 NVIDIA Jetson TX2將智能提升兩倍
NVIDIA Jetson TX2將智能提升兩倍
NVIDIA推出了Jetson TX2和JetPack 3.0 AI SDK。Jetson是全球領先的低功耗嵌入式平臺,可為各地的邊緣設備提供服務器級別的AI計算性能。Jetson TX2具有集成的256核NVIDIA Pascal GPU,六核ARMv8 64位CPU復合體和8GB LPDDR4內存以及128位接口。CPU復合體將雙核NVIDIA Denver 2與四核ARM Cortex-A57結合在一起。Jetson TX2模塊(如圖1所示)適合尺寸,重量和功率(SWaP)尺寸為50 x 87毫米,85克和7.5瓦典型能耗的小尺寸,重量和功耗。
物聯網(IoT)設備通常用作中繼數據的簡單網關。他們依靠云連接來執行繁重的工作和數字處理。邊緣計算是一種新興的范例,它使用本地計算來實現數據源的分析。憑借超過TFLOP / s的性能,Jetson TX2非常適合將先進的AI部署到缺乏或昂貴的互聯網連接的遠程現場位置。Jetson TX2還為需要任務關鍵型自治功能的智能機器提供接近實時的響應能力和最小的等待時間。
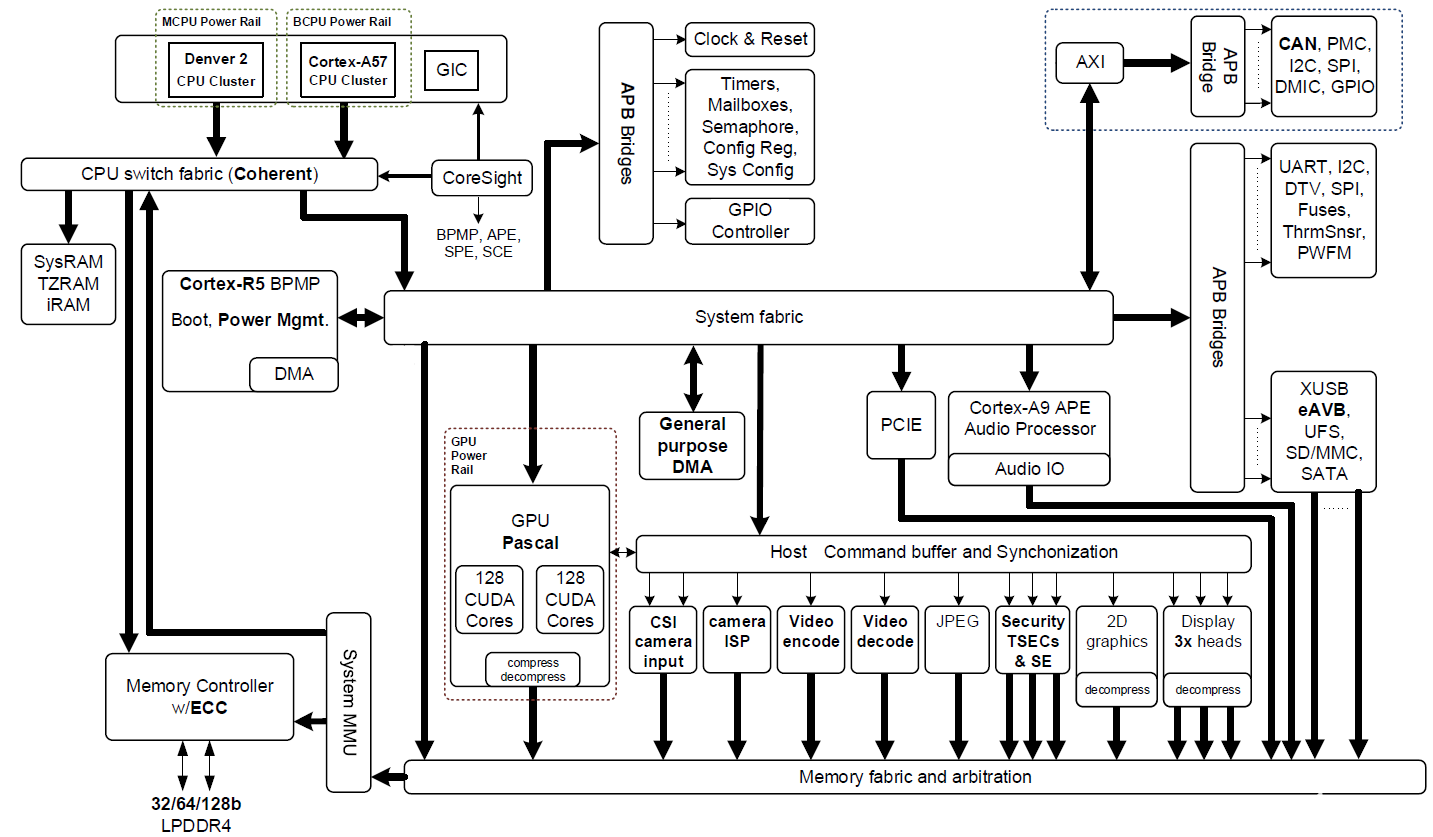
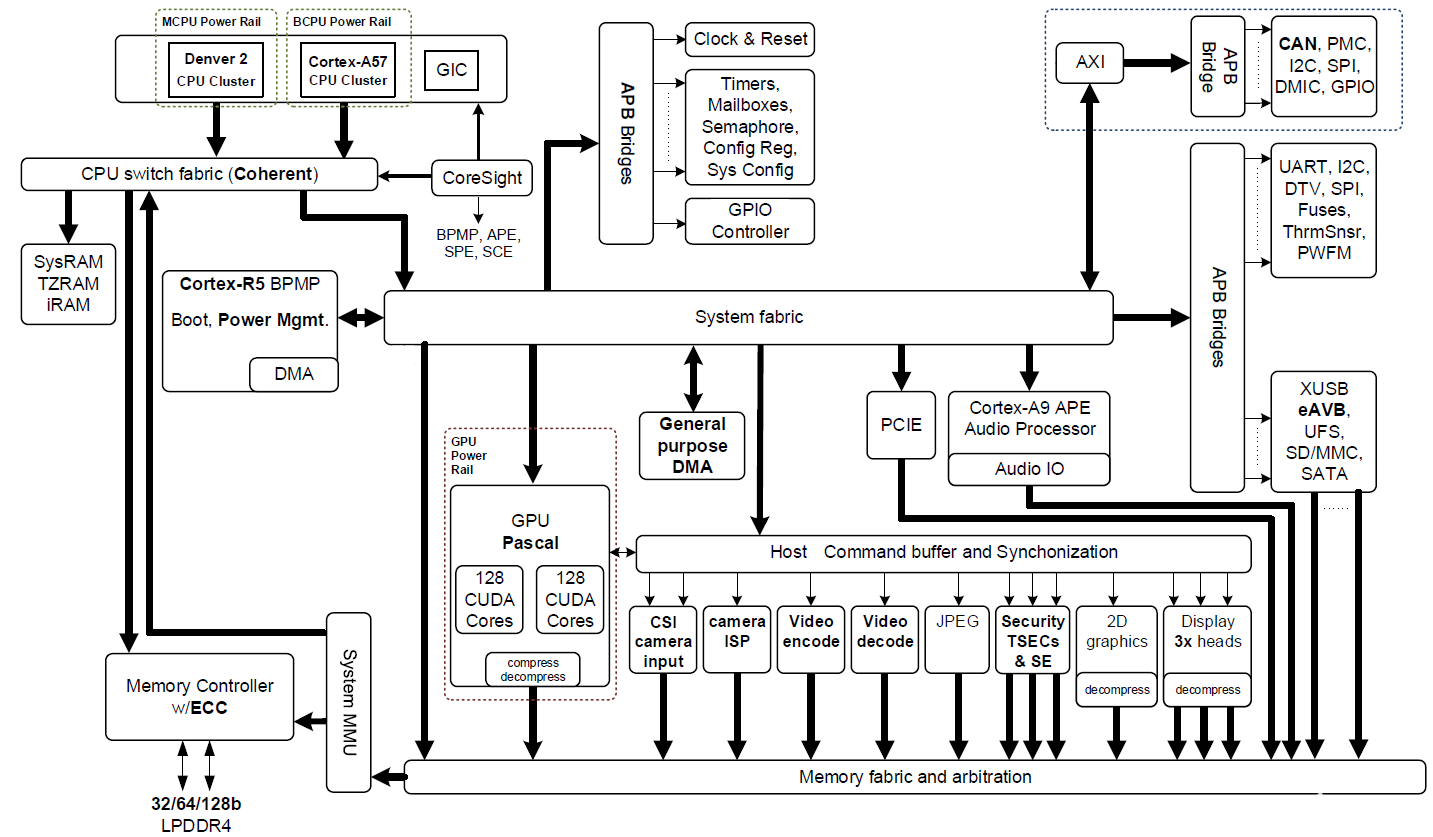
Jetson TX2基于16納米NVIDIA Tegra“Parker”片上系統(SoC)(圖2顯示了一個框圖)。Jetson TX2的深度學習推斷能效比其前身Jetson TX1高兩倍,并且性能比Intel Xeon Server CPU高。效率的這種跳躍重新定義了將高級AI從云端擴展到邊緣的可能性。
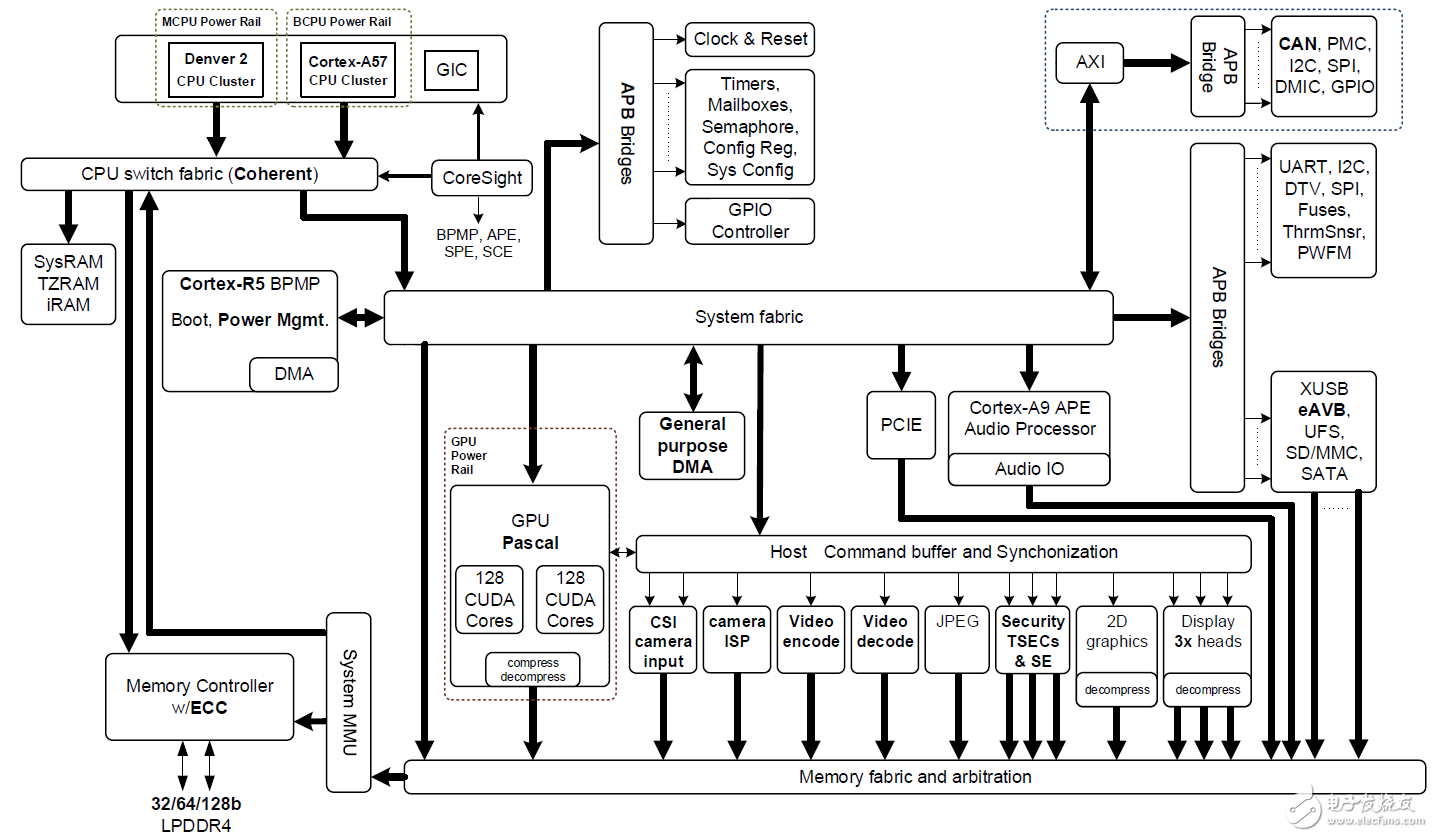 圖2:搭載NVIDIA Pascal GPU,NVIDIA Denver 2 + ARM Cortex-A57 CPU集群以及多媒體加速引擎的NVIDIA Jetson TX2 Tegra“Parker”SoC框圖(點擊圖片查看完整分辨率)。
圖2:搭載NVIDIA Pascal GPU,NVIDIA Denver 2 + ARM Cortex-A57 CPU集群以及多媒體加速引擎的NVIDIA Jetson TX2 Tegra“Parker”SoC框圖(點擊圖片查看完整分辨率)。
Jetson TX2擁有多個多媒體流引擎,通過卸載傳感器采集和分配來保持其Pascal GPU提供數據。這些多媒體引擎包括六個專用MIPI CSI-2攝像機端口,每個通道帶寬可提供2.5 Gb / s,雙圖像服務處理器(ISP)提供1.4 Gigapix / s處理能力,以及支持H.265的4K視頻編解碼器每秒60幀。
Jetson TX2使用NVIDIA cuDNN和TensorRT庫加速前沿深度神經網絡(DNN)架構,支持遞歸神經網絡(RNN),長期短期記憶網絡(LSTM)和在線強化學習。其雙CAN總線控制器使自動駕駛儀集成能夠控制使用DNN的機器人和無人機,以感知周圍的世界并在動態環境中安全運行。JetsonTX2的軟件通過NVIDIA的JetPack 3.0和Linux For Tegra(L4T)板級支持包(BSP)提供。
表1比較了Jetson TX2和上一代Jetson TX1的特性。
NVIDIA
Jetson TX1NVIDIA
Jetson TX2中央處理器ARM Cortex-A57(四核)@ 1.73GHzARM Cortex-A57(四核)@ 2GHz +
NVIDIA Denver2(雙核)@ 2GHzGPU256核心Maxwell @ 998MHz256核心Pascal @ 1300MHz記憶4GB 64位LPDDR4 @ 1600MHz |25.6 GB / s8GB 128位LPDDR4 @ 1866Mhz |59.7 GB / s存儲16GB eMMC 5.132GB eMMC 5.1編碼器*4Kp30,(2x)1080p604Kp60,(3x)4Kp30,(8x)1080p30解碼器*4Kp60,(4x)1080p60(2x)4Kp60相機?12條泳道MIPI CSI-2 |每通道1.5 Gb / s |1400萬像素/秒ISP12條泳道MIPI CSI-2 |每通道2.5 Gb /秒|1400萬像素/秒ISP顯示2x HDMI 2.0 / DP 1.2 / eDP 1.2 |2x MIPI DSI無線802.11a / b / g / n / ac 2×2 867Mbps |藍牙4.0802.11a / b / g / n / ac 2×2 867Mbps |藍牙4.1以太網絡10/100/1000 BASE-T以太網USBUSB 3.0 + USB 2.0的PCIeGen 2 |1×4 + 1×1Gen 2 |1×4 + 1×1或2×1 + 1×2能夠不支持雙CAN總線控制器雜項I / OUART,SPI,I2C,I2S,GPIO插座400針Samtec板對板連接器,50x87mm暖流?-25°C至80°C功率??10W7.5W價錢1K單位299美元1K單位399美元表1:Jetson TX1和Jetson TX2的比較。
*支持的視頻編解碼器:H.264,H.265,VP8,VP9
?MIPI CSI-2分岔:多達6個2通道或3個4通道相機
?工作溫度范圍,TTP最大結溫。
??負載下的典型功耗,輸入?5.5-19.6 VDC,Jetson TX2:最大Q值曲線。
性能提高兩倍,效率提高兩倍
在我關于JetPack 2.3的文章中,我演示了NVIDIA TensorRT如何提高Jetson TX1深度學習推理性能,效率比桌面級CPU高18倍。TensorRT通過使用圖優化,內核融合,半精度浮點計算(FP16)和架構自動調整優化生產網絡以顯著提高性能。除了利用Jetson TX2對FP16的硬件支持外,NVIDIA TensorRT還能夠批量同時處理多個圖像,從而實現更高的性能。
Jetson TX2和JetPack 3.0一起將Jetson平臺的性能和效率提升到一個全新的水平,為用戶提供兩倍于Jetson TX1的性能或兩倍于AI應用的性能。這種獨特的功能使Jetson TX2成為在邊緣需要高效AI的產品和靠近邊緣需要高性能的產品的理想選擇。Jetson TX2也與Jetson TX1兼容,并為使用Jetson TX1設計的產品提供輕松升級機會。
為了對Jetson TX2和JetPack 3.0的性能進行基準測試,我們將其與服務器級CPU Intel Xeon E5-2690 v4進行比較,并使用GoogLeNet深度圖像識別網絡測量深度學習推理吞吐量(每秒圖像數)。如圖3所示,運行功耗低于15W的Jetson TX2的性能優于運行在近200W的CPU,從而在邊緣實現了數據中心級別的AI功能。
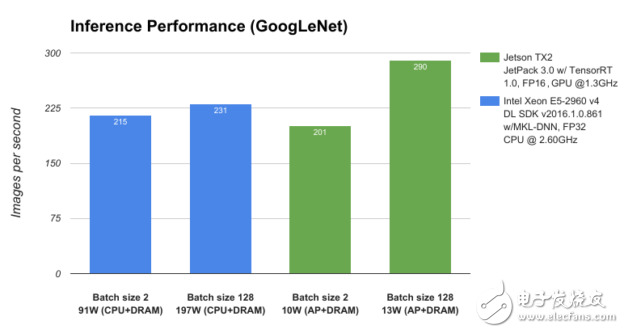 圖3:在NVIDIA Jetson TX2和Intel Xeon E5-2960 v4上分析的GoogLeNet網絡體系結構的性能。
圖3:在NVIDIA Jetson TX2和Intel Xeon E5-2960 v4上分析的GoogLeNet網絡體系結構的性能。
Jetson TX2的這種卓越的AI性能和效率來源于全新的Pascal GPU架構和動態能量配置文件(Max-Q和Max-P),JetPack 3.0附帶的優化深度學習庫以及大容量存儲器帶寬。
Max-Q和Max-P
Jetson TX2專為7.5W功率下的峰值處理效率而設計。這種性能水平(稱為Max-Q)代表功率/吞吐量曲線的峰值。包括電源在內的模塊上的每個組件都經過優化,可在此時提供最高的效率。GPU的Max-Q頻率為854 MHz,ARM A57 CPU為1.2 GHz。JetPack 3.0中的L4T BSP包含預設平臺配置,用于將Jetson TX2設置為Max-Q模式。JetPack 3.0還包含一個新的命令行工具,稱為nvpmodel在運行時切換配置文件。
雖然動態電壓和頻率調節(DVFS)允許Jetson TX2的Tegra“Parker”SoC在運行時根據用戶負載和功耗調整時鐘速度,但Max-Q配置設置了時鐘上限以確保應用程序正在運行只在最有效的范圍內。表2顯示了運行GoogLeNet和AlexNet深度學習基準時Jetson TX2和Jetson TX1的性能和能效。運行在Max-Q模式下的Jetson TX2的性能與Jetson TX1在最大時鐘頻率下運行的性能相似,但功耗僅為一半,因此能效提高一倍。
盡管大多
-
NVIDIA
+關注
關注
14文章
4990瀏覽量
103105 -
物聯網
+關注
關注
2909文章
44671瀏覽量
373634
發布評論請先 登錄
相關推薦
NVIDIA Jetson TX2助力安全巡檢 大幅提高巡檢效率
如何在JetSon TX2上移植VINS-Mono與RTAB-Map
如何去搭建一種基于Jetson TX2的全向四輪小車
TX2是如何控制風扇轉速的
怎樣在JetSon TX2上移植Vins-Mono與RTAB-Map呢
英偉達專為物聯網產品發布新品:Jetson TX2移動SoC平臺
Nvidia Jetson TX2系列管腳和功能名稱指南
微雪電子NVIDIA Jetson TX2人工智能開發套件介紹

NVIDIA Jetson TX2為邊緣提供雙倍的智能
NVIDIA Jetson TX2 將深度學習推理提升至兩倍





 工商網監
工商網監
評論