回復收到的電子郵件,還是新寫郵件都能夠體驗。
在開發智能撰寫的過程中,需要面對許多關鍵挑戰,其中包括:
延遲時間:智能撰寫基于每次的按鍵操作提供預測,因此它必須在 100 毫秒內作出響應,用戶才不會注意到任何延遲。因此,如何平衡模型復雜度和推斷速度成為一個關鍵問題。
規模:Gmail 擁有超過 14 億用戶。要為所有 Gmail 用戶提供有效的自動補全建議,模型必須具備足夠的建模能力,才能根據不同的語境給出相應的建議。
公平性和隱私性:在開發智能撰寫時,我們需要在訓練過程中杜絕存在潛在偏見的數據源,同時必須遵守與智能回復相同的嚴格用戶隱私標準,確保模型不會泄露用戶的隱私信息。此外,研究人員無法訪問電子郵件,這意味著他們必須開發并訓練一個機器學習系統來處理他們無法讀取的數據集。
尋找合適的模型
ngram、神經詞袋(BoW) 和RNN 語言(RNN-LM) 等典型的語言生成模型基于前面的單詞序列學習預測下個單詞。 然而,在電子郵件場景中,用戶在當前電子郵件撰寫會話中所打出的單詞只是模型可用于預測下個單詞的提示之一。為了融入有關用戶想表達內容的更多語境,我們的模型將電子郵件主題和之前的電子郵件正文(如果用戶要回復收到的郵件)也作為了一種預測條件。
要想包含這一額外語境,一種方法是將此問題看作序列到序列(seq2seq) 的機器翻譯任務,其中源序列是主題和之前電子郵件正文(如果有)的結合,目標序列是用戶當前正在撰寫的電子郵件。盡管此方法在預測質量方面表現良好,但它遠遠達不到我們嚴格的延遲時間約束標準。
為了改善這種情況,我們將 BoW 模型與 RNN-LM 結合起來,結果,速度快于 seq2seq 模型,且模型預測質量損失微乎其微。在這種混合方法中,我們通過將每個字段中的詞嵌入取平均值,對主題和之前的電子郵件進行編碼。然后在每個解碼步驟中,將這些平均嵌入連接起來并輸入到目標序列 RNN-LM 中。模型架構如下圖所示。
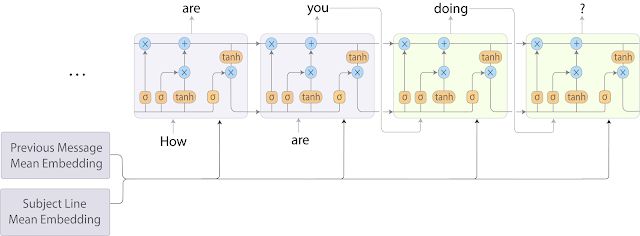
智能撰寫 RNN-LM 模型架構。通過對每個字段中的詞嵌入取平均值,對主題和之前的電子郵件消息進行編碼。然后在每個解碼步驟中將平均嵌入輸入到 RNN-LM 中。
加速模型訓練與服務
當然,確定使用這種建模方法后,我們仍需要調整不同的模型超參數,并在數十億個樣本上訓練模型,這些加起來需要耗費大量時間。為了加快速度,我們使用完整的 TPUv2 Pod 進行實驗。通過這種方式,不到一天的時間即可將模型訓練至收斂。
即使在訓練完較快的混合模型之后,最初版本的智能撰寫在標準 CPU 上運行時的平均服務延遲時間仍高達數百毫秒,這個值對于一個試圖節約用戶時間的功能來說仍然是不可接受的。幸運的是,在推斷時還可以使用 TPU,從而極大地加速用戶體驗。通過將大量計算轉移到 TPU 上,我們將平均延遲時間減少到幾十毫秒,同時極大地提高了單個機器可服務的請求數量。
公平性和隱私性
機器學習中的公平性非常重要,因為語言理解模型可能反映人類的認知偏見,產生一些不受歡迎的單詞和句子關聯。正如 Caliskan 等人在他們的近期論文"Semantics derived automatically from language corpora contain human-like biases"中所述,這些關聯與自然語言數據有著盤根錯節的聯系,這對構建語言模型提出了巨大挑戰。我們正在積極探索如何在訓練過程中進一步減少潛在偏見。同時,由于智能撰寫與垃圾郵件機器學習模型的訓練方式類似,基于數十億詞組和句子訓練而成,因此,我們運用此論文的研究成果,對模型進行了大量測試,以便確保只有多個用戶使用的常見詞組才會被模型記住。
-
cpu
+關注
關注
68文章
10879瀏覽量
212199 -
電子郵件
+關注
關注
0文章
110瀏覽量
15364 -
機器學習
+關注
關注
66文章
8425瀏覽量
132771
原文標題:基于機器學習的「智能撰寫」讓你的 Gmail 如開掛一般好用
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
傳真百科:電子郵件能取代傳真嗎
一種電子郵件網絡的加權演化模型與仿真
基于數字簽名的安全電子郵件系統的研究
怎樣通過Microsoft Exchange電子郵件使用Gmail或Google Apps for Business





 工商網監
工商網監
評論