 根據美團“猜你喜歡”來深度學習排序模型實踐
根據美團“猜你喜歡”來深度學習排序模型實踐
▌引言
推薦作為解決信息過載和挖掘用戶潛在需求的技術手段,在美團點評這樣業務豐富的生活服務電子商務平臺,發揮著重要的作用。在美團App里,首頁的“猜你喜歡”、運營區、酒店旅游推薦等重要的業務場景,都是推薦的用武之地。
圖1 美團首頁“猜你喜歡”場景
目前,深度學習模型憑借其強大的表達能力和靈活的網絡結構在諸多領域取得了重大突破,美團平臺擁有海量的用戶與商家數據,以及豐富的產品使用場景,也為深度學習的應用提供了必要的條件。本文將主要介紹深度學習模型在美團平臺推薦排序場景下的應用和探索。
▌深度學習模型的應用與探索
美團推薦場景中每天活躍著千萬級別的用戶,這些用戶與產品交互產生了海量的真實行為數據,每天能夠提供十億級別的有效訓練樣本。為處理大規模的訓練樣本和提高訓練效率,我們基于PS-Lite研發了分布式訓練的DNN模型,并基于該框架進行了很多的優化嘗試,在排序場景下取得了顯著的效果提升。
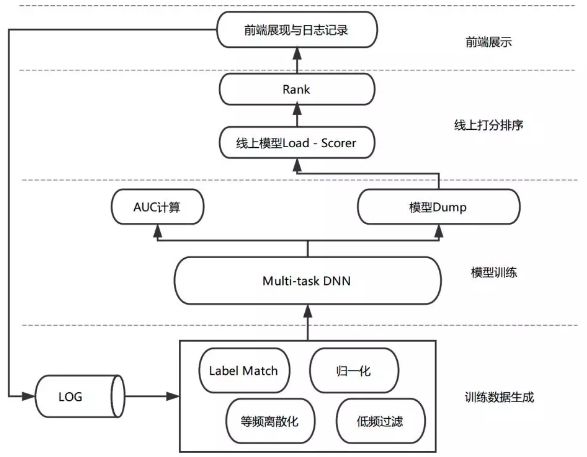
圖2 模型排序流程圖
如上圖所示,模型排序流程包括日志收集、訓練數據生成、模型訓練和線上打分等階段。當推薦系統對瀏覽推薦場景的用戶進行推薦時,會記錄當時的商品特征、用戶狀態與上下文信息,并收集本次推薦的用戶行為反饋。在經過標簽匹配和特征處理流程后生成最終的訓練數據。我們在離線運用PS-Lite框架對Multi-task DNN模型進行分布式訓練,通過離線評測指標選出效果較好的模型并加載到線上,用于線上排序服務。
下面將著重介紹我們在特征處理和模型結構方面所做的優化與嘗試。
特征處理
美團“猜你喜歡”場景接入了包括美食、酒店、旅游、外賣、民宿、交通等多種業務,這些業務各自有著豐富的內涵和特點,同時各業務的供給、需求與天氣、時間、地理位置等條件交織,構成了O2O生活服務場景下特有的多樣性和復雜性,這就給如何更高效地組織排序結果提出了更高的要求。構造更全面的特征、更準確高效地利用樣本一直是我們優化的重點方向。
特征種類
User特征:用戶年齡,性別,婚否,有無孩子等
Item特征:價格,折扣,品類和品牌相關特征,短期和長期統計類特征等
Context特征:天氣,時間,地理位置,溫度等
用戶行為:用戶點擊Item序列,下單Item序列等
除上述列舉的幾類特征外,我們還根據O2O領域的知識積累,對部分特征進行交叉,并針對學習效果對特征進行了進一步處理。具體的樣本和特征處理流程如下:
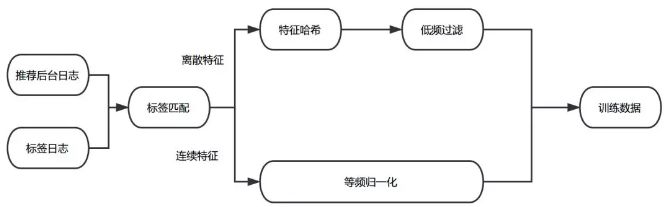
圖3 訓練數據處理流程
標簽匹配
推薦后臺日志會記錄當前樣本對應的User特征、Item特征與Context特征,Label日志會捕獲用戶對于推薦項的行為反饋。我們把兩份數據按照唯一ID拼接到一起,生成原始的訓練日志。
等頻歸一化
通過對訓練數據的分析,我們發現不同維度特征的取值分布、相同維度下特征值的差異都很大。例如距離、價格等特征的數據服從長尾分布,體現為大部分樣本的特征值都比較小,存在少量樣本的特征值非常大。常規的歸一化方法(例如min-max,z-score)都只是對數據的分布進行平移和拉伸,最后特征的分布仍然是長尾分布,這就導致大部分樣本的特征值都集中在非常小的取值范圍內,使得樣本特征的區分度減小;與此同時,少量的大值特征可能造成訓練時的波動,減緩收斂速度。此外也可以對特征值做對數轉化,但由于不同維度間特征的分布不同,這種特征值處理的方式并不一定適用于其他維度的特征。
在實踐中,我們參考了Google的Wide & Deep Model[6]中對于連續特征的處理方式,根據特征值在累計分布函數中的位置進行歸一化。即將特征進行等頻分桶,保證每個桶里的樣本量基本相等,假設總共分了n個桶,而特征xi屬于其中的第bi(bi∈ {0, …, n - 1})個桶,則特征xi最終會歸一化成bi/n。這種方法保證對于不同分布的特征都可以映射到近似均勻分布,從而保證樣本間特征的區分度和數值的穩定性。
低頻過濾
過多的極為稀疏的離散特征會在訓練過程中造成過擬合問題,同時增加參數的儲存數量。為避免該問題,我們對離散特征進行了低頻過濾處理,丟掉小于出現頻次閾值的特征。
經過上述特征抽取、標簽匹配、特征處理后,我們會給特征分配對應的域,并對離散特征進行Hash處理,最終生成LIBFFM格式的數據,作為Multi-task DNN的訓練樣本。下面介紹針對業務目標所做的模型方面的優化嘗試。
模型優化與嘗試
在模型方面,我們借鑒工業界的成功經驗,在MLP模型的基礎上,針對推薦場景進行模型結構方面的優化。在深度學習中,很多方法和機制都具有通用性,比如Attention機制在機器翻譯,圖像標注等方向上取得了顯著的效果提升,但并不是所有具體的模型結構都能夠直接遷移,這就需要結合實際業務問題,對引入的模型網絡結構進行了針對性調整,從而提高模型在具體場景中的效果。
Multi-task DNN
推薦場景上的優化目標要綜合考慮用戶的點擊率和下單率。在過去我們使用XGBoost進行單目標訓練的時候,通過把點擊的樣本和下單的樣本都作為正樣本,并對下單的樣本進行上采樣或者加權,來平衡點擊率和下單率。但這種樣本的加權方式也會有一些缺點,例如調整下單權重或者采樣率的成本較高,每次調整都需要重新訓練,并且對于模型來說較難用同一套參數來表達這兩種混合的樣本分布。針對上述問題,我們利用DNN靈活的網絡結構引入了Multi-task訓練。
根據業務目標,我們把點擊率和下單率拆分出來,形成兩個獨立的訓練目標,分別建立各自的Loss Function,作為對模型訓練的監督和指導。DNN網絡的前幾層作為共享層,點擊任務和下單任務共享其表達,并在BP階段根據兩個任務算出的梯度共同進行參數更新。網絡在最后一個全連接層進行拆分,單獨學習對應Loss的參數,從而更好地專注于擬合各自Label的分布。
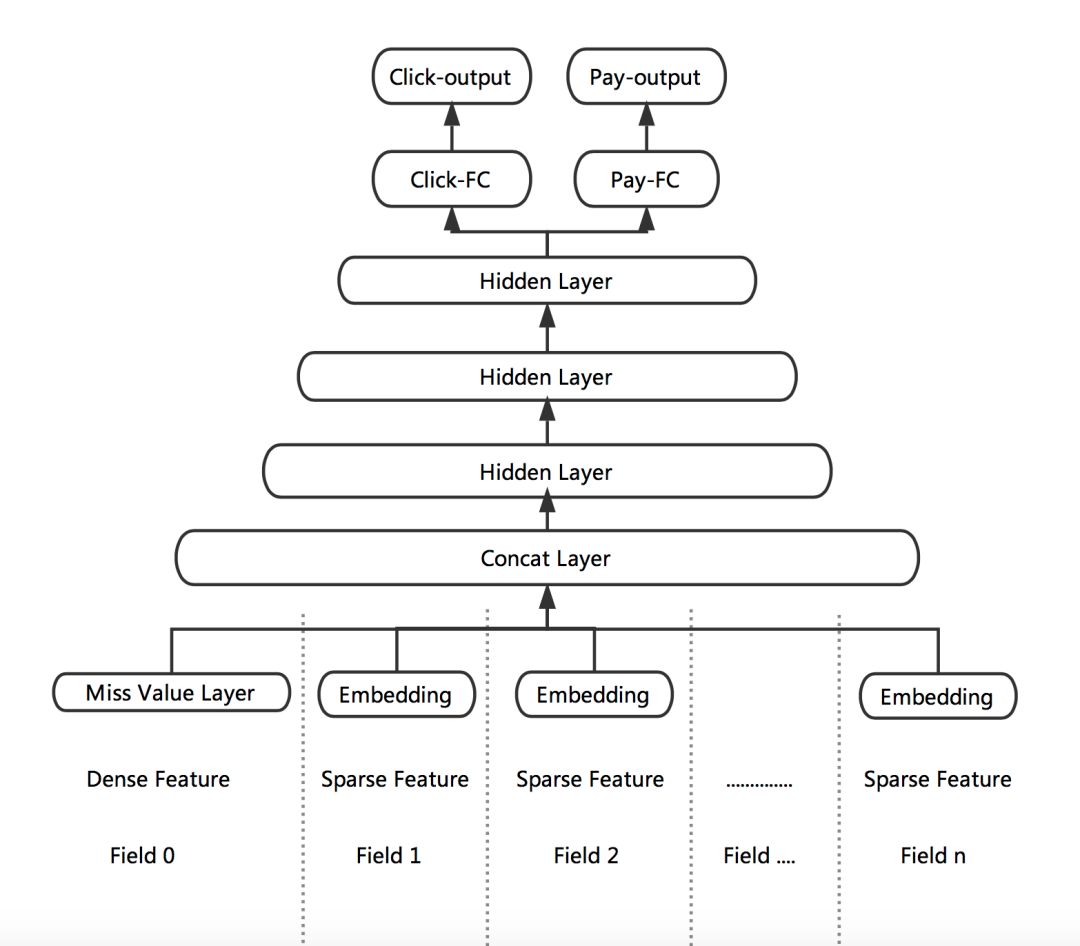
圖4 點擊與下單多目標學習
Multi-task DNN的網絡結構如上圖所示。線上預測時,我們將Click-output和Pay-output做一個線性融合。
在此結構的基礎上,我們結合數據分布特點和業務目標進行了進一步的優化:針對特征缺失普遍存在的情況我們提出Missing Value Layer,以用更合理的方式擬合線上數據分布;考慮將不同task的物理意義關聯起來,我們提出KL-divergence Bound,以減輕某單一目標的Noise的影響。下面我們就這兩塊工作做具體介紹。
Missing Value Layer
通常在訓練樣本中難以避免地有部分連續特征存在缺失值,更好地處理缺失值會對訓練的收斂和最終效果都有一定幫助。通常處理連續特征缺失值的方式有:取零值,或者取該維特征的平均值。取零值會導致相應權重無法進行更新,收斂速度減慢。而取平均值也略顯武斷,畢竟不同的特征缺失所表示的含義可能不盡相同。一些非神經網絡的模型能比較合理的處理缺失值,比如XGBoost會通過Loss的計算過程自適應地判斷特征缺失的樣本被劃分到左子樹還是右子樹更優。受此啟發,我們希望神經網絡也可以通過學習的方式自適應地處理缺失值,而不是人為設置默認值。因此設計了如下的Layer來自適應的學習缺失值的權重:
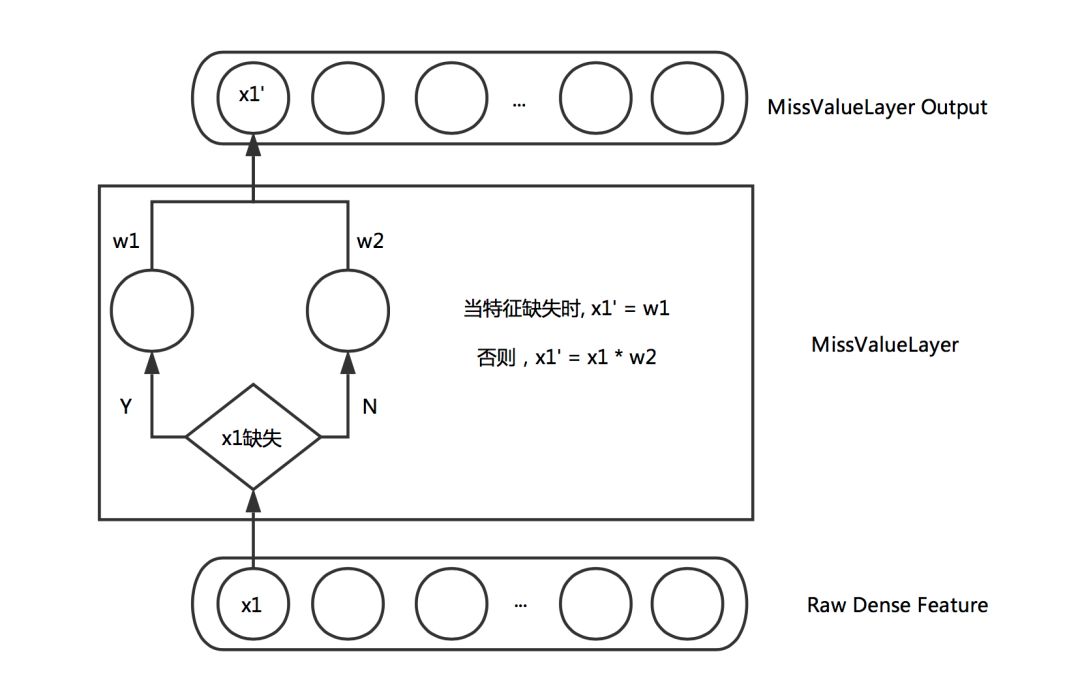
圖5 Miss Value Layer
通過上述的Layer,缺失的特征可以根據對應特征的分布去自適應的學習出一個合理的取值。
通過離線調研,對于提升模型的訓練效果,自適應學習特征缺失值的方法要遠優于取零值、取均值的方式,模型離線AUC隨訓練輪數的變化如下圖所示:
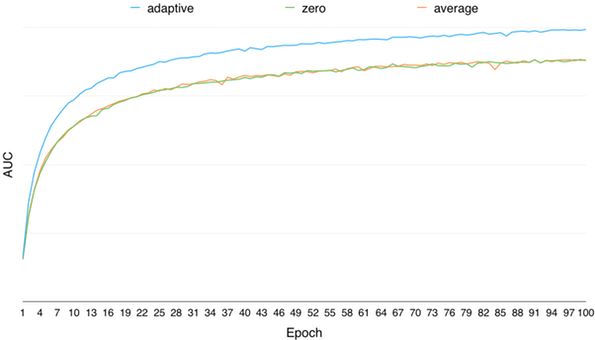
圖6 自適應學習特征缺失值與取0值和均值效果對比
AUC相對值提升如下表所示:
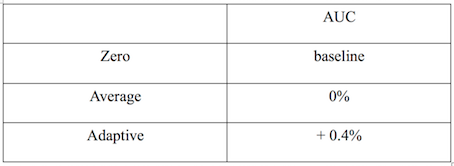
圖7 自適應學習特征缺失值AUC相對值提升
KL-divergence Bound
我們同時考慮到,不同的標簽會帶有不同的Noise,如果能通過物理意義將有關系的Label關聯起來,一定程度上可以提高模型學習的魯棒性,減少單獨標簽的Noise對訓練的影響。例如,可以通過MTL同時學習樣本的點擊率,下單率和轉化率(下單/點擊),三者滿足p(點擊) * p(轉化) = p(下單)的意義。因此我們又加入了一個KL散度的Bound,使得預測出來的p(點擊) * p(轉化)更接近于p(下單)。但由于KL散度是非對稱的,即KL(p||q) != KL(q||p),因此真正使用的時候,優化的是KL(p||q) + KL(q||p)。
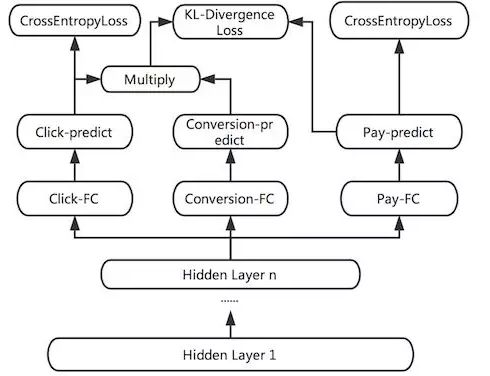
圖8 KL-divergence Bound
經過上述工作,Multi-tast DNN模型效果穩定超過XGBoost模型,目前已經在美團首頁“猜你喜歡”場景全量上線,在線上也取得了點擊率的提升:
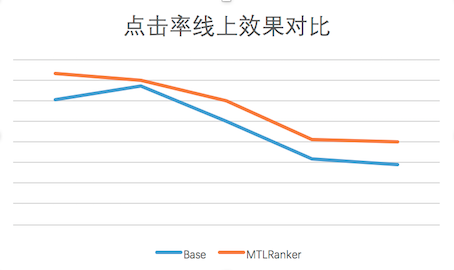
圖9 線上CTR效果與基線對比圖
線上CTR相對值提升如下表所示:
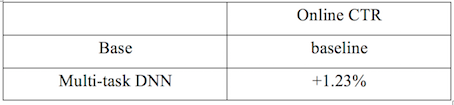
圖10 線上CTR效果相對值提升
除了線上效果的提升,Multi-task訓練方式也很好的提高了DNN模型的擴展性,模型訓練時可以同時考慮多個業務目標,方便我們加入業務約束。
更多探索
在Multi-task DNN模型上線后,為了進一步提升效果,我們利用DNN網絡結構的靈活性,又做了多方面的優化嘗試。下面就NFM和用戶興趣向量的探索做具體介紹。
NFM
為了引入Low-order特征組合,我們在Multi-task DNN的基礎上進行了加入NFM的嘗試。各個域的離散特征首先通過Embedding層學習得到相應的向量表達,作為NFM的輸入,NFM通過Bi-Interaction Pooling的方式對輸入向量對應的每一維進行2-order的特征組合,最終輸出一個跟輸入維度相同的向量。我們把NFM學出的向量與DNN的隱層拼接在一起,作為樣本的表達,進行后續的學習。
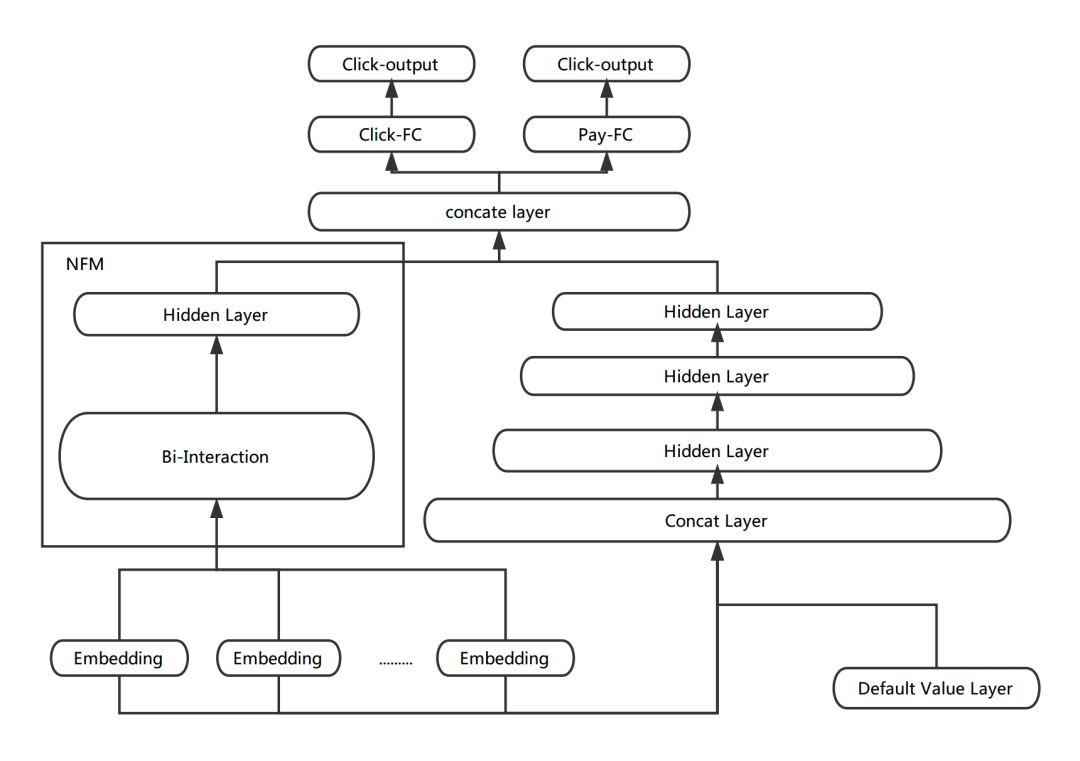
圖11 NFM + DNN
NFM的輸出結果為向量形式,很方便和DNN的隱層進行融合。而且從調研的過程中發現,NFM能夠加快訓練的收斂速度,從而更有利于Embedding層的學習。因為DNN部分的層數較多,在訓練的BP階段,當梯度傳到最底層的Embedding層時很容易出現梯度消失的問題,但NFM與DNN相比層數較淺,有利于梯度的傳遞,從而加快Embedding層的學習。
通過離線調研,加入NFM后,雖然訓練的收斂速度加快,但AUC并沒有明顯提升。分析原因是由于目前加入NFM模型部分的特征還比較有限,限制了學習的效果。后續會嘗試加入更多的特征域,以提供足夠的信息幫助NFM學出有用的表達,深挖NFM的潛力。
用戶興趣向量
用戶興趣作為重要的特征,通常體現在用戶的歷史行為中。通過引入用戶歷史行為序列,我們嘗試了多種方式對用戶興趣進行向量化表達。
Item的向量化表達:線上打印的用戶行為序列中的Item是以ID的形式存在,所以首先需要對Item進行Embedding獲取其向量化的表達。最初我們嘗試通過隨機初始化Item Embedding向量,并在訓練過程中更新其參數的方式進行學習。但由于Item ID的稀疏性,上述隨機初始化的方式很容易出現過擬合。后來采用先生成item Embedding向量,用該向量進行初始化,并在訓練過程中進行fine tuning的方式進行訓練。
用戶興趣的向量化表達:為生成用戶興趣向量,我們對用戶行為序列中的Item向量進行了包括Average Pooling、 Max Pooling與Weighted Pooling三種方式的融合。其中Weighted Pooling參考了DIN的實現,首先獲取用戶的行為序列,通過一層非線性網絡(Attention Net)學出每個行為Item對于當前要預測Item的權重(Align Vector),根據學出的權重,對行為序列進行Weighted Pooling,最終生成用戶的興趣向量。計算過程如下圖所示:
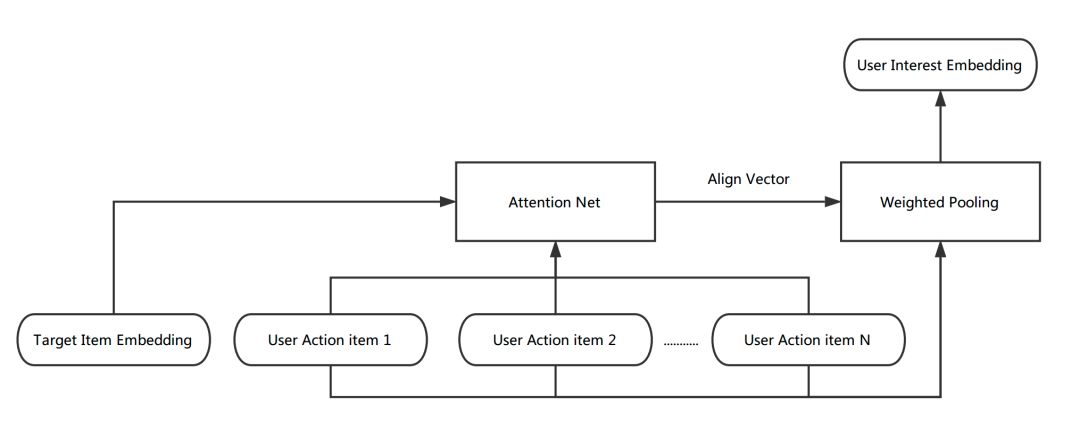
圖12 Weighted Pooling
通過離線AUC對比,針對目前的訓練數據,Average Pooling的效果為最優的。效果對比如下圖所示:
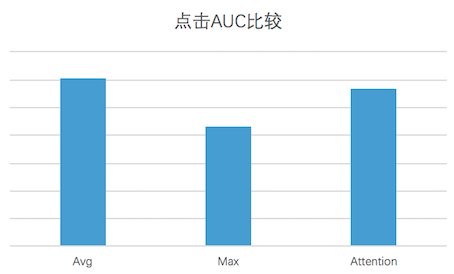
圖13 不同Pooling方式點擊AUC對比
以上是我們在模型結構方面的優化經驗和嘗試,下面我們將介紹針對提高模型訓練效率所做的框架性能優化工作。
訓練效率優化
經過對開源框架的廣泛調研和選型,我們選擇了PS-Lite作為DNN模型的訓練框架。PS-Lite是DMLC開源的Parameter Server實現,主要包含Server和Worker兩種角色,其中Server端負責模型參數的存儲與更新,Worker端負責讀取訓練數據、構建網絡結構和進行梯度計算。相較于其他開源框架,其顯著優點在于:
PS框架:PS-Lite的設計中可以更好的利用特征的稀疏性,適用于推薦這種有大量離散特征的場景。
封裝合理:通信框架和算法解耦,API強大且清晰,集成比較方便。
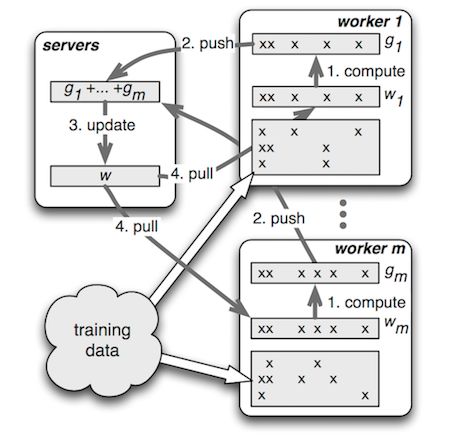
圖14 Parameter Server
在開發過程中,我們也遇到并解決了一些性能優化問題:
為了節約Worker的內存,通常不會將所有的數據儲存在內存中,而是分Batch從硬盤中Pre-fetch數據,但這個過程中存在大量的數據解析過程,一些元數據的重復計算(大量的key排序去重等),累計起來也是比較可觀的消耗。針對這個問題我們修改了數據的讀取方式,將計算過的元數據也序列化到硬盤中,并通過多線程提前將數據Pre-fetch到對應的數據結構里,避免了在此處浪費大量的時間來進行重復計算。
在訓練過程中Worker的計算效率受到宿主機實時負載和硬件條件的影響,不同的Worker之間的執行進度可能存在差異(如下圖所示,對于實驗測試數據,大部分Worker會在700秒完成一輪訓練,而最慢的Worker會耗時900秒)。而通常每當訓練完一個Epoch之后,需要進行模型的Checkpoint、評測指標計算等需要同步的流程,因此最慢的節點會拖慢整個訓練的流程。考慮到Worker的執行效率是大致服從高斯分布的,只有小部分的Worker是效率極低的,因此我們在訓練流程中添加了一個中斷機制:當大部分的機器已經執行完當前Epoch的時候,剩余的Worker進行中斷,犧牲少量Worker上的部分訓練數據來防止訓練流程長時間的阻塞。而中斷的Worker在下個Epoch開始時,會從中斷時的Batch開始繼續訓練,保證慢節點也能利用所有的訓練數據。
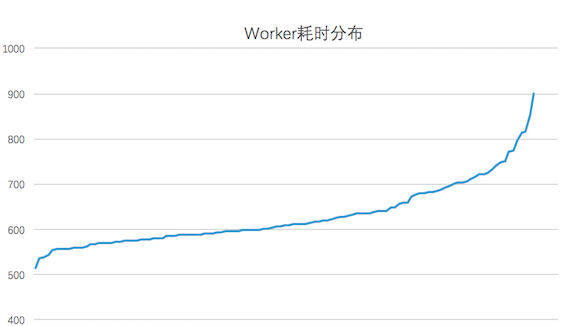
圖15 Worker耗時分布
▌總結與展望
深度學習模型落地到推薦場景后,對業務指標有了明顯的提升,今后我們還將深化對業務場景的理解,做進一步優化嘗試。
在業務方面,我們將嘗試對更多的業務規則進行抽象,以學習目標的方式加入到模型中。業務規則一般是我們短期解決業務問題時提出的,但解決問題的方式一般不夠平滑,規則也不會隨著場景的變化進行自適應。通過Multi-task方式,把業務的Bias抽象成學習目標,在訓練過程中對模型的學習進行指導,從而可以比較優雅的通過模型解決業務問題。
在特征方面,我們會繼續對特征的挖掘和利用進行深入調研。不同于其他推薦場景,對于O2O業務,Context特征的作用非常顯著,時間,地點,天氣等因素都會影響用戶的決策。今后會繼續嘗試挖掘多樣的Context特征,并利用特征工程或者模型進行特征的組合,用于優化對樣本的表達。
在模型方面,我們將持續進行網絡結構的探索,嘗試新的模型特性,并針對場景的特點進行契合。學術界和工業界的成功經驗都很有價值,給我們提供了新的思路和方法,但由于面臨的業務問題和場景積累的數據不同,還是需要進行針對場景的適配,以達到業務目標的提升。
-
數據處理
+關注
關注
0文章
607瀏覽量
28597 -
排序模型
+關注
關注
0文章
2瀏覽量
1530
原文標題:干貨 | 美團“猜你喜歡”深度學習排序模型實踐
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【NanoPi K1 Plus試用體驗】搭建深度學習框架
labview調用深度學習tensorflow模型非常簡單,附上源碼和模型
什么是深度學習?使用FPGA進行深度學習的好處?
深度學習在58同城首頁推薦中的應用





 工商網監
工商網監
評論