

近日,和任天堂關(guān)系密切的日本網(wǎng)絡(luò)服務(wù)公司DeNA發(fā)布了一篇頗為有趣的文章:Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks,即用PSGAN生成高分辨率的全身動(dòng)畫(huà)。據(jù)了解,DeNA的業(yè)務(wù)涵蓋社交游戲、電子商務(wù)等領(lǐng)域,此前公司推出的手游《忍者天下》也在中國(guó)市場(chǎng)取得了驕人的成績(jī)。昔日忍者化身?yè)Q裝暖暖,DeNA想用GAN做些什么呢?
以下是論智對(duì)文章的編譯。
摘要
本文提出了一種漸進(jìn)結(jié)構(gòu)—條件生成對(duì)抗網(wǎng)絡(luò)(PSGAN),它是一個(gè)能基于姿態(tài)信息生成全身的高分辨率圖像的新框架。
近年來(lái),許多人都研究過(guò)用深度生成模型自動(dòng)生成圖像和視頻,這項(xiàng)技術(shù)對(duì)媒體創(chuàng)建工具來(lái)說(shuō)很有幫助,它可以被用來(lái)進(jìn)行圖片編輯、動(dòng)畫(huà)制作甚至是電影制作。
就動(dòng)漫產(chǎn)業(yè)角度看,一個(gè)能自動(dòng)生成動(dòng)畫(huà)角色的神經(jīng)網(wǎng)絡(luò)不僅能為創(chuàng)作者帶來(lái)諸多靈感,它還能為整個(gè)產(chǎn)業(yè)節(jié)省作畫(huà)上巨額開(kāi)支。現(xiàn)在我們已經(jīng)有了能生成人物臉部圖像的GAN,但還沒(méi)有能生成角色全身圖的工具。而且就這些生成臉部圖像的神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō),它們的圖像質(zhì)量還達(dá)不到工業(yè)級(jí)作畫(huà)標(biāo)準(zhǔn)。
因此,開(kāi)發(fā)一個(gè)既能生成全身圖像,又能生成高質(zhì)量姿態(tài)的GAN將對(duì)制作新角色、繪制新動(dòng)漫大有裨益。但達(dá)成這個(gè)目標(biāo)還有兩大難點(diǎn):(1)生成高分辨率圖像;(2)用特定的姿態(tài)序列生成圖像。
為了解決上述問(wèn)題,我們引入PSGAN,它能根據(jù)結(jié)構(gòu)信息,在訓(xùn)練過(guò)程中逐步提高生成圖像的分辨率,以此細(xì)化圖像在結(jié)構(gòu)上的細(xì)節(jié)特征,如生成對(duì)象的全身圖。同時(shí),我們也在網(wǎng)絡(luò)上添加了任意的潛在變量和結(jié)構(gòu)條件,讓它能基于目標(biāo)姿勢(shì)序列生成多樣化和可控制的動(dòng)作視頻。
在這篇文章中,我們用實(shí)驗(yàn)證明了PSGAN的有效性,如下文這個(gè)512x512的視頻所示,視頻中的動(dòng)畫(huà)角色展示了PSGAN生成的人物服裝細(xì)節(jié)、身體姿態(tài)的整體調(diào)整。
生成結(jié)果預(yù)覽
視頻展示了由PSGAN生成的各種動(dòng)漫角色和動(dòng)畫(huà)。首先,我們用隨機(jī)潛在變量生成大量動(dòng)畫(huà)角色;其次,我們?cè)賹?duì)具體的動(dòng)漫角色進(jìn)行潛在插值,以生成新的動(dòng)畫(huà)角色;最后,我們用連續(xù)的姿勢(shì)序列制作出流暢的動(dòng)畫(huà)。
換裝PLAY
PSGAN生成全新全身圖的主要方式是插入不同的服飾,這是利用改變潛在變量實(shí)現(xiàn)的。需要注意的一點(diǎn)是,換裝時(shí)人物的姿態(tài)是固定的。
舞動(dòng)人“身”
下圖展示了指定動(dòng)畫(huà)角色生成目標(biāo)姿態(tài)的具體過(guò)程:
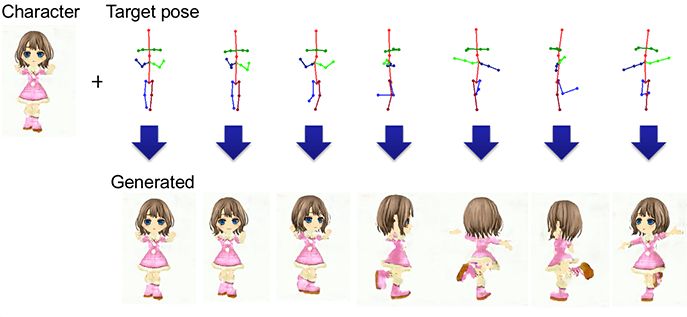
和生成服飾相反,這里我們固定潛在變量,并給PSGAN提供連續(xù)的姿勢(shì)序列。更具體地說(shuō),就是將指定動(dòng)畫(huà)角色的表示映射到潛在變量?jī)?nèi)——它處于潛在空間誒,是PSGAN的輸入向量——然后用這個(gè)新的潛在變量做PSGAN的輸入,以此做到在不改變外觀的前提下改變姿態(tài)。
漸進(jìn)結(jié)構(gòu)的條件GAN
我們的主要想法是逐步學(xué)習(xí)具有結(jié)構(gòu)條件的圖像表示。我們參考了Karras等人提出的GAN的結(jié)構(gòu),并在生成器和判別器上都添加上結(jié)構(gòu)條件,這樣做之后,無(wú)論圖像分辨率是什么,它們都帶有相應(yīng)縮放比例的姿態(tài)信息。
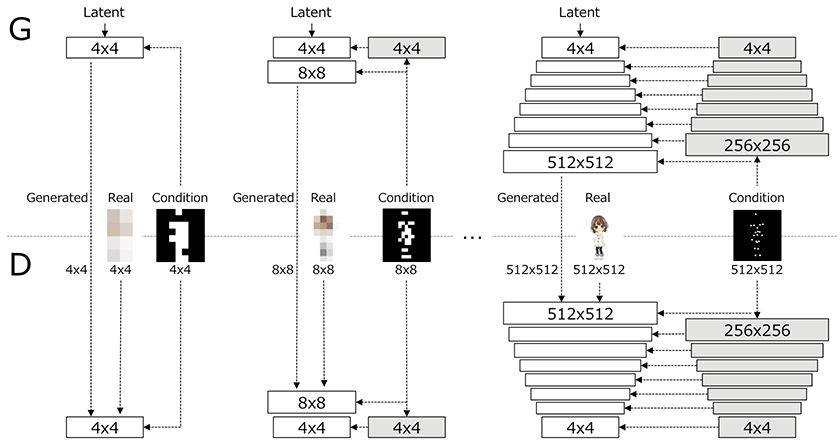
PSGAN的生成器和判別器
如上圖所示,N×N的白色框表示的是NxN空間分辨率下正在工作的可學(xué)習(xí)卷積層,灰色框表示的則是結(jié)構(gòu)條件的不可學(xué)習(xí)的下采樣層。
訓(xùn)練數(shù)據(jù)
本文用到的數(shù)據(jù)集有Unity合成的原始頭像動(dòng)漫角色數(shù)據(jù)集,以及由Openpose檢測(cè)到的關(guān)鍵點(diǎn)的DeepFashion數(shù)據(jù)集。PSGAN的訓(xùn)練要求是有成對(duì)的圖像和成對(duì)的關(guān)鍵點(diǎn)坐標(biāo)。
Avatar Anime-Character數(shù)據(jù)集
我們按照以下3個(gè)要求為PSGAN重新構(gòu)建了新數(shù)據(jù)集:
姿態(tài)多樣性。為了生成平滑、自然地圖像,我們需要各式各樣的姿態(tài)。
訓(xùn)練圖像的數(shù)量。通過(guò)用Unity生成3D頭像,我們無(wú)需任何手動(dòng)注釋就可以獲得大量帶注釋的合成圖像。
背景消除。我們把背景統(tǒng)一設(shè)置成白色,以避免不必要的信息對(duì)圖像產(chǎn)生負(fù)面干擾。
我們把單個(gè)角色的幾個(gè)連續(xù)動(dòng)作分解成600個(gè)姿勢(shì),并不捉每個(gè)姿勢(shì)的關(guān)鍵點(diǎn)。通過(guò)對(duì)79種服飾進(jìn)行同樣的處理,我們最終獲得了47,400張圖像。此外,我們還根據(jù)3D模型的骨骼結(jié)構(gòu)獲得了20個(gè)關(guān)鍵點(diǎn)。
下圖是幾個(gè)訓(xùn)練樣本(上:動(dòng)漫角色;下:姿態(tài)圖):
對(duì)于這個(gè)數(shù)據(jù)集,我們用Adam收斂網(wǎng)絡(luò),其中β1= 0,β2= 0.99。當(dāng)生成器中的圖像分辨率為4x4—64x64時(shí),學(xué)習(xí)率為0.001。隨著尺寸逐漸變?yōu)?28x128、256x256、512x512,學(xué)習(xí)率也逐漸降低為0.0008、0.0006和0.0002。
DeepFashion數(shù)據(jù)集
PSGAN利用姿態(tài)信息在圖像生成網(wǎng)絡(luò)上施加結(jié)構(gòu)條件。我們使用Openpose從沒(méi)有關(guān)鍵點(diǎn)注釋的圖像中提取關(guān)鍵點(diǎn)坐標(biāo)。
同樣的,這里我們還是使用Adam,β1= 0,β2= 0.99,學(xué)習(xí)率α始終是0.0008。
不同GAN的比較
我們先來(lái)看看PSGAN在多樣性上的表現(xiàn)。如下圖所示,PSGAN為每個(gè)姿勢(shì)條件生成各種各樣的圖像。
接下來(lái),我們?cè)賮?lái)看看PSGAN在生成姿態(tài)上的表現(xiàn)。在對(duì)照組中,PG2和DPG2需要同時(shí)輸入源圖像和相應(yīng)的目標(biāo)姿態(tài)才能生成目標(biāo)圖像,但PSGAN只需調(diào)整潛在變量就能使圖像具備目標(biāo)結(jié)構(gòu),它所受到限制更少。
下圖對(duì)比了PG2、DPG2和PSGAN生成的姿態(tài)圖,其中前兩者所需的參考姿態(tài)圖沒(méi)有顯示出來(lái)。通過(guò)對(duì)比我們可以發(fā)現(xiàn),PSGAN生成的圖像和PG2、DPG2一樣自然合理,但又一定的瑕疵。由于這是通過(guò)調(diào)整潛在變量實(shí)現(xiàn)的,所以從理論上來(lái)說(shuō),如果變量調(diào)試得完美,PSGAN同樣能生成具有相同的質(zhì)量的姿態(tài)圖。
最后,我們還評(píng)估了PSGAN與Progressive GAN在結(jié)構(gòu)一致性上的表現(xiàn)。實(shí)驗(yàn)結(jié)果顯示,無(wú)論是細(xì)節(jié)還是全局,PSGAN生成的圖像都更自然,而且它在結(jié)構(gòu)細(xì)節(jié)上的處理也更合理。
小結(jié)
本文展示了PSGAN在生成平滑、高分辨率動(dòng)畫(huà)上的水平,也通過(guò)實(shí)驗(yàn)證實(shí)它能基于512x512的目標(biāo)姿勢(shì)序列生成動(dòng)畫(huà)角色全身圖和相應(yīng)動(dòng)畫(huà)。由于實(shí)驗(yàn)條件有限,神經(jīng)網(wǎng)絡(luò)在一些方面還發(fā)揮欠佳,所以未來(lái)我們還會(huì)在更多條件下進(jìn)行試驗(yàn)和評(píng)估。
此外,經(jīng)處理的Avatar Anime-Character數(shù)據(jù)集即將開(kāi)放。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4789瀏覽量
101901 -
GaN
+關(guān)注
關(guān)注
19文章
2107瀏覽量
75465
原文標(biāo)題:旋轉(zhuǎn)吧!換裝少女:一種可生成高分辨率全身動(dòng)畫(huà)的GAN
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
高分辨率合成孔徑雷達(dá)圖像的直線特征多尺度提取方法
增強(qiáng)高分辨率圖像捕獲的選擇
如何設(shè)計(jì)高速高分辨率ADC電路?
超高分辨率圖像實(shí)時(shí)顯示系統(tǒng)設(shè)計(jì)
基于FPGA+PowerPC的高分辨率圖像實(shí)時(shí)壓縮系統(tǒng)的設(shè)計(jì)
基于多模型表示的高分辨率遙感圖像配準(zhǔn)方法_項(xiàng)盛文
高分辨率遙感圖像飛機(jī)目標(biāo)檢測(cè)

YOLOv8版本升級(jí)支持小目標(biāo)檢測(cè)與高分辨率圖像輸入





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論