 深入理解Linux RCU:經典RCU實現概要
深入理解Linux RCU:經典RCU實現概要
1、準備工作
本文基于linux 2.6.32-rc7版本的源碼, 因此請準備一份linux2.6.32-rc7代碼。建議用如下兩種方法獲取源代碼:
2、使用git從linux-next拉取最新代碼,然后使用git checkout -b linux-2.6.32-rc7 v2.6.32-rc7檢出2.6.32-rc7版本的源碼。
2、概述
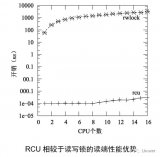
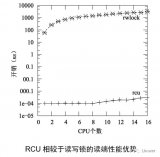
雖然Linux更早版本中的經典RCU,其讀端原語擁有出色的性能和擴展性,但是寫端原語則需要判斷預先存在的讀端臨界區在什么時候完成,它僅僅被設計用于數十個CPU的系統。經典RCU的實現,要求在每個優雅周期內,每個CPU必須獲取一個全局鎖,這使得它們的擴展性受到了限制。雖然在實際生產系統中,經典RCU可以運行在幾百個CPU的系統中,甚至能夠比較困難的使用到上千個 CPU的系統中,但是大型多核系統仍然需要更好的擴展性。
另外,經典RCU有一個不是最優的dynticks 接口,導致經典RCU在每一個優雅周期都要喚醒每一個CPU,即使這些CPU處于idle狀態。我們考慮一個16核的系統,它只有四個CPU比較忙,其他CPU的負載都很輕。理想情況下,余下12個CPU可以一直處于深度睡眠模式以節約能源。然而不幸的是,如果四個忙的CPU頻繁的執行RCU更新,這12個空閑CPU會被周期性的喚醒,浪費了重要的能源。因此,對于經典RCU的任何優化,都應當讓這些睡眠狀態的CPU繼續處于睡眠狀態。
經典RCU和分級RCU實現都有和經典RCU相同的語義和API。但是,原有的實現被稱為“經典RCU”,新實現被稱為“分級RCU”。
2.1.RCU基礎回顧
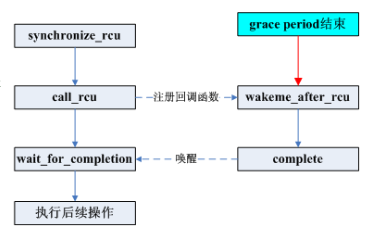
從最基本的方面來說,RCU 是一種等待事務完成的方法。當然,要等待事務完成,還存在很多其他方法,包括引用計數、讀寫鎖、事件等等。RCU的一個大的優勢是可以同時等待20,000個不同的事件,而不必具體的跟蹤其中每一個事件,并且不用擔心性能被降低,以及擴展性被限制,也不用擔心復雜的死鎖情況和內存泄漏的危險。
在RCU中,被等待的事件被稱為“RCU 讀端臨界區”。RCU讀端臨界區以rcu_read_lock()原語開始,以相應的rcu_read_unlock() 原語結束。RCU讀端臨界區可以嵌套,也可以包含相當多的代碼,只要這些代碼不阻塞或者睡眠(當然,這是針對經典RCU來說的。有一種特殊的名為SRCU的可睡眠RCU,它允許在SRCU讀端臨界區中進行短期睡眠)。如果您遵從這些約束,您可以使用RCU來等待任何代碼片段完成。
RCU通過間接的確定其他事務何時完成來實現這一點。但是,請注意:在特定的優雅周期之后開始的RCU 讀端臨界區能夠、也必然會延長優雅周期的結束點。
2.2.經典RCU實現概要
經典RCU實現的關鍵原理是:經典RCU 讀端臨界區限制其中的內核代碼不允許阻塞。這意味著在任意時刻,一個特定的CPU只要看起來處于阻塞狀態、IDLE循環、或者離開了內核后,我們就知道所有RCU讀端臨界區已經完成。這些狀態被稱為“靜止狀態”,當每一個CPU已經經歷過至少一次靜止狀態時,RCU優雅周期結束。
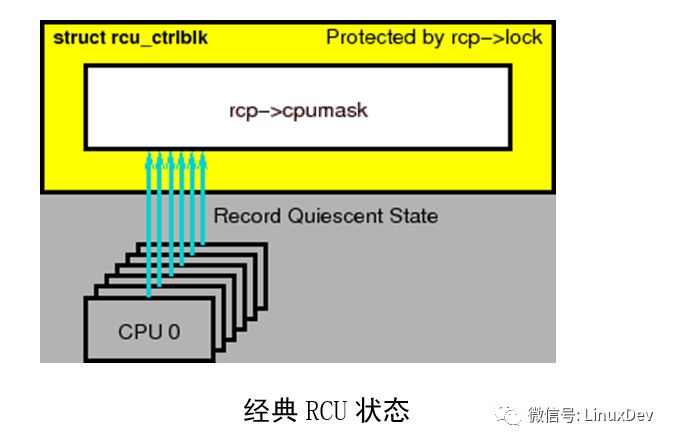
經典RCU最重要的數據結構是rcu_ctrlblk,它包含了->cpumask字段,每一個CPU在該字段中包含一位,如上圖所示。當每一個優雅周期開始時,每一個 CPU相應的位被設置為1,每一個CPU經過一次靜止狀態時,必須清除相應的位。由于多個CPU可能希望同時清除它們的位,這將破壞->cpumask 字段,因此使用了一個->lock自旋鎖來保護->cpumask。不幸的是,當超過幾千個CPU時,這個自旋鎖會遇到嚴重的競爭狀態。更糟糕的是,事實上所有CPU必須清除它們的位,意味著在一個優雅周期內,CPU不允許一直睡眠。這削弱了LINUX節能的能力。
2.3.RCU迫切要解決的問題
實時RCU迫切要解決的問題列表如下:
1. 延遲銷毀。這樣,直到所有已經預先存在的RCU讀端臨界區已經完成,一個RCU優雅周期才能結束。
2. 可靠性,這樣RCU支持24x7運行。
3. 可以在IRQ處理函數中調用。
4. 包含內存標記,這樣,如果有很多回調過程,這種機制將加快結束優雅周期。
5. 獨立的內存塊,這樣RCU能夠基于可信的內存分配器進行工作。
6. synchronization-free的讀端,這樣允許通常的非原子指令操作于CPU(或者任務)的本地內存。
7. 無條件的read-to-write提升,在LINUX內核中,有幾個地方需要這樣使用。
8. 兼容的API。
9. 搶占RCU讀端臨界區的要求可以被去掉。
10. 極低的RCU內部鎖的競爭,從而帶來極大的擴展性。RCU必須支持至少1,024個CPU,最好是至少4,096個CPU。
11. 節能:RCU必須能夠避免喚醒低電壓狀態的dynticks-idle CPU,但是仍然能夠判斷當前的優雅周期何時結束。這已經在實時RCU中實現,但是需要大大的簡化。
12. RCU讀端臨界區必須允許在NMI處理函數中使用,就如在中斷處理函數中一樣。
13. RCU必須很好的管理不停的CPU熱插撥操作。
14. 必須能夠等待所有事先注冊的RCU回調完成,雖然這已經以rcu_barrier()的形式提供。
15. 檢測失去響應的CPU是值得的,以幫助診斷RCU和死循環BUG及硬件錯誤,這能夠防止RCU優雅周期不能結束的情況。
16. 加快RCU優雅周期是值得的,這樣RCU優雅周期能夠強制在數百微秒內完成。但是,這樣的操作預期會帶來嚴重的CPU負載。
最急迫的首要需求是:可擴展性。因此需要減少RCU的內部鎖。
2.4.邁向可擴展RCU實現
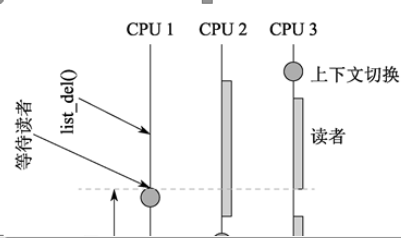
減少鎖競爭的一個有效方法是創建一個分級結構,如上圖所示。在此,四個rcu_node 結構中的每一個都有各自的鎖,這樣只有 CPU 0 和 1 會獲取最左邊的 rcu_node的鎖, CPU 2 和 3 會獲取中間的rcu_node的鎖,CPU 4和5會獲取右邊的rcu_node的鎖。在任一個優雅周期期間,僅僅某一個CPU節點會訪問rcu_node 結構的上一層的rcu_node。也就是說,在上圖中,每一對CPU(它們處于同一個CPU節點)中,最后一個記錄靜止狀態的CPU才會訪問上一層的rcu_node。
這樣做的最終結果,是減少了鎖的競爭。在經典RCU中,6個CPU在每一個優雅周期內競爭同一個全局鎖,在上圖中,僅僅是三個節點競爭最上層的rcu_node鎖 (降低了50%)。
rcu_node結構樹被嵌入到rcu_state 結構的一個線性數組,樹根是結點0,如上圖。它是一個8-CPU的、三層分級結構的系統。 每一個箭頭將一個rcu_node 結構鏈接到它的父結點,這對應著rcu_node結構的->parent 字段。每一個rcu_node都標示了它所覆蓋的CPU范圍,這樣根結點覆蓋了所有CPU,每一個二級結點覆蓋了一半的CPU,每一個葉子結點覆蓋了兩個 CPU。這個數組在編譯時基于NR_CPUS的值靜態分配。
上圖顯示了如何檢測優雅周期。在第一個圖中,沒有CPU經過靜止狀態,并用紅塊標示。假設所有6個CPU試圖同時告訴RCU,它們已經經過一個靜止狀態。那么,在每一對CPU中,僅僅其中某一個CPU能夠獲得底層rcu_node結構的鎖。第二個圖中,假設CPU0、3、5比較幸運的獲得了底層rcu_node結構的鎖,在圖中標識為綠色塊。一旦這些幸運的CPU結束了,那么其他CPU將獲得鎖,如圖3所示。這三個CPU中,每一個CPU將會發現它們是組內最后一個CPU,因此所有三個CPU嘗試移到上層rcu_node。此時,僅僅其中一個能獲得上層rcu_node 鎖。我們假設CPU1、2、4依次獲得了鎖,則第4、5、6圖顯示了相應的狀態。最后,第6圖顯示了所有CPU已經經過一次靜止狀態,因此優雅周期結束。
在上面的順序中,沒有超過3個CPU為同一個鎖產生競爭,與經典RCU進行對比,我們會高興的發現,經典RCU中,所有6個CPU都可能沖突。但是,對更多的CPU來說,可以再顯著的減少鎖之間的沖突。考慮有64個底層結構及64*64=4,096 CPU的分組結構,如圖上圖。
在此,每一個底層rcu_node 結構的鎖被64個CPU申請,將從經典RCU的4096個CPU競爭一個單一的鎖降為64個CPU競爭一個鎖。在一個特定的優雅周期期間,僅僅一個底層rcu_node 中的某一個CPU會申請上級rcu_node 的鎖。這樣,與經典RCU相比,減少了64倍的鎖競爭。
2.5.邁向不成熟的RCU實現
正如較早前提示的一樣,這些努力的一個重要目的是使一個處于睡眠狀態的CPU保持它的睡眠狀態,以節約能源。與之相對的是,經典RCU至少會在一個優雅周期內喚醒每一個處于睡眠狀態的CPU。當其他大多數CPU都處于空閑狀態時,這些個別的CPU進行rcu寫操作,會使得這種處理方法不是最優的。這種情形將在周期性的高負載系統中發生,我們需要更好的處理這種情況。
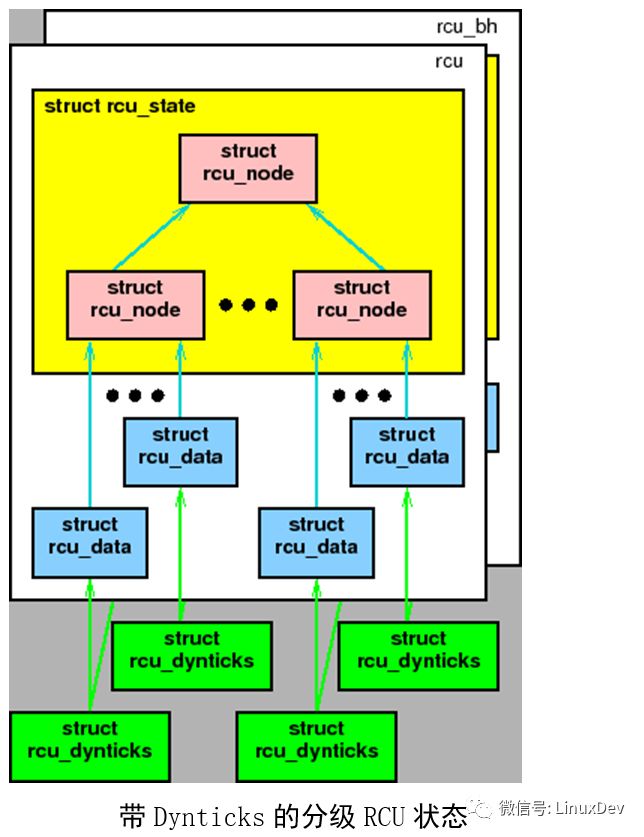
這是通過要求所有CPU操作位于一個每CPU rcu_dynticks 結構中的計數器來實現的。不是那么準確的說,當相應的CPU處于dynticks idle模式時,計數器的值為偶數,否則是奇數。這樣,RCU僅僅需要等待rcu_dynticks 計數值為奇數的CPU經過靜止狀態,而不必喚醒正在睡眠的CPU。如上圖,每一個每CPU rcu_dynticks結構被“rcu”和“rcu_bh”實現所共享。
2.6.狀態機
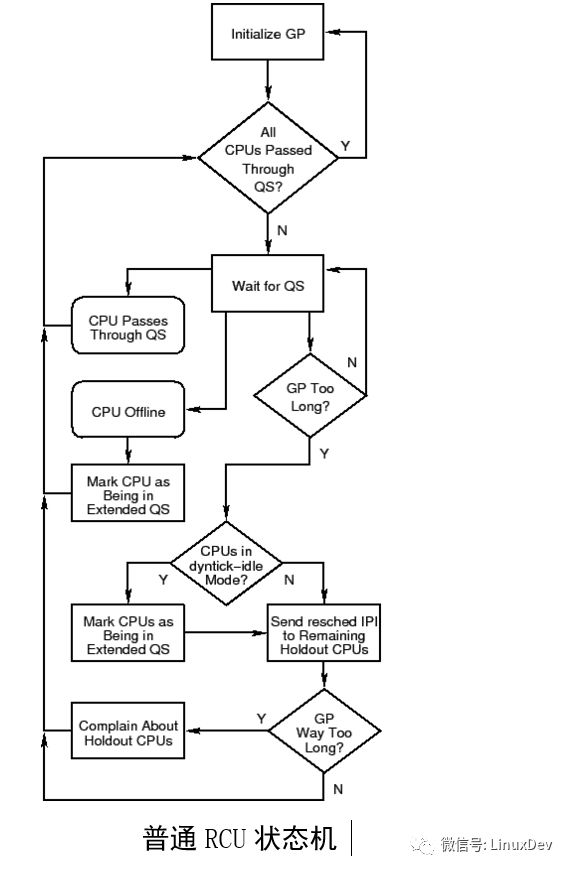
從十分高層的視角來看,Linux內核RCU 實現可以被認為是一個高級狀態機,如上圖。在一個很繁忙的系統上,通常的路徑是最上面的兩個循環。在每一個優雅周期(GP)開始時進行初始化,等待靜止狀態 (QS)。在一個特定的優雅周期中,當每一個CPU都經歷過靜止狀態時,它其實什么都不用做。在這樣一個系統中,經歷如下事件表明產生一個靜止狀態:
1、每一次進程切換
2、在CPU進入idle狀態
3、或者執行用戶態代碼時
CPU熱插撥事件將使狀態機進入“CPU Offline”流程。而“holdout”CPU(那些由于軟件或者硬件原因導致遲遲不能經過一次靜止狀態的CPU)的出現,使得不能快速經歷一次靜止狀態,這將使狀態機進入“send reschedIPIs to Holdout CPUs”(發送重新調度IPI給Holdout CPUS)流程。為了避免不必要的喚醒處于dyntick-idle 狀態的CPU,RCU 實現將標記這些CPU處于擴展的靜止狀態,通過“Y”分支離開“CPUs in dyntick-idle Mode?”(但是請注意,這些處于dyntick-idle模式的CPU將不會被發送重新調度IPI)。最后,如果CONFIG_RCU_CPU_STALL_DETECTOR打開了,過遲的到達靜止狀態將使狀態機進入“Complain About Holdout CPUs”流程。
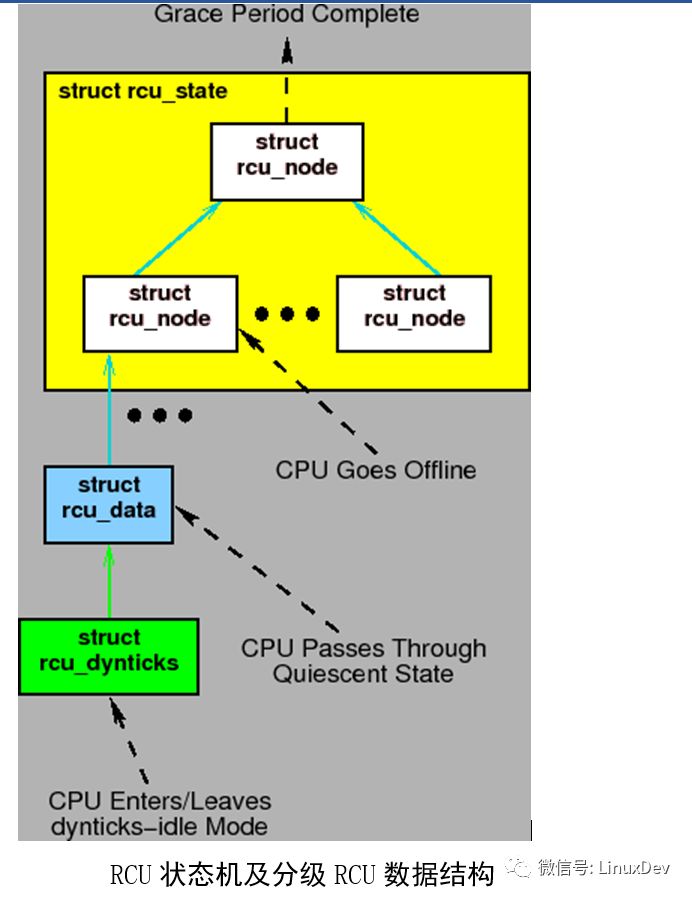
上面的狀態圖中,事件會與不同的數據結構交互。但是,狀態圖不會被任何RCU實現直接翻譯為C代碼。相反的,這些實現在內核中被編碼為事件驅動的系統。我們通過一些用例來表示這些事件。
2.7.用例
這些事件驅動的用例包括:
1.開始一個新的優雅周期
2.經歷一個靜止狀態
3.向RCU通告一個靜止狀態
4.進入、退出Dynticks Idle 模式
5.從Dynticks Idle 模式進入中斷
6.從 Dynticks Idle 模式進入NMI
7.標記一個CPU處于Dynticks Idle 模式
8.CPU離線
9.CPU上線
10.檢測一個太長的優雅周期
2.7.1.開始一個新的優雅周期
rcu_start_gp()函數開始一個新的優雅周期。當一個CPU存在回調,而該回調需要等待優雅周期時,就需要調用此函數。
rcu_start_gp()函數更新rcu_state和rcu_data結構中的狀態,以標識開始一個新的優雅周期,獲取->onoff 鎖 (并關中斷) 以防止任何并發的CPU熱插撥操作,在所有的rcu_node結構中設置位,以標識所有CPU (包括當前CPU) 必須經歷一次靜止狀態,最后釋放->onoff 鎖。
設置位操作分兩個階段進行。首先,在沒有持有任何鎖的情況下,非葉子節點rcu_node 的位被設置,然后,在持有->lock的情況下,每一個葉子節點的rcu_node 結構的位被設置。
2.7.2.經歷一次靜止狀態
rcu和rcu_bh有各自的靜止狀態集合。
RCU的靜止狀態是進程切換、IDLE (不管是dynticks 還是IDLE循環)、以及執行用戶態程序。
RCU-bh的靜止狀態是在開中斷狀態下,退出軟中斷。
需要注意的是,rcu的靜止狀態也是rcu_bh的靜止狀態。rcu的靜止狀態通過調用rcu_qsctr_inc()來記錄。而rcu_bh的靜止狀態通過調用rcu_bh_qsctr_inc()來記錄。這兩個函數將它們的狀態記錄到當前CPU的rcu_data 結構中。請注意:在2.6.32版本中,rcu_qsctr_inc和rcu_bh_qsctr_inc函數已經被更名。如何通過git查找它們被更名為什么名稱,這個任務就留給作者當做練習了。
這些函數在調度器、__do_softirq()和rcu_check_callbacks()中被調用。后面這個函數在調度時鐘中斷中調用,并分析狀態以確定中斷是否發生在一個靜止狀態中,以確定是調用rcu_qsctr_inc()或者 rcu_bh_qsctr_inc()。它也觸發RCU_SOFTIRQ軟中斷,并導致當前CPU在隨后的軟中斷上下文中調用rcu_process_callbacks(),rcu_process_callbacks函數處理RCU在每個CPU上的回調函數以釋放資源。
2.7.3.向RCU宣告一次靜止狀態
前述的rcu_process_callbacks() 函數要完成幾個事情:
1.確定何時結束一個太長的優雅周期(通過force_quiescent_state())。
2.當CPU檢測到優雅周期結束時,采用適當的動作。(通過 rcu_process_gp_end())。“適當的動作”包括加快本CPU的回調,以及記錄新的優雅周期。同一個函數也更新狀態以響應其他CPU。
3.向RCU核心機制報告當前CPU的靜止狀態。(通過 rcu_check_quiescent_state(),它會調用 cpu_quiet())。當然,這個過程也會標記當前的優雅周期結束。
4.如果沒有處理優雅周期,并且這個CPU有RCU回調等待優雅周期,則開始一個新的優雅周期(通過 cpu_needs_another_gp()和rcu_start_gp())。
5.當優雅周期結束時,調用這個CPU的回調 (通過 rcu_do_batch())。
這些接口都經過精心實現,以避免BUG,如:錯誤的從上一個優雅周期向當前優雅周期報告靜止狀態這樣的BUG。
2.7.4.進入和退出 Dynticks Idle模式
調度器調用rcu_enter_nohz()進入dynticks-idle 模式,并調用 rcu_exit_nohz()離開此模式。rcu_enter_nohz() 函數遞增每CPU dynticks_nesting變量,也遞增每CPU dynticks計數器,然后,后者必然擁有一個偶數值。rcu_exit_nohz() 函數遞減每CPU dynticks_nesting 變量,并且再一次遞增每CPU dynticks計數器,后者將擁有一個奇數值。
dynticks 計數器可以被其他 CPU采樣。如果其值是偶數,那么該CPU處于擴展靜止狀態。類似的,如果計數器在一個特定的優雅周期內發生了改變,那么CPU必然在優雅周期期間的某個時間點上處于擴展靜止狀態。但是,還需要采樣另外一個dynticks_nmi每CPU變量,隨后我們將討論這個變量。
2.7.5.從Dynticks Idle 模式進入中斷
從dynticks idle 模式進入中斷由rcu_irq_enter() 和 rcu_irq_exit()處理。rcu_irq_enter() 函數遞增每CPU dynticks_nesting 變量,如果此變量為0,也遞增dynticks每CPU變量 (它將擁有一個奇數值)。
rcu_irq_exit()函數遞減每CPU dynticks_nesting變量。并且,如果新值是0,也遞增dynticks每CPU變量 (它將擁有一個偶數值)。
注意:進入中斷會處理退出dynticks idle模式,反之也一樣。進入、退出之間不一致可能導致一些混亂,不用警告你也應該想得到這一點。
2.7.6.從Dynticks Idle 模式進入NMI
從dynticks idle模式進入NMI由rcu_nmi_enter()和rcu_nmi_exit()處理。這些函數同時遞增dynticks_nmi計數器,但僅僅是在前述dynticks 計數是偶數時才進行遞增。換句話說,如果NMI發生時,處于非dynticks-idle模式或者處于中斷狀態,那么 NMI將不操作dynticks_nmi計數器。
這兩個函數之間唯一的差異在于錯誤檢查,rcu_nmi_enter()必然使dynticks_nmi計數器為奇數值,rcu_nmi_exit()必然使這個計數器為偶數值。
2.7.7.標記CPU處于Dynticks Idle模式
force_quiescent_state()函數實現一個三階段的狀態機。 第一個階段 (RCU_INITIALIZING)等待rcu_start_gp()完成對優雅周期的初始化。這個狀態不是從force_quiescent_state()退出,就是從rcu_start_gp()退出。
在第二階段(RCU_SAVE_DYNTICK),dyntick_save_progress_counter()函數掃描還沒有報告靜止狀態的CPU,記錄它們的每CPU dynticks 和dynticks_nmi 計數器。如果這些計數器都是偶數值,那么相應的CPU處于dynticks-idle 狀態,因此標記它們為擴展靜止狀態(通過cpu_quiet_msk()報告)。
在第三階段(RCU_FORCE_QS),rcu_implicit_dynticks_qs()函數再一次掃描仍然沒有報告靜止狀態的CPU (既沒有明確標示,也沒有在RCU_SAVE_DYNTICK階段隱含的標示),再一次檢查每CPU dynticks 和 dynticks_nmi計數器。如果每一個值都變化,或者目前為偶數,那么相應的相應的CPU已經經過一次靜止狀態或者目前處于dynticks idle模式,也就是前述擴展靜止狀態。
如果rcu_implicit_dynticks_qs()發現特定CPU既沒有處于dynticks idle模式,也沒有報告一個靜止狀態,它調用rcu_implicit_offline_qs(),這個函數檢查CPU是否處于離線狀態,如果是,那么也報告一個擴展靜止狀態。如果CPU在線,那么rcu_implicit_offline_qs()發送一個重新調度IPI,嘗試提醒該CPU應當向RCU報告一個靜止狀態。
請注意:force_quiescent_state() 既不直接調用dyntick_save_progress_counter(),也不直接調用rcu_implicit_dynticks_qs(),而是將它們傳遞給rcu_process_dyntick() 函數。這個函數抽象出掃描CPU、報告擴展靜止狀態的通用代碼。
2.7.8.CPU離線
CPU離線事件導致rcu_cpu_notify()調用rcu_offline_cpu(),在rcu和rcu_bh上依次調用__rcu_offline_cpu()。這個函數清除離線CPU的位,這樣,后面的優雅周期將不再期望這個CPU宣告靜止狀態,隨后調用cpu_quiet(),以宣告離線擴展靜止狀態。這是在持有全局->onofflock鎖的情況下執行的,這是為了防止與優雅周期初始化相沖突。
2.7.9.CPU上線
CPU上線事件導致rcu_cpu_notify()調用rcu_online_cpu(),用于初始化CPU的dynticks狀態,然后調用rcu_init_percpu_data()初始化CPU的rcu_data 數據結構,也設置這個 CPU的位(同樣通過全局->onofflock進行保護),這樣后面的優雅周期將等待這個CPU的靜止狀態。最后,rcu_online_cpu()設置這個CPU的RCU 軟中斷向量。
2.7.10.檢測太長的優雅周期
當配置了CONFIG_RCU_CPU_STALL_DETECTOR內核參數時,record_gp_stall_check_time() 函數記錄當前時間,以及3秒以后的時間戳。如果當前優雅周期到期后仍然沒有結束,那么check_cpu_stall函數將檢測罪魁禍首。并且如果當前CPU是造成延遲的CPU,則調用print_cpu_stall(),如果不是,則調用print_other_cpu_stall()。兩個jiffies的時間差有助于確保其他CPU在可能的情況下報告它的狀態,利用這個時間差,CPU能夠做一些事情,例如跟蹤它自己的堆棧。
2.8.測試
RCU是基本的同步代碼,因此RCU的錯誤導致的后果是隨機的、難于調試的內存錯誤。因此,高可靠的RCU是非常重要的。這些可靠性來自于小心的設計,但是最終還是需要依賴于高強度的壓力測試。
幸運的是,雖然有一些關于覆蓋性方面的爭論,但是仍然可以對軟件進行一些壓力測試。實際上,進行這些測試是被強烈建議的,因為不對你的軟件進行折磨性測試的話,它就會反過來折磨你,這種折磨來自于:它在不合時宜的時候崩潰掉。
因此,我們使用rcutorture模塊來對RCU進行壓力測試。
但是,根據通常情況下的RCU用法來對RCU進行測試,顯得還不是很充分。也有必要針對不常用的情況進行壓力測試。例如,CPU并發的上線或者離線,CPU并發的進入及退出dynticks idle模式。Paul使用了一個腳本CodeSamples,并向模塊rcutorture使用test_no_idle_hz 模塊參數對dynticks idle模式進行壓力測試。有時作者也比較疑神疑鬼,因此盡量在測試時運行一個kernbench負載測試程序。在128路的機器上運行10個小時的壓力測試,看起來是足夠測試出幾乎所有BUG了。
實際上這還不算完。Alexey Dobriyan和Nick Piggin早在2008年就證明過,以所有相關內核參數組合對RCU進行壓力測試是必要的。相關的內核參數可以使用另外一個腳本CodeSamples進行標識。
1.CONFIG_CLASSIC_RCU:經典 RCU。
2.CONFIG_PREEMPT_RCU:可搶占 (實時) RCU。
3.CONFIG_TREE_RCU:用于大型SMP系統的經典 RCU。
4.CONFIG_RCU_FANOUT:每一個rcu_node 的子結點數量。
5.CONFIG_RCU_FANOUT_EXACT:平衡rcu_node 樹。
6.CONFIG_HOTPLUG_CPU:允許 CPU上線、離線。
7.CONFIG_NO_HZ:打開dyntick-idle 模式。
8.CONFIG_SMP:打開 multi-CPU選項。
9.CONFIG_RCU_CPU_STALL_DETECTOR:當CPU進入擴展靜止狀態時進行RCU檢測。
10.CONFIG_RCU_TRACE:在debugfs中生成 RCU跟蹤文件。
我們忽略CONFIG_DEBUG_LOCK_ALLOC 配置變量,因為我們假設分級RCU不能打斷 lockdep。仍然有10個配置變量,如果它們是獨立的布爾值,則導致1024種組合。幸運的是,首先,其中前三個是互斥的,這樣可以將組合數量減少到384個,但是CONFIG_RCU_FANOUT可以取值2-64,將組合數量增加到12,096。這么大量的組合是不可能都實施的。
關鍵的一點是:如果CONFIG_CLASSIC_RCU或者CONFIG_PREEMPT_RCU有效時,預期僅僅CONFIG_NO_HZ 和 CONFIG_PREEMPT 可能會改變其行為。這幾乎減少了三分之二的組合。
而且,并不是這些所有可能的CONFIG_RCU_FANOUT值都會產生顯著有效的結果,實際上僅僅一部分情況需要分別測試:
1.單結點“tree”。
2.兩級平衡樹。
3.三級平衡樹。
4.自動平衡樹,當 CONFIG_RCU_FANOUT 指定一個不平衡樹,但是沒有配置CONFIG_RCU_FANOUT_EXACT 時,進行自動平衡。
5.非平衡樹。
更進一步說,CONFIG_HOTPLUG_CPU僅僅在指定CONFIG_SMP 時才有用,CONFIG_RCU_CPU_STALL_DETECTOR是獨立的,因此僅僅需要測試一次(然而有些人比我還多疑,他們可能決定在有CONFIG_SMP和沒有CONFIG_SMP 時,都測試它)。類似的,CONFIG_RCU_TRACE也僅僅需要測試一次。但是象我一樣多疑的人,會選擇在有CONFIG_NO_HZ 和沒有CONFIG_NO_HZ 時,都測試一下它。
這允許我們在15種測試情形下,得到一個覆蓋率較好的RCU測試。所有這些測試情形都指定如下配置參數以運行rcutorture,這樣CONFIG_HOTPLUG_CPU=n會產生實際的效果:
CONFIG_RCU_TORTURE_TEST=m
CONFIG_MODULE_UNLOAD=y
CONFIG_SUSPEND=n
CONFIG_HIBERNATION=n
15個測試用例如下:
1.強制單節點“樹”,用于小型系統:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=8
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
2.強制兩級節點樹用于大型系統:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=4
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=n
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
3.強制三級節點樹,用于非常大型的系統:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=2
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
4.測試自動平衡:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
5.測試不平衡樹:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
6.禁止CPU延遲檢測:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
7.禁止 CPU延遲檢測及dyntick idle 模式:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
8.禁止 CPU延遲檢測及CPU熱插撥:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
9.禁止 CPU延遲檢測,dyntick idle 模式,及CPU熱插撥:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
10.禁止SMP、CPU延遲檢測、dyntick idle 模式、及CPU熱插撥:
CONFIG_SMP=n
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
這個組合有一些編譯警告。
11.禁止SMP、禁止CPU熱插撥:
CONFIG_SMP=n
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
12.有dynticks idle 但是沒有搶占的情況下,測試經典RCU:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
13.有搶占但是沒有dynticks idle時,測試經典RCU:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
14.在dynticks idle情況下,測試可搶占RCU:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
15.在沒有 dynticks idle時,測試可搶占RCU:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
對于每一次大的影響RCU核心代碼的變化,都應當以上面的組合運行rcutorture,并且在CONFIG_HOTPLUG_CPU時,并發的進行CPU熱插撥。對小的變化,在每一種情況下運行kernbench就行了。當然,如果變化僅僅限于配置參數的部分子集,就可以減少測試用例的數量。
作者強烈推薦壓力測試軟件:Geneva Convention!
2.9.結論
這個分級RCU實現減少了鎖競爭,避免了不必要的喚醒dyntick-idle睡眠狀態的CPU,因此有助于調試Linux CPU熱插撥代碼。這個實現被設計用于處理數千個CPU的大型系統,并且在64位系統上,CPU數量限制是250,000,在今后一段時間內,這個限制是沒有問題的。
這個RCU實現當然也有一些局限:
1.force_quiescent_state()可能在關中斷下掃描整個CPU集。這在實時RCU實現中,是一個重大缺陷。因此,如果需要在可搶占RCU中加入分級,則需要其他方法。在4096個CPU的系統中,它可能會產生一些問題,但是需要在實際的系統中進行測試以證明真的有問題。
在繁忙的系統中,不能指望force_quiescent_state()掃描會發生,CPU將在開始一個靜止狀態后,在三個jiffies內經歷一次靜止狀態。在半繁忙的系統中,僅僅處于dynticks-idle模式的CPU需要掃描。其他情況下,例如,在一個dynticks-idle CPU掃描過程中,處理一個中斷時,后繼的掃描是需要的。但是,這樣的掃描是分別在相應的CPU上執行的,因此相應的調度延遲僅僅影響該掃描過程所在的CPU負載。
如果掃描被證明確實有問題,一個好的方法是進行遞增掃描。這將稍微增加一點代碼復雜性,也增加一點結束優雅周期的時間,但是這也確實算是一個好的方案。
2.rcu_node分級在編譯時創建,因此其長度是最大的CPU數量NR_CPUS。 但是,即使在4,096 CPU的系統中,在64位系統上,rcu_node 分級也僅僅消耗65個緩存行。(即使在32位系統上包含4,096 CPUs也是這樣!)。當然,在一個16 CPU的系統中,配置NR_CPUS=4096將使用一個二級樹,實際上在這種情況下,單節點樹也會運行得很好。雖然這個配置會增加鎖的負載,但是實際上不會影響經常執行的讀端代碼,因此事實上不會有太大的問題。
3.這個補丁會稍微增加內核代碼及數據尺寸:在NR_CPUS=4的系統中,從經典RCU的1,757字節內核代碼、456字節數據,共2213字節的內核尺寸,而分級RCU則增加到4,006字節的內核代碼、624字節的內核數據,共計4,630字節尺寸。即使對大多數嵌入式系統來說,這也不是一個問題。這些系統通常有上百兆主內存。但是對特別小的系統來說,這可能就是一個問題了,需要提供兩種類型的RCU實現以滿足這樣的嵌入式系統。不過有一個有趣的問題,在這樣的系統中,也許僅僅包含一個CPU,這樣的系統完全可以用一個特別簡單的RCU實現。
即使有這些問題,相對于經典RCU來說,在數百個CPU的系統中,這個分級RCU實現仍然是一個巨大的進步。最后需要說明一下,經典RCU設計用于16-32個CPU的系統。
在某些地方,在可搶占RCU實現中使用分級是有必要的。
后續章節將繼續分析分級RCU的代碼,以及Linux中其他一些RCU的實現。也許還會討論實現RCU這類復雜并行軟件的開發方法及其形式化驗證。
-
cpu
+關注
關注
68文章
10878瀏覽量
212169 -
Linux
+關注
關注
87文章
11320瀏覽量
209833 -
rcu
+關注
關注
0文章
21瀏覽量
5455
原文標題:謝寶友:深入理解RCU之六:分級RCU基礎
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
謝寶友教你學Linux:深入理解Linux RCU之從硬件說起
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
基于Linux內核源碼的RCU實現方案
Linux內核RCU鎖的原理與使用
深入理解RCU:玩具式實現
分級RCU的基礎知識
Linux內核中RCU的用法
linux內核rcu機制詳解
深入理解Linux RCU:RCU是讀寫鎖的替代者
深入了解RCU是怎樣實現的?





 工商網監
工商網監
評論