
 內部業務支撐&前瞻技術布局 One4All下一代生成式推薦系統
內部業務支撐&前瞻技術布局 One4All下一代生成式推薦系統
作者:京東零售 申磊
自LLM在自然語言處理等領域取得了矚目成就之后,學術界積極探索生成式模型對搜廣推系統的增強或改進方式[1],現有工作大體可以分為兩類[2]:(1)用大模型做數據和知識增強、提取表征、通過prompt將推薦轉成對話驅動的任務等,本質上沒有修改LLM,屬于信息增強和補充方法,無法直接建模海量協同信號。 (2)修改LLM直接建模搜廣推海量數據中的協同信號,對輸入輸出范式改造,通過預訓練/微調等過程建模海量數據,讓模型同時擁有通用的世界知識和垂直領域海量協同信息。是能實現搜廣推大模型scaling的前提,需要更復雜的工程架構支持。第一類工作層出不窮,第二類工作是搜廣推值得探索的前沿方向之一。2024年至今,業界在第二類工作中也有一些相關進展和成果,例如,GR(Meta)[3]、HLLM(字節)[4]、NoteLLM(小紅書)[5]、NoteLLM-2(小紅書)[6]、OneRec(快手)[7]。
CPS算法組也在生成式推薦方向上進行了一系列工作,在探索前沿技術的同時提升業務效果。關于生成式推薦系統、CPS聯盟廣告、以及第一階段的工作內容介紹可以參考我之前撰寫的文章: 生成式推薦系統與京東聯盟廣告-綜述與應用。下面,我將介紹在此文章發布之后的近期工作進展。本文進一步梳理了業務需求,并以此總結出核心技術點,針對CPS廣告的特點,對前鏈路的用戶意圖和后鏈路的多目標進行感知和建模,從而進行推薦全鏈路優化。
二、業務需求&核心技術點
CPS廣告推薦主要針對站外用戶進行多場景推薦。業務需求包括精準感知用戶意圖、進行多目標優化以兼顧收益與用戶活躍度,以及利用和兼容多種場景和任務數據。圍繞這些需求,我聚焦于顯式意圖感知的可控商品推薦、推薦效果的多目標優化、One4All生成式推薦框架這三項核心技術,分別對應生成式模型的指令遵循微調階段、偏好對齊階段以及數據到模型的全流程范式。

CPS廣告推薦業務需求與核心技術點的關系
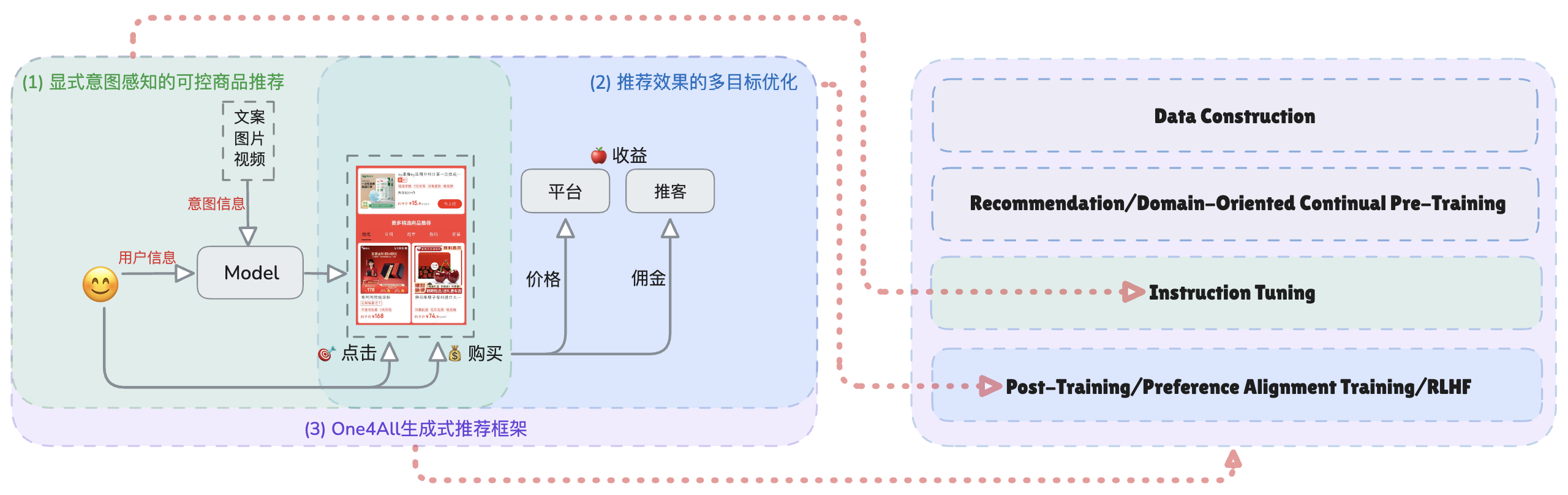
CPS廣告推薦的核心技術點與生成式推薦框架
三、顯式意圖感知的可控商品推薦
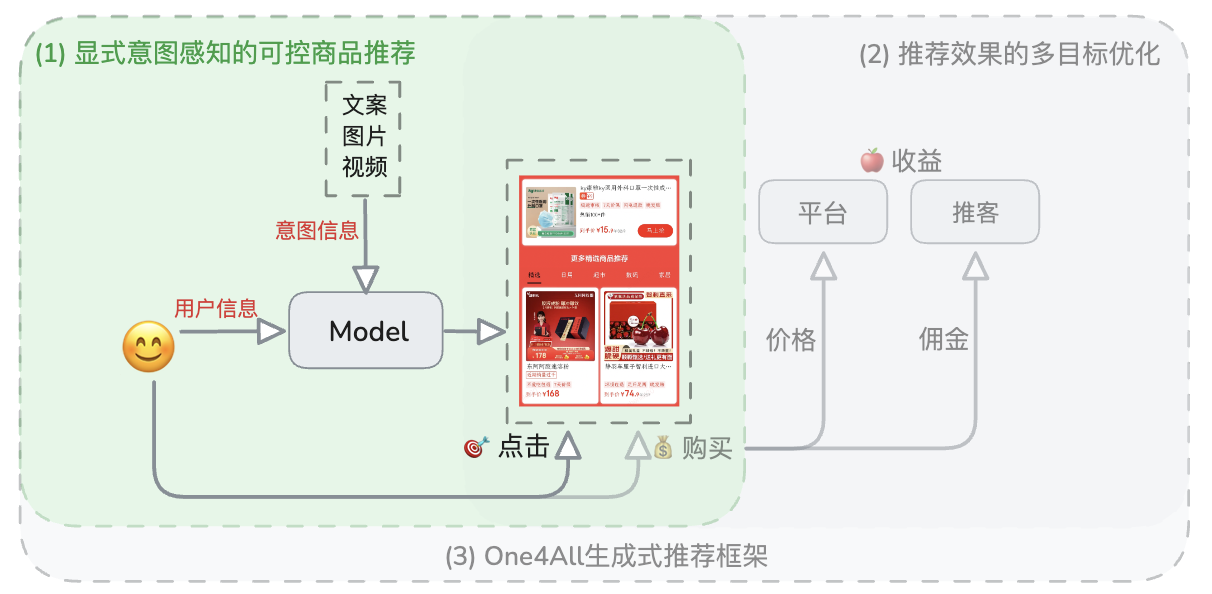
顯式意圖感知的可控商品推薦示意圖
背景介紹
現有方案匯總
落地頁商品推薦是站外廣告很重要的一種形式,對應的研究課題是觸發誘導推薦(Trigger-Induced Recommendation, TIR),現有方案包含如下三類:
?基于歷史行為序列隱式建模用戶意圖;
?利用觸發項進行I2I召回或通過sku2query生成搜索詞再進行商品檢索;
?通過三個網絡來分別表示觸發項、建模用戶歷史行為和預估權重來融合前兩者,例如,DIHN、DIAN、DEI2N和DUIN[8、9、10、11]。
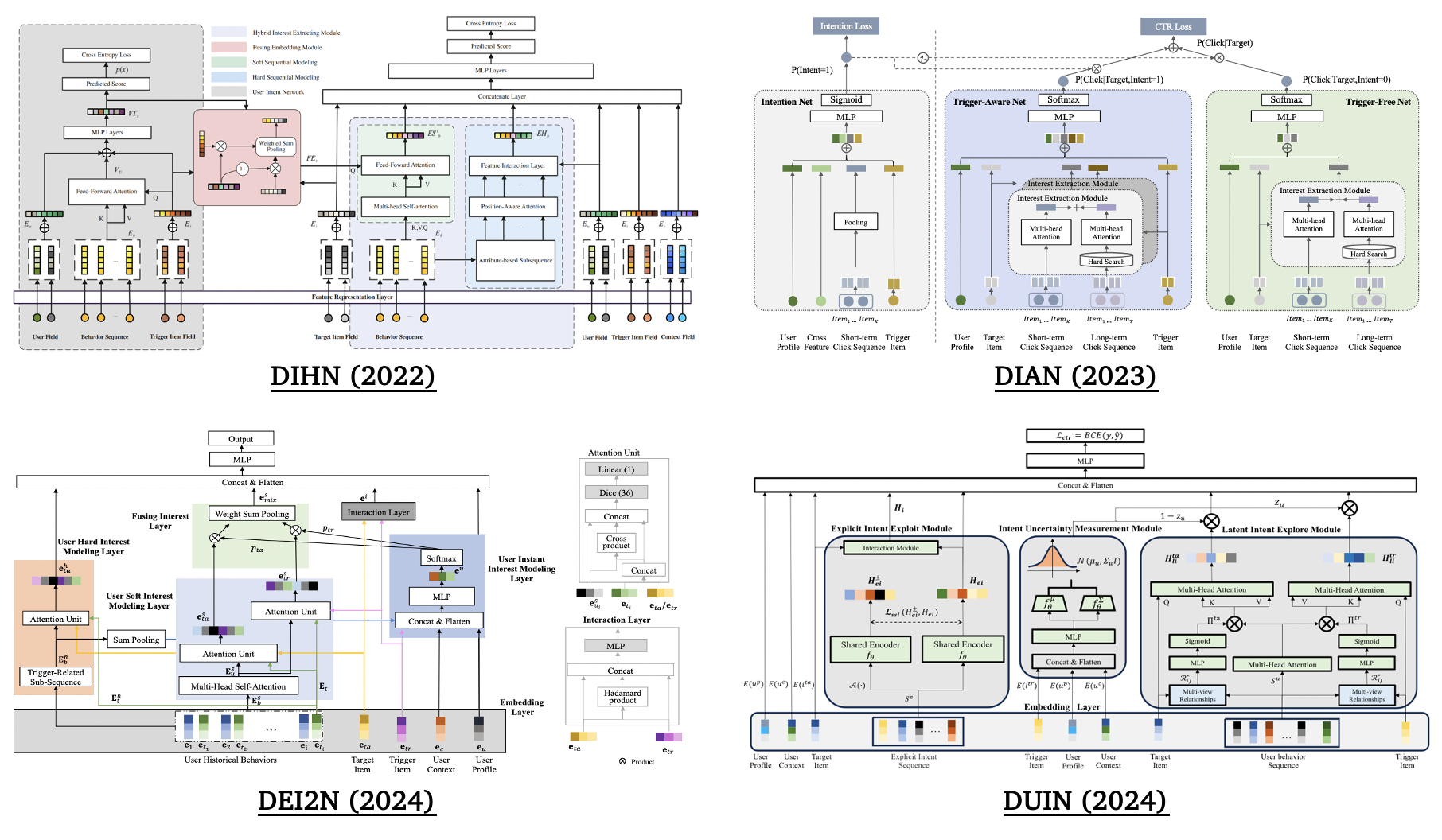
一些觸發誘導推薦方案
業務需求&現有方案局限性

顯式意圖感知的可控商品推薦業務需求與現有方案局限性
解決方案
(1) 通過傳統推薦數據自動化地生成豐富的意圖描述,以意圖文本+歷史商品語義ID序列作為輸入,目標商品語義ID作為輸出的方式 (2)重構觸發誘導推薦的任務范式,利用 (3)生成式指令遵循微調的方式實現對歷史行為和觸發項的感知和動態調控。
自動化意圖生成和評估
?輸入“用戶行為數據+目標商品”;
?基于Few-shot Prompting和CoT策略,通過言犀-81B模型對用戶行為數據進行總結、推理,并預測當前意圖;
?輸出“總結-推理-預測”的三元組數據;
?利用Self-Verification的方式對生成的顯性意圖進行評估。
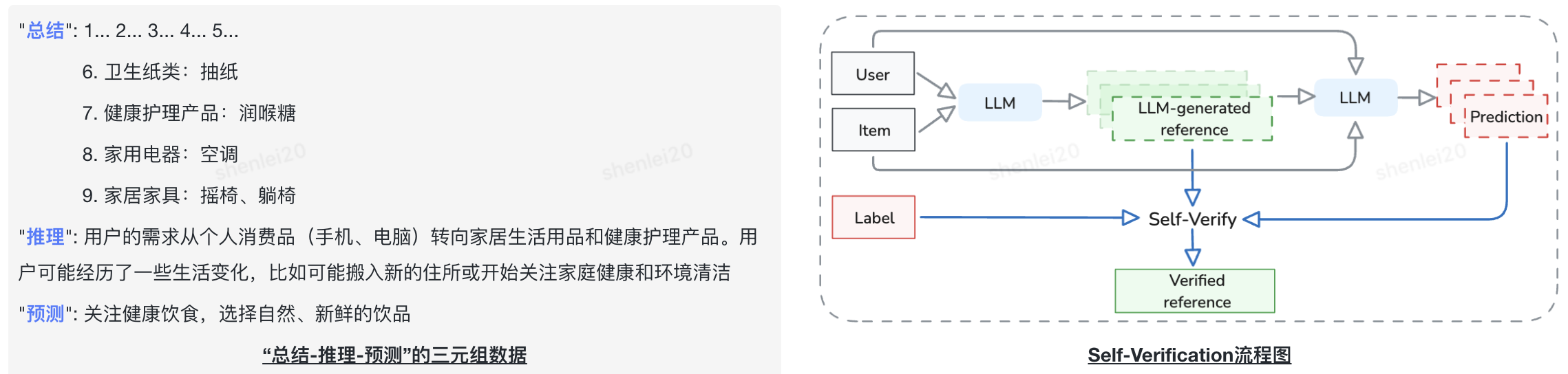
輸入輸出范式+指令遵循微調
?將數據組織成“Input: [Prompt]. Output: [Response]”的形式,在序列推薦的基礎上增加三類任務,其輸入輸出數據定義如下:

顯式意圖感知的可控商品推薦任務定義及輸入輸出示例
方案效果
?離線效果:意圖感知的可控模型在HitRate和NDCG指標上,相比非意圖感知的模型可提升2~3倍,并且表現出較好的可控能力。
?線上效果:SKUCTR提升3%+,SKUCVR、同店訂單和同店傭金也獲得顯著提升。

樣例展示1

樣例展示2
四、推薦效果的多目標優化
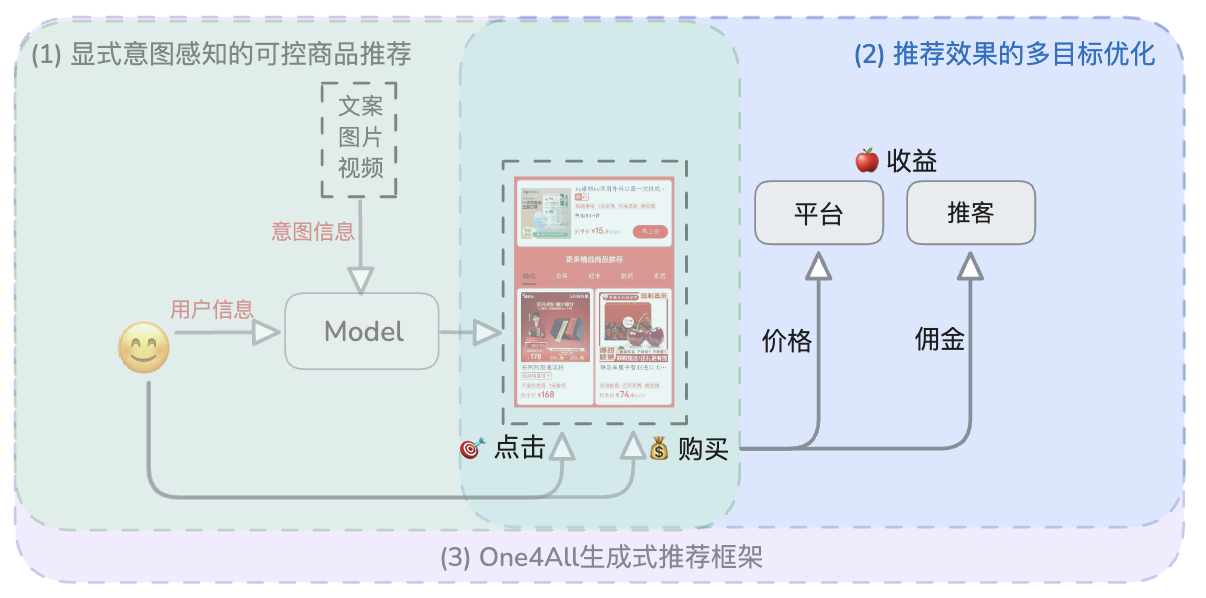
推薦效果的多目標優化示意圖
背景介紹
現有方案匯總
非LLM方法
?Shared Bottom、MMOE、PLE:通過共享和獨立網絡平衡多個任務[12、13];
?ESMM:通過全空間建模解決樣本選擇偏差問題[14]。

一些多目標優化的非LLM方法
LLM方法
?MORLHF和MODPO:基于RLHF和DPO改進,對多個獎勵函數的線性加權[15、16];
?Reward Soups:對多個LLM的權重進行插值[17]。
?

?
一些多目標優化的LLM方法
業務需求&現有方案局限性

推薦效果的多目標優化業務需求與現有方案局限性
解決方案
整合行為和價格數據,提高點擊到購買的轉化率,并最終提升廣告收益。
基于DPO的偏好對齊算法
?基于點擊商品預測模型,對“購買”偏好進行建模f(點擊->購買);
?以“點擊且購買”商品作為正例,“點擊未購買”商品作為負例,將數據組織成“Input: [Prompt]. Output1: [Response+]. Output2:[Response-]”的形式。
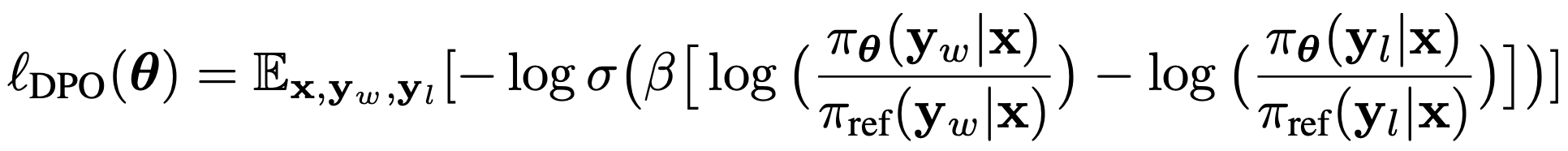
?劣勢:DPO[18、19]僅考慮了f(點擊->購買),且是正負例間的相對關系,需要將數據組成三元組的形式,沒有利用到獎勵值。
基于RiC (Rewards-in-Context) 的偏好對齊算法
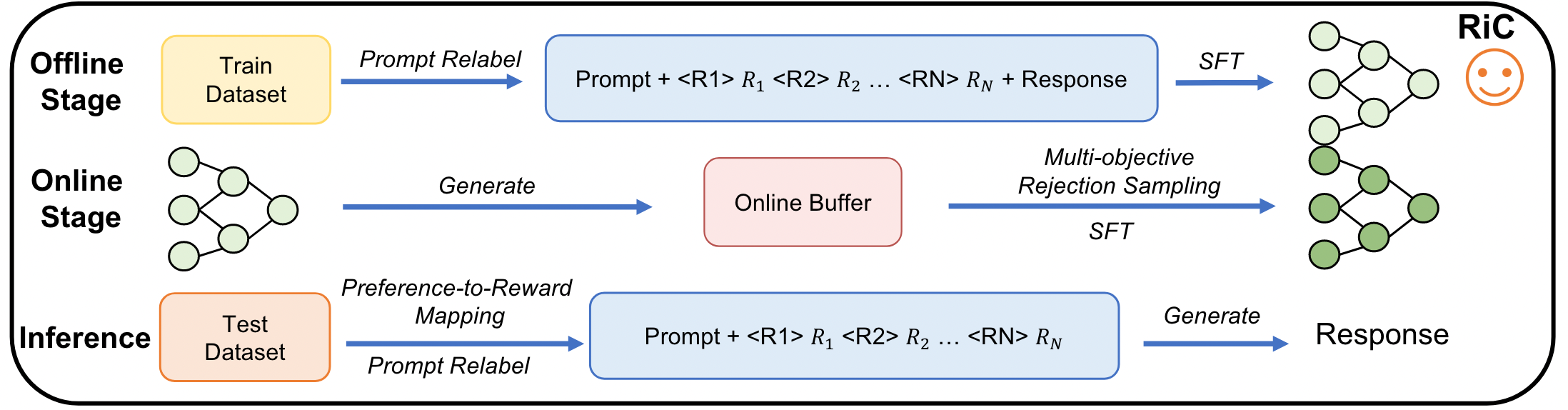
RiC框架圖
?離線訓練:把行為和收益相關的多種獎勵融入數據進行監督微調,讓模型學習不同獎勵組合下的策略
?數據形式:“Input: [Prompt]r1r2 ...rN”;
?獎勵設計:針對點擊、購買、價格、傭金獎勵進行設計,并歸一化。
?在線訓練:通過在帕累托前沿上的增強數據來改善數據稀疏問題
?產生隨機提示:在帕累托前沿附近分配獎勵,即除一維度外均賦最大值;
?離線SFT模型生成結果,獎勵模型評分,多目標拒絕采樣過濾樣本。
?推理階段:利用偏好到獎勵的映射,自由適應多樣化的用戶偏好
?優勢:(1) 僅通過監督微調就能實現LLM策略的對齊;(2) 同時利用正面和負面反饋,提升對獎勵機制的理解;(3) 擴展性非常強,覆蓋多種獎勵組合下的多樣化表現[20、21、22]。
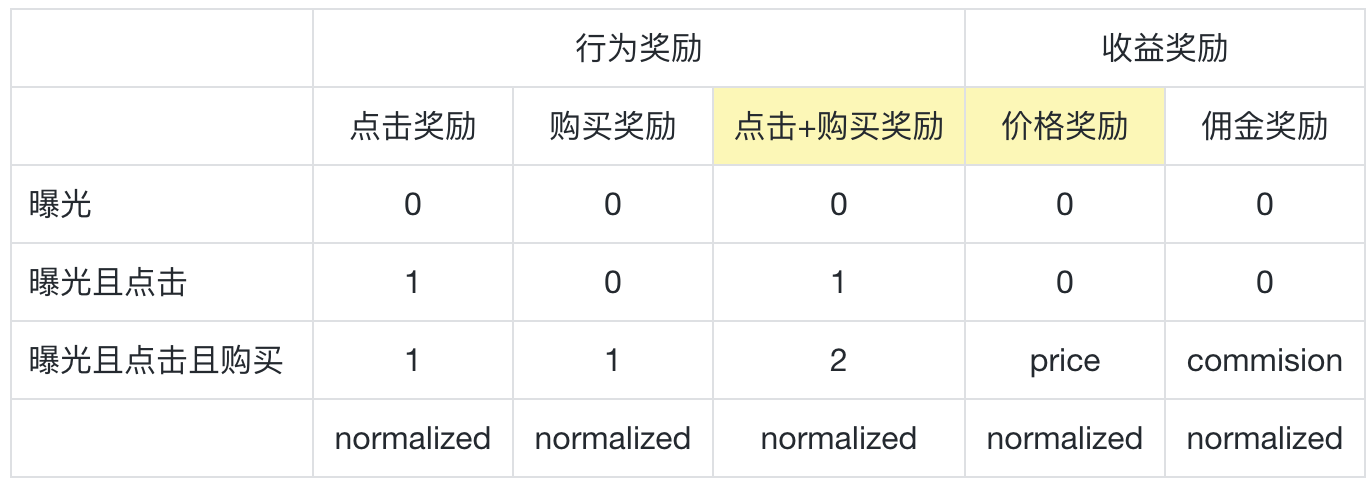
RiC獎勵設計方案
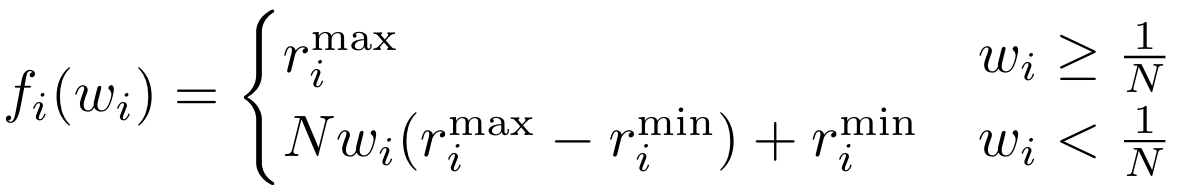
偏好到獎勵的映射函數
方案效果
?離線效果:HitRate@1在多個數據集上提升10%+;
?線上效果:SKUCTR提升1.5%+,SKUCVR提升7%+,同店訂單和同店傭金也獲得顯著提升。
五、One4All生成式推薦框架
背景介紹
業務需求
?CPS廣告推薦涉及多樣的業務場景,需要強化系統的跨場景適應性;
?需要優化框架中的模型更新策略,提升系統實時性與靈活性。
解決方案
設計可擴展框架兼顧行為和語義的理解與生成,提升推薦系統的泛化能力;同時優化模型更新策略,確保系統能夠靈活適用于不同任務和場景。
可擴展框架設計
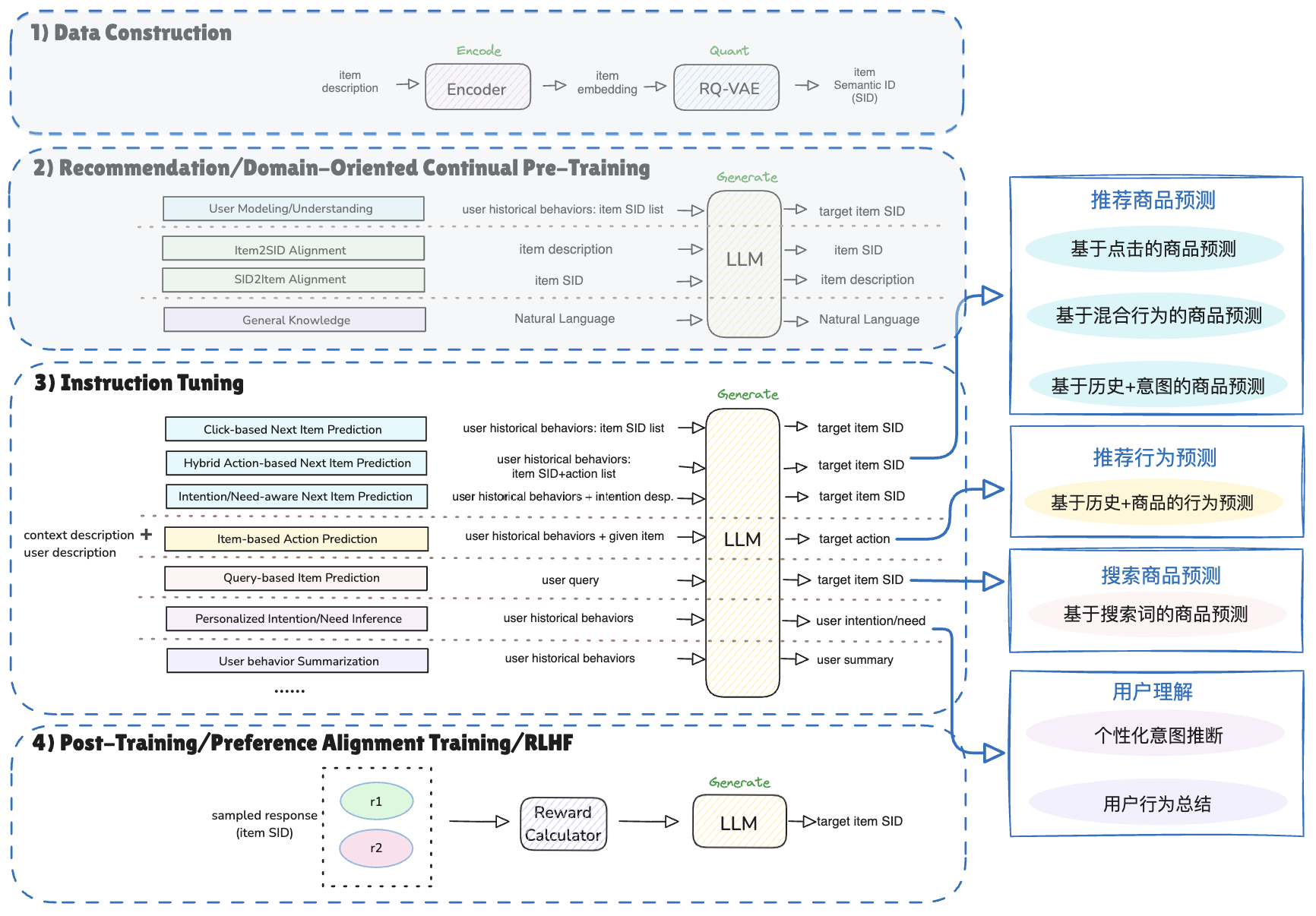
One4All生成式推薦框架示意圖
線上模型更新策略

線上模型更新策略
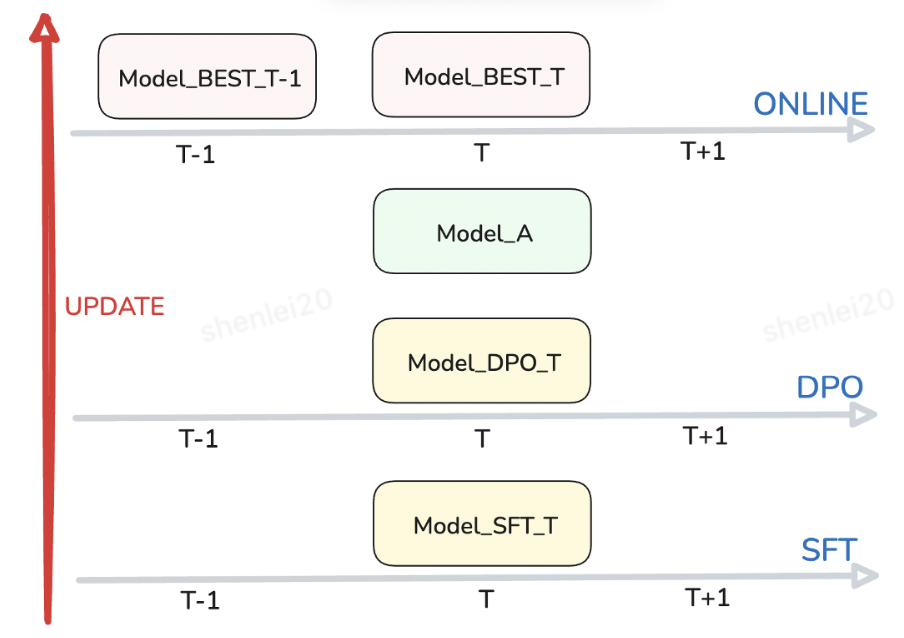
線上模型更新策略示意圖

線上例行化更新信息
方案效果
?完成了線上例行化的開發,支撐CPS廣告每天1000w+UV的在線實時推理;
?基于One4All生成式推薦框架,在現有序列推薦主任務的基礎上兼容更多的行為和語言理解的任務,推動召排一體化、搜推聯合建模、用戶行為總結、個性化意圖推斷等技術的探索。
六、總結和未來展望
?交互式推薦系統(搜索推薦聯合)
?現有方案仍未更大限度激發生成式模型的效果和能力,交互式應用是值得嘗試的方向,同時需要配合上下游進行產品形式的重構。
?多模態信息理解與生成
?前鏈路中有豐富的圖片和視頻信息,對多模態信息進行高效地理解和內容組織,可以增強推薦效果和提升展示形式的豐富程度。
最后打個小廣告:
歡迎對生成式推薦系統感興趣的同學聯系我(erp: shenlei20)一起交流討論,也歡迎加入我們CPS算法組共同探索下一代交互式搜廣推系統!
七、參考文獻
1.Xu L, Zhang J, Li B, et al. Prompting large language models for recommender systems: A comprehensive framework and empirical analysis[J]. arXiv preprint arXiv:2401.04997, 2024.
2.知乎《一文梳理工業界大模型推薦實戰經驗》. 2024
3.Zhai J, Liao L, Liu X, et al. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations[C]//Proceedings of the 41st International Conference on Machine Learning. 2024: 58484-58509.
4.Chen J, Chi L, Peng B, et al. Hllm: Enhancing sequential recommendations via hierarchical large language models for item and user modeling[J]. arXiv preprint arXiv:2409.12740, 2024.
5.Zhang C, Wu S, Zhang H, et al. Notellm: A retrievable large language model for note recommendation[C]//Companion Proceedings of the ACM Web Conference 2024. 2024: 170-179.
6.Zhang C, Zhang H, Wu S, et al. NoteLLM-2: multimodal large representation models for recommendation[J]. arXiv preprint arXiv:2405.16789, 2024.
7.Deng J, Wang S, Cai K, et al. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment[J]. arXiv preprint arXiv:2502.18965, 2025.
8.Ma J, Xiao Z, Yang L, et al. Modeling User Intent Beyond Trigger: Incorporating Uncertainty for Trigger-Induced Recommendation[C]//Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2024: 4743-4751.
9.Shen Q, Wen H, Tao W, et al. Deep interest highlight network for click-through rate prediction in trigger-induced recommendation[C]//Proceedings of the ACM web conference 2022. 2022: 422-430.
10.Xia Y, Cao Y, Hu S, et al. Deep intention-aware network for click-through rate prediction[C]//Companion Proceedings of the ACM Web Conference 2023. 2023: 533-537.
11.Xiao Z, Yang L, Zhang T, et al. Deep evolutional instant interest network for ctr prediction in trigger-induced recommendation[C]//Proceedings of the 17th ACM International Conference on Web Search and Data Mining. 2024: 846-854.
12.Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1930-1939.
13.Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Proceedings of the 14th ACM conference on recommender systems. 2020: 269-278.
14.Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
15.Zhou Z, Liu J, Shao J, et al. Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization[C]//Findings of the Association for Computational Linguistics ACL 2024. 2024: 10586-10613.
16.Li K, Zhang T, Wang R. Deep reinforcement learning for multi-objective optimization[J]. IEEE transactions on cybernetics, 2020, 51(6): 3103-3114.
17.Rame A, Couairon G, Dancette C, et al. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards[J]. Advances in Neural Information Processing Systems, 2023, 36: 71095-71134.
18.Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. Advances in Neural Information Processing Systems, 2023, 36: 53728-53741.
19.Wu J, Xie Y, Yang Z, et al. beta-DPO: Direct Preference Optimization with Dynamic beta[J]. Advances in Neural Information Processing Systems, 2025, 37: 129944-129966.
20.Lin X, Chen H, Pei C, et al. A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation[C]//Proceedings of the 13th ACM Conference on recommender systems. 2019: 20-28.
21.Hu J, Tao L, Yang J, et al. Aligning language models with offline learning from human feedback[J]. arXiv preprint arXiv:2308.12050, 2023.
22.Yang R, Pan X, Luo F, et al. Rewards-in-context: multi-objective alignment of foundation models with dynamic preference adjustment[C]//Proceedings of the 41st International Conference on Machine Learning. 2024: 56276-56297.
審核編輯 黃宇
-
AI
+關注
關注
87文章
33443瀏覽量
274013 -
大模型
+關注
關注
2文章
2925瀏覽量
3673 -
LLM
+關注
關注
1文章
316瀏覽量
628
發布評論請先 登錄
相關推薦





 工商網監
工商網監

評論