 基于深度學習的圖像塊型超分辨重建的經典論文進行關鍵技術點分析
基于深度學習的圖像塊型超分辨重建的經典論文進行關鍵技術點分析
分辨率極限,無論對于圖像重建或是圖像后處理算法的研究者,都是一項無法回避的技術指標。在實際的應用場景中,受限于圖像采集設備成本、視頻圖像傳輸帶寬,抑或是成像模態本身的技術瓶頸,我們并不是每一次都有條件獲得邊緣銳化,無塊狀模糊的大尺寸高清圖像。在這種需求背景下,超分辨重建技術應運而生。
圖1:圖片壓縮與傳輸
應用場景I:圖片壓縮與傳輸,即以較低的碼率進行圖像編碼,在傳輸過程中可極大節省轉發服務器的流量帶寬,在客戶端解碼得到相對低清晰度的圖片,最后通過超分辨重建技術處理獲得高清晰度圖片
圖2:生物組織成像
應用場景II:生物組織成像 左圖:光聲顯微成像圖像 右圖:光聲超分辨顯微圖像,細微的蜜蜂翅膀紋理清晰可見
傳統超分辨重建技術大體上可分為4類,分別是預測型(prediction-based), 邊緣型(edge-based), 統計型(statistical)和圖像塊型(patch-based/example-based)的超分辨重建方法。
我們選擇了4篇基于深度學習的圖像塊型超分辨重建的經典論文進行關鍵技術點分析,從中我們可以看出研究者們對于超分辨任務的不同的理解與解決問題思路。在2012年AlexNet以15.4%的歷史性超低的分類錯誤率獲得ImageNet大規模視覺識別挑戰賽年度冠軍,吹響了深度學習在計算機視覺領域爆炸發展的號角之后。超分辨重建技術也開始采用深度學習的思想,以期獲得更優的算法表現。
SRCNN
SRCNN是基于深度學習的超分辨重建領域的開山之作,繼承了傳統機器學習領域稀疏編碼的思想,利用三層卷積層分別實現:
圖像的圖像塊抽取與稀疏字典建立
圖像高、低分辨率特征之間的非線性映射
高分辨率圖像塊的重建
具體地,假設需要處理的低分辨率圖片的尺寸為H × W × C, 其中H、W、C分別表示圖片的長、寬和通道數;SRCNN第一層卷積核尺寸為C × f1 × f1 × n1,可以理解為在低分辨率圖片上滑窗式地提取f1 × f1的圖像塊區域進行n1種類型的卷積操作。在全圖范圍內,每一種類型卷積操作都可以輸出一個特征向量,最終n1個特征向量構成了低分辨率圖片的稀疏表示的字典,字典的維度為H1 × W1 × n1;SRCNN第二層卷積核尺寸為n1 × 1 × 1 × n2,以建立由低分辨率到高分辨率稀疏表示字典之間的非線性映射,輸出的高分辨率稀疏字典的維度為H1 × W1 × n2,值得注意的是在這一步中SRCNN并未采用全連接層(fully connected layer)來進行特征圖或是稀疏字典之間的映射,而是采用1x1卷積核,從而使得空間上每一個像素點位置的映射都共享參數,即每一個空間位置以相同的方式進行非線性映射; SRCNN第三層卷積核尺寸為n2 × f3 × f3 × C,由高分辨率稀疏字典中每一個像素點位置的n2 × 1向量重建f3 × f3圖像塊,圖像塊之間相互重合覆蓋,最終實現圖片的超分辨率重建。
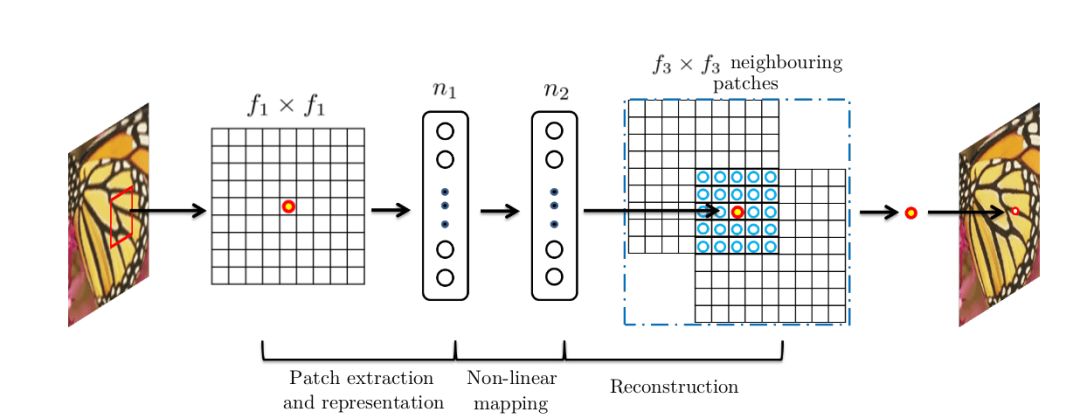
圖3:SRCNN的三層卷積結構
ESPCN
在SRCNN將CNN引入超分辨率重建領域之后,研究者們開始考慮如何利用“卷積”來解決更深入的問題。
如果對一幅高分辨率圖片做高斯平滑或是降采樣可以等效為卷積操作,那么由降采樣后低分辨率圖片恢復高分辨率的過程則相應的等效為反卷積操作(deconvolution)。此時我們的計算任務是學習合適的解卷積核,從低分辨率圖片中恢復高分辨率圖像。
CNN中反卷積層的標準做法如圖4所示,對一幅低分辨率圖片填充零值(zero padding),即以每一個像素點位置為中心,周圍2×2或3×3鄰域填充0,再以一定尺寸的卷積核進行卷積操作。
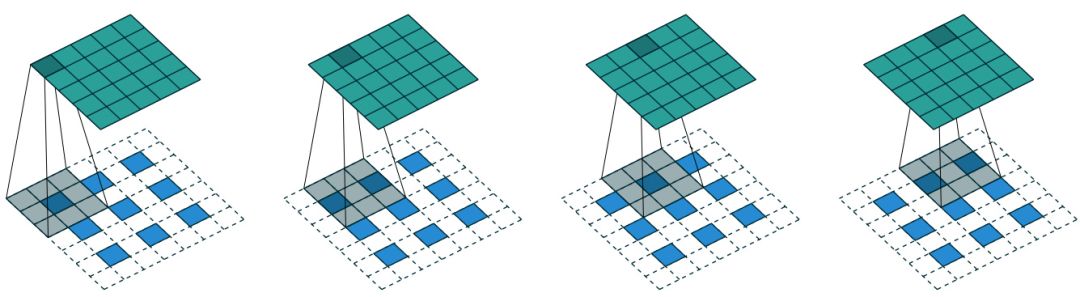
圖4:標準反卷積層實現示意圖
但是標準反卷積操作的弊端是顯而易見的,首先,填充的零值并不包含任何圖像相關的有效信息,其次填充后的圖片卷積操作的計算復雜度有所增加。
在這種情況下,Twitter圖片與視頻壓縮研究組將sub-pixel convolution的概念引入SRCNN中。
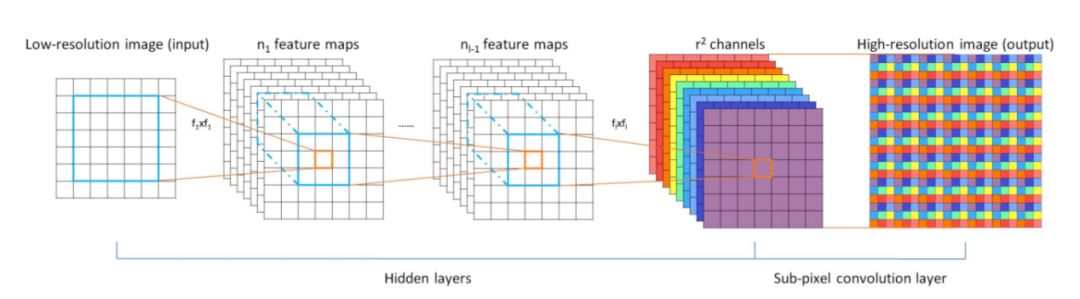
圖5:Efficient Sub-Pixel Convolutional Neural Network (ESPCN)網絡結構
Sub-Pixel核心思想在于對于任意維度為H × W × C的圖像,標準反卷積操作輸出的特征圖維度為rH × rW × C,其中r為超分辨系數即圖片尺寸放大的倍數,而sub-pixel的輸出特征圖維度為H × W × C × r2,即令特征圖與輸入圖片的尺寸保持一致,但增加卷積核的通道數,既使得輸入圖片中鄰域像素點的信息得到有效利用,還避免了填充0引入的計算復雜度增加。
Perceptual Loss
相較于其他機器學習任務,如物體檢測(object detection)或者實例分割(instance segmentation),超分辨重建技術中學習任務的損失函數的定義通常都相對簡單粗暴,由于我們重建的目的是為了使得重建的高分辨率圖片與真實高清圖片之間的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)盡可能的大,因此絕大多數的基于深度學習的超分辨重建研究都直接的將損失函數設計為平均均方差(Mean Square Error, MSE),即計算兩幅圖片所有對應像素位置點之間的均方差,由于MSE Loss要求像素點之間位置一一對應,因此又被稱作Per-Pixel Loss。
但隨著技術的發展,研究者慢慢發現Per-Pixel Loss的局限性。考慮一個極端的情況,將高清原圖向任意方向偏移一個像素,事實上圖片本身的分辨率與風格并未發生太大的改變,但Per-Pixel Loss卻會因為這一個像素的偏移而出現顯著的上升,因此Per-Pixel Loss的約束并不能反應圖像高級的特征信息(high-level features)。
因此研究圖像風格遷移的研究者們相對于Per-Pixel Loss在2016年的CVPR會議上提出了Perceptual Loss的概念。
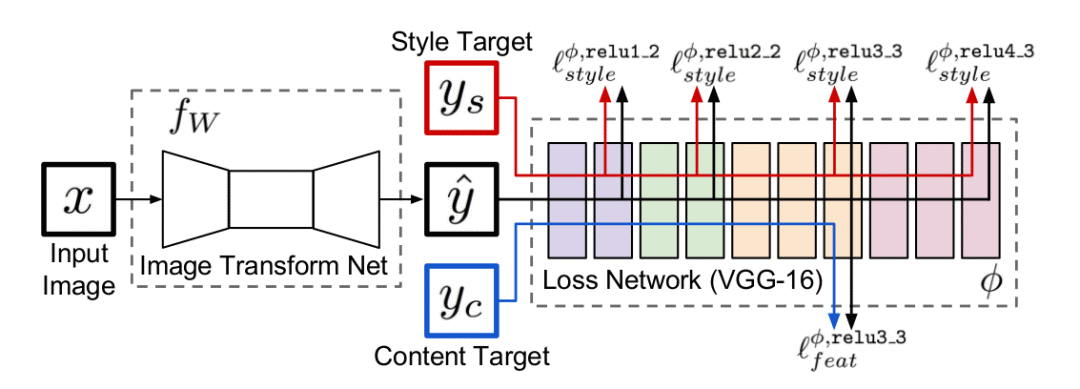
圖6:基于Perceptual Loss的全卷積網絡結構
基于Per-Pixel Loss的超分辨重建網絡目標在于直接最小化高清原圖與超分辨重建圖像之間的差異,使得超分辨重建圖像逐步逼近原圖的清晰效果。但Perceptual Loss最小化的是原圖與重建圖像的特征圖之間的差異,為了提高計算效率,Perceptual Loss中的特征圖由固定權重值的卷積神經網絡提取,例如在ImageNet數據集上預訓練得到的VGG16網絡,如圖7所示,不同深度的卷積層提取的特征信息不同,反映的圖像的紋理也不同。

圖7:不同深度的卷積層提取的圖片特征示意圖
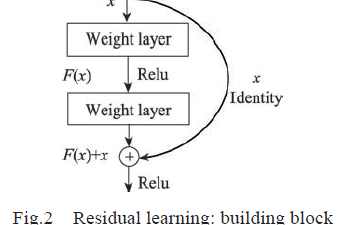
因此研究者們在訓練超分辨神經網絡時,利用跨間隔的卷積層(strided convolution layer)代替池化層(pooling layer)構建全卷積神經網絡(Fully Convolutional Network, FCN)進行超分辨重建,并在卷積層之間添加殘差結構(residual block)以在保證網絡擬合性能的前提下加深網絡深度獲得更佳表現。最終利用VGG16網絡對原圖與重建圖像進行特征提取,最小化兩者特征圖之間的差異使得超分辨重建圖像不斷逼近原圖的分辨率。
RAISR
前面提到的幾種典型的圖像塊型(也被稱作樣例型)超分辨技術,都是在高低分辨率圖像塊一一對應的數據基礎上,學習由低分辨率到高分辨率圖像塊的映射。具體的來說,通常這種映射是一系列的濾波器,針對輸入圖片不同像素位置點的不同的紋理特征來選擇適當的濾波器進行超分辨重建。基于這種思想,Google于2016年在SRCNN,A+以及ESPCN等超分辨研究的基礎上發布了RAISR算法。
該算法主打高速的實時性能與極低的計算復雜度,核心思想在于利用配對的高低分辨率圖像塊訓練得到一系列的濾波器,在測試時根據輸入圖片的局部梯度統計學特性索引選擇合適的濾波器完成超分辨重建。因此RAISR算法由兩部分組成,第一部分是訓練高低分辨率映射(LR/HR mapping)的濾波器,第二部分是建立濾波器索引機制(hashing mechanism)。
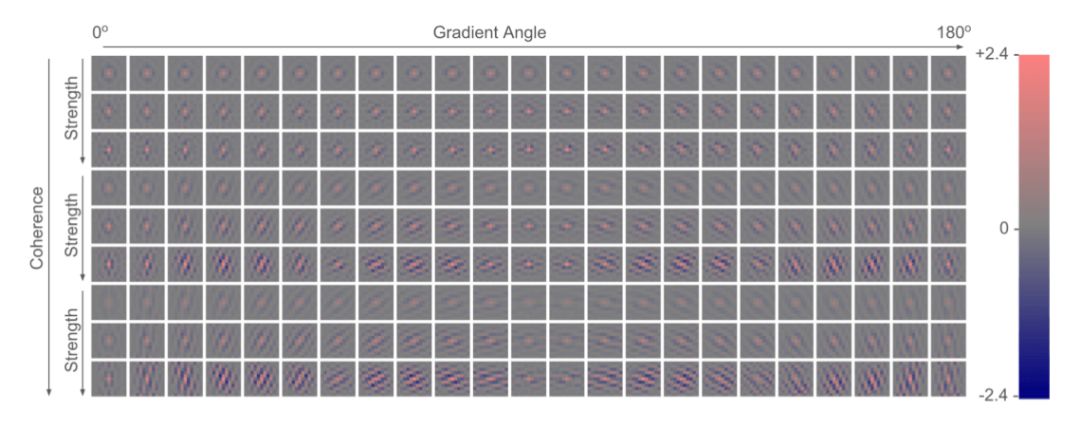
圖8:RAISR 2倍上采樣濾波器
下圖為RAISR在2x上采樣率時與SRCNN,A+等超分辨算法的技術指標對比。左為PSNR-runtime指標,右圖為SSIM-runtime指標。
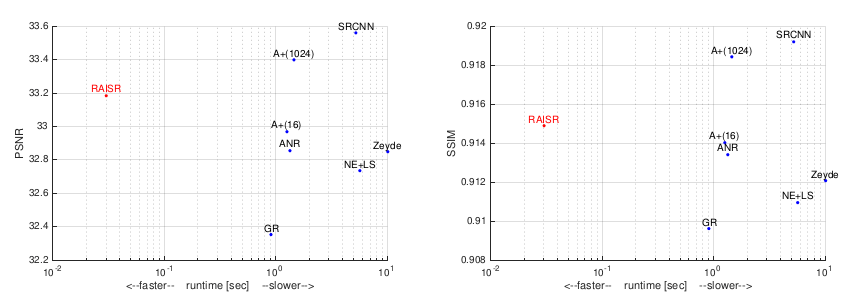
圖9:RAISR在2x上采樣率時與SRCNN,A+等超分辨算法的技術指標對比
結語
超分辨率重建在醫學影像處理、壓縮圖像增強等方面具有廣闊的應用前景,近年來一直是深度學習社區研究的熱點領域。卷積和殘差構件的改進、不同種類Perceptual Loss的進一步分析、對抗生成網絡用于超分辨率重建的探索等都是值得關注的方向。相信我們很快就能看到深度學習在超分辨率重建領域的更多重大進展。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100801 -
機器學習
+關注
關注
66文章
8420瀏覽量
132680
原文標題:一文概覽基于深度學習的超分辨率重建架構
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

結合壓縮感知與非局部信息的圖像超分辨率重建
序列圖像超分辨率重建
基于結構自相似性和形變塊特征的單幅圖像超分辨率算法
基于復合的深度神經網絡的圖像超分辨率重建





 工商網監
工商網監
評論