

想要進行圖像分割,傳統方法是先檢測圖中物體,在進行分離。在本文中,來自清華大學、騰訊AI研究室和英國卡迪夫大學的研究者們提出了一種新型分割圖像中人物的方法,基于人物動作辨認。以下是論智對原文的編譯。

圖像分割的一般方法是先對物體進行檢測,然后用邊界框對畫中物體進行分割。最近,例如Mask R-CNN的深度學習方法也被用于圖像分割任務,但是大多數研究都沒有注意到人類的特殊性:可以通過身體姿勢進行辨認。在這篇論文中,我們提出了一種新方法,可以通過人作出的不同動作進行圖像分割。
多人姿態辨認的目的是分辨圖像中每個人物的動作,這些需要通過身體部位判斷,比如頭部、肩膀、手部、腳等等。而一般的對象分割實例旨在預測圖像中每個對象的像素級標簽。要想解決這兩個問題,都需要檢測目標物體并將它們分離,這一過程通常被稱為目標檢測。但是由于二維圖像所含信息較少,導致想分離兩個重疊的同類圖像非常困難。對于目標檢測,有許多強有力的基準系統,例如Fast/Faster R-CNN、YOLO,它們都遵循著一個基本規則:先生成大量proposal regions,然后用非極大抑制刪除重復區域。但是,當兩個相同類別的物體重疊時,NMS總是將其中一個視為重復的proposal region,然后刪除它。這表明幾乎所有的目標檢測都不能處理大面積重合的問題。
盡管在許多多人姿態識別任務中都選用了這種框架,一些不依賴于目標檢測的bottom-up方法也取得了良好性能。Bottom-up方法的主要思想是首先在所有人身體上找幾個關鍵點。如圖1所示:
圖1
這種方法有幾個優點,首先,運行成本不會隨著圖像中人數的增加而增加;其次,兩個重疊在一起的人物可以在連接身體部位時分開,如圖2所示,使用人體姿勢可以改善目標檢測中物體重疊的問題。

圖2
新方法Pose2Seg
基于人體姿勢識別,我們提出了一種端到端的物體分割框架,整體框架如圖3所示,它將圖片和姿勢識別結果一同作為輸入:
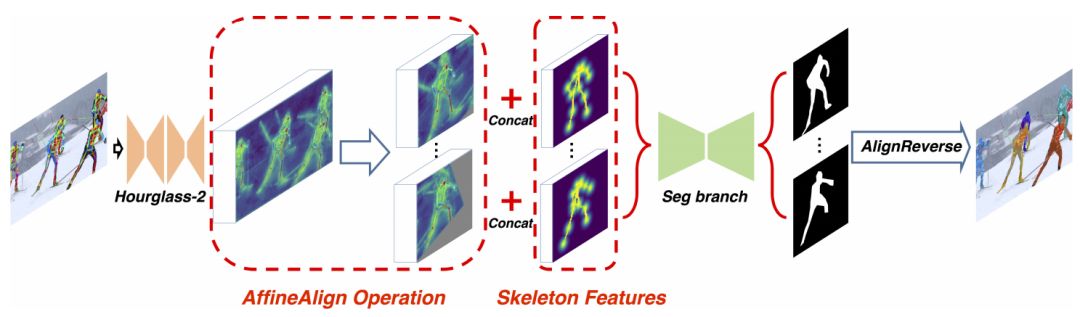
圖3
然后我們使用一個對準模塊,基于人體姿勢檢測結果(稱為Affine Align),將感興趣區域(ROI)對齊為統一大小(64×64)。同時,我們為圖中的每個人物生成骨架特征,并將它們連接到ROI。最終實驗表明,將骨骼信息明確地添加到網絡中可以在圖像分割中提供更好的信息。
AffineAlign
人類的動作種類多且復雜,想要進行圖像分割是很困難的。基于Faster R-CNN和Mask R-CNN中的ROIAlign,我們提出了AffineAlign操作。但是與它們不同的是,我們是基于人物的動作對齊,而不是邊界框。通過人類動作蘊涵的信息,AffineAlign操作可以把奇怪的人類動作拉直,然后將重疊的人分開,具體過程可看圖4:
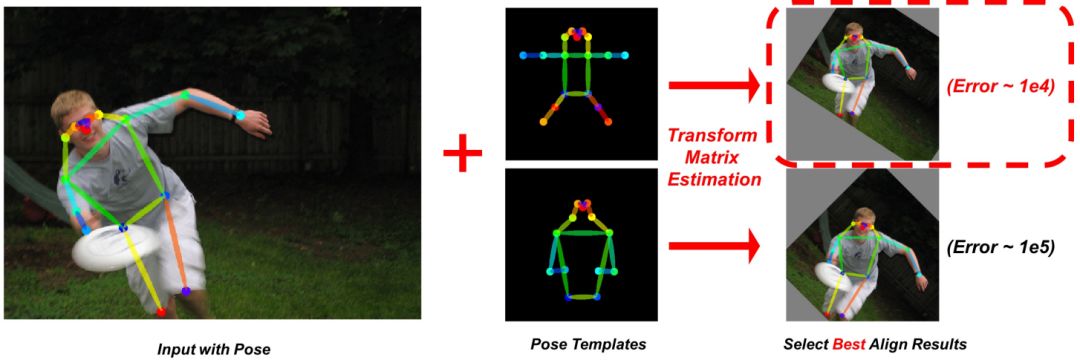
圖4
同時,我們還研究了人類骨骼的特征,我們用部分親和字段(PAF)重現某個動作的骨骼結構,PAF是一個有兩通道的向量字段映射,如果COCO數據集中有11個骨骼標記,PAF就是一個有22個通道的特征映射。

實驗過程
我們選用了COCO數據集,它是人類圖像數量最多的公開數據及,其中我們將其分成了COCOHUMAN和COCOHUMAN-OC兩個數據集,前者是有中等和大型目標物體的人類數據集,并對其中的動作進行了標注;后者是有較多重疊對象的圖像,共有44張圖。COCOHUMAN-OC中的一些樣例如圖所示:

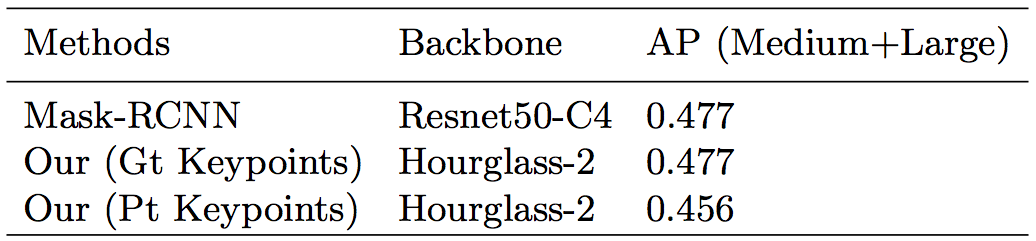
首先是在COCOHUMAN上,本文提出的方法與Mask R-CNN進行對比:
其他AffineAlign操作,a代表輸入的圖像,b代表在原圖上鎖定目標,c代表AffineAlign操作的結果,d代表分割結果
然后是在COCOHUMAN-OC上的實驗對比:
我們的方法與Mask R-CNN在處理重疊圖像上的表現。我們方法中的邊界框使用預測掩碼生成的,能更好地進行可視化和對比
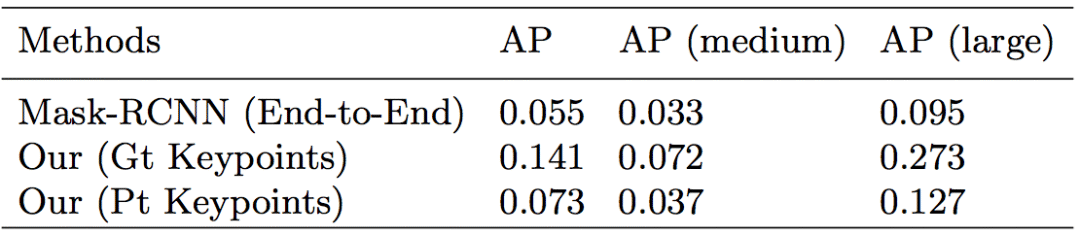
上表顯示,我們提出的基于動作姿勢的框架比基于圖像檢測的框架表現得好。由于非極大抑制,一些基于檢測的框架,如Mask R-CNN無法處理大面積重疊的現象。即使目標物體能被分離,仍然有一部分無法算入其中。但是在這種新框架下,我們做到了讓整個身體都被分離的結果。
-
圖像分割
+關注
關注
4文章
182瀏覽量
18180 -
深度學習
+關注
關注
73文章
5542瀏覽量
122265
原文標題:清華大學與騰訊AI合作推出Pose2Seg:無需目標檢測即對人像進行分割
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Unity 3D和Vuforia制作AR人物互動
一種新的彩色圖像分割算法

一種視頻流特定人物檢測方法
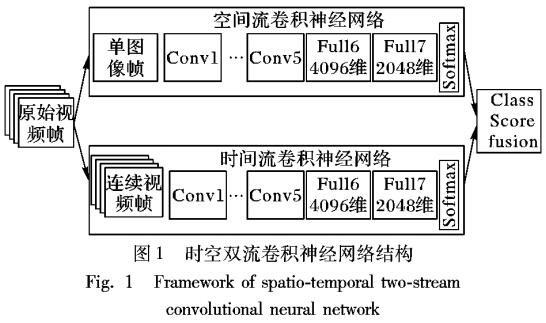
基于視頻深度學習的時空雙流人物動作識別模型
一種開源的機器學習模型,可在瀏覽器中使用TensorFlow.js對人物及身體部位進行分割
基于TensorFlow的開源JS庫的網頁前端人物動作捕捉的實現

一種可用于生成動漫人物頭像的改進模型






 工商網監
工商網監

評論